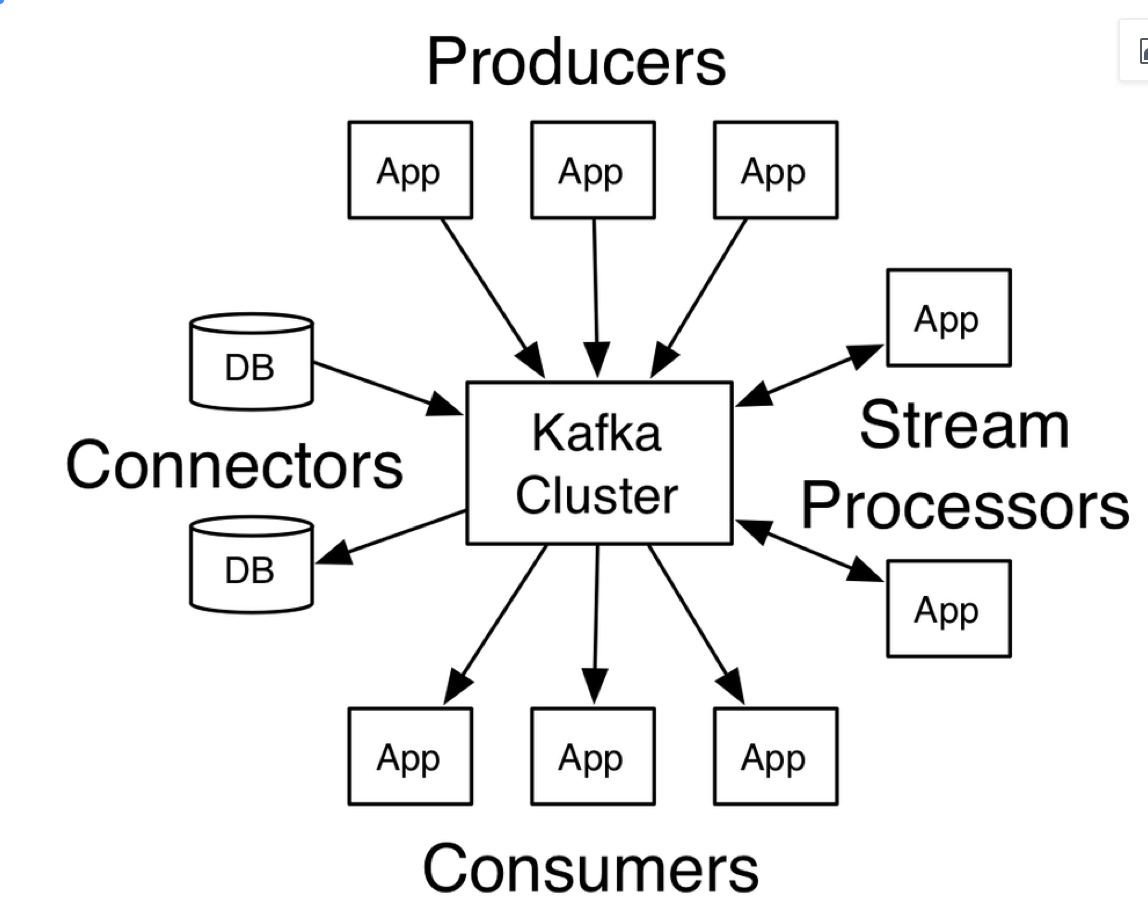
认识kafka
- 理解kafka
Apache kafka是消息中间件的一种,我发现很多人不知道消息中间件是什么,在开始学习之前,我这边就先简单的解释一下什么是消息中间件,只是粗略的讲解,目前kafka已经可以做更多的事情。
举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”kafka“。
鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。
消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是kafka的扩容。
各位现在知道kafka是干什么的了吧,它就是那个"篮子"。
- Kafka的特性:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
- kafka名词解释
- producer:生产者。
- consumer:消费者。
- topic: 消息以topic为类别记录,Kafka将消息种子(Feed)分门别类,每一类的消息称之为一个主题(Topic)。
- broker:以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker;消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
- 每个消息(也叫作record记录,也被称为消息)是由一个key,一个value和时间戳构成。
- 使用场景
1:Building real-time streaming data pipelines that reliably get data between systems or applications.在系统或应用程序之间构建可靠的用于传输实时数据的管道,消息队列功能
