27 友盟项目--azkaban资源调度
azkaban资源调度
1、启动azkaban

2、azkban web执行器 8081
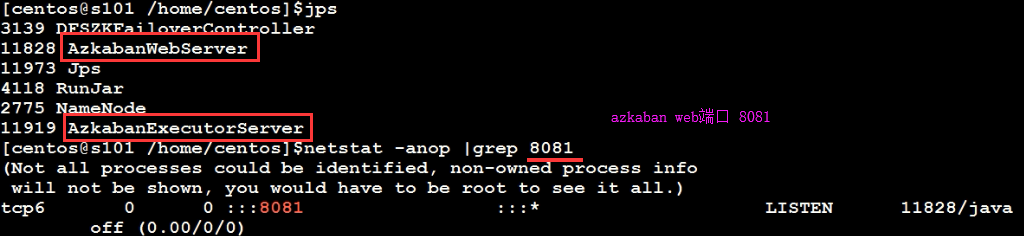
3、s101:8081
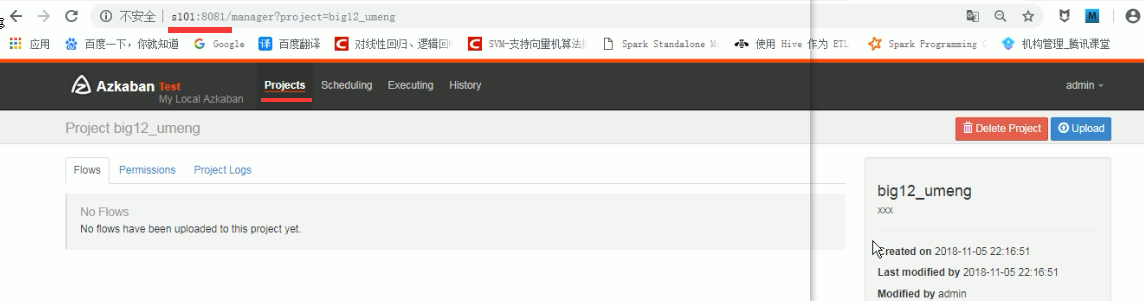
4、jar包目录
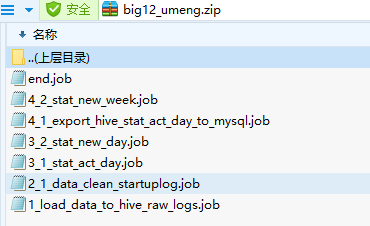
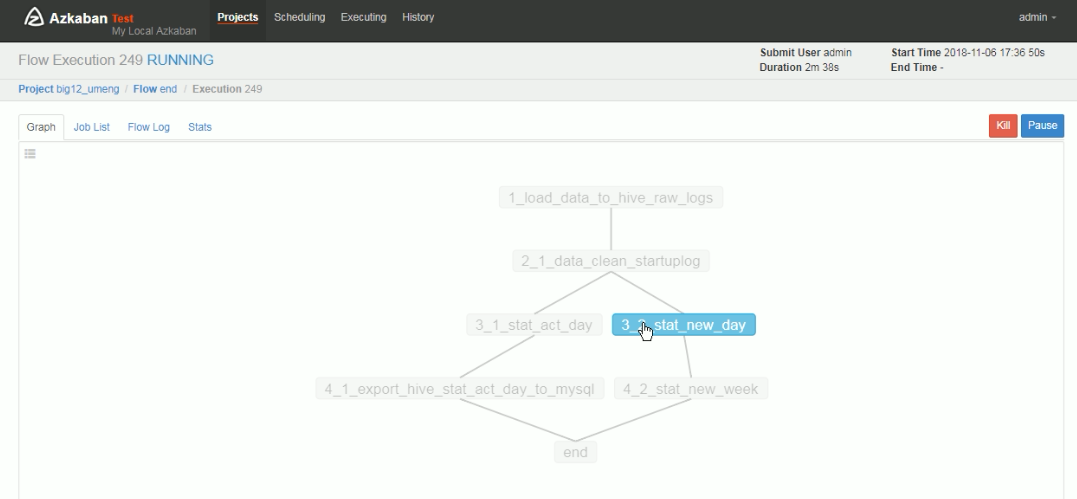
创建有依赖关系dependencies的多个job描述
1_load_data_to_hive_raw_logs.job
type=command
command=sh /home/centos/big12_umeng/load_data_to_hive_raw_logs.sh
2_1_data_clean_startuplog.job
type=command
command=sh /home/centos/big12_umeng/data_clean.sh /home/centos/big12_umeng/data_clean_startup.sql
dependencies=1_load_data_to_hive_raw_logs
3_1_stat_act_day.job
type=command
command=sh /home/centos/big12_umeng/stat_act_day.sh /home/centos/big12_umeng/stat_act_day.sql
dependencies=2_1_data_clean_startuplog
3_2_stat_new_day.job
type=command
command=sh /home/centos/big12_umeng/stat_new_day.sh /home/centos/big12_umeng/stat_new_day.sql
dependencies=2_1_data_clean_startuplog
4_1_export_hive_stat_act_day_to_mysql.job //hive导出日活到mysql
type=command
command=/home/centos/big12_umeng/export_hive_stat_act_day_to_mysql.sh
dependencies=3_1_stat_act_day
4_2_stat_new_week.job
type=command
command=sh /home/centos/big12_umeng/stat_new_week.sh /home/centos/big12_umeng/stat_new_week.sql
dependencies=3_2_stat_new_day
end.job
type=noop
dependencies=4_2_stat_new_week,4_1_export_hive_stat_act_day_to_mysql
6、job作业执行过程需要的执行文件、sql文件
load_data_to_hive_raw_logs.sh
#!/bin/bash cd /home/centos/big12_umeng if [[ $# = 0 ]] ; then time=`date -d "-1 days" "+%Y%m-%d"` ; else time=$1$2-$3 fi #external time variable echo -n $time > _time ym=`echo $time | awk -F '-' '{print $1}'` day=`echo $time | awk -F '-' '{print $2}'` hive -hiveconf ym=${ym} -hiveconf day=${day} -f load_data_to_hive_raw_logs.sql
|
|
\/
load_data_to_hive_raw_logs.sql
use big12_umeng ;
load data inpath 'hdfs://mycluster/user/centos/umeng_big12/raw-logs/${hiveconf:ym}/${hiveconf:day}' into table raw_logs partition(ym=${hiveconf:ym},day=${hiveconf:day}) ;
data_clean.sh
#!/bin/bash cd /home/centos/big12_umeng spark-submit --master yarn --jars /home/centos/big12_umeng/umeng_hive.jar --class com.oldboy.umeng.spark.stat.DataClean /home/centos/big12_umeng/umeng_spark.jar $1 `cat _time | awk -F '-' '{print $1$2}'`
