
一、pandas简介
二、Series 一维数据对象(“一列”数据,无列名,有索引)
1、Series是一种类似于ndarray一维数组的对象
2、Series创建方式
3、获取值和索引数组:values属性和index属性
4、Series比较像数组和字典的结合体:索引和切片
5、应用:例如表格数据,列名可以当做key
6、Series-整数索引的处理
7、Series-数据对齐
8、Series缺失值NaN的处理
9、Series小结
三、DataFrame -二维数据对象(“多列”数据,有列名,有索引)
1、DataFrame创建方式
2、DataFrame-常用属性
3、DataFrame-索引和切片
4、DataFrame数据对齐与缺失数据处理
5、DataFrame其他常用函数
四、pandas-时间序列
1、转换日期字符串为datetime对象
2、批量转换日期字符串为datatimeIndex序列
3、等长度生成时间序列datatimeIndex
4、datatimeIndex时间序列特殊功能:切片、统计
五、pandas-文件处理:csv读写
1、pandas -- csv读
2、pandas -- csv写
一、pandas简介
1、基于NumPy构建
2、具备对其功能的数据结构DataFrame、Series
3、集成时间序列功能
4、提供丰富的数学运算和操作
5、灵活处理缺失数据
pip install pandas
import pandas as pd
二、Series 一维数据对象(“一列”数据,无列名,有索引)
1、Series是一种类似于ndarray一维数组的对象
由一组数据和一组与之相关的数据标签(索引)组成。
2、Series创建方式
pd.Series([4, 7, -5, 3]) 索引为:0,1,2,3...
pd.Series([4, 7, -5, 3], index=['a','b','c','d'])
pd.Series( numpy.arange(5) ) //从ndarray创建
pd.Series({'a':1, 'b':2}) //从字典创建
pd.Series(0, index=['a','b','c','d'])
3、获取值和索引数组:values属性和index属性
sr.index
sr.values
4、Series比较像数组和字典的结合体:索引和切片
a、支持数组的特性
*从ndarray创建Series: sr = Series( numpy.arange(5) )
*与标量运算:sr*2
*两个Series运算:sr1+sr2
*索引:sr[0], sr[[1,2,4]]
*切片:sr[0:2]
*通用函数:np.abs(sr)
*布尔值过滤:sr[sr>0]
b、支持字典的特性
*从字典创建Series:Series(dic)
*in运算:'a' in sr
*键索引:sr['a']
*花式:sr[ ['a','c'] ] ,sr[ ['a','b','d'] ]
*切片:sr['a':'c']
5、应用:例如表格数据,列名可以当做key
6、Series-整数索引的处理
整数索引的pandas对象往往会使新手抓狂。
例如:sr对象是
10 10
11 11
12 12
13 13
...
sr[10]表示的是什么呢?默认解释为标签,
如果索引是整数类型,则根据整数进行下标获取值时总是面向标签的。
解决方法:loc属性(将索引解释为标签)和iloc属性(将索引解释为下标)
这时候--
sr.loc[10]:解释为标签
sr.iloc[10]:解释为下标
7、Series-数据对齐
例:
sr1=pd.Series([12,23,34], index=['c','a','d'])
sr1=pd.Series([11,20,10], index=['d','c','a'])
pandas在进行两个Series对象的运算时,会按标签key进行对齐,然后计算。
例:
sr1=pd.Series([12,23,34], index=['c','a','d'])
sr1=pd.Series([11,20,10], index=['b','c','a'])
sr1+sr2两列相加,如果一个里面有b标签,另外一个没有,默认相加会出现NAN
如何使结果在'b'处值为11,在索引'd'处的值为34?
答案:sr1.add(sr2, fill_value=0) # 没有的那个标签会被fill成0
灵活的算术方法:add, sub, div, mul 对应+-*/
8、Series缺失值NaN的处理
a、删掉缺失数据
sr=[ {'a':33.0,
'b':NaN,
'c':32.0,
'd':NaN} ]
sr.isnull() [a:False,b:True, c:False,d:True]
sr.notnull() [a:True, b:Fasle,c:True, d:False]
扔掉缺失数据: sr[sr.notnull()] 或 sr.dropna()
b、填充缺失数据
NaN变为0: sr.fillna(0) #不会改sr, 要保存要重新赋值
NaN变为平均值: sr.fillna(sr.mean())
9、Series小结
Series是数组+字典的集合体
特点:按下标,按key,切片...