2:Building real-time streaming applications that transform or react to the streams of data。构建实时的流数据处理程序来变换或处理数据流,数据处理功能
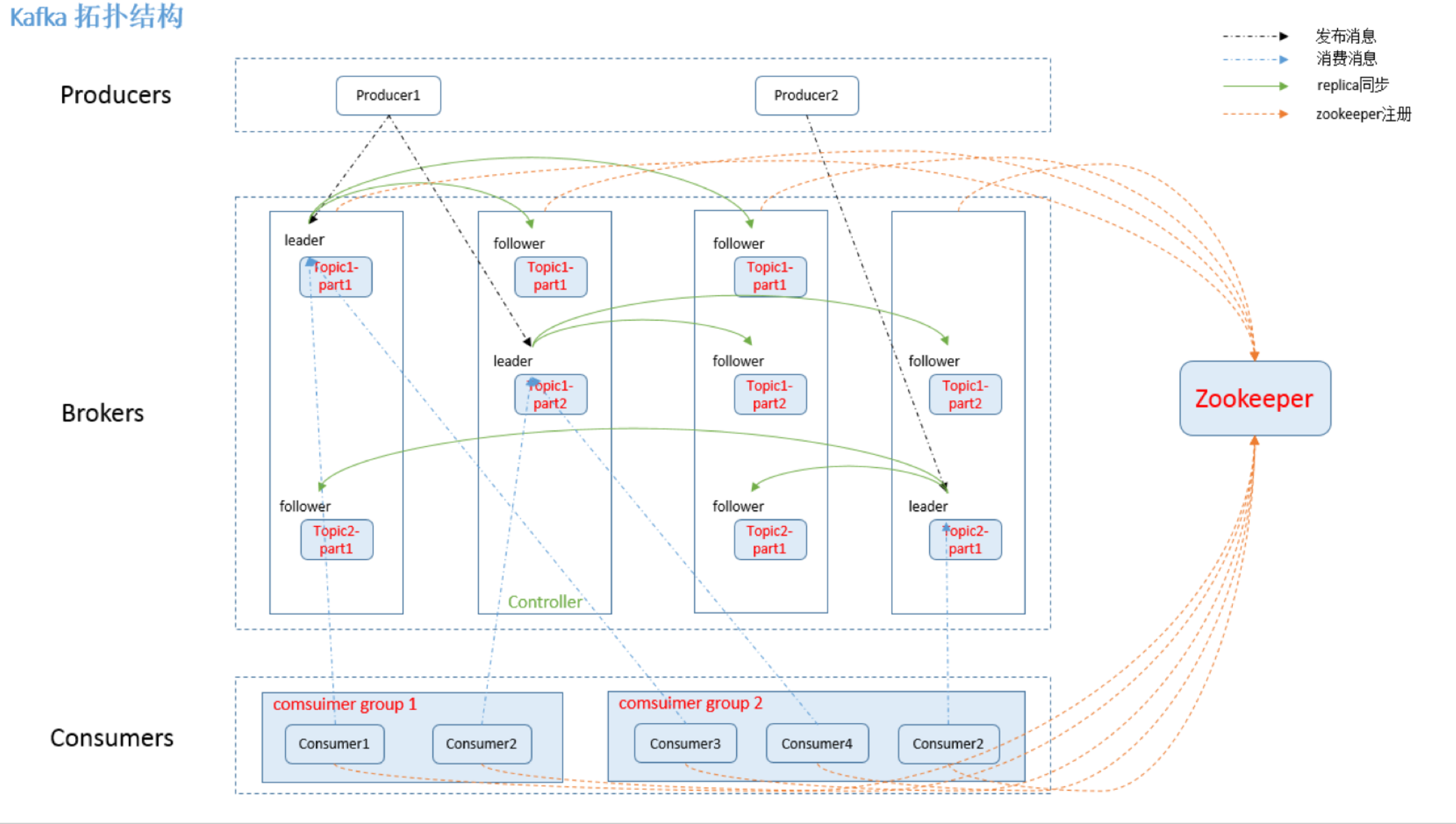
- kafka结构拓扑图
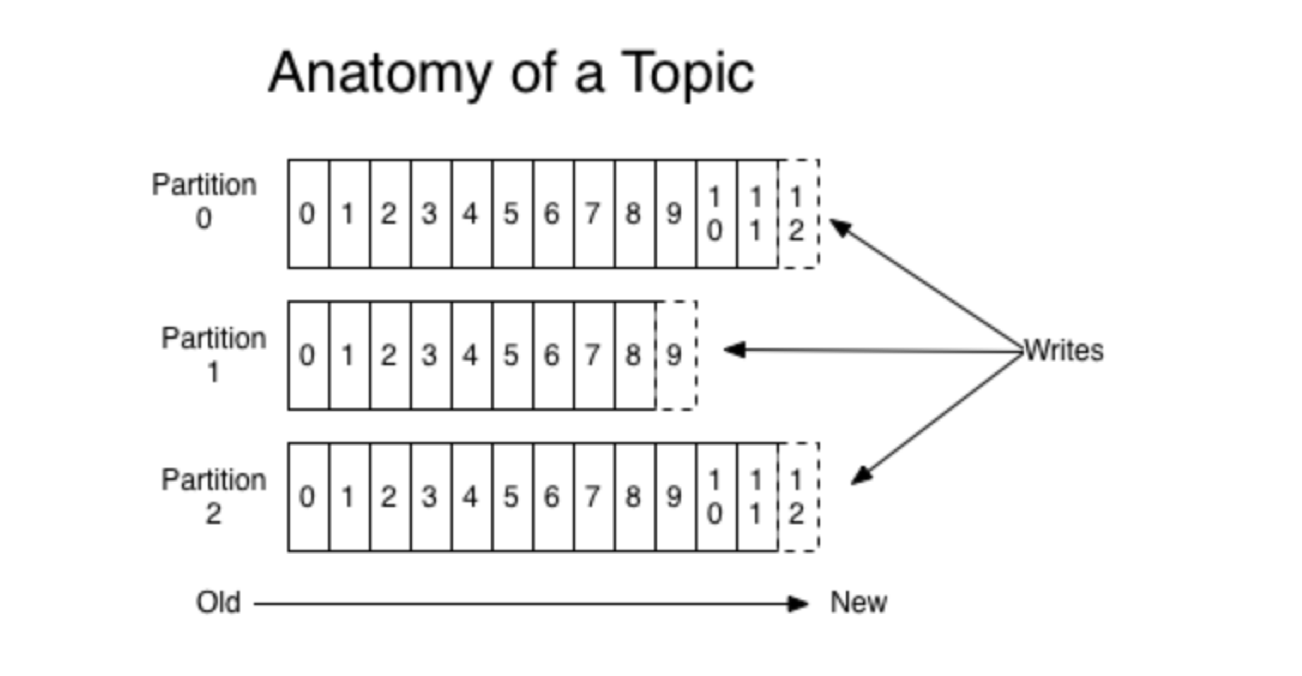
- Topics and Logs
生产者的数据流量按照不同种类分为不同的topic,一个topic可能有多个消费者进行消费。一个topic包含多个分区。
每个分区都是有序的写入日志,每个消息都是按照offset作为唯一标识按照连续顺序存储在分区里面。
生产者向kafka发送消息的时候,可以指定分区进行写入,如果不指定分区,它会按照均衡策略随机写入分区。
producer使用push模式将消息发布到broker,consumer使用pull模式从broker订阅并消费消息。
- Leader选举
Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。为了保证较高的处理效率,消息的读写都是在固定的一个副本上完成。这个副本就是所谓的Leader,而其他副本则是Follower。而Follower则会定期地到Leader上同步数据。
如果某个分区所在的服务器除了问题,不可用,kafka会从该分区的其他的副本中选择一个作为新的Leader。之后所有的读写就会转移到这个新的Leader上。现在的问题是应当选择哪个作为新的Leader。显然,只有那些跟Leader保持同步的Follower才应该被选作新的Leader。