|
|
\/
data_clean_startup.sql


-- appstartuplog use big12_umeng ; insert into appstartuplogs partition(ym , day) select t.appChannel , t.appId , t.appPlatform , t.appVersion , t.brand , t.carrier , t.country , t.createdAtMs , t.deviceId , t.deviceStyle , t.ipAddress , t.network , t.osType , t.province , t.screenSize , t.tenantId , formatbyday(t.createdatms , 0 , 'yyyyMM') , formatbyday(t.createdatms , 0 , 'dd') from ( select forkstartuplogs(servertimestr ,clienttimems ,clientip ,json) from raw_logs where concat(ym,day) = '${ymd}' )t;
stat_act_day.sh
#!/bin/bash cd /home/centos/big12_umeng spark-submit --master yarn --jars /home/centos/big12_umeng/umeng_hive.jar --class com.oldboy.umeng.spark.stat.StatActDay umeng_spark.jar $1 `cat _time | awk -F '-' '{print $1$2}'`
|
|
\/
stat_act_day.sql
use big12_umeng ; create table if not exists stat_act_day( day string , appid string, appplatform string, brand string , devicestyle string, ostype string , appversion string , cnt int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' lines terminated by '\n'; insert into table stat_act_day select '${ymd}', ifnull(tt.appid ,'NULLL') , ifnull(tt.appplatform,'NULLL') , ifnull(tt.brand ,'NULLL') , ifnull(tt.devicestyle,'NULLL') , ifnull(tt.ostype ,'NULLL') , ifnull(tt.appversion ,'NULLL') , count(tt.deviceid) FROM ( select t.appid , t.appplatform, t.brand , t.devicestyle, t.ostype , t.appversion , t.deviceid FROM ( select appid , appplatform, brand , devicestyle, ostype , appversion , deviceid from appstartuplogs WHERE concat(ym,day) = '${ymd}' group BY appid , appplatform, brand , devicestyle, ostype , appversion, deviceid with cube )t where t.appid is not null and t.deviceid is not null )tt group BY tt.appid , tt.appplatform, tt.brand , tt.devicestyle, tt.ostype , tt.appversion order by tt.appid , tt.appplatform, tt.brand , tt.devicestyle, tt.ostype , tt.appversion
stat_new_day.sh
#!/bin/bash cd /home/centos/big12_umeng spark-submit --master local[4] --class com.oldboy.umeng.spark.stat.StatNewDay --jars /home/centos/big12_umeng/umeng_hive.jar umeng_spark.jar $1 `cat _time | awk -F '-' '{print $1$2}'`
|
|
\/
stat_new_day.sql
