
SpringCloud
1. 微服务概念说明
1.1 系统架构演变
随着互联网的发展,网站应用的规模不断扩大,常规的应用架构已无法应对,分布式服务架构以及微服 务架构势在必行,亟需一个治理系统确保架构有条不紊的演进。
1.1.1 单体应用架构
Web应用程序发展的早期,大部分web工程(包含前端页面,web层代码,service层代码,dao层代码)是将所有的功能模块,打包到一起并放在一个web容器中运行
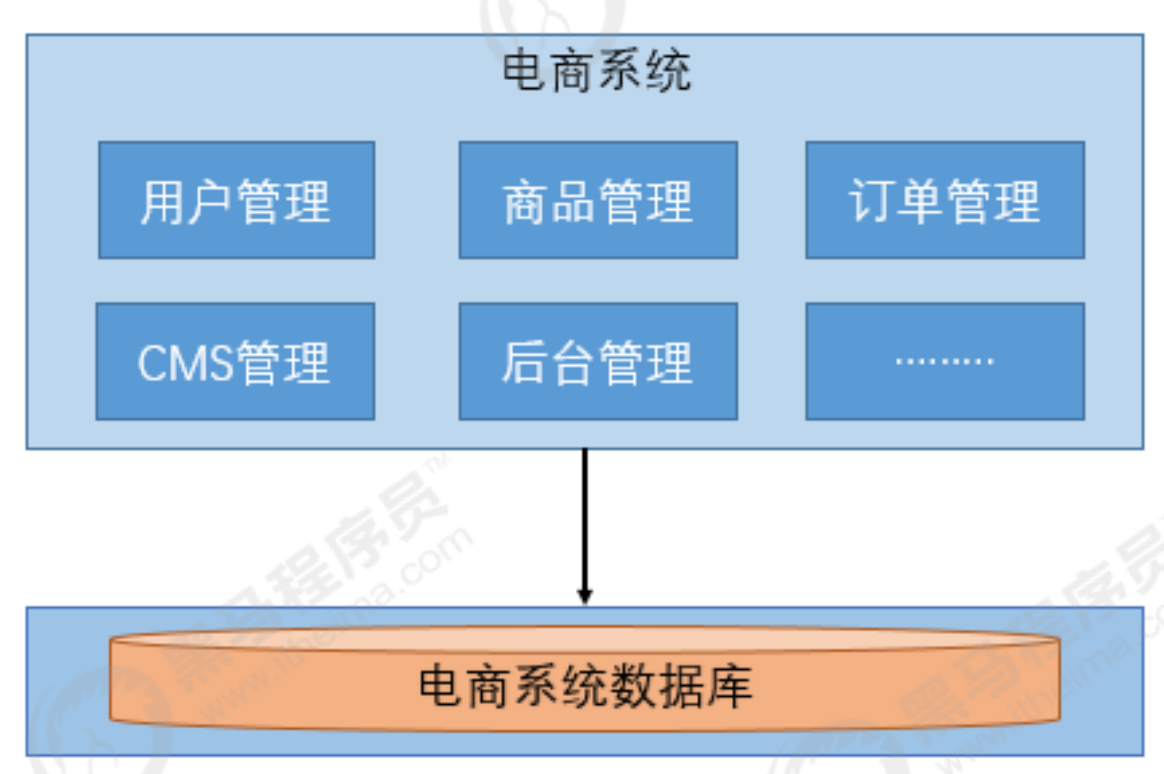
比如搭建一个电商系统:客户下订单,商品展示,用户管理。这种将所有功能都部署在一个web容器中 运行的系统就叫做单体架构。
优点:
- 所有的功能集成在一个项目工程中
- 项目架构简单,前期开发成本低,周期短,小型项目的首选。
缺点:
- 全部功能集成在一个工程中,对于大型项目不易开发、扩展及维护。
- 系统性能扩展只能通过扩展集群结点,成本高、有瓶颈。
- 技术栈受限
1.1.2 垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率
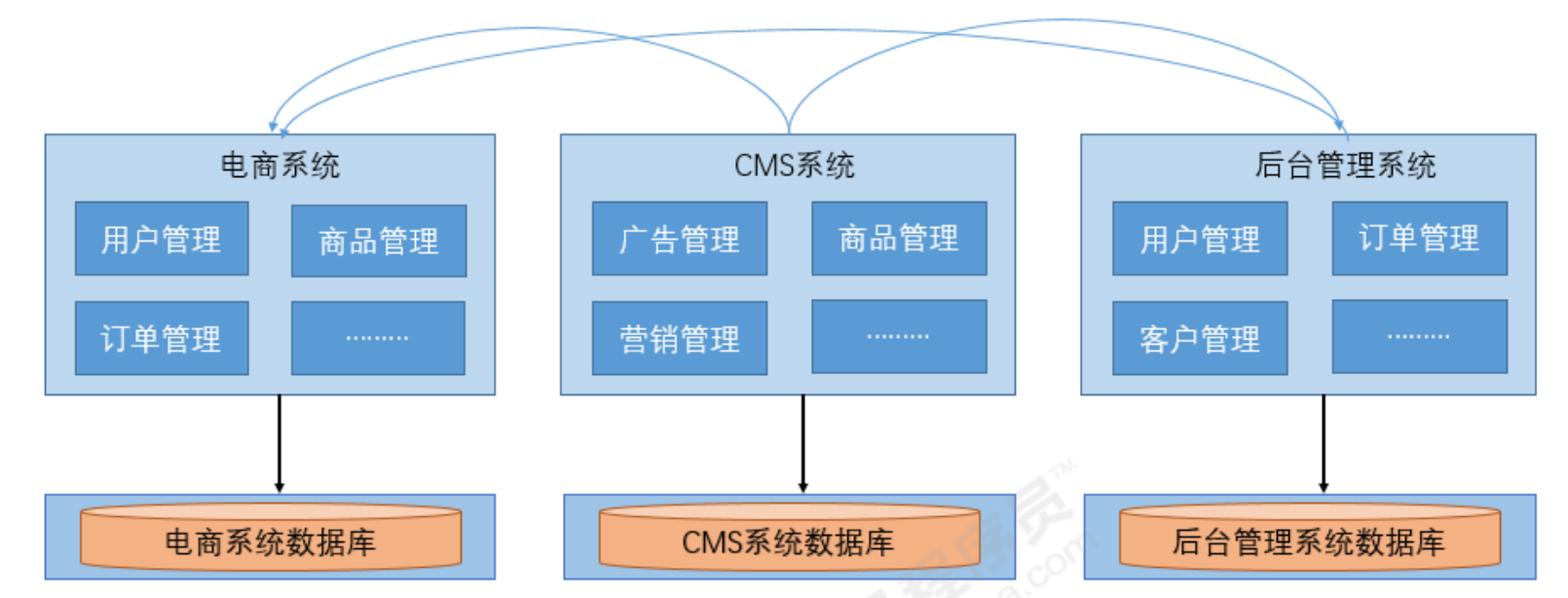
优点:
- 项目架构简单,前期开发成本低,周期短,小型项目的首选。
- 通过垂直拆分,原来的单体项目不至于无限扩大
- 不同的项目可采用不同的技术。
缺点:
- 全部功能集成在一个工程中,对于大型项目不易开发、扩展及维护。
- 系统性能扩展只能通过扩展集群结点,成本高、有瓶颈
1.1.3 分布式SOA架构
SOA 全称为 Service-Oriented Architecture,即面向服务的架构。它可以根据需求通过网络对松散耦合 的粗粒度应用组件(服务)进行分布式部署、组合和使用。一个服务通常以独立的形式存在于操作系统进 程中。
站在功能的角度,把业务逻辑抽象成可复用、可组装的服务,通过服务的编排实现业务的快速再生,目 的:把原先固有的业务功能转变为通用的业务服务,实现业务逻辑的快速复用。
通过上面的描述可以发现 SOA 有如下几个特点:分布式、可重用、扩展灵活、松耦合
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求
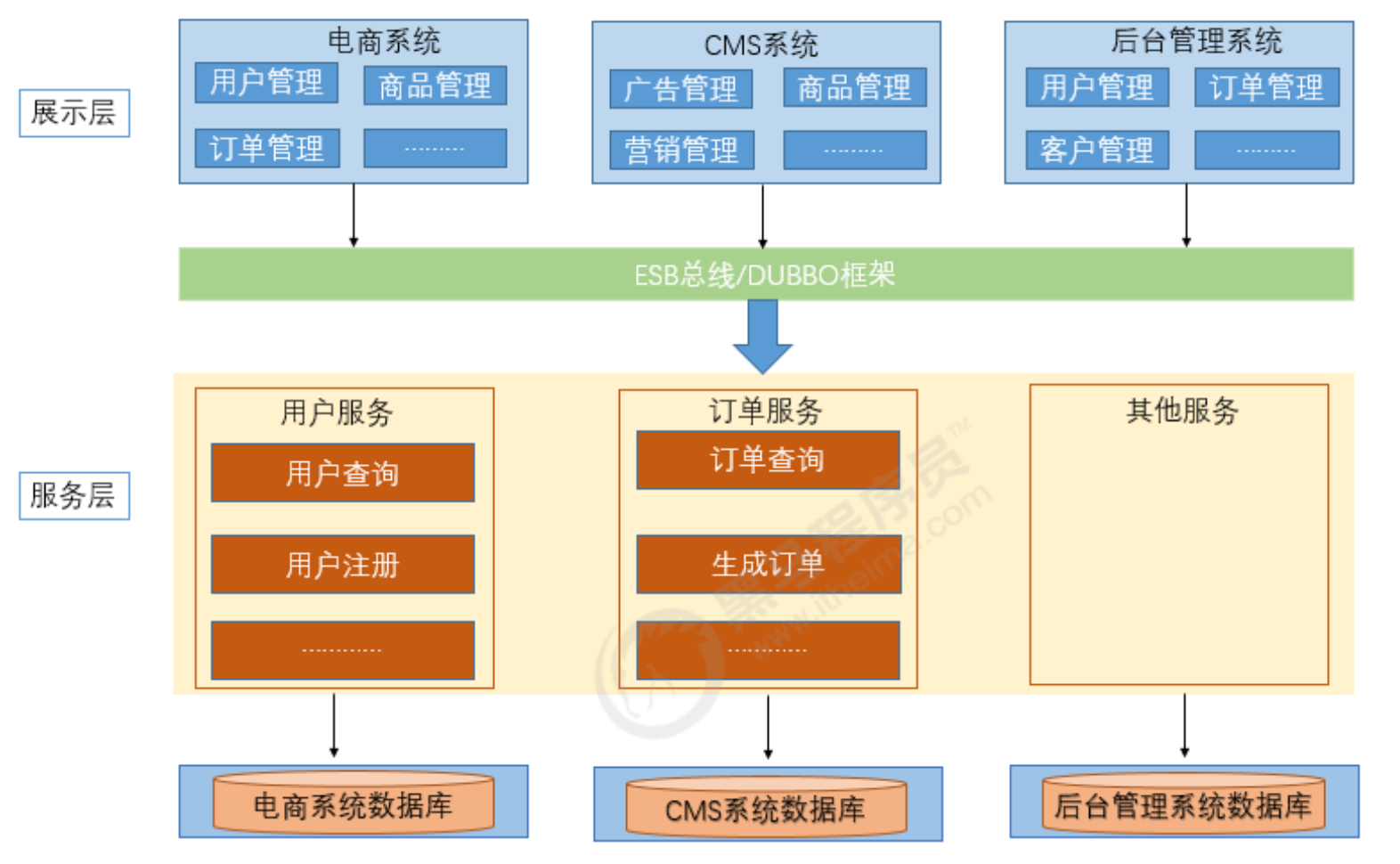
优点:
- 抽取公共的功能为服务,提高开发效率
- 对不同的服务进行集群化部署解决系统压力
- 基于ESB/DUBBO减少系统耦合
缺点:
- 抽取服务的粒度较大
- 服务提供方与调用方接口耦合度较高
1.1.4 微服务架构
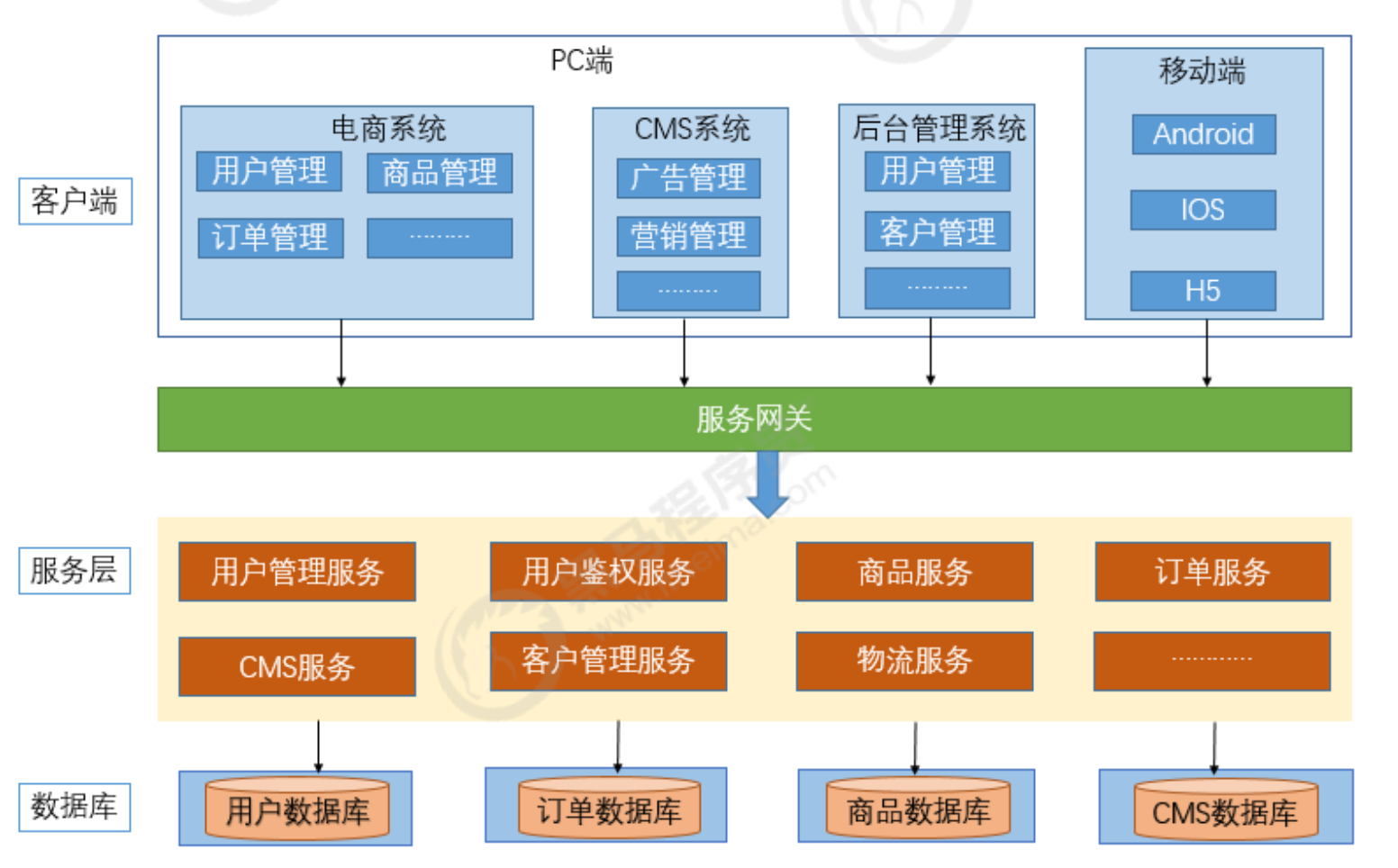
优点:
- 通过服务的原子化拆分,以及微服务的独立打包、部署和升级,小团队的交付周期将缩短,运维成本也将大幅度下降
- 微服务遵循单一原则。微服务之间采用Restful等轻量协议传输。
缺点:
- 微服务过多,服务治理成本高,不利于系统维护。
- 分布式系统开发的技术成本高(容错、分布式事务等)
1.2 分布式
1.2.1 远程调用
在微服务架构中,通常存在多个服务之间的远程调用的需求。
远程调用通常包含两个部分:序列化和通 信协议。常见的序列化协议包括json、xml、hession、protobuf、thrift、text、bytes等,目前主流的远程调用技术有基于HTTP的RESTful接口以及基于TCP的RPC协议
RESTful接口
REST,Representational State Transfer的缩写,如果一个架构符合REST原则,就称它为RESTful架构
-
资源(Resources)
所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图 片、一首歌曲、一种服务,总之就是一个具体的实在。
你可以用一个URI(统一资源定位符)指向它, 每种资源对应一个特定的URI。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地 址或独一无二的识别符。
REST的名称"表现层状态转化"中,省略了主语。"表现层"其实指的是"资源"(Resources)的"表现层"
-
表现层(Representation)
"资源"是一种信息实体,它可以有多种外在表现形式。
我们把"资源"具体呈现出来的形式,叫做它的"表 现层"(Representation)。比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格 式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
URI只代表资源的实体,不代表它的形式。严格地说,有些网址最后的".html"后缀名是不必要的,因为这个后缀名表示格式,属于"表现层"范畴,而URI应该只代表"资源"的位置。
-
状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转化"。 客户端用到的手段,只能是HTTP协议。
具体来说,就是HTTP协议里面,四个表示操作方式的动词: GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源 (也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源
综合上面的解释,我们总结一下什么是RESTful架构:
- 每一个URI代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现层;
- 客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
RPC协议
RPC(Remote Procedure Call ) 一种进程间通信方式。允许像调用本地服务一样调用远程服务。RPC 框架的主要目标就是让远程服务调用更简单、透明。
RPC框架负责屏蔽底层的传输方式(TCP或者 UDP)、序列化方式(XML/JSON/二进制)和通信细节。开发人员在使用的时候只需要了解谁在什么位置提供了什么样的远程服务接口即可,并不需要关心底层通信细节和调用过程。
比较
| RestFul | RPC | |
|---|---|---|
| 通讯协议 | HTTP | 一般使用TCP |
| 性能 | 略低 | 较高 |
| 灵活度 | 高 | 低 |
| 应用 | 微服务架构 | SOA架构 |
-
HTTP相对更规范,更标准,更通用,无论哪种语言都支持http协议。
如果你是对外开放API,例如开放平台,外部的编程语言多种多样,你无法拒绝对每种语言的支持,现在开源中间件,基本最先支持的几个协议都包含RESTful。
-
RPC 框架作为架构微服务化的基础组件,它能大大降低架构微服务化的成本,提高调用方与服务提 供方的研发效率,屏蔽跨进程调用函数(服务)的各类复杂细节。
让调用方感觉就像调用本地函数一样 调用远端函数、让服务提供方感觉就像实现一个本地函数一样来实现服务。
1.2.2 CAP原理
现如今,对于多数大型互联网应用,分布式系统(distributed system)正变得越来越重要。
分布式系统的最大难点,就是各个节点的状态如何同步。CAP 定理是这方面的基本定理,也是理解分布式系统的起点
-
Consistency(一致性): 数据一致更新,所有数据的变化都是同步的
-
Availability(可用性):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求
-
Partition tolerance(分区容忍性):某个节点的故障,并不影响整个系统的运行
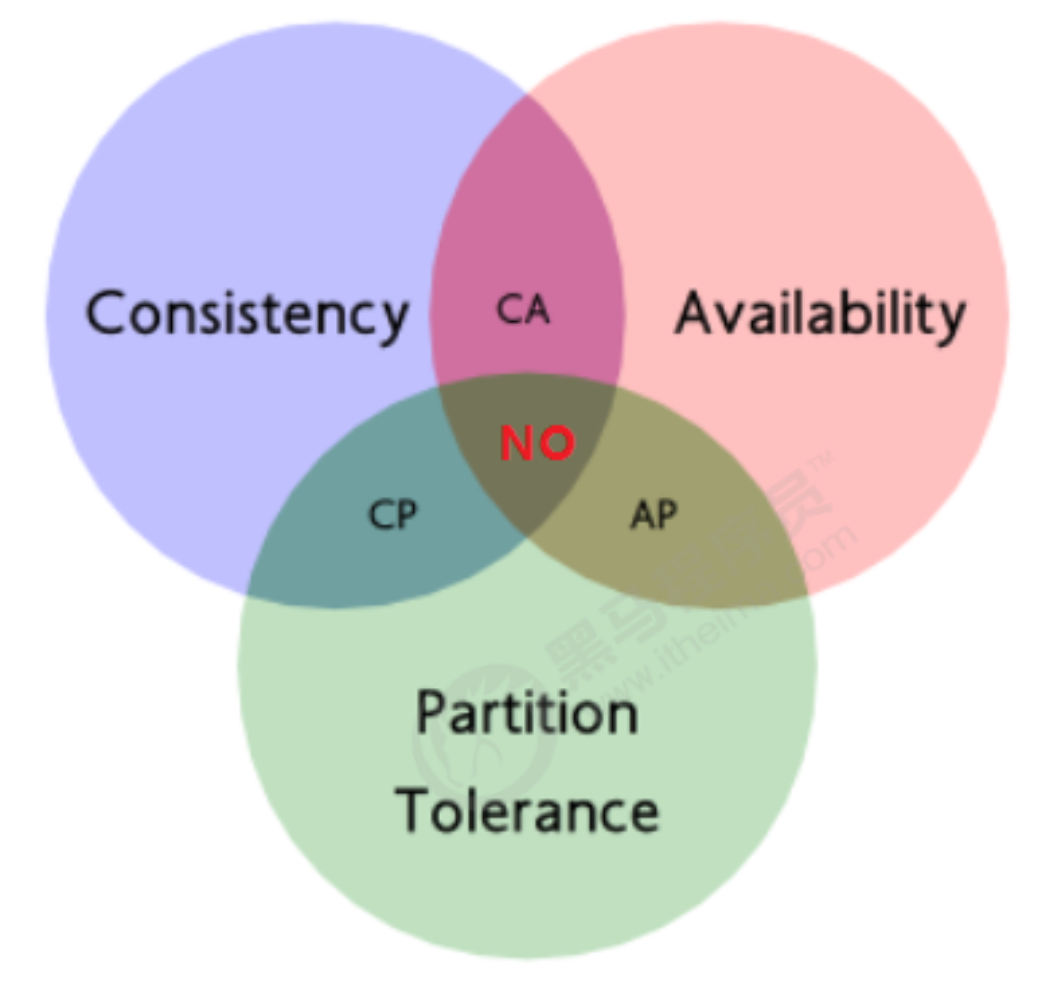
任何分布式系统只可同时满足二点,没法三者兼顾,既然一个分布式系统无法同时满足一致性、可用性、分区容错性三个特点,所以我们就需要抛弃其中一点。
选择 说明 CA 放弃分区容错性,加强一致性和可用性,其实就是传统的关系型数据库的选择 AP 放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,例如很多NoSQL系统就是如此 CP 放弃可用性,追求一致性和分区容错性,基本不会选择,网络问题会直接让整个系统不可用
1.3 常见微服务架构
1.3.1 SpringCloud
Spring Cloud是一系列框架的有序集合。
它利用Spring Boot的开发便利性,巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,这些都可以用 Spring Boot的开发风格做到一键启动和部署。
Spring Cloud并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具 包。
1.3.2 ServiceComb
Apache ServiceComb 是业界第一个Apache微服务顶级项目,是一个开源微服务解决方案,致力于帮助 企业、用户和开发者将企业应用轻松微服务化上云,并实现对微服务应用的高效运维管理。其提供一站 式开源微服务解决方案,融合SDK框架级、0侵入ServiceMesh场景并支持多语言
1.3.3 ZeroC ICE
ZeroC IceGrid 是ZeroC公司的杰作,继承了CORBA的血统,是新一代的面向对象的分布式系统中间 件。作为一种微服务架构,它基于RPC框架发展而来,具有良好的性能与分布式能力。
2. SpringCloud概述
2.1 微服务
2.1.1 服务注册与发现
-
服务注册
服务实例将自身服务信息注册到注册中心。
这部分服务信息包括服务所在主机IP和提供服务的Port,以及暴露服务自身状态以及访问协议等信息。
-
服务发现
服务实例请求注册中心获取所依赖服务信息。
服务实例通过注册中心,获取到注册到其中的 服务实例的信息,通过这些信息去请求它们提供的服务
2.1.2 负载均衡
负载均衡是高可用网络基础架构的关键组件,通常用于将工作负载分布到多个服务器来提高网站、应 用、数据库或其他服务的性能和可靠性。
2.1.3 熔断
熔断这一概念来源于电子工程中的断路器(Circuit Breaker)。
在互联网系统中,当下游服务因访问压 力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。
2.1.4 链路追踪
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务。
互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要对一次请求涉及的多个 服务链路进行日志记录,性能监控即链路追踪
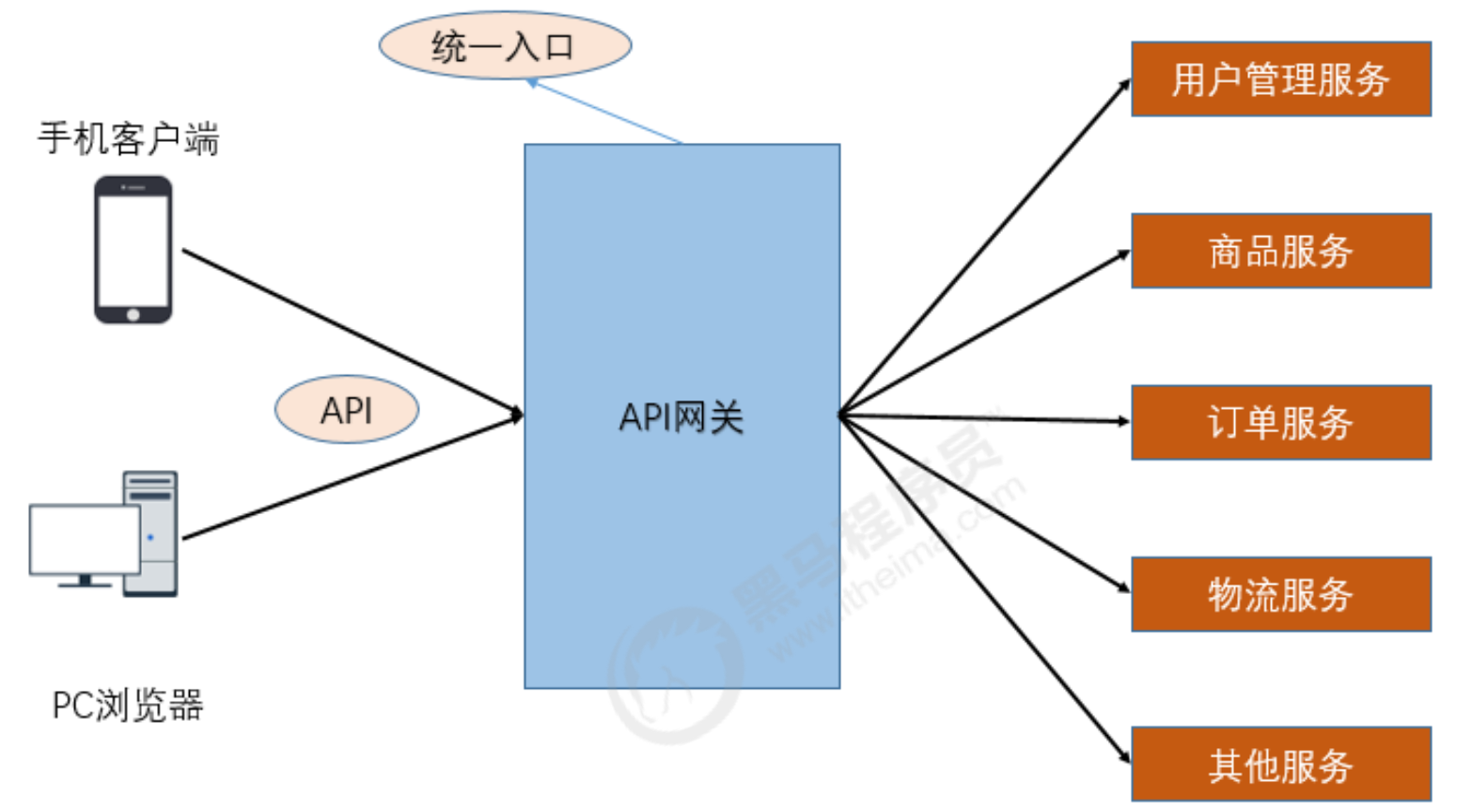
2.1.5 API网关
随着微服务的不断增多,不同的微服务一般会有不同的网络地址,而外部客户端可能需要调用多个服务的接口才能完成一个业务需求,如果让客户端直接与各个微服务通信可能出现:
- 客户端需要调用不同的url地址,增加难度
- 在一定的场景下,存在跨域请求的问题
- 每个微服务都需要进行单独的身份认证
针对这些问题,API网关顺势而生。
API网关直面意思是将所有API调用统一接入到API网关层,由网关层统一接入和输出。
一个网关的基本功能有:统一接入、安全防护、协议适配、流量管控、长短链接支持、容错能力。
有了网关之后,各个 API服务提供团队可以专注于自己的的业务逻辑处理,而API网关更专注于安全、流量、路由等问题。
2.2 SpringCloud架构
2.2.1 核心组件
Spring Cloud的本质是在 Spring Boot 的基础上,增加了一堆微服务相关的规范,并对应用上下文 (Application Context)进行了功能增强。
既然 Spring Cloud 是规范,那么就需要去实现,目前 Spring Cloud 规范已有 Spring官方,Spring Cloud Netflix,Spring Cloud Alibaba等实现。通过组件化的方式,Spring Cloud将这些实现整合到一起构成全家桶式的微服务技术栈。
Spring Cloud Netflix
| 组件名称 | 作用 |
|---|---|
| Eureka | 服务注册中心 |
| Ribbon | 客户端负载均衡 |
| Feign | 声明式服务调用 |
| Hystrix | 客户端容错保护 |
| Zuul | API服务网关 |
Spring Cloud Alibaba
| 组件名称 | 作用 |
|---|---|
| Nacos | 服务注册中心 |
| Sentinel | 客户端容错保护 |
Spring Cloud原生及其他组件
| 组件名称 | 作用 |
|---|---|
| Consul | 服务注册中心 |
| Config | 分布式配置中心 |
| Gateway | API服务网关 |
| Sleuth/Zipkin | 分布式链路追踪 |
2.2.2 体系结构
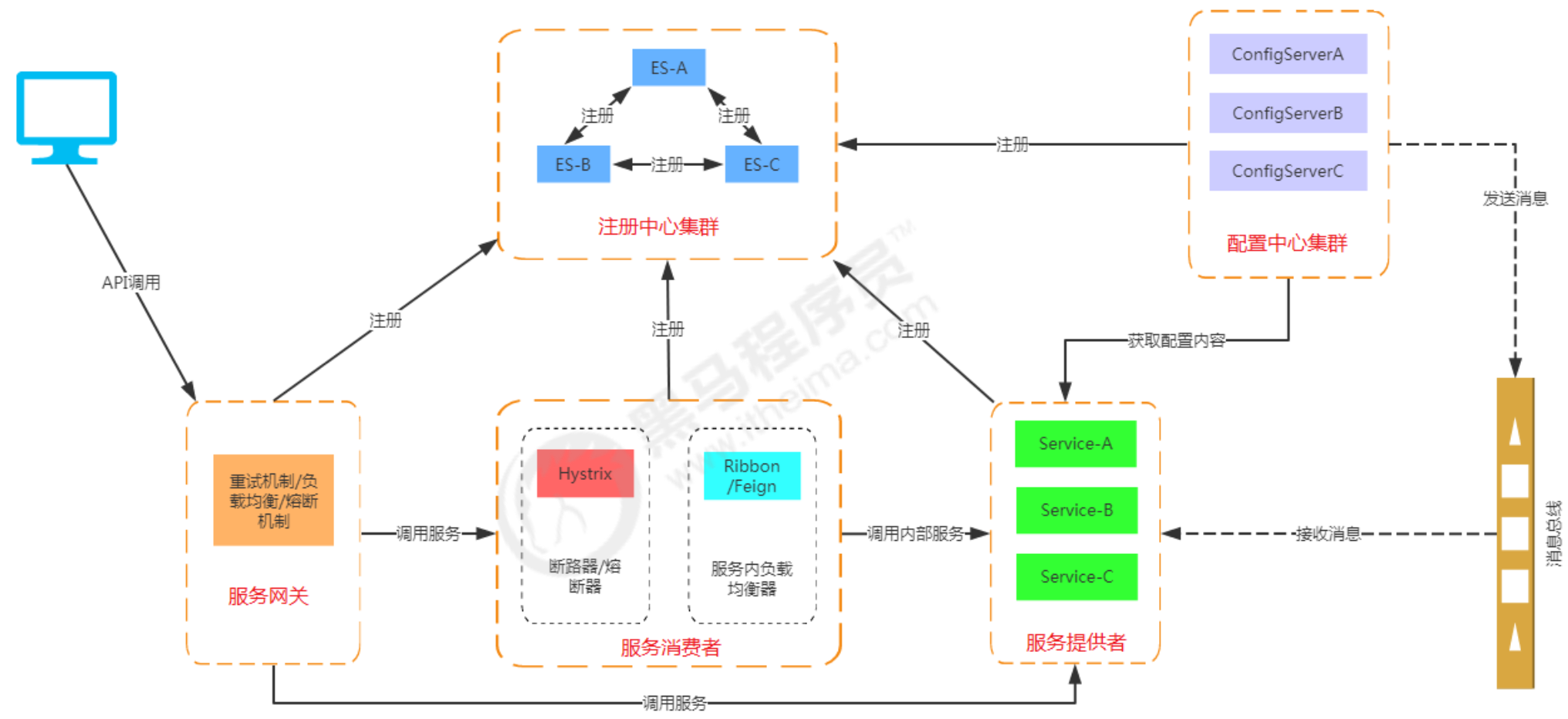
从上图可以看出Spring Cloud各个组件相互配合,合作支持了一套完整的微服务架构。
-
注册中心负责服务的注册与发现,很好将各服务连接起来
-
断路器负责监控服务之间的调用情况,连续多次失败进行熔断保护。
-
API网关负责转发所有对外的请求和服务
-
配置中心提供了统一的配置信息管理服务,可以实时的通知各个服务获取最新的配置信息
-
链路追踪技术可以将所有的请求数据记录下来,方便我们进行后续分析
-
各个组件又提供了功能完善的dashboard监控平台,可以方便的监控各组件的运行状况
3. 简单案例
操作系统:Mac OS
开发工具:IntelliJ IDEA
创建一个微服务,实现商品信息查询
3.1 创建项目
创建Maven空项目
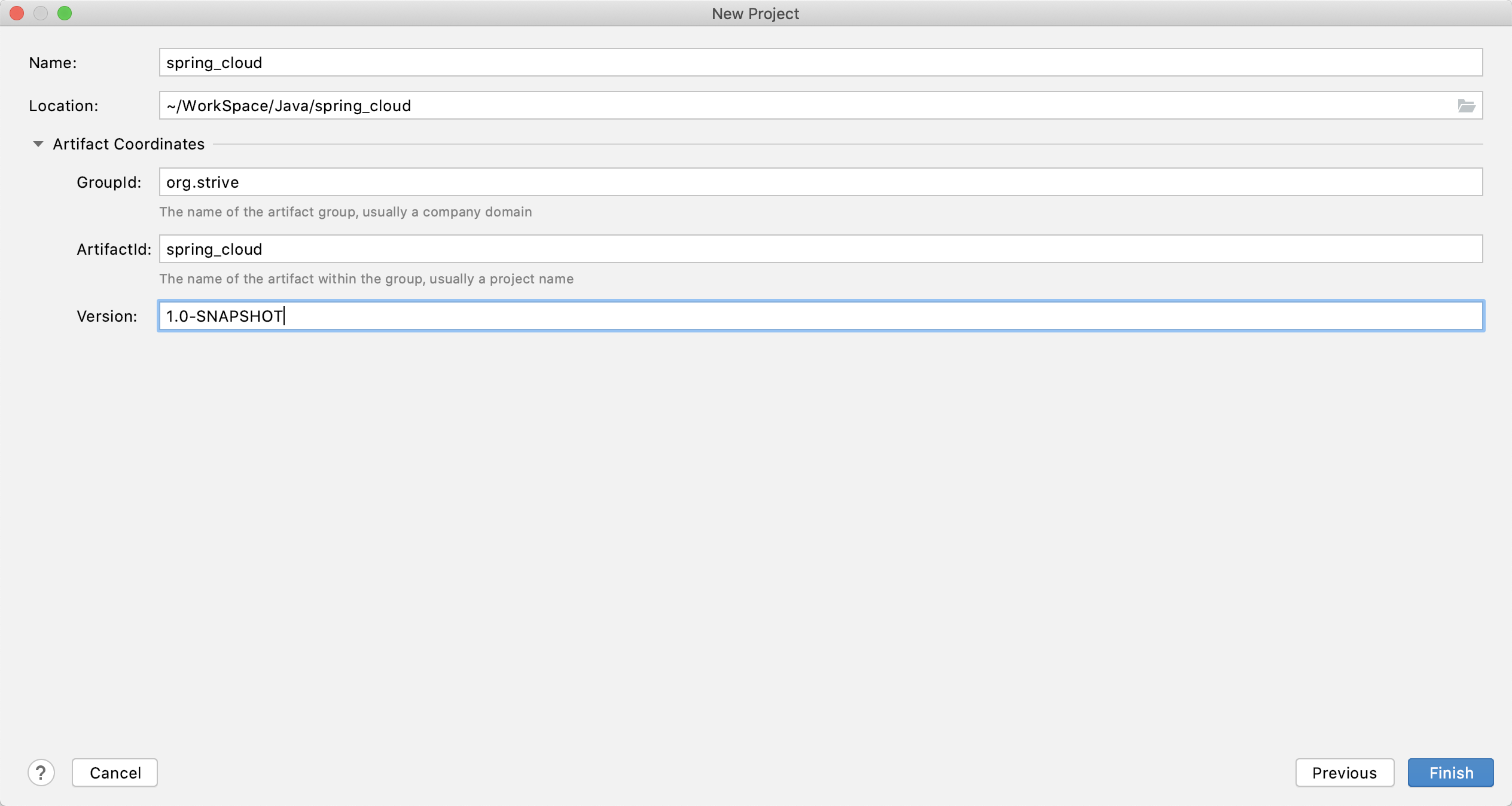
添加项目依赖
修改pom.xml,增加如下内容:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.2.RELEASE</version>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR7</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
3.2 创建商品子模块
创建maven子模块
我们这里的子模块,就是模拟一个微服务了
-
删除项目下的src文件夹
-
新建一个子模块:
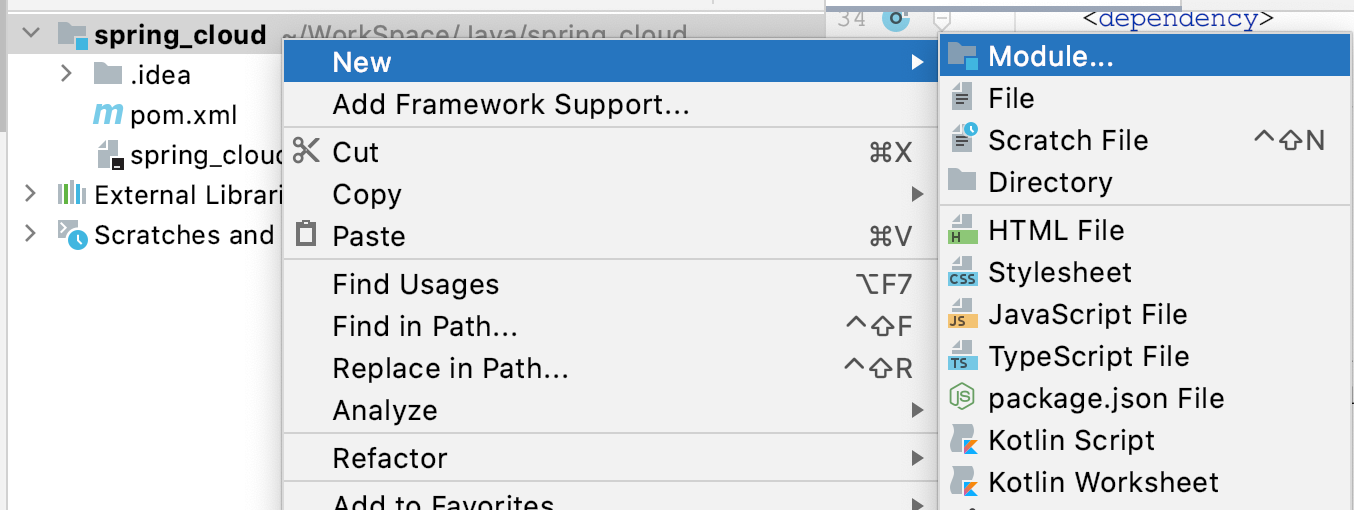
-
依然选择Maven类型
-
给子模块起个名字:
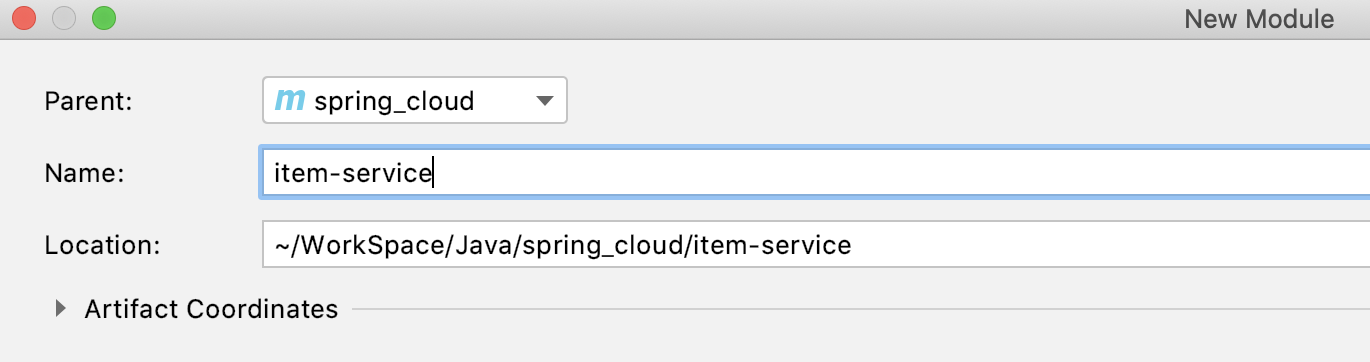
添加子模块依赖
本例使用mysql数据库,所以要引入其驱动包。
本例使用jpa演示查询,所以要引入jpa包
修改子模块pom.xml,添加如下配置:
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
</dependencies>
添加子模块配置
在子模块item-service的src/main/resources目录下,添加application.yml文件,内容:
server:
port: 9000
spring:
application:
name: item-service
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://server.strive.com:3306/test
username: root
password: root
jpa:
database: mysql
show-sql: true
open-in-view: true
这里配置了服务端口、服务应用名、数据库信息、jpa配置
3.3 商品服务代码开发
创建entity
我这里的数据库已有一张商品表:
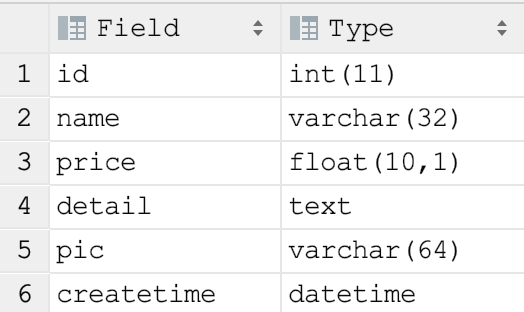
对应这些字段,创建实体类:
package com.strive;
import lombok.Data;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import java.util.Date;
@Entity
@Table(name = "items")
@Data
public class Item {
@Id
private Integer id;
private String name;
private Float price;
private String detail;
private String pic;
private Date createtime;
}
创建DAO
继承jpa的两个接口
package com.strive.dao;
import com.strive.entity.Item;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
public interface ItemDao extends JpaRepository<Item, Integer>, JpaSpecificationExecutor<Item> {
}
创建service
服务接口:
package com.strive.service;
import com.strive.entity.Item;
public interface ItemService {
Item findItemById(int id);
}
服务实现类:
package com.strive.service.impl;
import com.strive.dao.ItemDao;
import com.strive.entity.Item;
import com.strive.service.ItemService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ItemServiceImpl implements ItemService {
@Autowired
ItemDao itemDao;
@Override
public Item findItemById(int id) {
return itemDao.findById(id).get();
}
}
创建controller
package com.strive.controller;
import com.strive.entity.Item;
import com.strive.service.ItemService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("item")
public class ItemController {
@Autowired
ItemService itemService;
@RequestMapping("{id}")
public Item findItemById(@PathVariable int id) {
return itemService.findItemById(id);
}
}
创建启动类
package com.strive;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.domain.EntityScan;
@SpringBootApplication
@EntityScan("com.strive.entity")
public class ItemApplication {
public static void main(String[] args) {
SpringApplication.run(ItemApplication.class, args);
}
}
运行测试
-
运行子模块