整数索引:loc和iloc
数据对齐:默认是按标签对齐
缺失值处理:对不齐的出现NAN,扔掉NaN或者填充NaN
三、DataFrame -二维数据对象(“多列”数据,有列名,有索引)
*DataFrame是一个表格型的数据结构,含有一组有序的列。
DataFrame可以被看做是由Series组成的字典,并且共用一个索引。
1、DataFrame创建方式
pd.DataFrame({'one':[1,2,3,4], 'two':[4,3,2,1]}) # 共两列one和two,行自动生成整数

pd.DataFrame( {'one':[1,2,3,4], 'two':[4,3,2,1]}, index=['a','b','c','d']) # 共两列one和two,行'a','b','c','d'

pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']), 'two':pd.Series([1,2,3,4],index=['a','b','c','d'])}) # d列是NaN,第一列'one'都被调整为浮点型,第二列'two'是整数
*csv文件读取与写入:
# 读取:第一行自动解释为列名,行名为自增整数
df.read_csv('xy.csv')
# 保存:
df.to_csv('save.csv')
2、DataFrame-常用属性
1、index 获取行索引(第一列)
2、T 转置(行列转换,类型也会转换)
3、colums 获取列索引(第一行)
4、values 获取值numpy数组(二维)
5、describe() 获取快速统计
对每一列做的一些统计,数量,平均数,最大最小值等
3、DataFrame-索引和切片
1、DataFrame是一个二维数据类型,所以有行索引和列索引
2、DataFrame同样可以通过标签和位置两种方法进行索引和切片
3、loc属性和iloc属性
使用方法:逗号隔开,前面是行索引,后面是列索引
行/列索引部分可以是常规索引、切片、布尔值索引、花式索引任意搭配
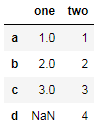
------------
one two
a 1.0 2
b 2.0 1
c 3.0 3
d NaN 4
------------
取1.0: df.loc['a','one']
取第一行:df.loc['a',:]
获取ac行:df.loc[['a','c'],:]
4、DataFrame数据对齐与缺失数据处理
1、DataFrame对象在运算时,同样会进行数据对齐,其行索引和列索引分别对齐
2、DataFrame处理缺失数据的相关方法:填充或删除
fillna(0) # 填充缺失数据,用0替换NaN
isnull() # 返回二维布尔数组对象
notnull() # 返回二维布尔数组对象
dropna(axis=0/1, how='all'/'any') # 整行或整列删除缺失数据 (axis=0表示行,axis=1表示列,how='all'表示所有为NaN才删,how='any'表示有一个为NaN就删)
5、DataFrame其他常用函数
1 mean(axis=0,skipna=False) # 对列(行)求平均值(skipna=True默认,表示平均值NaN不参与计算,skipna=False表示NaN参与计算,结果也为NaN)
2 sum(axis=1) 对列(行)求和
3 sort_index(axis,..,ascending) # 对列(行)索引排序
4 sort_values(by,axis,ascending) #对某列(行)的值排序,by指定列(行),ascending升序降序,NaN不参与排序,统一放在最后
5 NumPy的通用函数同样适用于pandas
四、pandas-时间序列
时间序列类型:
1,时间戳:特定时刻
2,固定时期:如2017年7月
3,时间间隔:起始时间-结束时间
python标准库处理时间对象:datetime
pandas灵活处理时间对象:dateutil -- dateutil.parser.parse()
成组处理时间对象:pandas -- pd.to_datetime()
1、转换日期字符串为datetime对象
可以转换各种类型字符串
import dateutil
dateutil.parser.parse('2001-01-01')
dateutil.parser.parse('2001/01/01')
dateutil.parser.parse('2001-JAN-01')
2、批量转换日期字符串为datatimeIndex序列
时间序列就是以时间对象为索引的Series或DataFrame,datatime对象作为索引时是存储在datatimeIndex对象中的
pd.to_datetime(['2001-01-01','2010/Feb/12'])
3、等长度生成时间序列datatimeIndex
pd.date_range(start,end,periods,freq)
start:开始时间
end:结束时间
periods:时间长度
freq:时间频率,默认为'D',可选H(our),W(eek),B(usiness),S(emi-)M(onth),T(min),S(econd),A(year),1h20min这种也行
# W:每周 W-MON:每周一 B:工作日
pd.date_range('2010-01-01',periods=60,freq='W')
4、datatimeIndex时间序列特殊功能:切片、统计
传入"年"或“年月”作为切片方式
传入日期范围作为切片方式
丰富的函数支持:resample(), truncate(),...
例如:
sr=pd.Series(np.arange(100), index=pd.date_range('2017-01-01',periods=100)) # 创建时间序列
sr['2017-03'] 选取的是2017-3-1至2017-3-31的
sr['2017-1-1':'2018-2-1'] 选取范围
sr.resample('W').sum() 看每周的和
sr.resample('W').mean() 看每周平均值
sr.truncate(before='2018-2-3') 用处不大一般用":"切片
五、pandas-文件处理:csv读写
pandas支持的数据源类型:
csv,json, XML, HTML, 数据库, pickle, excel...
这里拿csv来举例:
1、pandas -- csv读
------------------------------------------------------
数据文件常用格式:csv(以某间隔符分割数据)
pandas读取文件: pd.read_csv(...) --默认分隔符为逗号 或 read_table(...) --默认分隔符为制表符
主要参数:
sep: 指定分隔符,可用正则表达式
header=None 指定文件无列名
names 指定列名
index_col 指定某列作为索引
skip_row 指定跳过某些行
na_values 指定某些字符串表示缺失值,例如单元格里有None,Null等na_values=['None','Null']
parse_dates 指定某些列是否被解析为日期,类型为布尔或列表
------------------------------------------------------
pd.read_csv('xy.csv', index_col='date') # 选date列做索引
pd.read_csv('xy.csv', index_col='date', parse_dates=True) #选date列做索引,所有能转为时间的,全转为datetime
pd.read_csv('xy.csv', index_col='date', parse_dates=['date']) #选date列做索引,把指定的列变为datetime
pd.read_csv('xy.csv', index_col=0) #第一列做索引
pd.read_csv('xy.csv',header=None) #如果csv里面从第一行开始就是数据,没有列名,自动生成自增的列名
pd.read_csv('xy.csv',header=None,names=['id','count','value']) #没有列名指定列名
2、pandas -- csv写
写入到csv文件:to_csv函数
该函数主要参数:
sep 指定文件分隔符
na_rep 指定缺失值转换的字符串,默认为空字符串
header=False 不输出列名一行
index=False 不输出行索引一列
cols 指定输出的列,传入列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号