use big12_umeng ; create table if not exists stat_new_day( day string , appid string, appplatform string, brand string , devicestyle string, ostype string , appversion string , cnt int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' lines terminated by '\n'; insert into table stat_new_day SELECT '${ymd}' , t.appid , t.appversion , t.appplatform, t.brand , t.devicestyle, t.ostype , count(t.deviceid) cnt FROM ( select appid , appplatform, brand , devicestyle, ostype , appversion , deviceid , min(createdatms) firsttime from appstartuplogs group BY appid , appplatform, brand , devicestyle, ostype , appversion, deviceid with cube )t WHERE t.appid is not NULL and t.deviceid is not null and formatbyday(t.firsttime , 0 , 'yyyyMMdd') = '${ymd}' group by t.appid , t.appversion , t.appplatform, t.brand , t.devicestyle, t.ostype order BY t.appid , t.appversion , t.appplatform, t.brand , t.devicestyle, t.ostype
export_hive_stat_act_day_to_mysql.sh
sqoop-export --driver com.mysql.jdbc.Driver --connect jdbc:mysql://192.168.231.1:3306/big12 --username root --password root --columns day,appid,appplatform,brand,devicestyle,ostype,appversion,cnt --table stat_act_day --export-dir /user/hive/warehouse/big12_umeng.db/stat_act_day -m 3
stat_new_week.sh
#!/bin/bash cd /home/centos/big12_umeng spark-submit --master yarn -class com.oldboy.umeng.spark.stat.StatNewWeek --jars /home/centos/big12_umeng/umeng_hive.jar umeng_spark.jar $1 `cat _time | awk -F '-' '{print $1$2}'`
|
|
\/
stat_new_week.sql
use big12_umeng ; create table if not exists stat_new_week( day string , appid string, appplatform string, brand string , devicestyle string, ostype string , appversion string , cnt int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' lines terminated by '\n'; insert into table stat_new_week SELECT appid , appversion , appplatform, brand , devicestyle, ostype , sum(cnt) cnt FROM stat_new_day WHERE formatbyweek(day ,'yyyyMMdd' , 0 , 'yyyyMMdd') = formatbyweek('${ymd}' ,'yyyyMMdd' , 0 , 'yyyyMMdd') group by appid , appversion , appplatform, brand , devicestyle, ostype
_time
201811-05
7、所有文件和jar包放到 /home/centos/big12_umeng/下
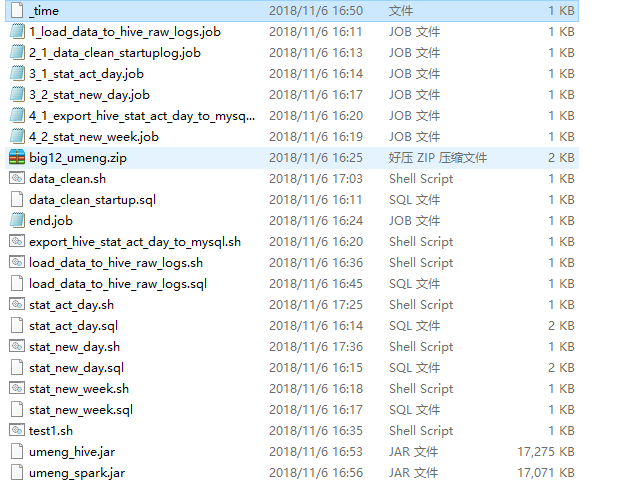
8、azkaban创建工程 ,执行job 8081

 浙公网安备 33010602011771号
浙公网安备 33010602011771号