Kafka会在Zookeeper上针对每个Topic维护一个称为ISR(in-sync replica,已同步的副本)的集合,该集合中是一些分区的副本。只有当这些副本都跟Leader中的副本同步了之后,kafka才会认为消息已提交,并反馈给消息的生产者。如果这个集合有增减,kafka会更新zookeeper上的记录。
如果某个分区的Leader不可用,Kafka就会从ISR集合中选择一个副本作为新的Leader。
显然通过ISR,kafka需要的冗余度较低,可以容忍的失败数比较高。假设某个topic有f+1个副本,kafka可以容忍f个服务器不可用。
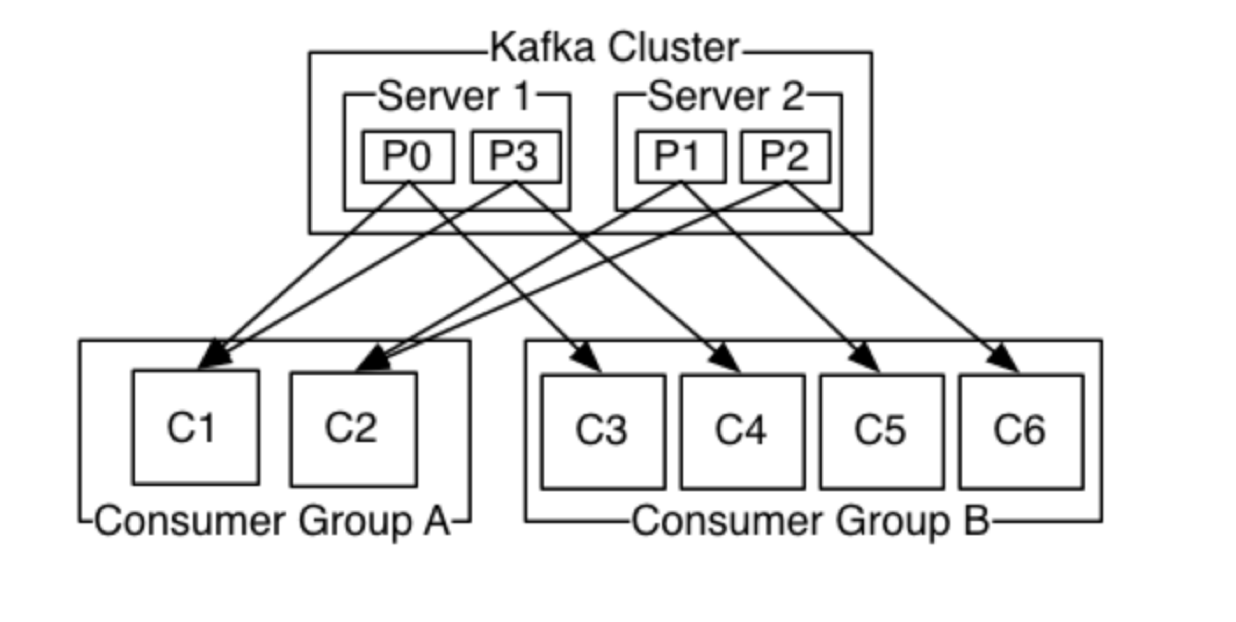
- 消费者
在消费者消费消息时,kafka使用offset来记录当前消费的位置
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
对于一个group而言,消费者的数量不应该多余分区的数量,因为在一个group中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费
因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
- kafka优缺点
优点:
- 可扩展。Kafka集群可以透明的扩展,增加新的服务器进集群。
- 高性能。Kafka性能远超过传统的ActiveMQ、RabbitMQ等,Kafka支持Batch操作。
- 容错性。Kafka每个Partition数据会复制到几台服务器,当某个Broker失效时,Zookeeper将通知生产者和消费者从而使用其他的Broker。
- 持久化:消息被持久化到本地磁盘(线性的按顺序写入磁盘,不会造成阻塞),并且支持数据备份防止数据丢失
缺点:
- 重复消息。Kafka保证每条消息至少送达一次,虽然几率很小,但一条消息可能被送达多次。
- 消息乱序。Kafka某一个固定的Partition内部的消息是保证有序的,如果一个Topic有多个Partition,partition之间的消息送达不保证有序。
- 复杂性。Kafka需要Zookeeper的支持,Topic一般需要人工创建,部署和维护比一般MQ成本更高。
- partiton中segment文件存储结构
partition是分段的,每个段叫LogSegment,包括了一个数据文件和一个索引文件,下图是某个partition目录下的文件:

每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
- segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件.
- segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个全局partion的最大offset(偏移message数)。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
每个segment中存储很多条消息,消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
下面文件列表是笔者在Kafka broker上做的一个实验,创建一个topicXXX包含1 partition,设置每个segment大小为500MB,并启动producer向Kafka broker写入大量数据,如下图2所示segment文件列表形象说明了上述2个规则:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号