注意问题:flume总结+kafka总结
flume总结
flume如何保证数据可靠性:JDBC FILE MEMORY ???
JDBC
FILE: 传输慢
MEMORY:传输快,但是容易丢数据。解决:写个脚本监控如果flume挂了,瞬间启动
改造flume exec源 ,增加守护线程来监控目录-----防止丢失数据 | redis缓存中,存储已经收集过的key---防止重复收集

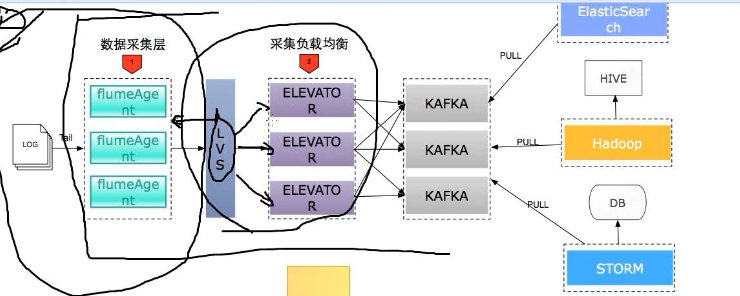
flume LVS 负载均衡
Linux Virtual Server
LVS集群采用IP负载均衡技术和基于内容请求分发技术
og
升级成ng
kafka总结
kafka数据丢失问题解决
1、kafka数据丢失问题:
acks = 1 只保证leader成功,如果刚好leader挂了,数据丢失
acks=0 使用异步模式,该模式下kafka无法保证消息,可能会丢失
2、broker kafka集群的缓存代理broker保证数据不丢失: Broker:缓存代理,Kafka集群中的一台或多台服务器统称为broker
acks = all :所有副本都写入成功并确认
retries = 设置合理值 重新拉数据
min.insync.replicas = 2 消息至少要被写入到2 个副本才算成功
unclean.leader.election.enable = false 关闭ubclean leader 选举,不允许非ISR中的副本被选举为leader,一面是户据丢失
3、consumer保证数据不丢失:
出现数据丢失因为在:在消息处理完成前就提交了offset
解决:关闭自动提交偏移量offset:enable.auto.commit = false
处理完消息手动提交偏移量
kafka工作流程
kafka保证消息顺序:
1、全局顺序:全局使用一个生产者,一个分区,一个消费者
2、局部顺序:每个分区是有序的,根据业务场景制定不同的key进入不同的分区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号