-
输入地址,查询商品信息:

3.4 服务间调用
我们这里再创建一个订单服务,来调取前面的商品服务。
具体怎么什么调用呢?
RestTemplate
Spring框架提供的RestTemplate类可用于在应用中调用rest服务,它简化了与http服务的通信方式,统 一了RESTful的标准,封装了http链接, 我们只需要传入url及返回值类型即可。相较于之前常用的 HttpClient,RestTemplate是一种更优雅的调用RESTful服务的方式。
在Spring应用程序中访问第三方REST服务与使用Spring RestTemplate类有关。RestTemplate类的设计 原则与许多其他Spring 模板类(例如JdbcTemplate、JmsTemplate)相同,为执行复杂任务提供了一种具 有默认行为的简化方法。
RestTemplate默认依赖JDK提供http连接的能力(HttpURLConnection),如果有需要的话也可以通过 setRequestFactory方法替换为例如 Apache HttpComponents、Netty或OkHttp等其它HTTP library。
考虑到RestTemplate类是为调用REST服务而设计的,因此它的主要方法与REST的基础紧密相连就不足 为奇了,后者是HTTP协议的方法:HEAD、GET、POST、PUT、DELETE和OPTIONS。例如, RestTemplate类具有headForHeaders()、getForObject()、postForObject()、put()和delete()等方法。

创建订单服务
仿效商品服务,创建订单服务。
创建商品子模块
具体不贴图了,参照商品服务
添加配置
这里只配置端口、服务名:
server:
port: 8000
spring:
application:
name: order-service
创建实体类
这里要调用商品服务,获取商品信息,需要创建商品类:
package com.strive.entity;
import lombok.Data;
import java.util.Date;
@Data
public class Item {
private Integer id;
private String name;
private Float price;
private String detail;
private String pic;
private Date createtime;
}
这里只需承接结果,所以不用绑定表名、注册为entity了。
但是@Data还是要的,需要修改对象属性值。
创建启动类
package com.strive;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
public class OrderApplication {
@Bean
RestTemplate getRestTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class);
}
}
我们在启动类里,注册一个RestTemplate对象。
创建控制器
package com.strive.controller;
import com.strive.entity.Item;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
@RequestMapping("order")
public class OrderController {
@Autowired
RestTemplate restTemplate;
@RequestMapping("purchase/{id}")
public Item findItemById(@PathVariable int id) {
return restTemplate.getForObject("http://localhost:9000/item/" + id, Item.class);
}
}
这里注入RestTemplate对象,通过他调用商品服务。
就是简单的拼了个访问url,指定返回对象类型。
测试
-
运行订单服务

-
地址栏输入请求url:

4. Eureka
4.1 概述
上面案例中,服务调用的代码,有硬编码,访问的商品服务url是写死了的。
那么,为了优化设计,方便维护,就有了服务注册中心。
注册中心
注册中心可以说是微服务架构中的”通讯录“,它记录了服务和服务地址的映射关系。
在分布式架构中, 服务会注册到这里,当一个服务需要调用其它服务时,就这里找到服务的地址,进行调用。
主要作用
-
服务发现:
- 服务注册/反注册:保存服务提供者和服务调用者的信息
- 服务订阅/取消订阅:服务调用者订阅服务提供者的信息,最好有实时推送的功能
- 服务路由(可选):具有筛选整合服务提供者的能力。
-
服务配置:
-
配置订阅:服务提供者和服务调用者订阅微服务相关的配置
-
配置下发:主动将配置推送给服务提供者和服务调用者
-
-
服务健康检测
- 检测服务提供者的健康情况
常见注册中心
-
Zookeeper
zookeeper它是一个分布式服务框架,是Apache Hadoop 的一个子项目。
它主要是用来解决分布式应 用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项 的管理等。
简单来说zookeeper=文件系统+监听通知机制。
-
Eureka
Eureka是在Java语言上,基于Restful Api开发的服务注册与发现组件,Springcloud Netflix中的重要组 件
-
Consul
Consul是由HashiCorp基于Go语言开发的支持多数据中心分布式高可用的服务发布和注册服务软件, 采用Raft算法保证服务的一致性,且支持健康检查。
-
Nacos
Nacos是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
简单来说 Nacos 就是 注册中心 + 配置中心的组合,提供简单易用的特性集,帮助我们解决微服务开发必会涉及到的服务注册 与发现,服务配置,服务管理等问题。
Nacos 还是 Spring Cloud Alibaba 组件之一,负责服务注册与发现。
最后我们通过一张表格大致了解Eureka、Consul、Zookeeper的异同点。选择什么类型的服务注册与 发现组件可以根据自身项目要求决定。
| 组件名 | 语言 | CAP | 一致性算法 | 服务健康检查 | 对外暴露接口 |
|---|---|---|---|---|---|
| Eureka | Java | AP | 无 | 可配置 | HTTP |
| Consul | Go | CP | Raft | 支持 | HTTP/DNS |
| Zookeeper | Java | CP | Paxos | 支持 | 客户端 |
| Nacos | Java | AP | Raft | 支持 | HTTP |
Eureka
基础知识
Eureka是Netflix开发的服务发现框架,SpringCloud将它集成在自己的子项目spring-cloud-netflix中, 实现SpringCloud的服务发现功能。
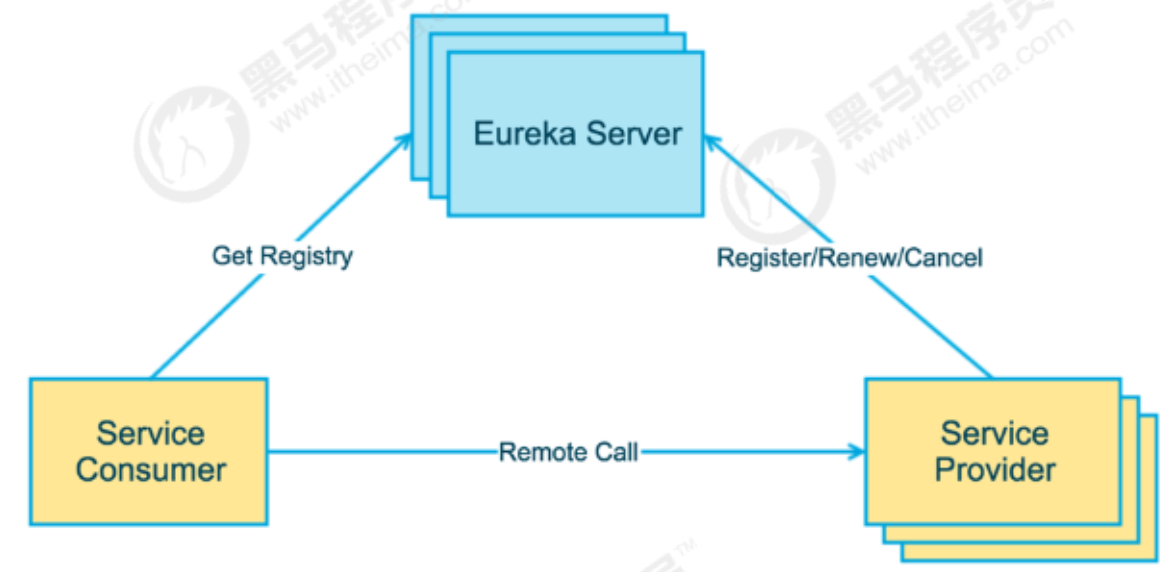
上图简要描述了Eureka的基本架构,由3个角色组成:
-
Eureka Server
- 提供服务注册和发现
-
Service Provider
-
服务提供方
-
将自身服务注册到Eureka,从而使服务消费方能够找到
-
-
Service Consumer
-
服务消费方
-
从Eureka获取注册服务列表,从而能够消费服务
-
4.2 搭建注册中心
创建Eureka子模块
和前面的子模块创建流程一致
添加依赖
这里要添加Eureka作为服务端(server)的依赖包:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
添加配置
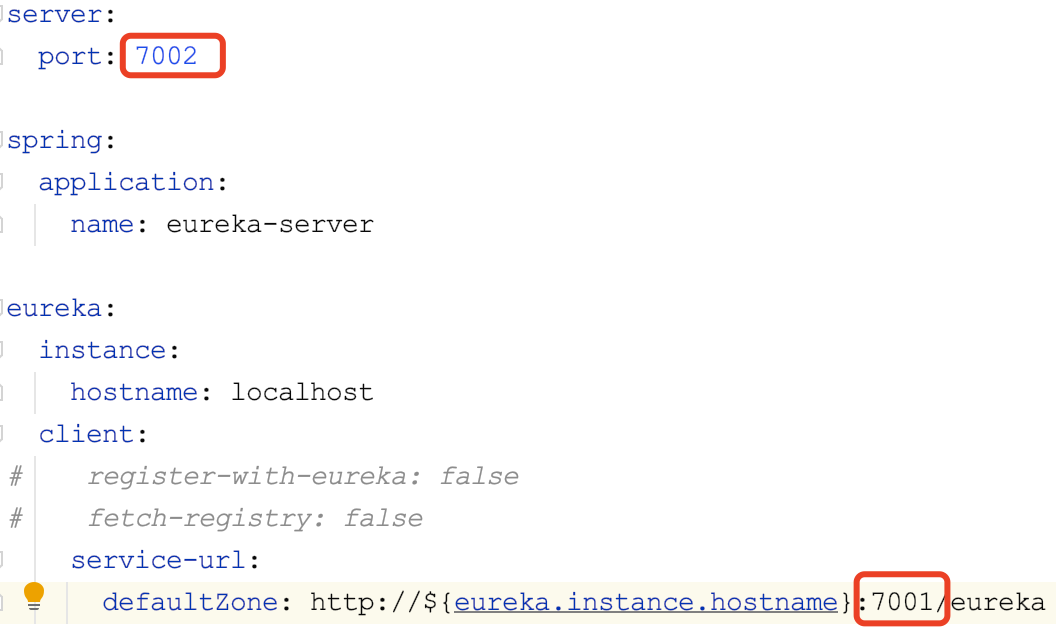
创建src/resources/application.yml:
server:
port: 7001
spring:
application:
name: eureka-server
eureka:
instance:
hostname: localhost
client:
register-with-eureka: false #不注册到eureka
fetch-registry: false #不从eureka获取注册信息
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka
主要是添加eureka的相关配置。
本服务是eureka注册中心,不向自己注册,也不从自身获取注册的信息。
创建启动类
package com.strive;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}
这里主要添加@EnableEurekaServer,将本服务标识为Eureka的注册中心
测试
-
运行启动类
-
地址栏输入对应url:
4.3 注册服务到注册中心
我们将前面的商品服务、订单服务,都注册到Eureka注册中心去。
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
添加配置
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka
instance:
prefer-ip-address: true
测试
-
重启item-service、order-service
-
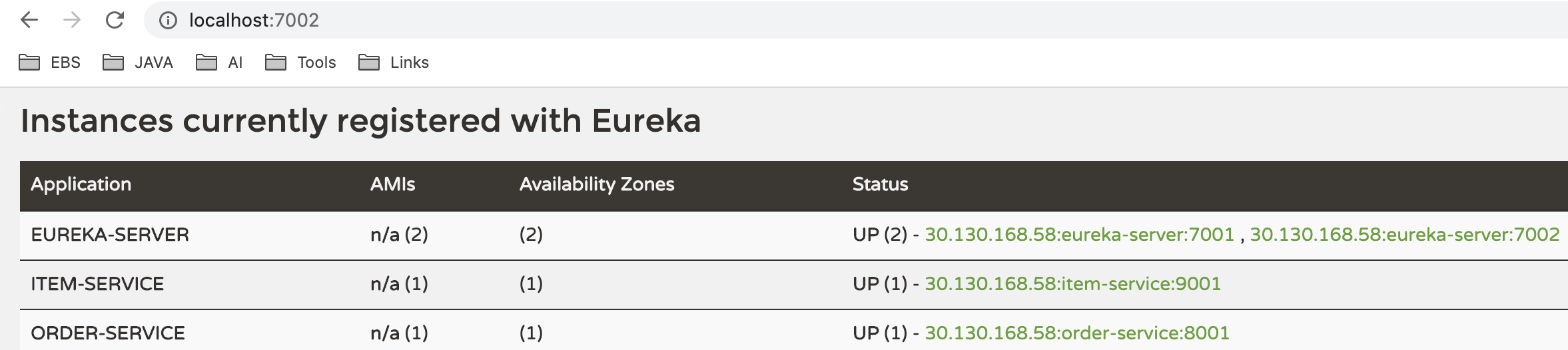
查看eureka:
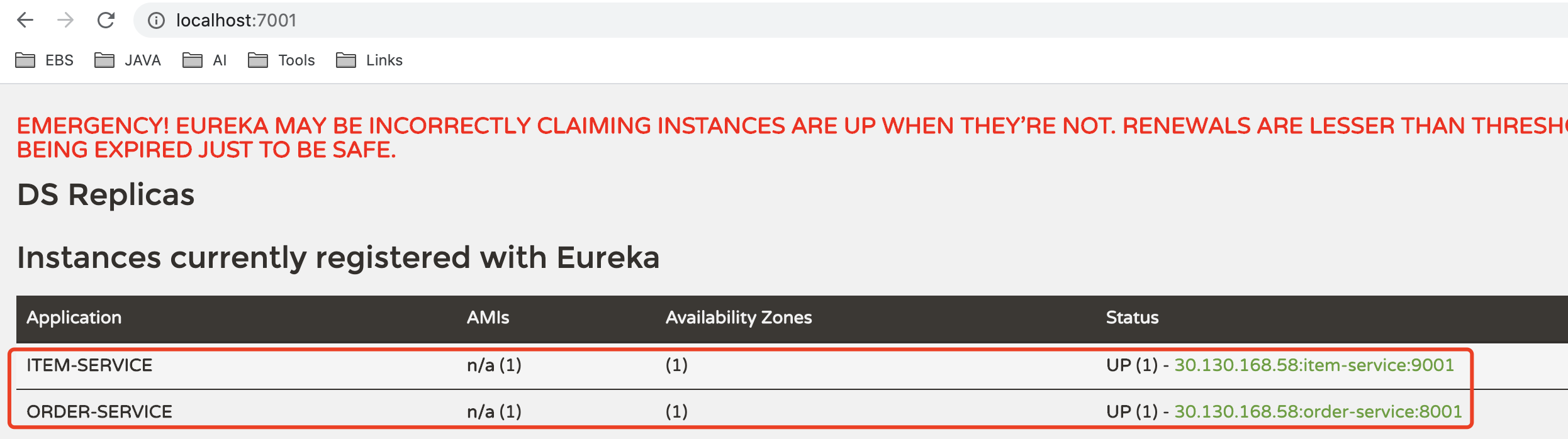
可以在eureka-server中,看到刚刚注册的两个服务了!
4.4 自我保护
微服务第一次注册成功之后,每30秒会发送一次心跳将服务的实例信息注册到注册中心,通知Eureka Server该实例仍然存在。
如果超过90秒没有发送更新,则server将从注册信息中将此服务移除。
Eureka Server在运行期间,会统计心跳失败的比例在15分钟之内是否低于85%。
如果出现低于的情况 (在单机调试的时候很容易满足,实际在生产环境上通常是由于网络不稳定导致),Eureka Server会进入保护模式,不再删除服务注册表中的数据(也就是不会注销任何微服务)。
自我保护机制开启后,并不会马上呈现到web上,而是默认需等待 5 分钟(可以通过
eureka.server.wait-time-in-ms-when-sync-empty 配置),即 5 分钟后你会看到上图中红色的提示信息。
保护模式主要用于一组客户端和Eureka Server 之间存在网络分区场景下的保护。
通过设置 eureka.server.enableSelfPreservation=false ,可以关闭自我保护功能
4.5 元数据
分类
-
标准元数据:
主机名、IP地址、端口号、状态页和健康检查等信息,都会被发布在服务注册表中,用于服务之间的调用。
-
自定义元数据:
可以使用eureka.instance.metadata-map配置,符合KEY/VALUE的存储格式。
这些元数据可以在远程客户端中访问
DiscoveryClient
可以通过DiscoveryClient类,获取元数据,从而动态拼接请求url。
修改订单服务:
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-commons</artifactId>
</dependency>
修改控制器
@Autowired
private DiscoveryClient discoveryClient;
@RequestMapping("purchase/{id}")
public Item findItemById(@PathVariable int id) {
List<ServiceInstance> instances = discoveryClient.getInstances("item-service");
ServiceInstance instance = instances.get(0);
return restTemplate.getForObject("http://" + instance.getHost() + ":" + instance.getPort() + "/item/" + id, Item.class);
//return restTemplate.getForObject("http://localhost:9000/item/" + id, Item.class);
}
这里根据应用名item-service获取对应元数据信息。
返回的是个集合,因为同一名称的微服务,可以有多个节点,提高可用性。
我们这里就1个,直接获取第一个即可。
4.6 集群
概述
在前面案例中,我们实现了单节点Eureka Server的服务注册与服务发现功能。
Eureka Client会定时连接 Eureka Server,获取注册表中的信息并缓存到本地。微服务在消费远程API时总是使用本地缓存中的数据。
因此一般来说,即使Eureka Server发生宕机,也不会影响到服务之间的调用。但如果Eureka Server宕机时,某些微服务也出现了不可用的情况,Eureka Server中的缓存若不被刷新,就可能会影 响到微服务的调用,甚至影响到整个应用系统的高可用。
因此,在生成环境中,通常会部署一个高可用 的Eureka Server集群。
Eureka Server可以通过运行多个实例并相互注册的方式实现高可用部署,Eureka Server实例会彼此增 量地同步信息,从而确保所有节点数据一致。事实上,节点之间相互注册是Eureka Server的默认行为。
搭建集群
- 修改eureka-server的application.yml:
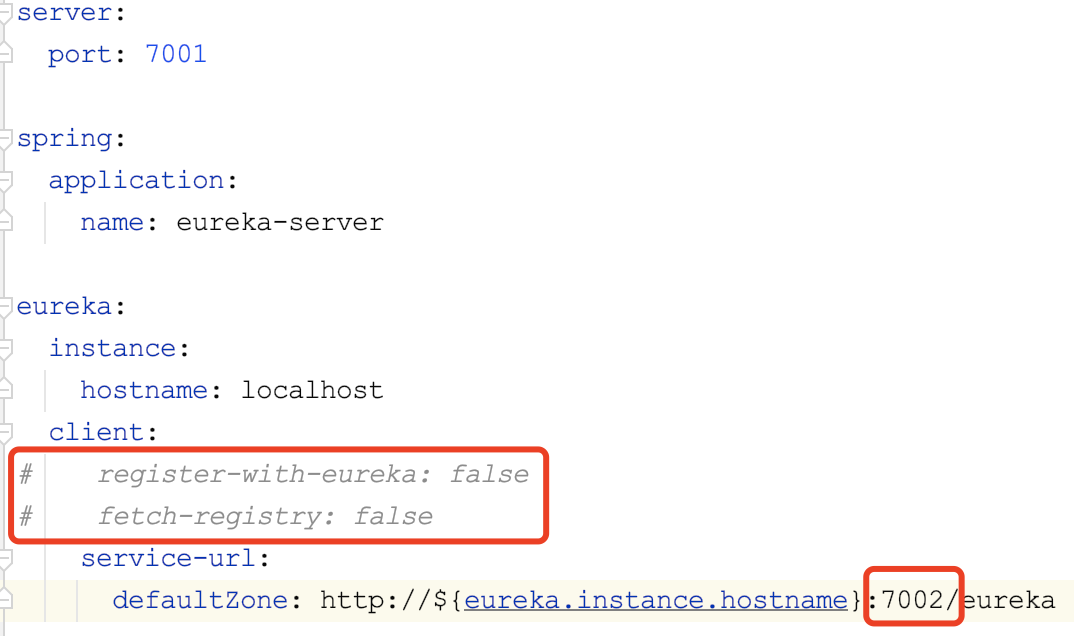
注释掉regist的配置。因为集群中,一个server要同步其他sever的信息,就需要相互注册信息了。
service-url的端口,不再和本服务同端,而是另一个server的端口,这里先设为7002.
重新运行当前eureka-server
-
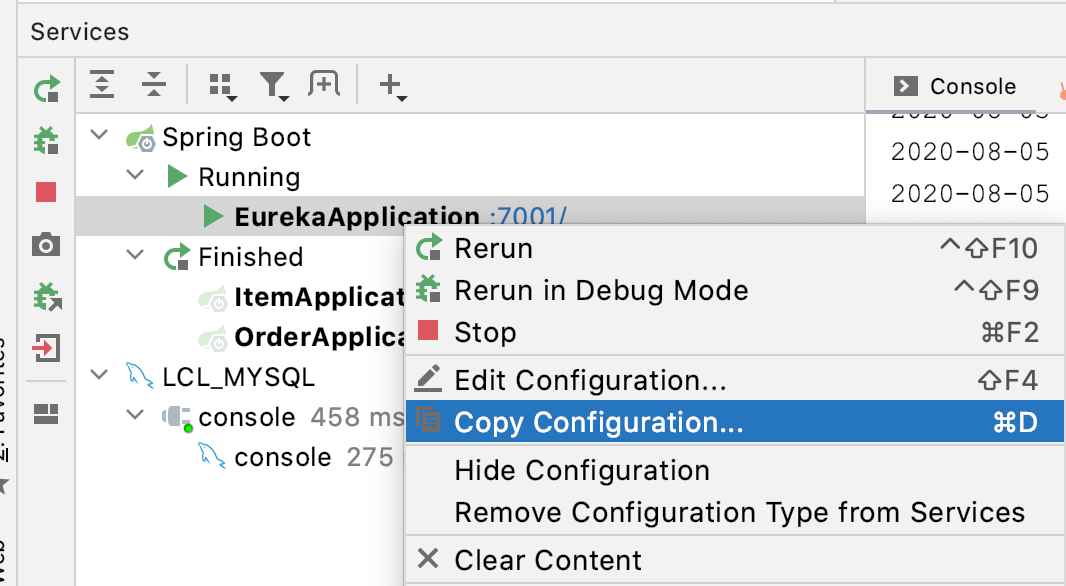
等前面一个server在运行时,再修改application.yml,将上下两个端口的位置调换下:
搭建一个新的server,端口为7002,并绑定前一个sever的url(7001)
然后复制7001:
这里可以重命名下,或者保持默认,直接确定
-
运行新的服务7002
-
等到2个服务都启动好后,浏览器中查看状态:

注册服务到集群
很简单,在微服务的application.yml中,配置新的server地址即可:

重启两个微服务,再次查看server:
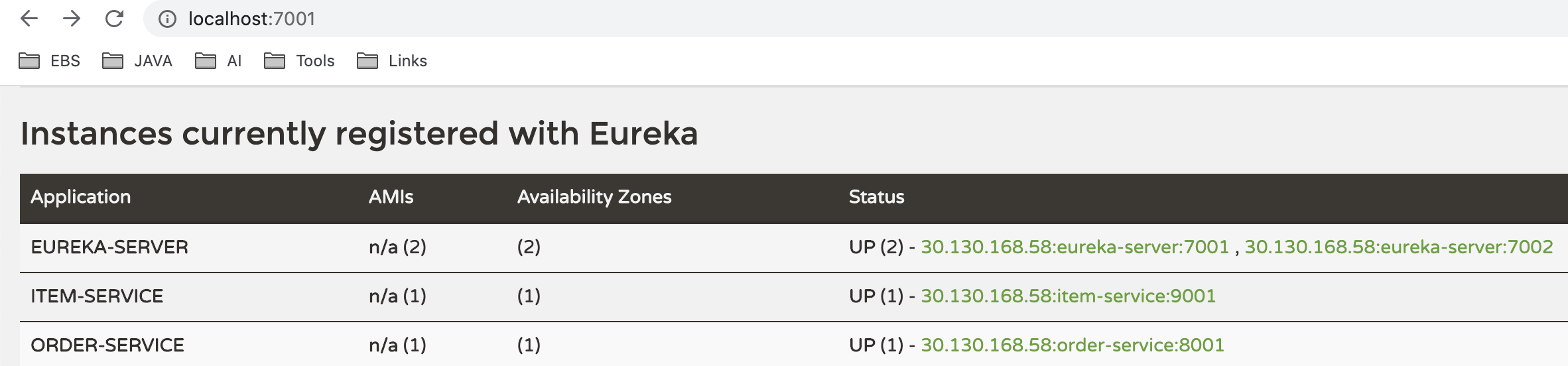
5. Ribbon
5.1 概述
啥是Ribbon
Netflix发布的一个负载均衡器,有助于控制 HTTP 和 TCP客户端行为。
在 SpringCloud 中, Eureka一般配合Ribbon进行使用,Ribbon提供了客户端负载均衡的功能,Ribbon利用从Eureka中读取到的服务信息,在调用服务节点提供的服务时,会合理的进行负载。
在SpringCloud中可以将注册中心和Ribbon配合使用,Ribbon自动的从注册中心中获取服务提供者的 列表信息,并基于内置的负载均衡算法,请求服务
作用
-
服务调用
基于Ribbon实现服务调用, 是通过拉取到的所有服务列表组成(服务名-请求路径的)映射关系。
借助RestTemplate 最终进行调用
-
负载均衡
当有多个服务提供者时,Ribbon可以根据负载均衡的算法自动的选择需要调用的服务地址
5.2 使用Ribbon
SpringCloud的服务发现jar包中,已包含Ribbon,不需额外添加依赖
修改商品服务
修改商品服务的控制器,使输出的内容中,显示被调用的服务地址:

修改订单服务
修改启动类

添加注解@LoadBalanced,使RestTemplate支持负载均衡
修改控制器
前面的案例中,是获取的商品服务实例的第一个,进行调用。
这样肯定测不出负载均衡的效果,因为一直调用固定的请求url。
我们这里修改下调用代码:
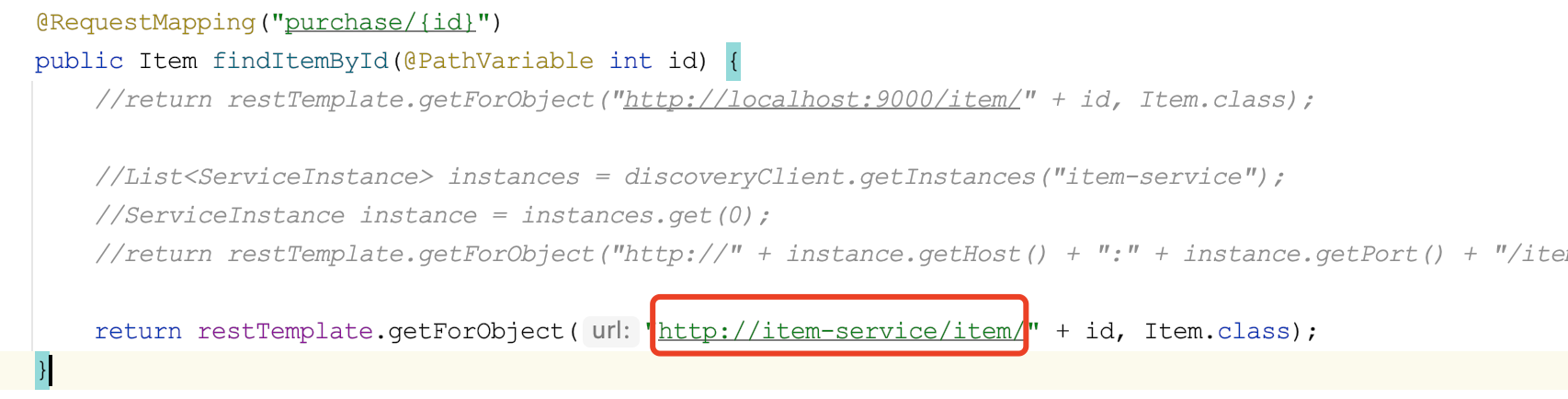
这里的域名,给成服务名。
测试
这里模仿前面Eureka集群的方法,复制出来一个item-service,端口改到9002,并运行。
然后通过订单服务调用:


5.3 进阶
负载均衡策略
Ribbon内置了多种负载均衡策略,最上层接口为com.netflix.loadbalancer.IRule ,实现关系为:
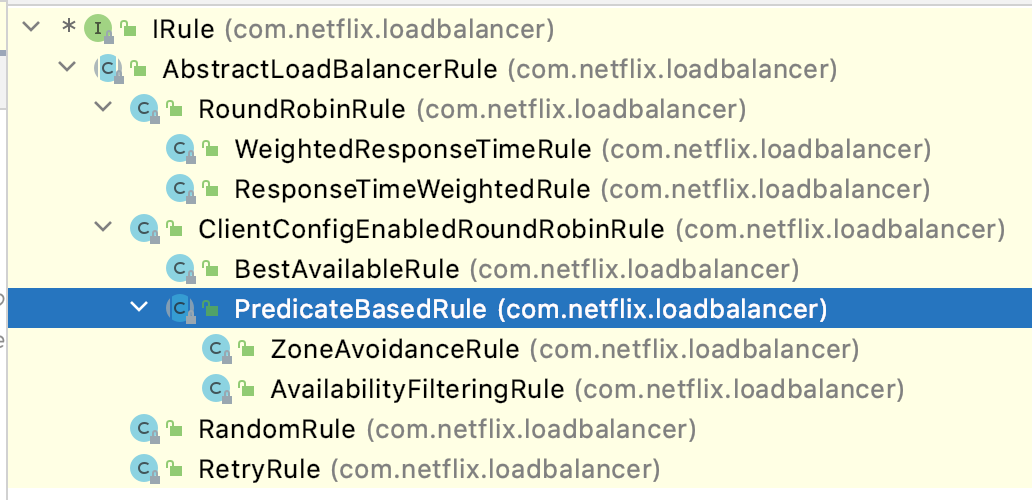
- com.netflix.loadbalancer.RoundRobinRule :以轮询的方式进行负载均衡
- com.netflix.loadbalancer.WeightedResponseTimeRule :权重策略。会计算每个服务的权重,越高的被调用的可能性越大
- com.netflix.loadbalancer.RandomRule :随机策略
- com.netflix.loadbalancer.RetryRule :重试策略
- com.netflix.loadbalancer.BestAvailableRule :最佳策略。遍历所有的服务实例,过滤掉故障实例,并返回请求数最小的实例返回。
- com.netflix.loadbalancer.AvailabilityFilteringRule :可用过滤策略。过滤掉故障和请求数超过阈值的服务实例,再从剩下的实例中轮询调用。
比较常用的是前两个。
轮询方式,是默认的策略,按顺序挨个调用微服务节点。
如果各节点服务器的配置不均衡,可以使用权重策略,对性能强的服务器,设置高权重,提高调用率。
6. Consul
6.1 概述
Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。
与其它分布式服务注册与发现的方案相比,Consul 的方案更“一站式”,内置了服务注册与发现框架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其它工具(比如 ZooKeeper 等)。 使用起来也较为简单。
Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和 Mac OS X);安装包仅包含一个可执行文件,方便部署,与 Docker 等轻量级容器可无缝配合
优势
-
使用 Raft 算法来保证一致性, 比复杂的 Paxos 算法更直接.
zookeeper 采用的是 Paxos, etcd 使用的也是 Raft。 -
支持多数据中心,内外网的服务采用不同的端口进行监听。
多数据中心集群可以避免单数据中心的单点故障,而其部署则需要考虑网络延迟, 分片等情况等。
zookeeper 和 etcd 均不提供多数据中 心功能的支持。
-
支持健康检查。 etcd 不提供此功能。
-
支持 http 和 dns 协议接口。
zookeeper 的集成较为复杂, etcd 只支持 http 协议
-
官方提供 web 管理界面, etcd 无此功能。
综合比较, Consul 作为服务注册和配置管理的新星, 比较值得关注和研究
特性
- 服务发现
- 健康检查
- Key/Value 存储
- 多数据中心
比对Eureka
-
一致性
-
Consul强一致性(CP)
- 服务注册相比Eureka会稍慢一些。因为Consul的raft协议要求必须过半数的节点都写入成功才认为注册成功
- Leader挂掉时,重新选举期间整个consul不可用。保证了强一致性但牺牲了可用性
-
Eureka保证高可用和最终一致性(AP)
- 服务注册相对要快,因为不需要等注册信息replicate到其他节点,也不保证注册信息是否replicate成功
- 当数据出现不一致时,虽然A, B上的注册信息不完全相同,但每个Eureka节点依然能够正常对外提供服务,这会出现查询服务信息时如果请求A查不到,但请求B就能查到。如此保证了可用性但牺牲了一致性
-
-
开发语言与使用
eureka就是个servlet程序,跑在servlet容器中
Consul则是go编写而成,安装启动即可
6.2 使用
安装
- 到Consul 官网下载对应平台的安装包即可。
-
这里以Mac OS为例,下载的是个压缩包,解压后,就是可执行的命令文件:
运行
-
打开终端,切到consul所在目录
-
运行命令,启动consul:
./consul agent -dev -client=0.0.0.0
-
打开浏览器,输入网址:http://localhost:8500/:
可以看到,consul正常运行了。
注册服务到Consul
我们这里复制前面的商品服务、订单服务,不过要修改关于Eureka的部分
修改pom.xml
去掉eureka-client依赖,添加consul依赖:
<!--spring提供的consul服务发现-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>
<!--心跳检查-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
修改application.yml
去掉原来的eureka配置,在spring节点下,添加consul配置:
spring:
application:
...(省略)
cloud:
consul:
host: localhost
port: 8500
discovery:
register: true #是否注册
instance-id: ${spring.application.name}-${server.port} #实例ID
service-name: ${spring.application.name} #服务名
port: ${server.port} #服务端口
health-check-path: /actuator/health #健康检查路径
health-check-interval: 15s #健康检查间隔时间
prefer-ip-address: true
ip-address: ${spring.cloud.client.ip-address}
测试
至此可以运行两个服务了,其他程序与前面Eureka中一致。

集群
和Eureka一样,Consul也可以搭建集群,实现高可用。
因为Consul是命令行运行的,我这里搭了3个Centos虚拟机,IP分别为172.16.134.141/142/143,用来运行server。
安装
-
下载好Linux版本安装包,上传到虚拟机,或者直接在虚拟机用wget命令下载
-
解压
unzip -q consul_1.8.0_linux_amd64.zip
-
将解压后命令文件,移至$PATH包含的路径下
mv consul /usr/bin/
运行
-
执行命令:
consul -agent -server -bootstrap-expect 3 -data-dir /etc/consul.d -node=server-3 -bind=172.16.135.141 -ui -client 0.0.0.0 &
-
其他虚拟机重复上述操作
注意运行命令中的ip地址,要对应各虚拟机自己的ip;node值,也区分下
-
本地运行consul:
./consul agent -bind=172.16.135.1 -client=0.0.0.0 -data-dir /Users/startong/Downloads/consul.d -node=client-1
加入集群
-
在某个server(如172.16.135.143)外的其他服务器上,包括本地,运行命令:
consul join 172.16.135.143
-
在服务器上运行命令查看集群成员:
consul members

-
或者登陆任一server网址:
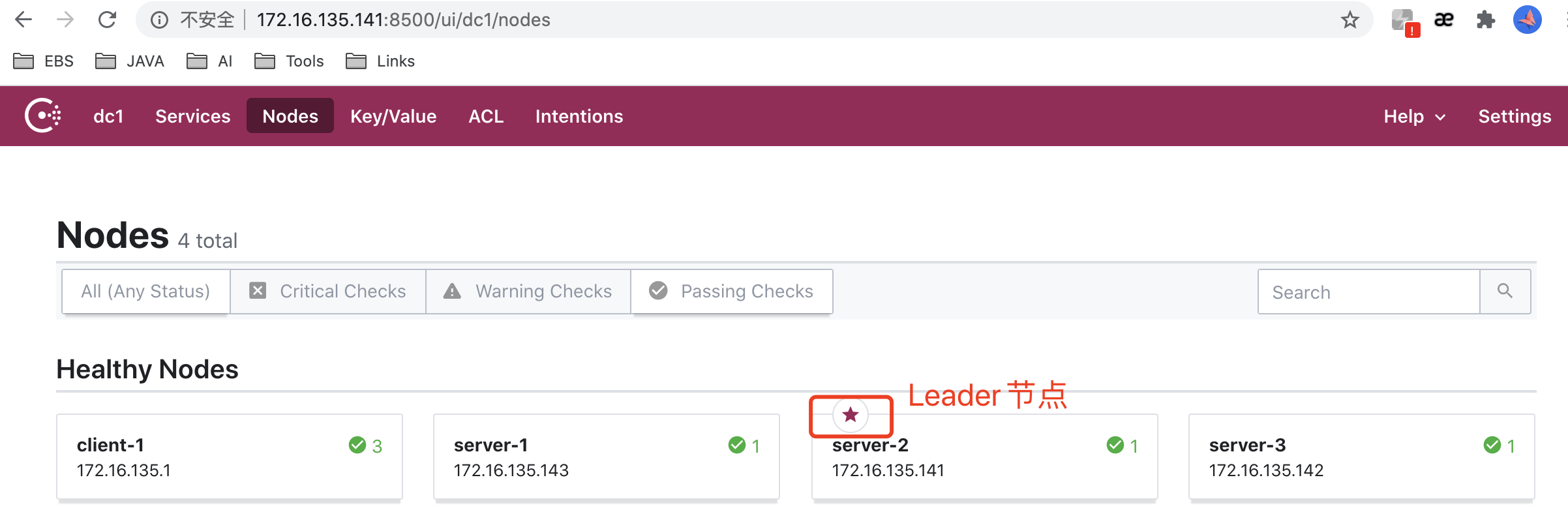
测试
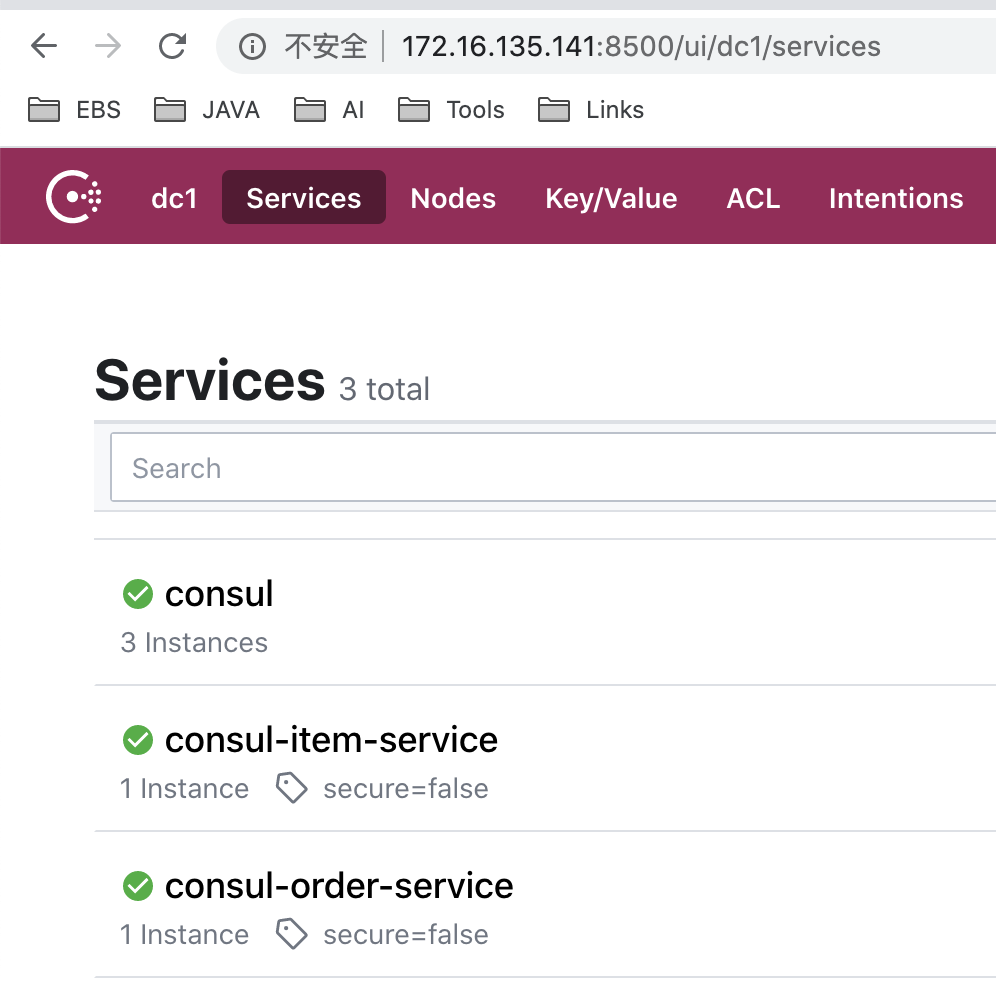
重新运行服务consul-item-service、consul-order-service。
因为client运行在本地,所以不需变更任何配置。
7. Feign
前面订单服务,使用RestTemplate远程调用商品服务的时候,调用url中的参数是手动拼接的。
当参数很多的时候,这种手动方式就比较痛苦了。
有没有什么优化的方法呢?
Feign!
7.1 概述
Feign是Netflix开发的声明式,模板化的HTTP客户端,其灵感来自Retrofit,JAXRS-2.0以及WebSocket.
Feign可帮助我们更加便捷,优雅的调用HTTP API。 在SpringCloud中,使用Feign非常简单——创建一个接口,并在接口上添加一些注解,代码就完 成了。
Feign支持多种注解,例如Feign自带的注解或者JAX-RS注解等。
SpringCloud对Feign进行了增强,使Feign支持了SpringMVC注解,并整合了Ribbon和Eureka, 从而让Feign的使用更加方便
7.2 使用
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
启用Feign
启动类上增加注解@EnableFeignClients

创建接口
package com.strive.feign;
import com.strive.entity.Item;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
@FeignClient("item-service")
public interface OrderFeign {
@RequestMapping("item/{id}")
Item findItemById(@PathVariable int id);
}
接口使用注解@FeignClient,指定调用的服务名。
创建一个方法,路径指向被调用服务的url
修改控制器
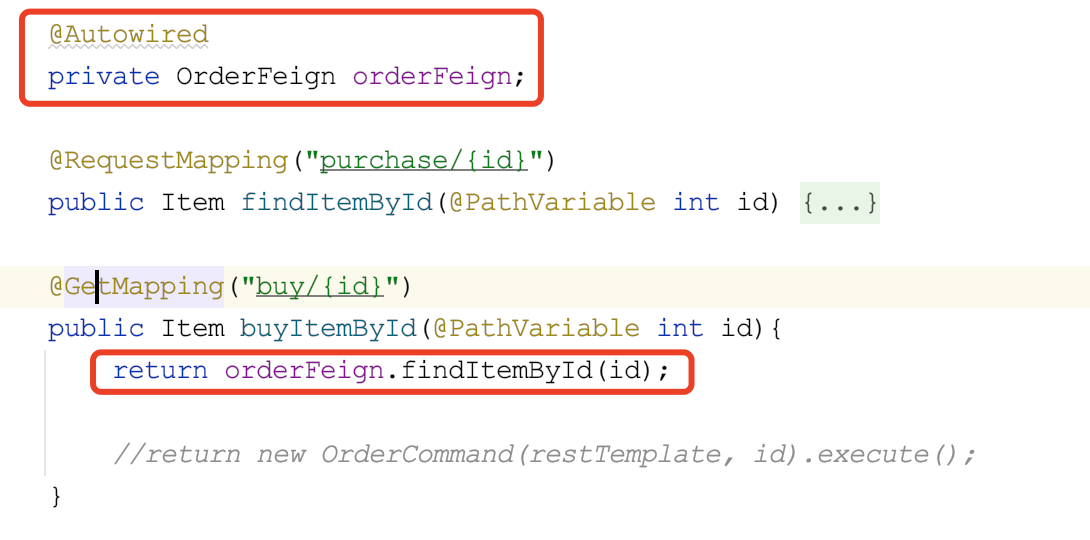
增加自动注入feign接口,然后在具体的方法中,调用它即可。
7.3 负载均衡
Feign中本身已经集成了Ribbon依赖和自动配置,因此我们不需要额外引入依赖,也不需要再注册 RestTemplate 对象,直接调用对应服务即可自动实现负载均衡。
Ribbon是一个基于 HTTP 和 TCP 客户端 的负载均衡的工具。它可以 在客户端 配置RibbonServerList(服务端列表),使用 HttpClient 或 RestTemplate 模拟http请求,步骤相当繁琐。
Feign 是在 Ribbon的基础上进行了一次改进,是一个使用起来更加方便的 HTTP 客户端。采用接口的 方式, 只需要创建一个接口,然后在上面添加注解即可 ,将需要调用的其他服务的方法定义成抽象方 法即可, 不需要自己构建http请求。然后就像是调用自身工程的方法调用,而感觉不到是调用远程方 法,使得编写客户端变得非常容易
8. Hystrix
8.1 概述
雪崩效应
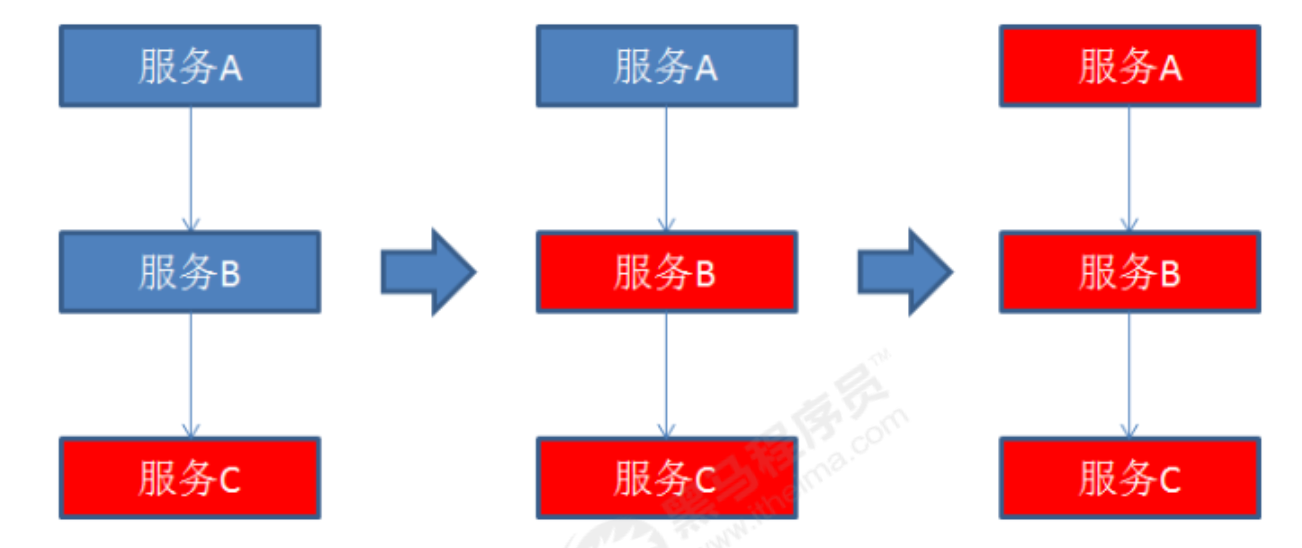
在微服务架构中,一个请求需要调用多个服务是非常常见的。
如客户端访问A服务,而A服务需要调用B 服务,B服务需要调用C服务,由于网络原因或者自身的原因,如果B服务或者C服务不能及时响应,A服 务将处于阻塞状态,直到B服务C服务响应。
此时若有大量的请求涌入,容器的线程资源会被消耗完毕,导致服务瘫痪。
服务与服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难 性的严重后果,这就是服务故障的“雪崩”效应。
雪崩是系统中的蝴蝶效应导致其发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方法响应变慢,亦或是某台机器的资源耗尽。
从源头上我们无法完全杜绝雪崩源头的发生,但是雪崩的根本原因来源于服务之间的强依赖,所以我们可以提前评估,做好熔断,隔离,限流
服务隔离
顾名思义,它是指将系统按照一定的原则划分为若干个服务模块,各个模块之间相对独立,无强依赖。 当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不波及其它模块,不影响整体 的系统服务
熔断降级
熔断这一概念来源于电子工程中的断路器(Circuit Breaker)。
在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断
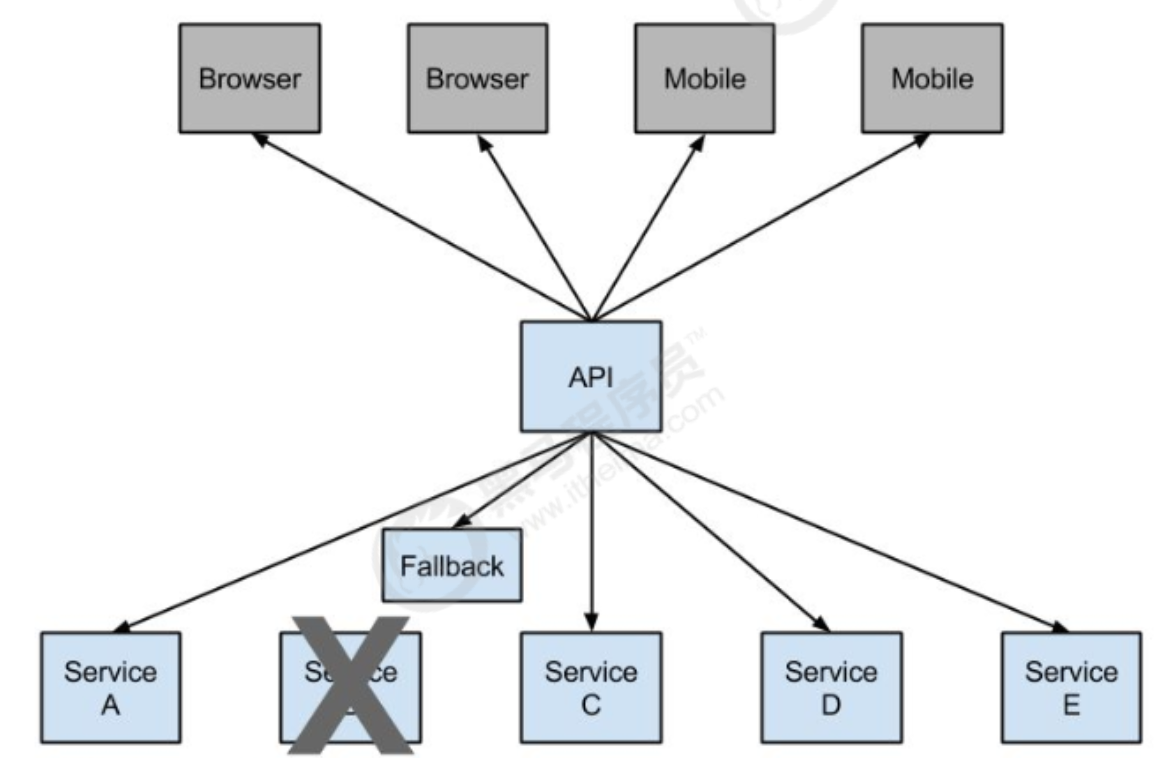
所谓降级,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的 fallback回调方法,返回一个缺省值。 也可以理解为兜底
服务限流
限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量,以达到保护系统的目的。
一般来说系统的吞吐量是可以被测算的,为了保证系统的稳固运行,一旦达到的需要限制的阈值,就需要限制流量,并采取少量措施以完成限制流量的目的。比方:推迟解决,拒绝解决,或者者部分拒绝解决等等
8.2 入门案例
模拟高并发
我们这里,模拟下高并发的问题场景:
- 延长商品服务的处理时间;
- 增加一个新的订单服务请求方法A
- 修改服务器线程上限
- 使用jmeter工具,多线程频繁调用订单服务的/order/purchase/{id},使服务线程耗尽
- 调用方法A,查看响应时间
修改控制器
- 在商品服务下,增加线程等待代码,延长处理时间:

-
在订单服务下,增加一个请求处理方法,直接返回固定字符串
@GetMapping public String testOrder() { System.out.println(Thread.currentThread().getName()); return "一笔订单"; }
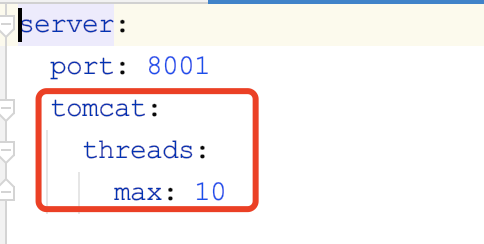
修改配置
修改订单服务的application.yml,增加线程上限:
配置jmeter
概述
Apache JMeter是Apache组织开发的基于Java的压力测试工具。
用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。
它可以用于测试静态和动态资源,例如静态文件、 Java 小服务程序、CGI 脚本、Java 对象、数据库、FTP 服务器,等等。
JMeter 可以用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能。
另外JMeter能够对应 用程序做功能/回归测试,通过创建带有断言的脚本来验证你的程序返回了你期望的结果。为了最大限度的灵活性,JMeter允许使用正则表达式创建断言
下载
直接到官网下载即可:
https://jmeter.apache.org/download_jmeter.cgi
运行
解压即可,在解压目录下有运行程序:bin/jmeter,双击即可启动
配置
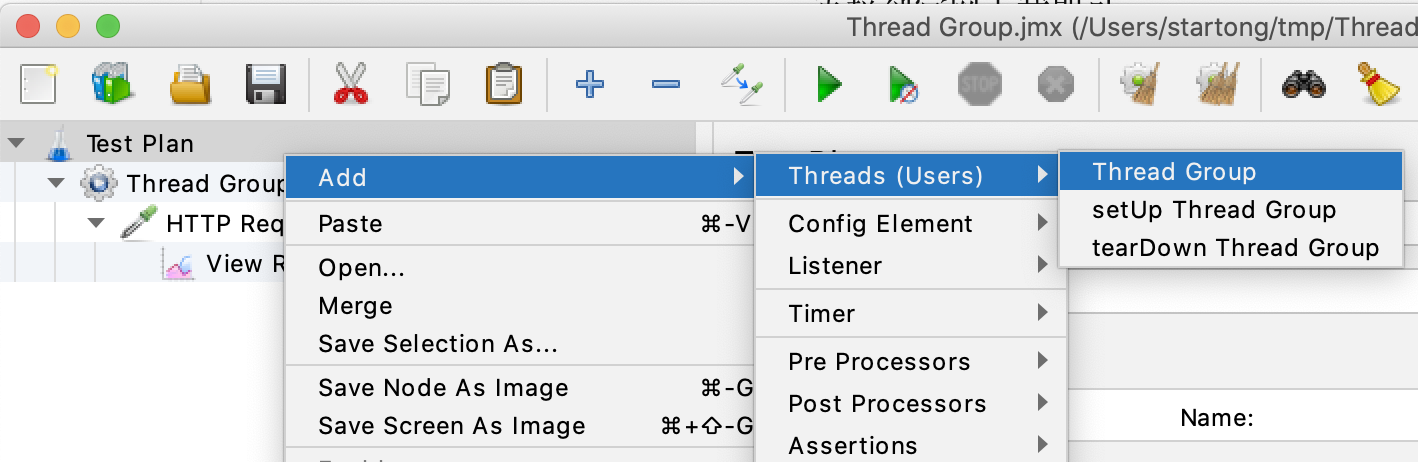
-
创建线程组
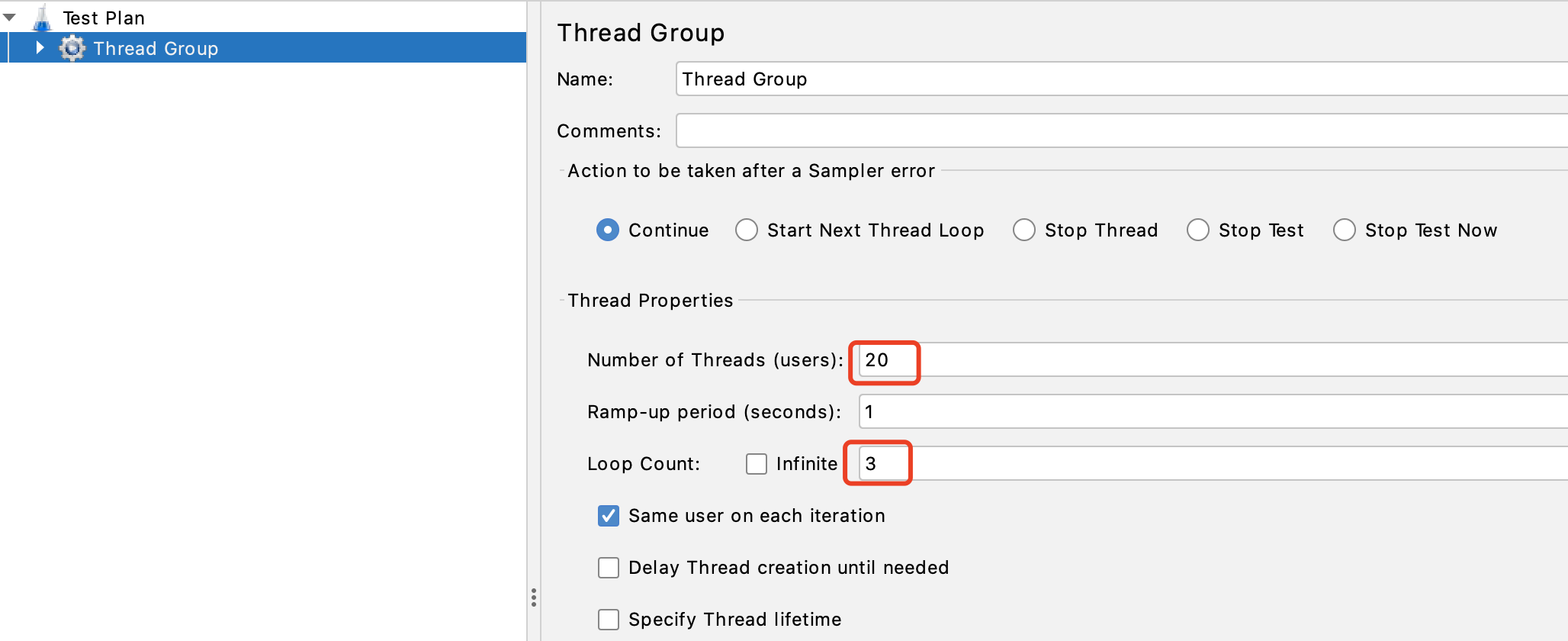
设置线程数量,及每个线程循环次数:
-
创建Http请求
配置请求的协议、IP、端口、请求路径等等信息:
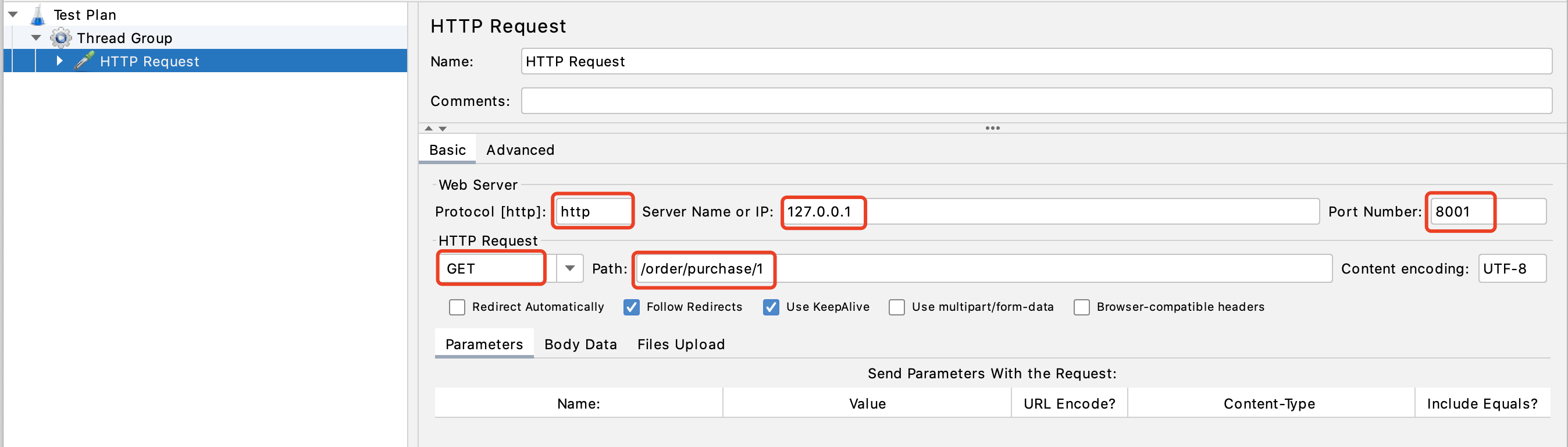
-
创建结果树
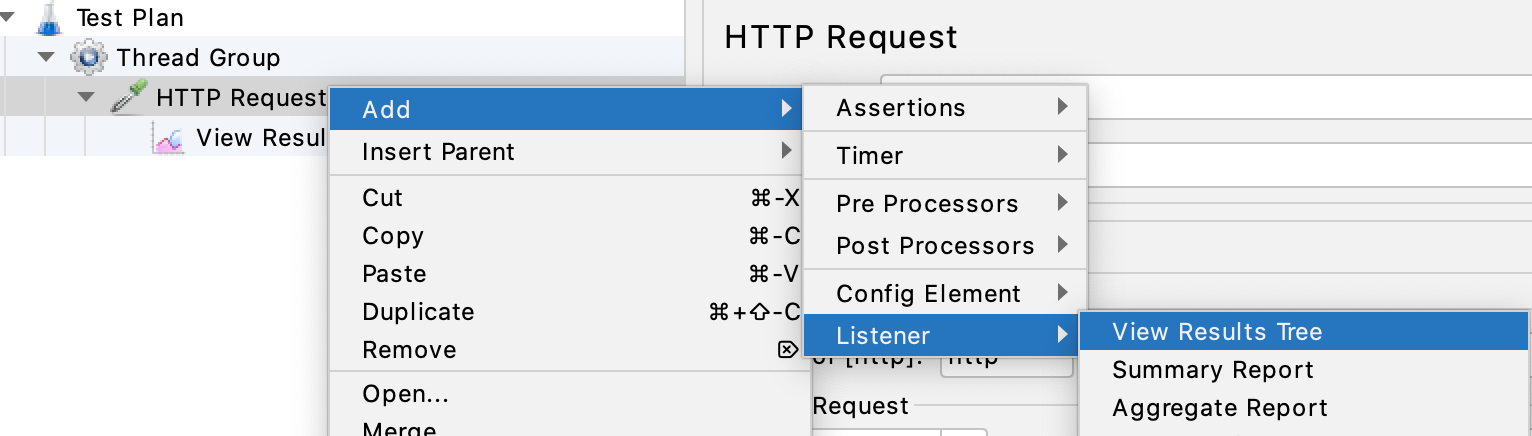
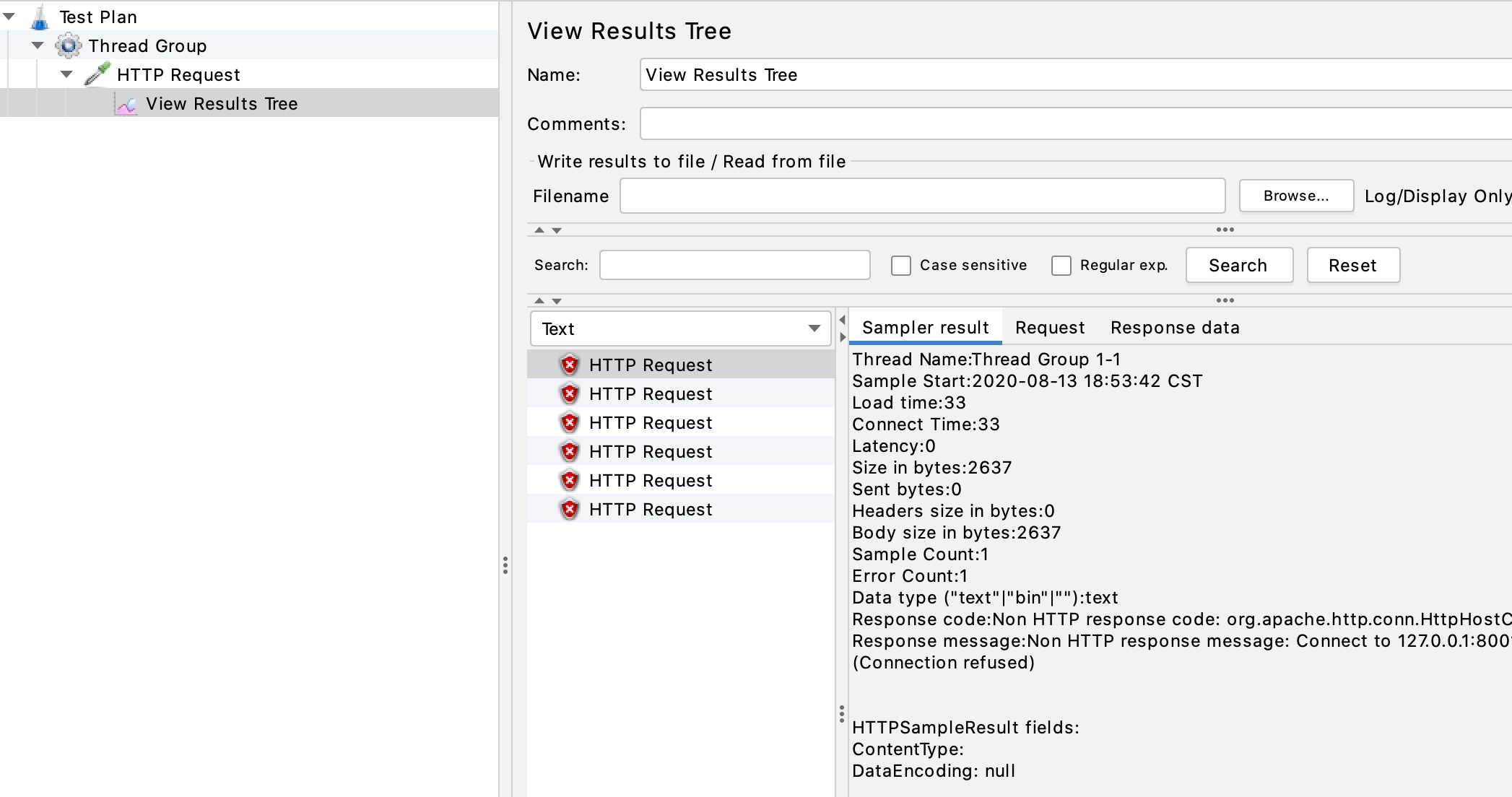
在这里,可以查看每次请求调用的详细信息:
测试
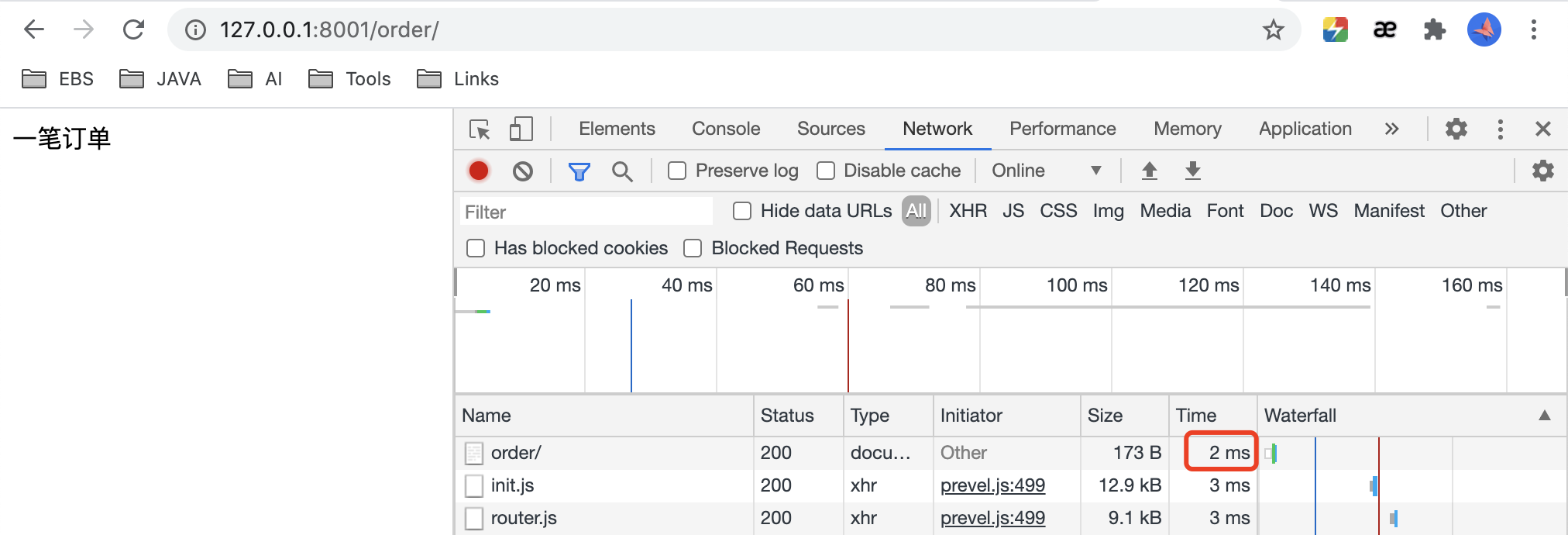
-
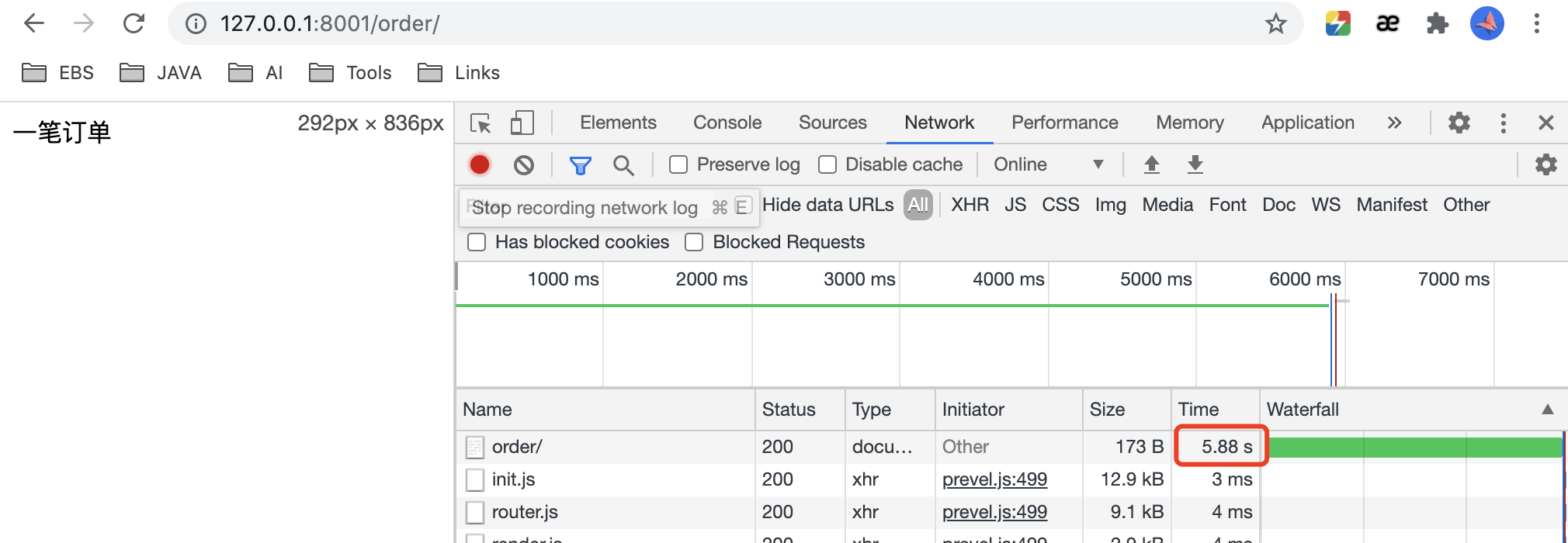
查看正常调用新请求的时间
-
启动jmeter中的配置:
-
再次调用:
解决高并发
我们这里使用线程池,实现服务隔离,解决上述问题。
前面配置了10个服务进程上限,我们只分配5个给/order/purchase/{id},使空出5个处理其他请求。
引入依赖
<dependency>
<groupId>com.netflix.hystrix</groupId>
<artifactId>hystrix-metrics-event-stream</artifactId>
</dependency>
<dependency>
<groupId>com.netflix.hystrix</groupId>
<artifactId>hystrix-javanica</artifactId>
</dependency>
配置线程池
创建HystrixCommand的资料,并通过代码配置线程池:
package com.strive.command;
import com.netflix.hystrix.*;
import com.strive.entity.Item;
import com.strive.feign.OrderFeign;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.client.RestTemplate;
import java.util.Date;
public class OrderCommand extends HystrixCommand<Item> {
private RestTemplate restTemplate;
private int id;
@Autowired
OrderFeign orderFeign;
private static Setter setter() {
HystrixCommandGroupKey groupKey = HystrixCommandGroupKey.Factory.asKey("order-service");
HystrixCommandKey commandKey = HystrixCommandKey.Factory.asKey("item");
HystrixThreadPoolKey threadPoolKey = HystrixThreadPoolKey.Factory.asKey("order-thread-pool");
HystrixThreadPoolProperties.Setter threadPoolProperties = HystrixThreadPoolProperties
.Setter()
.withCoreSize(5)
.withKeepAliveTimeMinutes(15)
.withQueueSizeRejectionThreshold(100);
HystrixCommandProperties.Setter commandProperties = HystrixCommandProperties
.Setter()
.withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.THREAD)
.withExecutionTimeoutEnabled(false);
return HystrixCommand.Setter
.withGroupKey(groupKey)
.andCommandKey(commandKey)
.andThreadPoolKey(threadPoolKey)
.andThreadPoolPropertiesDefaults(threadPoolProperties)
.andCommandPropertiesDefaults(commandProperties);
}
public OrderCommand(RestTemplate restTemplate, int id) {
super(setter());
this.restTemplate = restTemplate;
this.id = id;
}
@Override
protected Item run() throws Exception {
System.out.println("run..." + Thread.currentThread().getName());
//return orderFeign.findItemById(id);
Item item = restTemplate.getForObject("http://item-service/item/" + id, Item.class);
item.setCreatetime(new Date());
return item;
}
@Override
protected Item getFallback() {
System.out.println("fallback..." + Thread.currentThread().getName());
Item item = new Item();
item.setDetail("降级啦啦");
item.setCreatetime(new Date());
return item;
}
}
修改控制器
修改服务调用方法,通过线程池调用:
return new OrderCommand(restTemplate, id).execute();
测试
再次模拟高并发场景,这次可以正常调用新的请求方法了。
8.3 Rest熔断
上面的入门案例中,引入了Hystrix的2个包,实现了线程池隔离。
Hystrix是由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止级联失 败,从而提升系统的可用性与容错性。
下面演示RestTemplate如何实现熔断。
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
启用熔断
在启动类上增加注解@EnableCircuitBreaker。
也可用@SpringCloudApplication,替换@SpringBootApplication与@EnableCircuitBreaker
修改控制器
在请求方法上增加@HystrixCommand注解,并指定降级方法:
@HystrixCommand(fallbackMethod = "orderFallback")
@RequestMapping("purchase/{id}")
public Item findItemById(@PathVariable int id) {
System.out.println(id);
return restTemplate.getForObject("http://item-service/item/" + id, Item.class);
}
public Item orderFallback(int id) {
System.out.println("熔断降级。。。");
Item item = new Item();
item.setPic("熔断降级...");
return item;
}
降级方法与请求方法,具有相同的形参及返回值。
测试
不启动商品服务,然后调用订单服务,触发降级:

默认降级方法
前面的降级方法,是在请求方法的注解中指定的,如果有很多个请求方法,我们可以统一指定一个默认的降级方法,在类上添加注解@DefaultProperties(defaultFallback = ""):

超时配置
我们前面演示的入门案例中,将商品服务的处理时间,提到了2s以上,Hystrix默认超时为1s,可以通过下示设置,提高超时时间:
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 5000
8.4 Feign熔断
启用Hystrix
feign:
hystrix:
enabled: true
创建实现类
package com.strive.feign.impl;
import com.strive.entity.Item;
import com.strive.feign.OrderFeign;
import org.springframework.stereotype.Component;
@Component
public class OrderFeignImpl implements OrderFeign {
@Override
public Item findItemById(int id) {
System.out.println("feign -- 熔断降级。。。");
Item item = new Item();
item.setPic("熔断降级...");
return item;
}
}
指定降级类
在Feign接口的@FeignClient注解中,添加降级类:

8.5 监控平台
流数据
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
启用监控
启动类添加注解@EnableHystrixDashboard

修改配置
在application.yml中添加:
hystrix:
dashboard:
proxy-stream-allow-list: localhost
management:
endpoints:
web:
exposure:
include: '*'
前者是添加可监控的ip,不然无权查看;
后者是开放所有可查看的数据,不然流数据网址无响应。
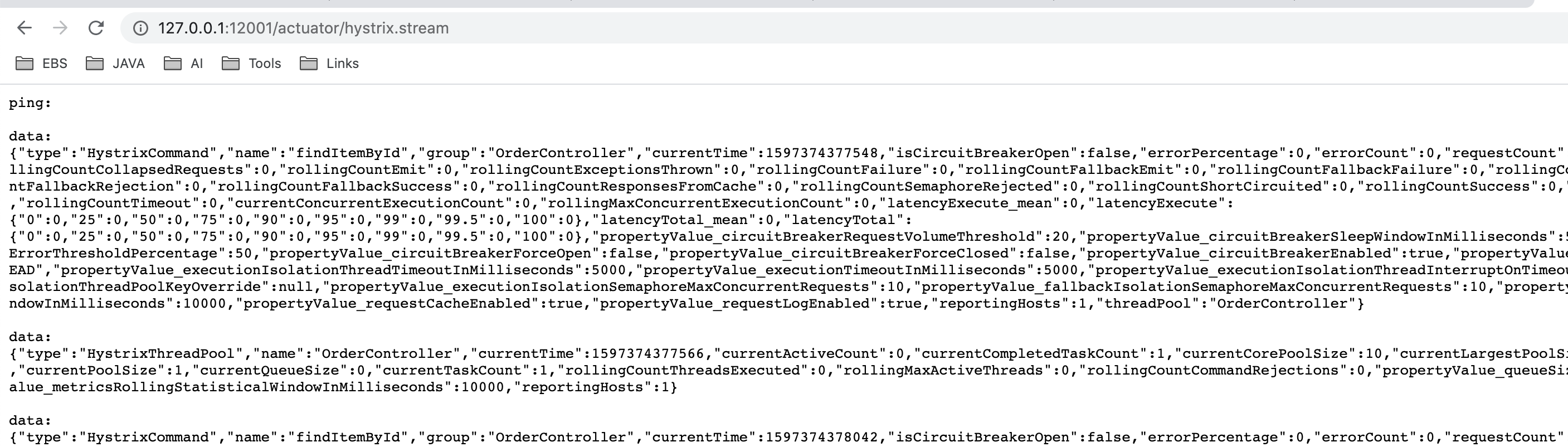
测试
调用一次订单服务,然后直接在其端口下,查看url:/actuator/hystrix.stream,即可查看调用的流数据
可视化
前面的流数据,全是文字,不易读取解析,这里可将其转为图形,便于理解。
配置
就是上一步引入的依赖,配置也一致。
测试
在地址栏中输入/hystrix:
在其中,输入上一步浏览流数据的地址,然后点击Monitor Stream:
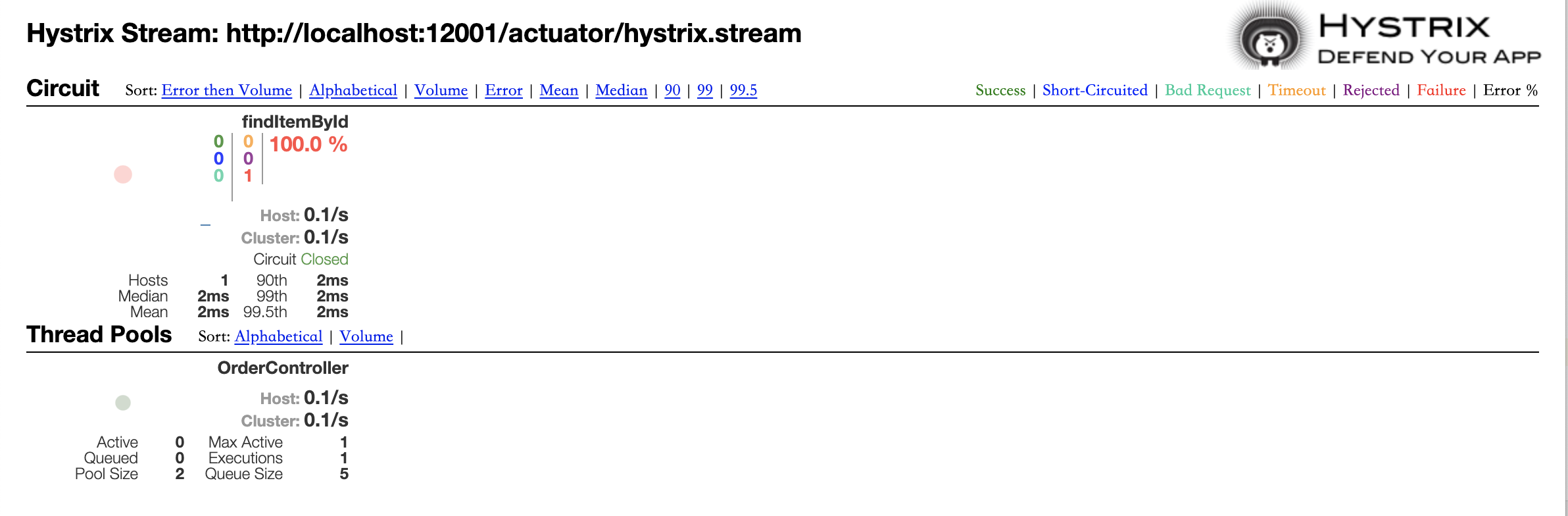
聚合监控
当有很多个服务时,按照上一步的方法,对每个服务只能单独监控,较为麻烦。
下面介绍Turbine,实现单个网站,监控多个服务。
原理简单来说,就是将各服务的流数据,汇总到Turbine,统一显示。
创建新模块
略
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
创建配置
server:
port: 7101
spring:
application:
name: hystrix-turbine-server
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka
instance:
prefer-ip-address: true
turbine:
app-config: hystrix-order-service,item-service
cluster-name-expression: "'default'"
hystrix:
dashboard:
proxy-stream-allow-list: localhost
关键是turbine配置,指定了监控的服务名
创建启动类
package com.strive;
import org.springframework.boot.SpringApplication;
import org.springframework.cloud.client.SpringCloudApplication;
import org.springframework.cloud.netflix.hystrix.dashboard.EnableHystrixDashboard;
import org.springframework.cloud.netflix.turbine.EnableTurbine;
@SpringCloudApplication
@EnableHystrixDashboard
@EnableTurbine
public class TurbineApplication {
public static void main(String[] args) {
SpringApplication.run(TurbineApplication.class, args);
}
}
测试
启动Turbine,并在其中输入http://
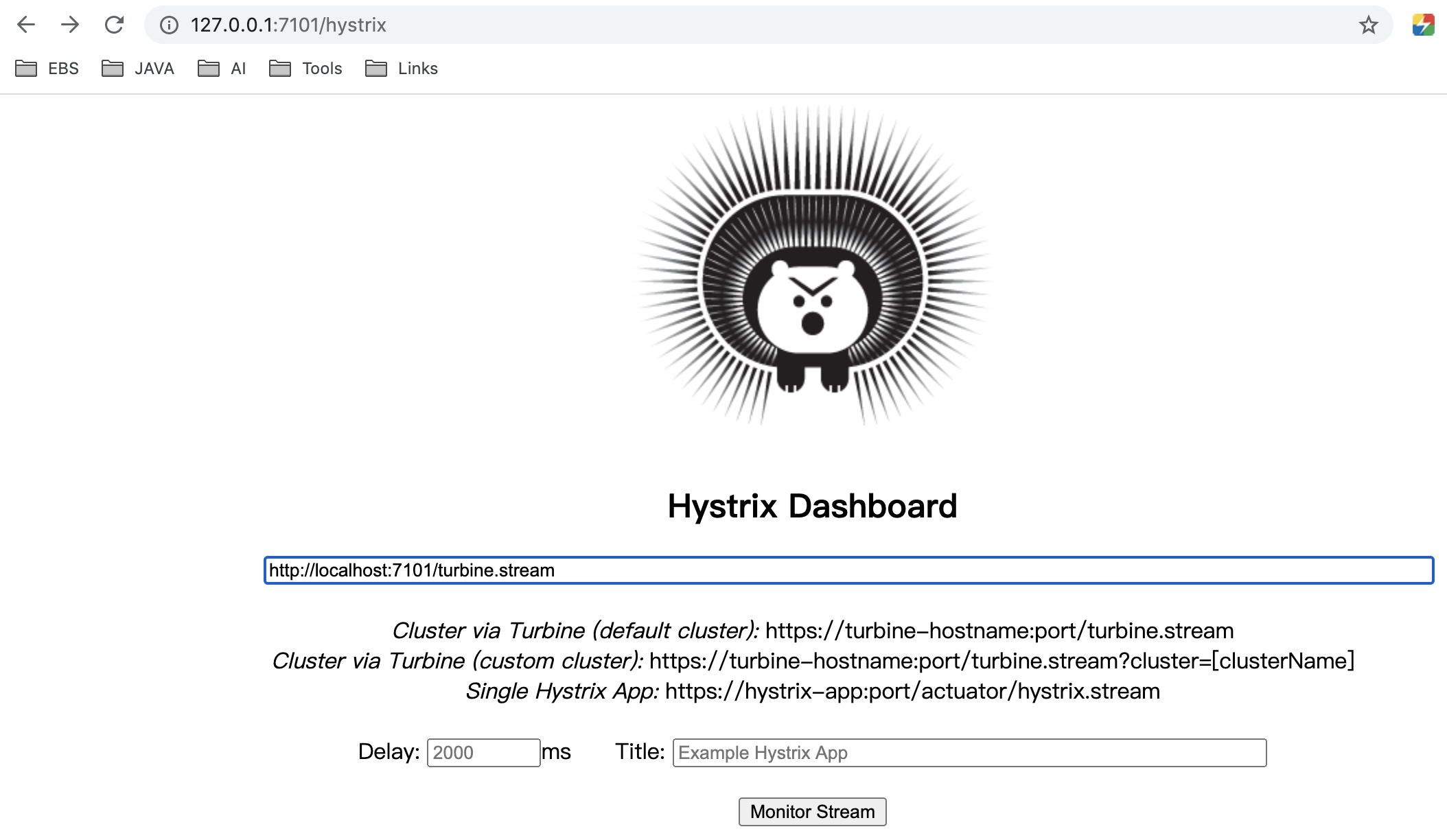
点击Monitor Stream后:
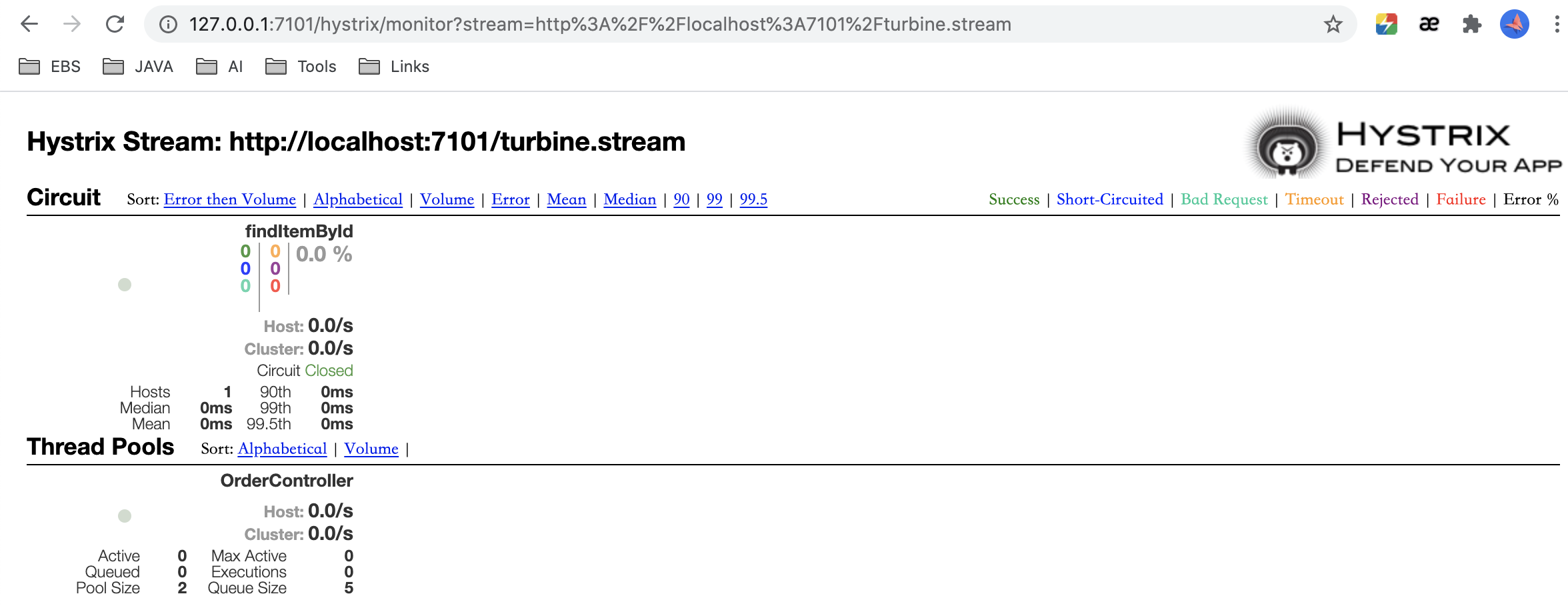
8.6 总结
Hystrix主要通过以下几点实现延迟和容错。
-
包裹请求
使用HystrixCommand包裹对依赖的调用逻辑,每个命令在独立线程中执行。这使用了设计模式中的“命令模式”。
-
跳闸机制
当某服务的错误率超过一定的阈值时,Hystrix可以自动或手动跳闸,停止请求该服务一段时间。
-
资源隔离
Hystrix为每个依赖都维护了一个小型的线程池(或者信号量)。如果该线程池已满,发往该依赖的请求就被立即拒绝,而不是排队等待,从而加速失败判定。
-
监控
Hystrix可以近乎实时地监控运行指标和配置的变化,例如成功、失败、超时、以及被拒绝的请求等。
-
回退机制
当请求失败、超时、被拒绝,或当断路器打开时,执行回退逻辑。
回退逻辑由开发人员自行提供,例如返回一个缺省值。
-
自我修复
断路器打开一段时间后,会自动进入“半开”状态。
9. Sentinel
9.1 概述
背景
18年底Netflix官方宣布Hystrix已经足够稳定,不再积极开发 Hystrix,该项目将处于维护模式。
就目前来看Hystrix是比较稳定的,并且Hystrix只是停止开发新的版本,并不是完全停止维护,Bug什么的依然会维护的。因此短期内,Hystrix依然是继续使用的。
但从长远来看,Hystrix总会达到它的生命周期。
替换方案
-
Alibaba Sentinel
Sentinel 是阿里巴巴开源的一款断路器实现,目前在Spring Cloud的孵化器项目Spring Cloud Alibaba 中的一员Sentinel本身在阿里内部已经被大规模采用,非常稳定。因此可以作为一个较好的替代品。
-
Resilience4J
Resilicence4J 一款非常轻量、简单,并且文档非常清晰、丰富的熔断工具,这也是Hystrix官方推荐的替代产品。
不仅如此,Resilicence4j还原生支持Spring Boot 1.x/2.x,而且监控也不像Hystrix一样弄 Dashboard/Hystrix等一堆轮子,而是支持和Micrometer(Pivotal开源的监控门面,Spring Boot 2.x 中的Actuator就是基于Micrometer的)、prometheus(开源监控系统,来自谷歌的论文)、以及 Dropwizard metrics(Spring Boot曾经的模仿对象,类似于Spring Boot)进行整合
9.2 管理控制台
下载
下载地址:https://github.com/alibaba/Sentinel/releases/
运行
下载的是个jar包,直接运行即可:java -jar sentinel-dashboard-
浏览器查看:http://localhost:8080/
默认用户名/密码:sentinel/sentinel
目前是空的,我们后面就注册服务进来
9.3 发布客户端
创建新模块
略
引入依赖
父项目添加(注意版本:版本说明):
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.1.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
子模块添加:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
</exclusion>
</exclusions>
</dependency>
这里对spring-cloud-starter-alibaba-sentinel依赖,排除了jackson-dataformat-xml,以保证请求返回的是json格式,否则xml优先级更高。
创建配置
server:
port: 8101
spring:
application:
name: sentinel-order-service
cloud:
sentinel:
transport:
dashboard: localhost:8080
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka
instance:
prefer-ip-address: true
关键是spring.cloud.sentinel的配置,添加sentinel管理控制台地址。
创建启动类
package com.strive;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
public class SentinelOrderApplication {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(SentinelOrderApplication.class, args);
}
}
实体类
将前面案例中订单服务的entity,复制过来
控制器
package com.strive.controller;
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.strive.entity.Item;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RequestMapping("order")
@RestController
public class SentinelOrderController {
@Autowired
RestTemplate restTemplate;
@GetMapping("{id}")
@SentinelResource(value = "findItem",
blockHandler = "blockHandler",
fallback = "fallback")
public Item findItem(@PathVariable int id) {
return restTemplate.getForObject("http://item-service/item/" + id, Item.class);
}
// 熔断降级
public Item blockHandler(int id) {
Item item = new Item();
item.setPic("限流熔断。。。");
return item;
}
// 异常降级
public Item fallback(int id) {
Item item = new Item();
item.setPic("异常熔断。。。");
return item;
}
}
这里对方法添加了注解@SentinelResource:
- value: 资源名,就是区分不同的请求,可以省略,默认为请求路径
- blockHandler: 限流降级方法,当触发了限流时的响应方法(非BlockException异常)
- fallback:触发了其他异常的降级方法
| 属性 | 作用 |
|---|---|
| value | 资源 |
| entryType | entry类型,标记流量的方向,取值IN/OUT,默 否 认是OUT |
| blockHandler | 处理BlockException的函数名称。函数要求: 1. 必须是 public 2. 返回类型与原方法一致 3. 参数类型需要和原方法相匹配,并在最后加 BlockException 类型的参数。 4. 默认需和原方法在同一个类中。若希望使用其他类的函数,可配置 blockHandlerClass ,并指定 blockHandlerClass里面的方法 |
| blockHandlerClass | 存放blockHandler的类。对应的处理函数必须 static修饰,否则无法解析,其他要求:同 blockHandler。 |
| fallback | 用于在抛出异常的时候提供fallback处理逻辑。 fallback函数可以针对所有类型的异常(除了exceptionsToIgnore 里面排除掉的异常类型) 进行处理。函数要求: 1. 返回类型与原方法一致 2. 参数类型需要和原方法相匹配,Sentinel 1.6 开始,也可在方法最后加Throwable 类型的参数。 3.默认需和原方法在同一个类中。若希望使用其他类的函数,可配置 fallbackClass ,并指定fallbackClass里面的方法 |
| fallbackClass【1.6】 | 存放fallback的类。对应的处理函数必须static修 否 饰,否则无法解析,其他要求:同fallback。 |
| defaultFallback【1.6】 | 用于通用的 fallback 逻辑。默认fallback函数可 以针对所有类型的异常(除了exceptionsToIgnore 里面排除掉的异常类型)进行处理。若同时配置了 fallback 和 defaultFallback,以fallback为准。函数要求 |
| exceptionsToIgnore【1.6】 | 指定排除掉哪些异常。排除的异常不会计入异常统计,也不会进入fallback逻辑,而是原样抛出。 |
| exceptionsToTrace | 需要trace的异常 |
测试
启动服务,随便调用一次,然后查看sentinel管理控制台。
因为sentinel是默认懒加载,不触发一次服务调用,就不会显示对应服务状态。
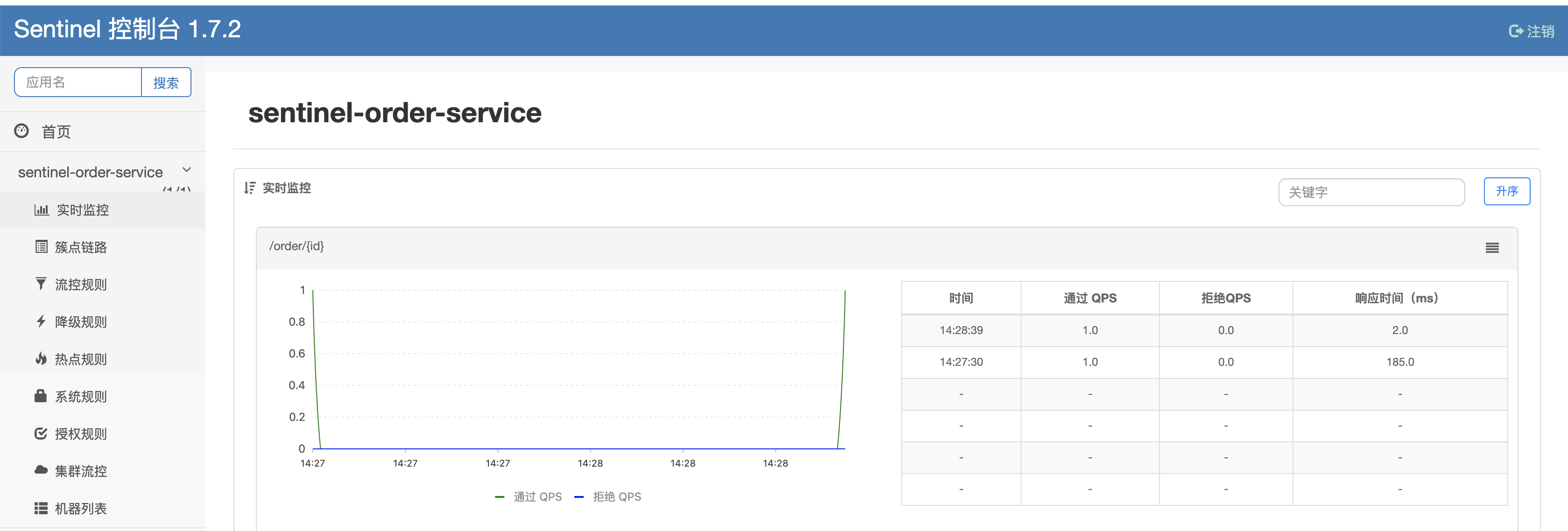
在簇点链路页签,显示的就是资源了,可以看到我们的请求资源findItem:
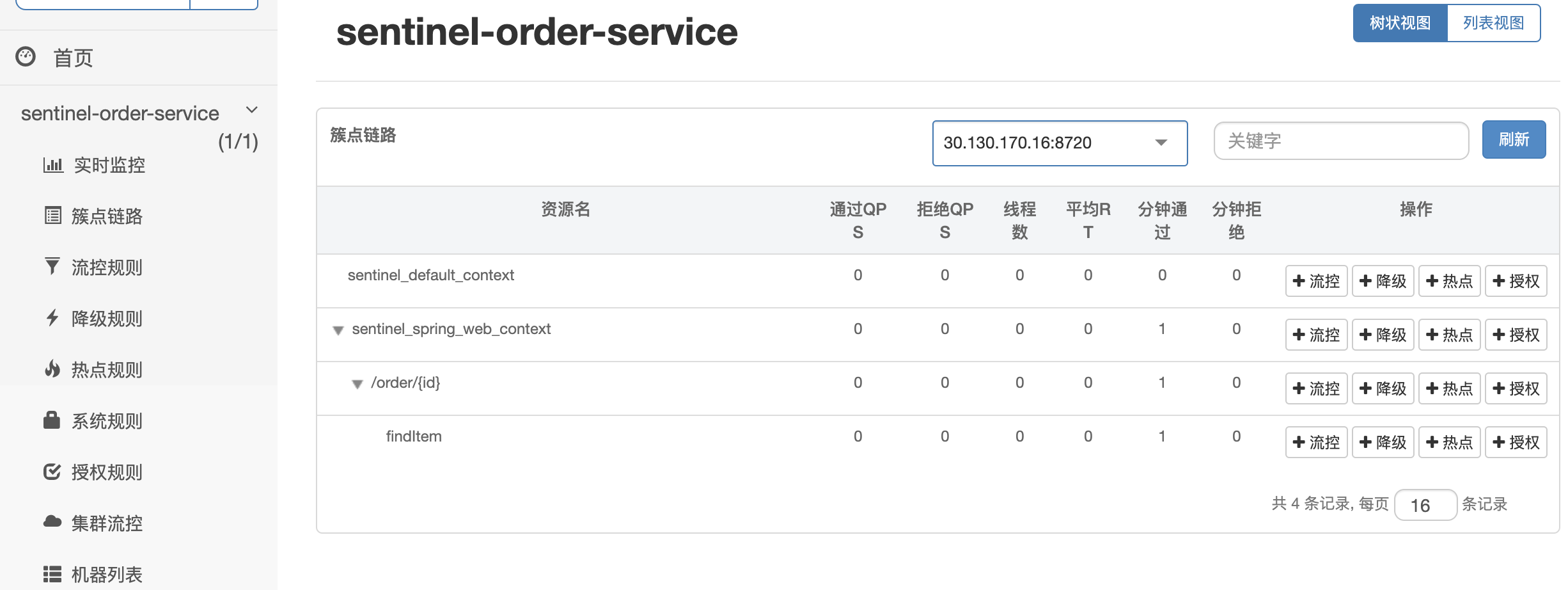
不启动商品服务,直接调用订单服务时:

9.4 Rest熔断
Spring Cloud Alibaba Sentinel 支持 RestTemplate 的服务调用使用Sentinel,以进行保护
修改启动类
在RestTemplate上增加注解@SentinelRestemplate:
@Bean
@LoadBalanced
@SentinelRestTemplate(blockHandler = "handleBlock",
blockHandlerClass = ExceptionUtil.class,
fallback = "handleFallback",
fallbackClass = ExceptionUtil.class)
public RestTemplate restTemplate() {
return new RestTemplate();
}
这里的blockHandler、fallback与@SentinelResource中的一致,是方法名。
blockHandlerClass与fallbackClass,指定了方法所属类,下面来创建
创建异常类
package com.strive.exception;
import com.alibaba.cloud.sentinel.rest.SentinelClientHttpResponse;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.fastjson.JSON;
import com.strive.entity.Item;
import org.springframework.http.HttpRequest;
import org.springframework.http.client.ClientHttpRequestExecution;
public class ExceptionUtil {
public static SentinelClientHttpResponse handleBlock(HttpRequest httpRequest,
byte[] body,
ClientHttpRequestExecution execution,
BlockException ex) {
System.out.println(ex.getMessage());
Item item = new Item();
item.setPic("限流熔断了!!");
return new SentinelClientHttpResponse(JSON.toJSONString(item));
}
public static SentinelClientHttpResponse handleFallback(HttpRequest request,
byte[] body,
ClientHttpRequestExecution execution,
BlockException ex) {
System.out.println(ex.getMessage());
Item item = new Item();
item.setPic("异常熔断了!!");
return new SentinelClientHttpResponse(JSON.toJSONString(item));
}
}
- 方法为静态
- 返回类型为SentinelClientResponse
- 请求参数四个不可少,不然启动会报错
修改启动类
去掉@SentinelResource的注解
测试
限流
这里做个限流测试,限制订单服务,每秒最多触发1次
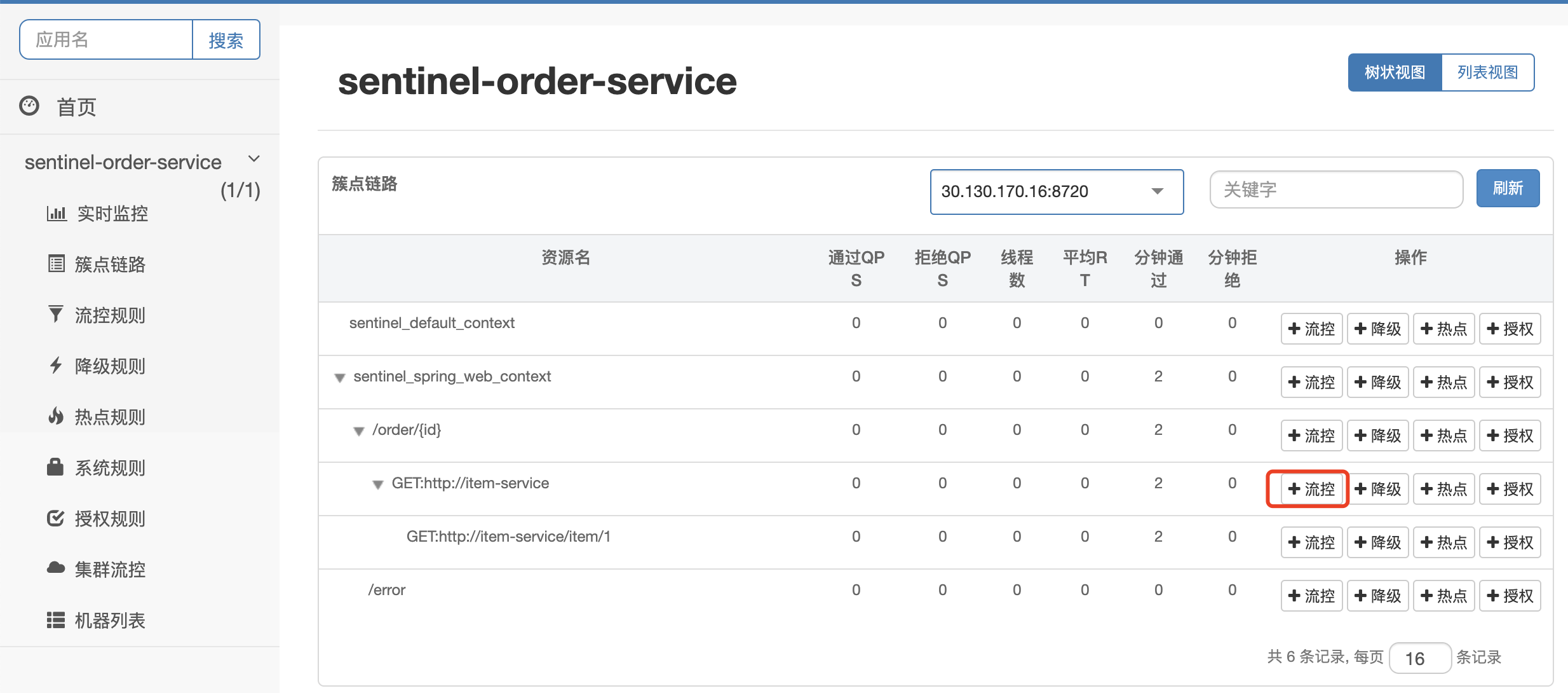
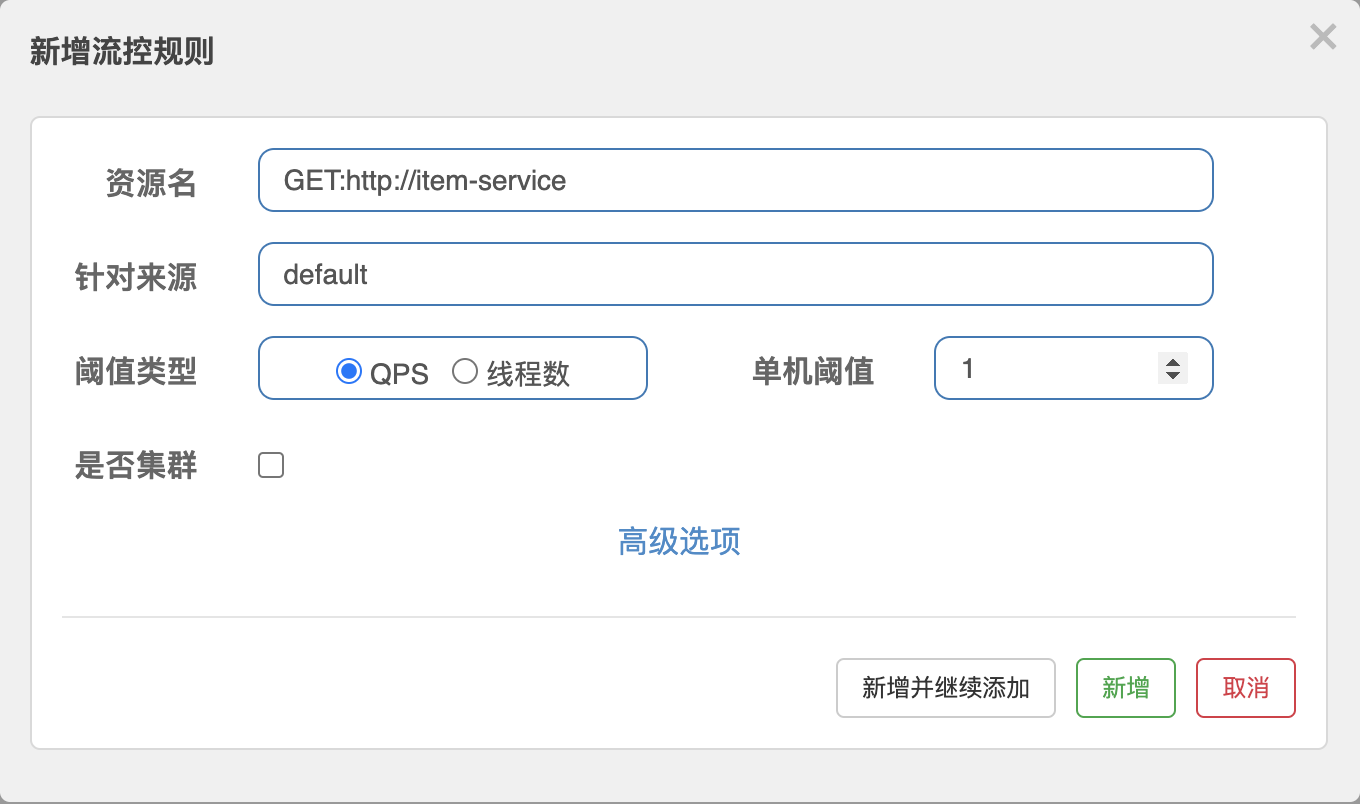
然后在订单服务页面,快速刷新两次:

降级
创建降级规则,当出现1个异常时,就熔断,时间为3s:
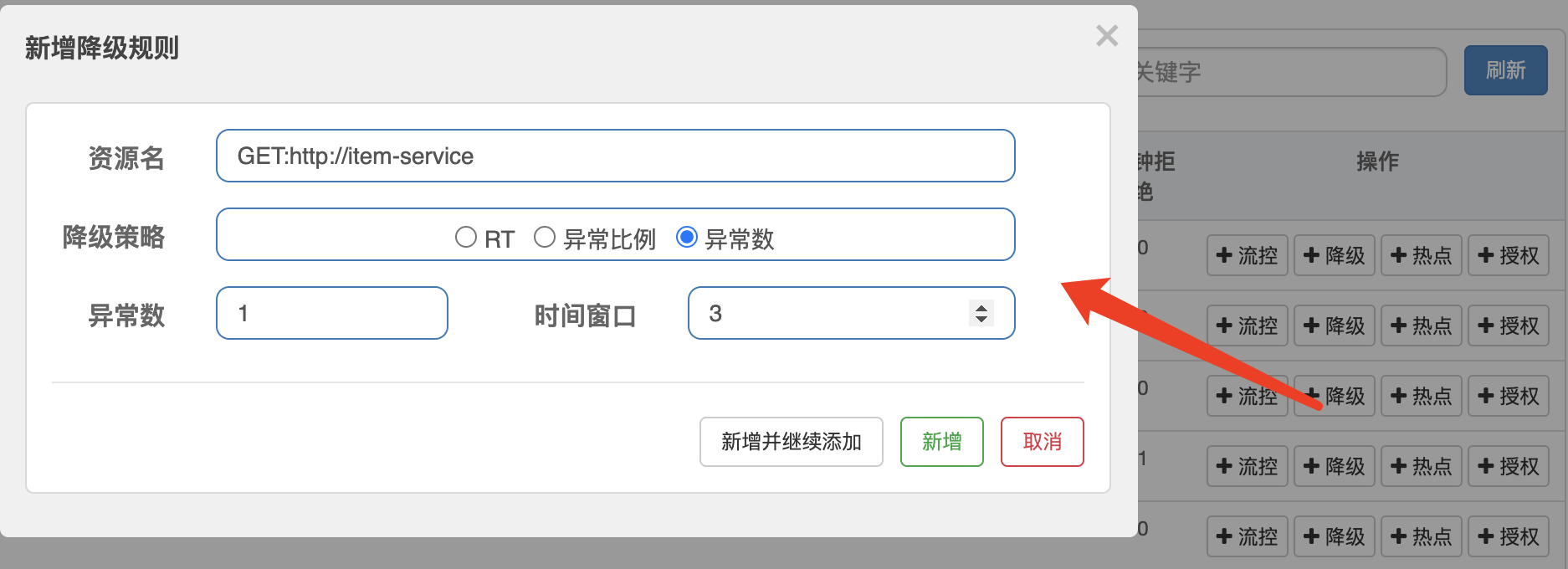
查询两次不存在的订单:
9.5 Feign熔断
Sentinel 适配了 Feign 组件。如果想使用,除了引入 sentinel-starter 的依赖外还需要 2 个步骤:
- 配置文件打开 sentinel 对 feign 的支持: feign.sentinel.enabled=true
- 加入 openfeign starter 依赖使 sentinel starter 中的自动化配置类生效
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
修改配置
增加如下配置:
feign:
sentinel:
enabled: true
修改启动类
添加类注解@EnableFeignClients,支持Feign
创建接口
package com.strive.feign;
import com.strive.entity.Item;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
@FeignClient(value = "item-service",
fallback = OrderFeignFallback.class)
public interface SentinelOrderFeign {
@RequestMapping("/item/{id}")
public Item findItem(@PathVariable int id);
}
创建实现类
package com.strive.feign;
import com.strive.entity.Item;
import org.springframework.stereotype.Component;
@Component
public class OrderFeignFallback implements SentinelOrderFeign {
@Override
public Item findItem(int id) {
Item item = new Item();
item.setPic("降级ing...");
return item;
}
}
修改控制器
增加方法:
@GetMapping("feign/{id}")
public Item findItemByFeign(@PathVariable int id) {
return orderFeign.findItem(id);
}
9.6 加载规则
我们在管理控制台设置的规则,在服务重启后就消失了,因为它是保存在服务内存中的。
为了服务启动时,就加载默认规则,可以通过修改配置实现。
修改配置
spring:
cloud:
sentinel:
datasource:
ds1:
file:
rule-type: flow
data-type: json
file: classpath:flowrule.json
ds2:
file:
rule-type: degrade
data-type: json
file: classpath:degrade.json
这里配置datasource,即数据来源。
-
ds1与ds2是自定义的文件来源名
-
file,表示来源类型为文件
-
rule-type,规则类型,flow为限流,degrade为降级
-
data-type,文件内容类型,这里给json
-
file,文件路径
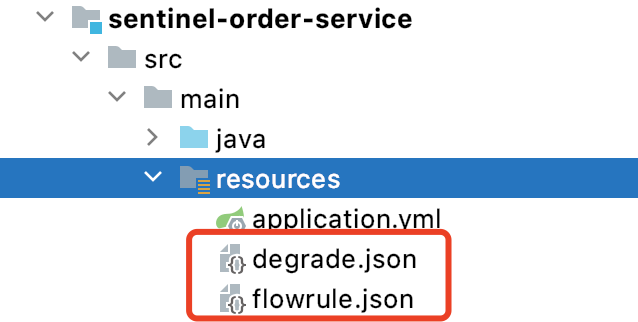
限流文件
[
{
"resource": "GET:http://item-service",
"controlBehavior": 0,
"count": 2,
"grade": 1,
"limitApp": "default",
"strategy": 0
}
]
这里的属性说明,可查看源码FlowRule
-
resource:资源名
-
controlBehavior:限流发生后的处理类型,0为直接拒绝
-
count:限流数量
-
grade:限流类型,0为线程,1为QPS(每秒查询量)
-
limitAPP:限流来源,defalt为所有来源
-
strategy:限流策略
-
STRATEGY_DIRECT(0)
根据调用方进行限流。ContextUtil.enter(resourceName, origin) 方法中的 origin 参数标明了调用方的身份。
如果 strategy 选择了DIRECT ,则还需要根据限流规则中的 limitApp 字段根据调用方在不同的场景中进行流量控制,包括有:”所有调用方“、”特定调用方origin“、”除特定调用方origin之外的调用方“。
-
STRATEGY_RELATE(1)
根据关联流量限流。当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联,可使用关联限流来避免具有关联关系的资源之间过度的争抢。
比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。
举例来说:read_db 和 write_db 这两个资源分别代表数据库读写,我们可以给 read_db 设置限流规则来达到写优先的目的:设置 FlowRule.strategy 为 RuleConstant.STRATEGY_RELATE,同时设置 FlowRule.refResource 为 write_db。这样当写库操作过于频繁时,读数据的请求会被限流。
-
STRATEGY_CHAIN(2)
根据调用链路入口限流。假设来自入口 Entrance1 和 Entrance2 的请求都调用到了资源 NodeA,Sentinel 允许根据某个入口的统计信息对资源进行限流。
举例来说:我们可以设置 FlowRule.strategy 为 RuleConstant.CHAIN,同时设置 FlowRule.refResource 为 Entrance1 来表示只有从入口 Entrance1 的调用才会记录到 NodeA 的限流统计当中,而对来自 Entrance2 的调用可以放行
-
10. Zuul
10.1 概述
背景
在学习完前面的知识后,微服务架构已经初具雏形。
但还有一些问题:不同的微服务一般会有不同的网络地址,客户端在访问这些微服务时必须记住几十甚至几百个地址,这对于客户端方来说太复杂也难以维护:
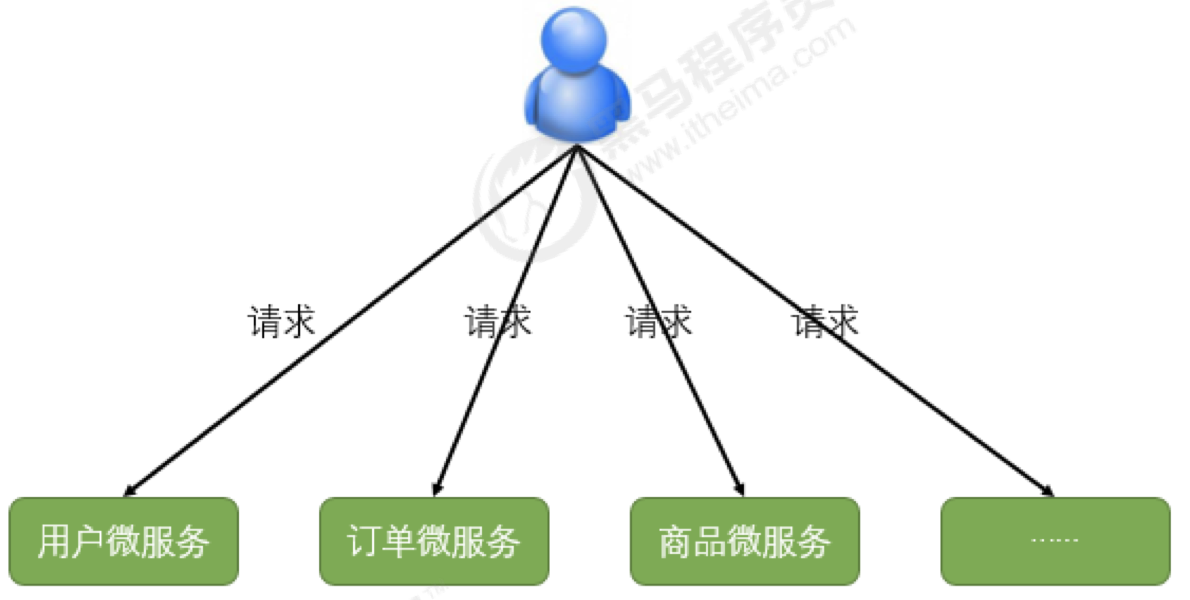
如果让客户端直接与各个微服务通讯,可能会有很多问题:
- 客户端会请求多个不同的服务,需要维护不同的请求地址,增加开发难度
- 在某些场景下存在跨域请求的问题
- 加大身份认证的难度,每个微服务需要独立认证
因此,我们需要一个介于客户端与服务器之间的中间层,所有的外部请求都会先经过它:微服务网关。
客户端只需要与网关交互,只知道一个网关地址即可,这样简化了开发:
- 易于监控
- 易于认证
- 减少了客户端与各个微服务之间的交互次数
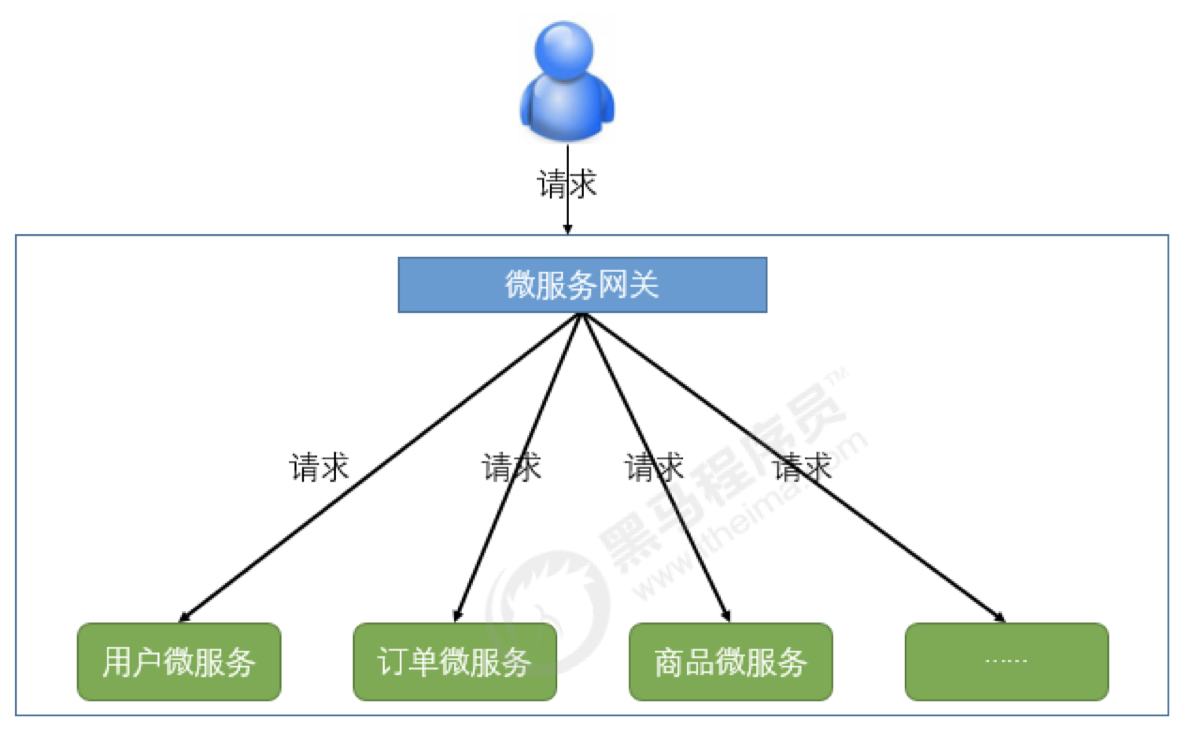
微服务网关
概念
API网关是一个服务器,是系统对外的唯一入口。
API网关封装了系统内部架构,为每个客户端提供 一个定制的API。
API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。
通常,网关也提供REST/HTTP的访问API。
服务端通过API-GW注册和管理服务
作用/场景
网关具有的职责,如身份验证、监控、负载均衡、缓存、请求分片与管理、静态响应处理。当然,最主 要的职责还是与“外界联系”
常见实现产品
-
Kong
基于Nginx+Lua开发,性能高,稳定,有多个可用的插件(限流、鉴权等等),可以开箱即用。
问题:
只支持Http协议;
二次开发,自由扩展困难;
提供管理API,缺乏更易用的管控、配置方式。
-
Zuul
Netflix开源,功能丰富,使用JAVA开发,易于二次开发;需要运行在web容器中,如Tomcat。
问题:
缺乏管控,无法动态配置;
依赖组件较多;
处理Http请求依赖的是Web容器,性能不如 Nginx;
-
Traefik
Go语言开发;轻量易用;提供大多数的功能:服务路由,负载均衡等等;提供WebUI
问题:
二进制文件部署,二次开发难度大;
UI更多的是监控,缺乏配置、管理能力;
-
Spring Cloud Gateway
SpringCloud提供的网关服务
-
Nginx+lua实现
使用Nginx的反向代理和负载均衡可实现对api服务器的负载均衡及高可用
问题:自注册的问题和网关本身的扩展性
Zuul
ZUUL是Netflix开源的微服务网关,它可以和Eureka、Ribbon、Hystrix等组件配合使用,Zuul组件的 核心是一系列的过滤器,这些过滤器可以完成以下功能:
- 动态路由:动态将请求路由到不同后端集群
- 压力测试:逐渐增加指向集群的流量,以了解性能
- 负载分配:为每一种负载类型分配对应容量,并弃用超出限定值的请求
- 静态响应处理:边缘位置进行响应,避免转发到内部集群
- 身份认证和安全: 识别每一个资源的验证要求,并拒绝那些不符的请求。
Spring Cloud对Zuul进行 了整合和增强。
10.2 路由转发
最直观的理解:“路由”是指根据请求URL,将请求分配到对应的处理程序。
在微服务体系中,Zuul负责接收所有的请求。根据不同的URL匹配规则,将不同的请求转发到不同的微服务处理。
创建子module
略
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
创建启动类
package com.strive;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.zuul.EnableZuulProxy;
@SpringBootApplication
@EnableZuulProxy // 启用Zuul
public class ZuulApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulApplication.class, args);
}
}
创建配置
server:
port: 8901
spring:
application:
name: zuul-server
zuul:
routes:
order-service: # 路由ID,可自定义
path: /order-service/** # 需要路由的PATH
url: http://127.0.0.1:8001/ # 实际的微服务URL
sensitiveHeaders: #默认zuul会屏蔽cookie,cookie不会传到下游服务,这里设置为空则取消默认的黑名单。如果设置了具体的头信息则对应信息不会传到下游服务
此时启动Zuul,在地址栏输入http://localhost:8901/order-service时,会转到http://localhost:8001/处理,order-service不会带过去。
面向服务
上一步的配置中,实际的微服务URL是配置了固定的IP、端口。
在实际开发中如果有负载均衡,则这种配置就不合理了。
Zuul支持与Eureka整合开发,根据ServiceID自动的从注册中心中获取服务地址并转发请求,这样做的 好处不仅可以通过单个端点来访问应用的所有服务,而且在添加或移除服务实例的时候不用修改Zuul的 路由配置
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
修改配置
注释原来的url,添加serviceId,对应微服务名称。
zuul:
routes:
order-service:
path: /order-service/**
# url: http://127.0.0.1:8001/
sensitiveHeaders:
serviceId: order-service
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:7001/eureka
registry-fetch-interval-seconds: 5
instance:
prefer-ip-address: true
ip-address: 127.0.0.1
实际上,zuul默认就是以微服务名称映射的,而路由id也是微服务名称。
所以可以简化路由配置为:
zuul:
routes:
order-service: /order-service/**
甚至可以不配置
10.3 过滤器
概述
通过之前的学习,我们得知Zuul它包含了两个核心功能:
- 路由:负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础
- 过滤器:负责对请求的处理过程进行干预,是实现请求校验、服务聚合等功能的基础。
其实,路由功能在真正运行时,它的路由映射和请求转发同样也由几个不同的过滤器完成的。
所以,过滤器可以说是Zuul实现API网关功能最为核心的部件,每一个进入Zuul的HTTP请求都会经过一系列的过滤器处理链得到请求响应并返回给客户端。
简介
Zuul 中的过滤器跟我们之前使用的 javax.servlet.Filter 不一样,javax.servlet.Filter 只有一种类型,可 以通过配置 urlPatterns 来拦截对应的请求。而 Zuul 中的过滤器总共有 4 种类型,且每种类型都有对 应的使用场景。
PRE:这种过滤器在请求被路由之前调用。我们可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。
ROUTING:这种过滤器将请求路由到微服务。这种过滤器用于构建发送给微服务的请求,并使用 Apache HttpClient或Netfilx Ribbon请求微服务。
POST:这种过滤器在路由到微服务以后执行。这种过滤器可用来为响应添加标准的HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
ERROR:在其他阶段发生错误时执行该过滤器。
Zuul提供了自定义过滤器的功能实现起来也十分简单,只需要编写一个类去实现zuul提供的接口:
public abstract ZuulFilter implements IZuulFilter{
abstract public String filterType();
abstract public int filterOrder();
boolean shouldFilter();// 来自IZuulFilter
Object run() throws ZuulException;// IZuulFilter
}
ZuulFilter是过滤器的顶级父类。在这里我们看一下其中定义的4个最重要的方法
- shouldFilter:返回一个Boolean值,判断该过滤器是否需要执行。返回true执行,返回false不执行。
- run:过滤器的具体业务逻辑。
- filterType:返回字符串,代表过滤器的类型。包含以下4种:
- pre:请求在被路由之前执行
- routing :在路由请求时调用
- post :在routing和errror过滤器之后调用
- error :处理请求时发生错误调用
- filterOrder :通过返回的int值来定义过滤器的执行顺序,数字越小优先级越高
生命周期
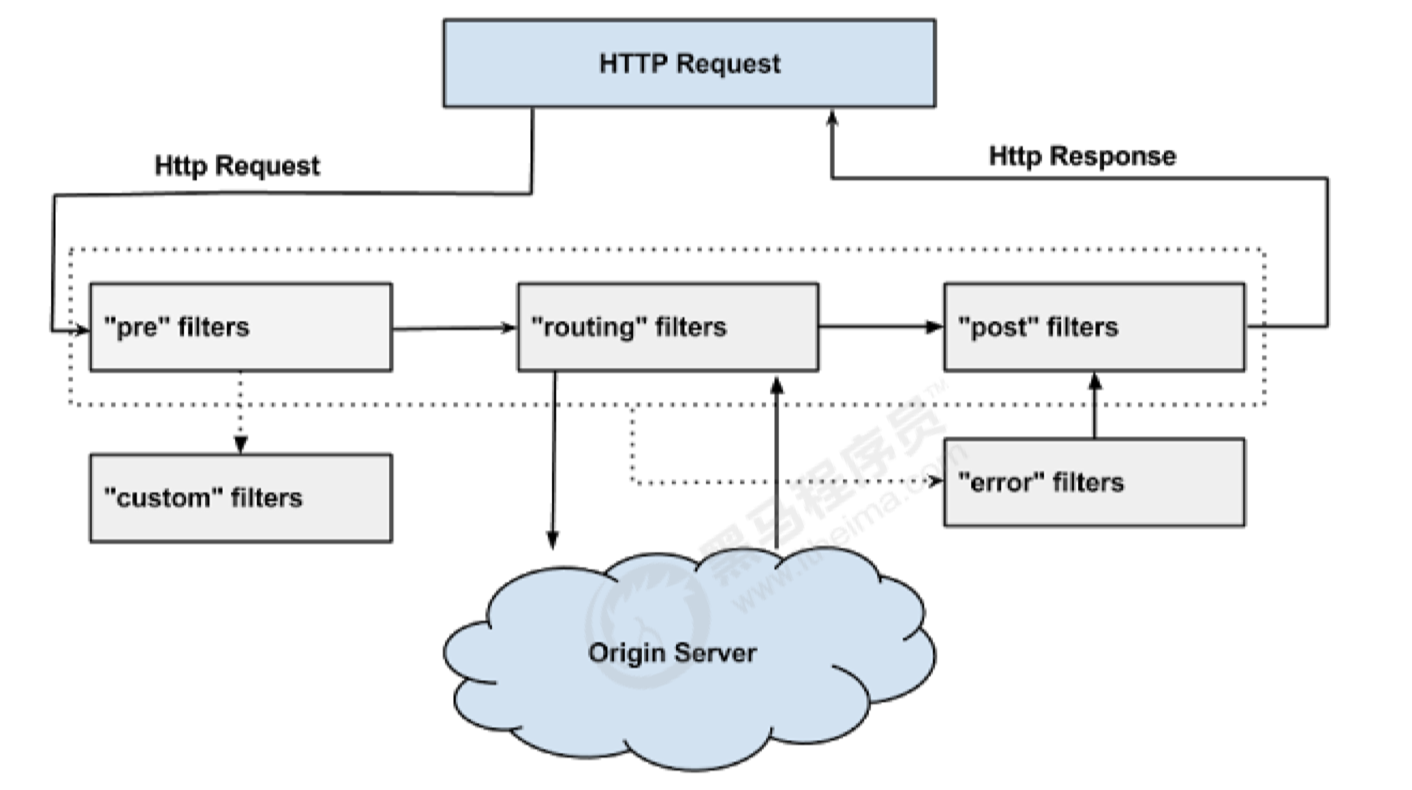
-
正常流程:
请求到达首先会经过pre类型过滤器,而后到达routing类型,进行路由,请求就到达真正的 服务提供者,执行请求,返回结果后,会到达post过滤器。而后返回响应。
-
异常流程:
- 整个过程中,pre或者routing过滤器出现异常,都会直接进入error过滤器,再error处理完毕 后,会将请求交给POST过滤器,最后返回给用户。
- 如果是error过滤器自己出现异常,最终也会进入POST过滤器,而后返回。
- 如果是POST过滤器出现异常,会跳转到error过滤器,但是与pre和routing不同的时,请求 不会再到达POST过滤器了。
-
不同过滤器的场景:
- 请求鉴权:一般放在pre类型,如果发现没有访问权限,直接就拦截了
- 异常处理:一般会在error类型和post类型过滤器中结合来处理。
- 服务调用时长统计:pre和post结合使用。
使用
创建一个过滤器类即可,这里测试一个登陆demo
package com.strive.filter;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import com.netflix.zuul.exception.ZuulException;
import org.apache.http.HttpStatus;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
@Component
public class LoginFilter extends ZuulFilter {
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() throws ZuulException {
RequestContext context = RequestContext.getCurrentContext();
HttpServletRequest request = context.getRequest();
if (request.getParameter("access-token") == null) {
context.setSendZuulResponse(false); // 拦截请求
context.setResponseStatusCode(HttpStatus.SC_UNAUTHORIZED); // 设置状态码
}
return null;
}
}
我这里判断url是否有access-token参数,有则通过,否则报错。
测试:
11. Spring Gateway
11.1 概述
Zuul 1.x问题
在实际使用中我们会发现直接使用Zuul会存在诸多问题,包括:
- 性能问题
Zuul1x版本本质上就是一个同步Servlet,采用多线程阻塞模型进行请求转发。
简单讲,每来 一个请求,Servlet容器要为该请求分配一个线程专门负责处理这个请求,直到响应返回客户端这个线程才会被释放返回容器线程池。
如果后台服务调用比较耗时,那么这个线程就会被阻塞,阻塞期间线程资源被占用,不能干其它事情。
我们知道Servlet容器线程池的大小是有限制的,当前端请求量大,而后台慢服务比较多时,很容易耗尽容器线程池内的线程,造成容器无法接受新的请求。 - 不支持任何长连接,如websocket
替换方案
- Zuul2.x版本,尚未被Spring Cloud整合
- SpringCloud Gateway
11.2 路由转发
创建子Module
略
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
创建启动类
package com.strive;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
创建配置
server:
port: 8801
spring:
application:
name: gateway-server
cloud:
gateway:
routes:
- id: order-service
uri: http://127.0.0.1:8001/
predicates:
- Path=/order/**
- id:自定义的路由ID,保持唯一
- uri:目标服务地址
- predicates:路由条件。Predicate 接收一个输入参数,返回一个布尔值结果。
该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非)
与Zuul的配置还是很类似的,但有一点,Path=/order/**里的/order/会一起转发到微服务。
这一步完成就可以运行测试了。
如果想要和Zuul一样的效果,统一对order-service开头的服务转发,但不带order-service过去,可以配置:
spring:
cloud:
gateway:
routes:
- id: ...
...
filters:
- RewritePath=/order-service/(?<segment>.*),/$\{segment}
这里支持正则表达式,转发时重写路径,将前面的去掉。
面向服务
一样的,Spring Cloud Gateway也支持面向服务的支持。
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
修改配置
spring:
application:
name: gateway-server
cloud:
gateway:
routes:
- id: order-service
uri: lb://order-service
...
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:7001/eureka
instance:
prefer-ip-address: true
这里只需要将uri改为lb://<微服务名>,并配置eureka客户端即可。
11.3 过滤器
概述
Spring Cloud Gateway除了具备请求路由功能之外,也支持对请求的过滤。
与Zuul网关类似,也是通过过滤器的形式来实现的。
生命周期
Spring Cloud Gateway 的 Filter 的生命周期不像 Zuul 的那么丰富,它只有两个:
- PRE: 这种过滤器在请求被路由之前调用。
我们可利用这种过滤器实现身份验证、在集群中选择 请求的微服务、记录调试信息等。 - POST:这种过滤器在路由到微服务以后执行。
这种过滤器可用来为响应添加标准的 HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
过滤器类型
-
GatewayFilter :应用到单个路由或者一个分组的路由上。
-
GlobalFilter :应用到所有的路由上。
使用
创建一个过滤器类即可
package com.strive.filter;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Component
public class LoginFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange,
GatewayFilterChain chain) {
String token = exchange.getRequest().getQueryParams().getFirst("token");
if (token == null || token.equals("")) {
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
// 继续执行
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 0;
}
}
这里是判断请求参数是否包含token,有则通过,否则置为失败。
11.4 限流
限流算法
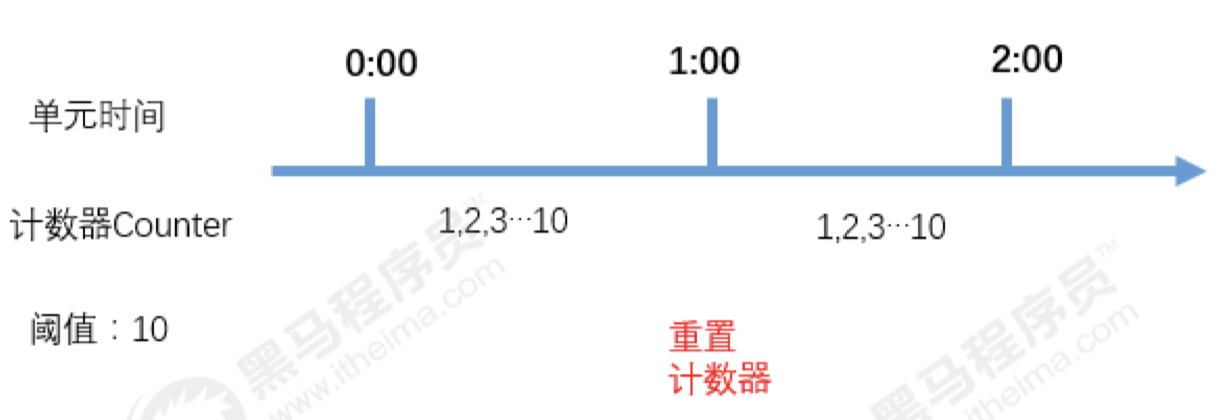
计数器
计数器限流算法是最简单的一种限流实现方式。
其本质是通过维护一个单位时间内的计数器,每次请求 计数器加1,当单位时间内计数器累加到大于设定的阈值,则之后的请求都被拒绝,直到单位时间已经 过去,再将计数器重置为零。
漏桶算法
漏桶算法可以很好地限制容量池的大小,从而防止流量暴增。
漏桶可以看作是一个带有常量服务时间的单服务器队列,如果漏桶(包缓存)溢出,那么数据包会被丢弃。 在网络中,漏桶算法可以控制端口的流量输出速率,平滑网络上的突发流量,实现流量整形,从而为网络提供一个稳定的流量。
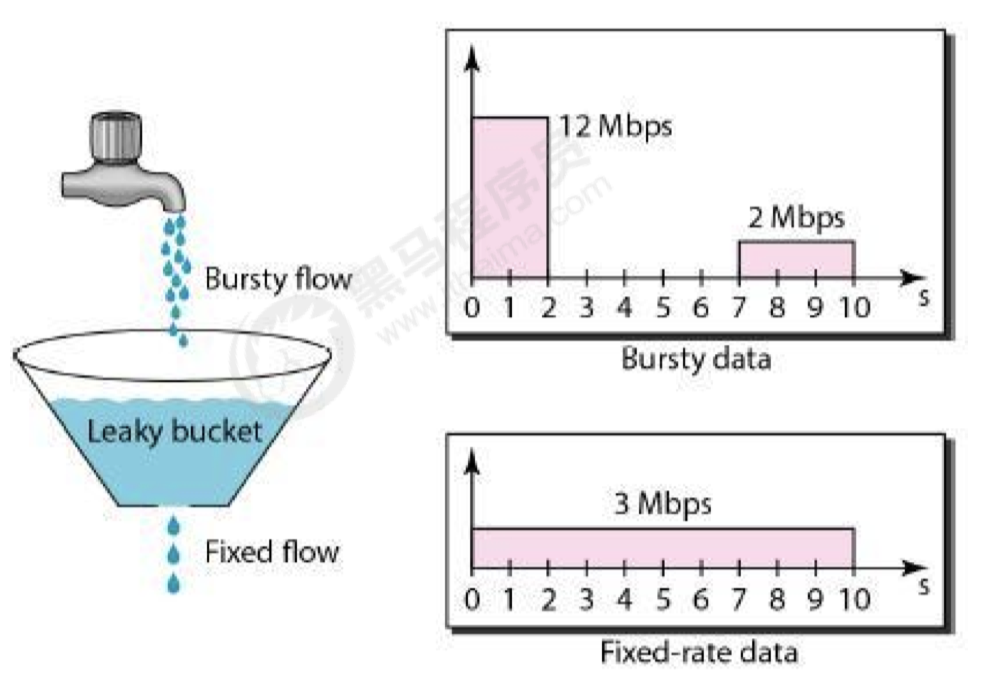
为了更好的控制流量,漏桶算法需要通过两个变量进行控制:
一个是桶的大小,支持流量突发增多时可 以存多少的水(burst)
另一个是水桶漏洞的大小(rate)。
令牌桶算法
令牌桶算法是对漏桶算法的一种改进。
漏桶算法能够限制请求调用的速率,而令牌桶算法能够在限制调用 的平均速率的同时还允许一定程度的突发调用。
在令牌桶算法中,存在一个桶,用来存放固定数量的令牌。
算法中存在一种机制,以一定的速率往桶中放令牌。
每次请求调用需要先获取令牌,只有拿到令牌,才有机会继续执行,否则选择选择等待可用的令牌、或者直接拒绝。
放令牌这个动作是持续不断的进行,如果桶中令牌数达到上限,就丢弃令牌,所以就存在这种情况,桶中一直有大量的可用令牌,这时进来的请求就可以直接拿到令牌执行。
比如设置qps为100,那么限流器初始化完成一秒后,桶中就已经有100个令牌了,这时服务还没完全启动好,等启动完成对外提供服务时,该限流器可以抵挡瞬时的100个请求。
所以,只有桶中没有令牌时,请求才会进行等待,最后相当于以一定的速率执行
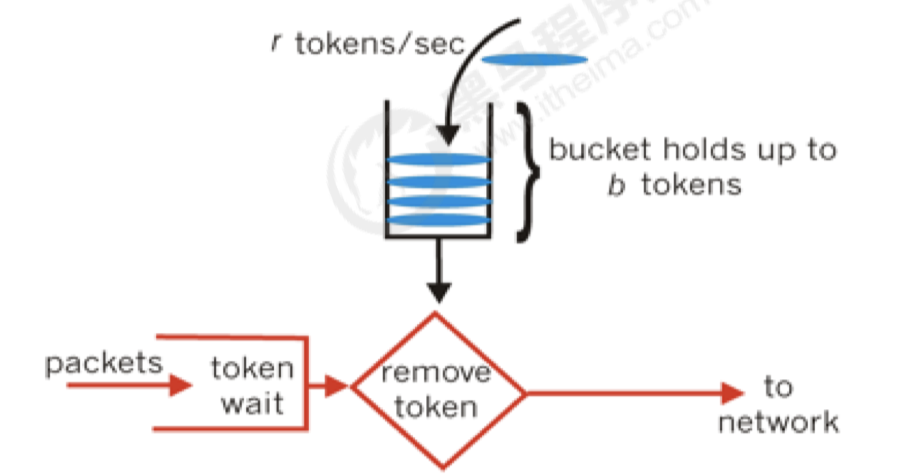
基于filter的限流
SpringCloudGateway官方就提供了基于令牌桶的限流支持。
基于其内置的过滤器工厂 RequestRateLimiterGatewayFilterFactory 实现。
在过滤器工厂中是通过Redis和lua脚本结合的方式进行流量控制
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
运行redis
我这里的redis运行在虚拟机中,而微服务运行在本机,相当于远程访问redis,需要对redis做设置,否则测不出限流效果,而且微服务连不通Redis也不抛错!(参考:https://blog.csdn.net/wxxiangge/article/details/95024214)
设置redis.conf:
- 注释 bind 127.0.0.1行
- 修改protected-mode为no
修改配置
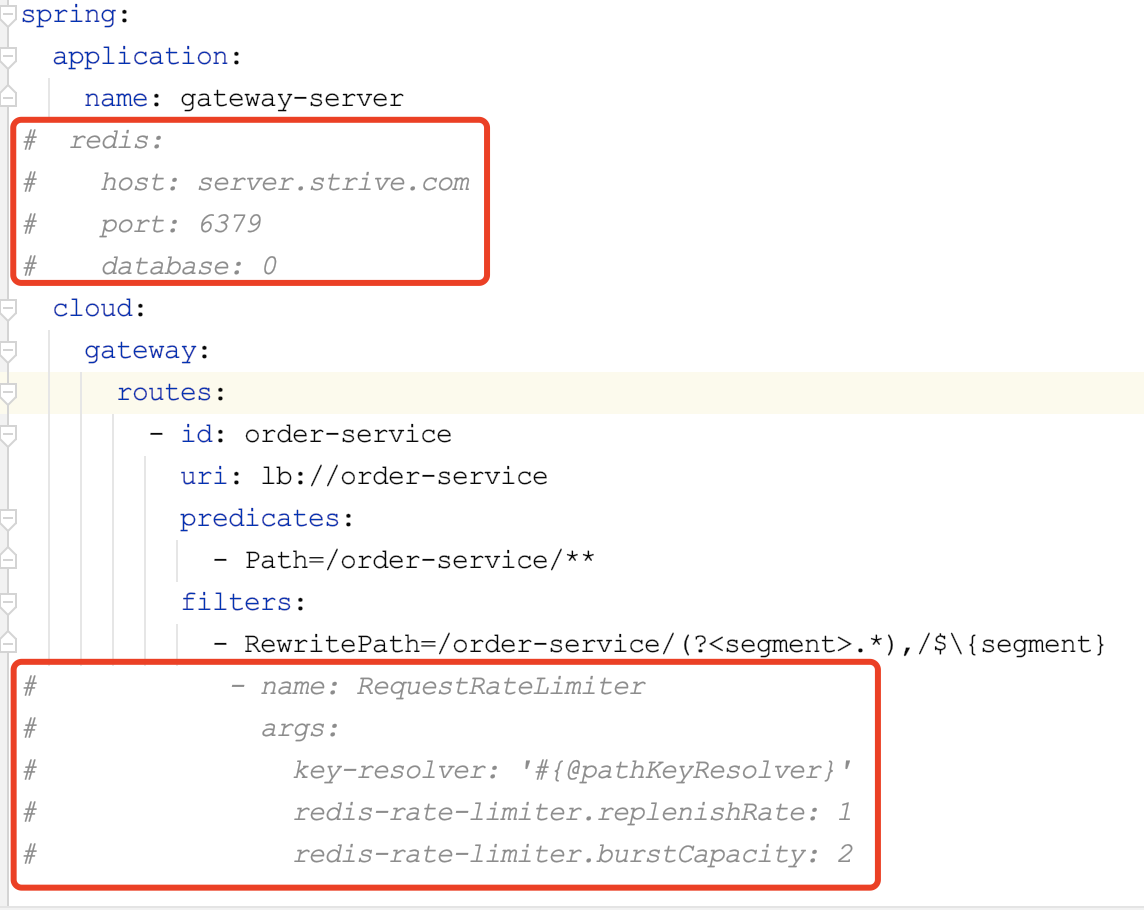
spring:
redis:
host: server.strive.com
port: 6379
database: 0
cloud:
gateway:
routes:
- id:
...
filters:
- name: RequestRateLimiter
args:
key-resolver: '#{@pathKeyResolver}'
redis-rate-limiter.replenishRate: 1
redis-rate-limiter.burstCapacity: 2
这里配置了redis、RequestRateLimiter.
- key-resolver:限流键的解析器的 Bean 名。它使用 SpEL 表达式根据# {@beanName}从 Spring 容器中获取 Bean 对象。
限流对相同的键有效,不同键之间无影响 - redis-rate-limiter.replenishRate:令牌桶每秒填充的个数
- redis-rate-limiter.burstCapacity:每秒最大允许的请求数
创建KeyResolver
package com.strive.configuration;
import org.springframework.cloud.gateway.filter.ratelimit.KeyResolver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Configuration
public class KeyResolverConfiguration {
@Bean
public KeyResolver pathKeyResolver() {
return new KeyResolver() {
@Override
public Mono<String> resolve(ServerWebExchange exchange) {
String path = exchange.getRequest().getPath().toString();
System.out.println(path);
return Mono.just(path);
}
};
}
}
我们这里将请求Path作为键。
测试
这里使用Jmeter测试。
设置了两个线程,各访问3次,访问两个路径:/order/buy/1与/order/buy/2
运行: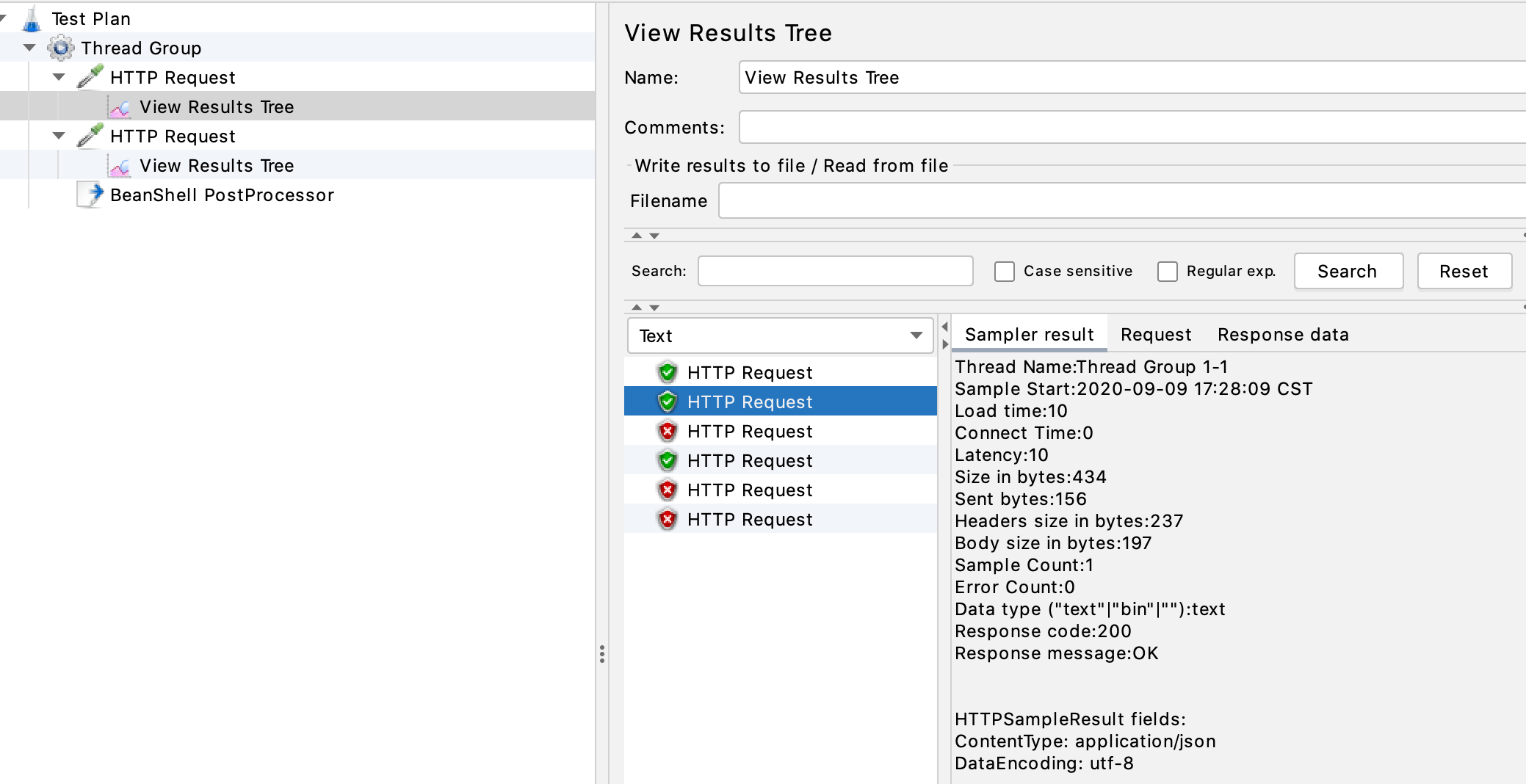
我们设置的是最大2个令牌容量,每秒补充1个。
每个路径发送了6次请求,前2次直接使用已有令牌,成功调用;第3次没有令牌可用,返回失败;
第4个请求在下一秒,自动补充了一个令牌,可以拿来使用,剩下同一秒内的另外2个请求,就失败了。
基于Sentinel的限流
从 1.6.0 版本开始,Sentinel 提供了 Spring Cloud Gateway 的适配模块,可以提供两种资源维度的限 流:
- route 维度:即在 Spring 配置文件中配置的路由条目,资源名为对应的 routeId
- 自定义 API 维度:用户可以利用 Sentinel 提供的 API 来自定义一些 API 分组
Sentinel 1.6.0 引入了 Sentinel API Gateway Adapter Common 模块,此模块中包含网关限流的规则和自定义 API 的实体和管理逻辑:
- GatewayFlowRule:网关限流规则,针对 API Gateway 的场景定制的限流规则,可以针对不同 route 或自定义的 API 分组进行限流,支持针对请求中的参数、Header、来源 IP 等进行定制化的 限流
- ApiDefinition :用户自定义的 API 定义分组,可以看做是一些 URL 匹配的组合。比如我们可以 定义一个 API 叫 my_api ,请求 path 模式为 /foo/** 和 /baz/** 的都归到 my_api 这个 API 分组下面。限流的时候可以针对这个自定义的 API 分组维度进行限流
引入依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-spring-cloud-gateway-adapter</artifactId>
</dependency>
修改配置
注释掉前面Filter限流中,对redis、RequestRateLimiter的配置:
创建限流器
package com.strive.configuration;
import com.alibaba.csp.sentinel.adapter.gateway.common.SentinelGatewayConstants;
import com.alibaba.csp.sentinel.adapter.gateway.common.api.ApiDefinition;
import com.alibaba.csp.sentinel.adapter.gateway.common.api.ApiPathPredicateItem;
import com.alibaba.csp.sentinel.adapter.gateway.common.api.ApiPredicateItem;
import com.alibaba.csp.sentinel.adapter.gateway.common.api.GatewayApiDefinitionManager;
import com.alibaba.csp.sentinel.adapter.gateway.common.rule.GatewayFlowRule;
import com.alibaba.csp.sentinel.adapter.gateway.common.rule.GatewayRuleManager;
import com.alibaba.csp.sentinel.adapter.gateway.sc.SentinelGatewayFilter;
import com.alibaba.csp.sentinel.adapter.gateway.sc.callback.BlockRequestHandler;
import com.alibaba.csp.sentinel.adapter.gateway.sc.callback.GatewayCallbackManager;
import com.alibaba.csp.sentinel.adapter.gateway.sc.exception.SentinelGatewayBlockExceptionHandler;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.Ordered;
import org.springframework.core.annotation.Order;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.codec.ServerCodecConfigurer;
import org.springframework.web.reactive.function.BodyInserters;
import org.springframework.web.reactive.function.server.ServerResponse;
import org.springframework.web.reactive.result.view.ViewResolver;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import javax.annotation.PostConstruct;
import java.util.*;
@Configuration
public class GatewayConfiguration {
private final List<ViewResolver> viewResolvers;
private final ServerCodecConfigurer serverCodecConfigurer;
public GatewayConfiguration(ObjectProvider<List<ViewResolver>> viewResolverProvider,
ServerCodecConfigurer serverCodecConfigurer) {
this.viewResolvers = viewResolverProvider.getIfAvailable(Collections::emptyList);
this.serverCodecConfigurer = serverCodecConfigurer;
}
// 配置异常处理器
@Bean
@Order(Ordered.HIGHEST_PRECEDENCE)
public SentinelGatewayBlockExceptionHandler sentinelGatewayBlockExceptionHandler() {
return new SentinelGatewayBlockExceptionHandler(this.viewResolvers, this.serverCodecConfigurer);
}
// 配置限流过滤器
@Bean
@Order(Ordered.HIGHEST_PRECEDENCE)
public GlobalFilter sentinelGatewayFilter() {
return new SentinelGatewayFilter();
}
// 配置过滤规则
@PostConstruct
public void initGatewayRules() {
Set<GatewayFlowRule> rules = new HashSet<>();
rules.add(new GatewayFlowRule("order-service").setCount(1).setIntervalSec(1)); // 每秒最多1个请求
GatewayRuleManager.loadRules(rules);
}
}
- 基于Sentinel 的Gateway限流是通过其提供的Filter来完成的,使用时只需注入对应的SentinelGatewayFilter 实例以及 SentinelGatewayBlockExceptionHandler 实例即可。
- @PostConstruct定义初始化的加载方法,用于指定资源的限流规则。
这里资源的名称为 order-service ,统计时间是1秒内,限流阈值是1,表示每秒只能访问一个请求
至此可以测试:

自定义异常处理
上面测试限流场景时,得到的是Sentinel的固定字符串,我们可以自定义返回值。
在限流器中添加方法:
@PostConstruct
public void initBlockHandler() {
BlockRequestHandler blockRequestHandler = new BlockRequestHandler() {
@Override
public Mono<ServerResponse> handleRequest(ServerWebExchange serverWebExchange,
Throwable throwable) {
Map errMap = new HashMap();
errMap.put("code", "err001");
errMap.put("message", "哎呀,限流了");
return ServerResponse.status(HttpStatus.TOO_MANY_REQUESTS).contentType(MediaType.APPLICATION_JSON)
.body(BodyInserters.fromValue(errMap));
}
};
GatewayCallbackManager.setBlockHandler(blockRequestHandler);
}
测试:

自定义分组
在限流器中添加方法:
@PostConstruct
public void initApiDefinitions() {
Set<ApiDefinition> apiDefinitions = new HashSet<>();
apiDefinitions.add(new ApiDefinition("order-group").setPredicateItems(new HashSet<ApiPredicateItem>() {{
add(new ApiPathPredicateItem().setPattern("/order-service/**")
.setMatchStrategy(SentinelGatewayConstants.URL_MATCH_STRATEGY_PREFIX));
}}));
GatewayApiDefinitionManager.loadApiDefinitions(apiDefinitions);
}
这里将/order-service/**归到一组,组名为order-group.
然后在initGatewayRules()方法中添加该组的限流规则:
rules.add(new GatewayFlowRule("order-group").setCount(1).setIntervalSec(1));
这样可以更为灵活地设置限流。
本文作者:水木夏
本文链接:https://www.cnblogs.com/star-tong/p/17013635.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步