Ceph Health_err osd_full等问题的处理
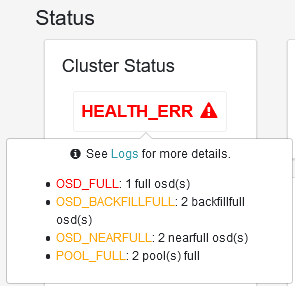
客户端无法再写入,卡在某处
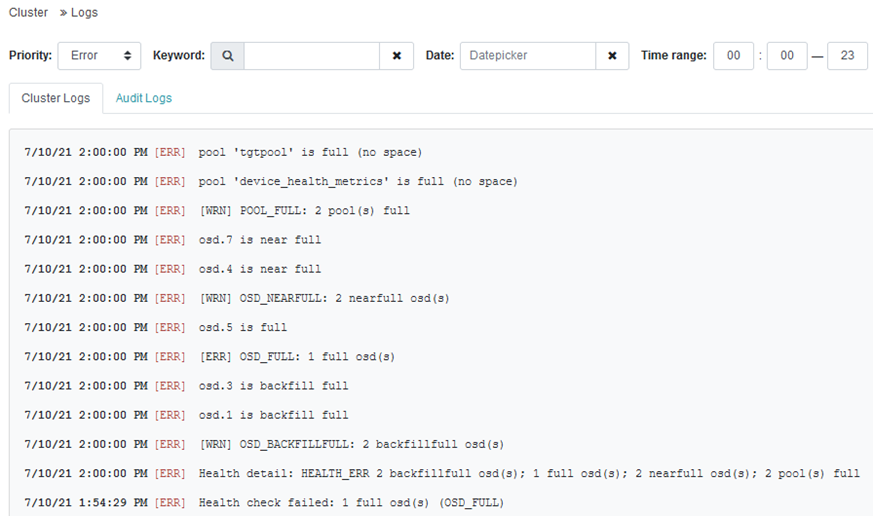
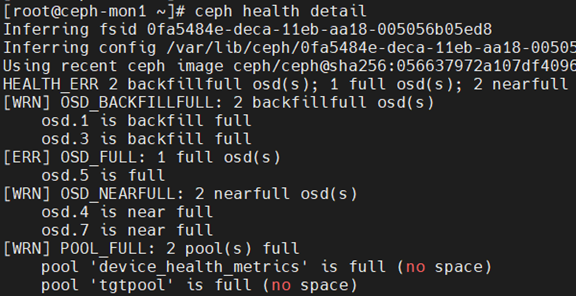
检查结果:
ceph health detail
ceph df

ceph osd df
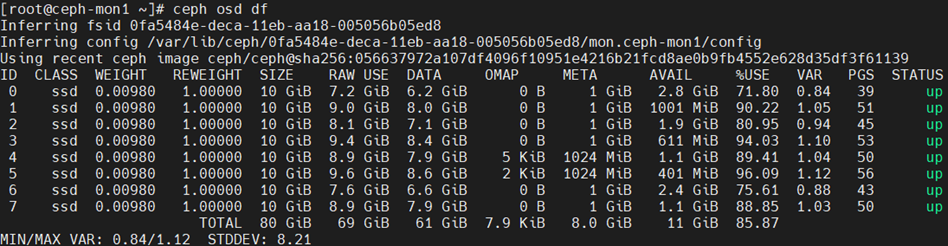
ceph osd dump | grep full_ratio

网络的解决方法:
1. 设置 osd 禁止读写
ceph osd pause
2. 通知 mon 和 osd 修改 full 阈值
ceph tell mon.* injectargs "--mon-osd-full-ratio 0.96"
ceph tell osd.* injectargs "--mon-osd-full-ratio 0.96"
3. 通知 pg 修改 full 阈值
ceph pg set_full_ratio 0.96 (Luminous版本之前)
ceph osd set-full-ratio 0.96 (Luminous版本)
4. 解除 osd 禁止读写
ceph osd unpause
5. 删除相关数据
最好是 nova 或者 glance 删除
也可以在 ceph 层面删除
6. 配置还原
ceph tell mon.* injectargs "--mon-osd-full-ratio 0.95"
ceph tell osd.* injectargs "--mon-osd-full-ratio 0.95"
ceph pg set_full_ratio 0.95 (Luminous版本之前)
ceph osd set-full-ratio 0.95 (Luminous版本)
按以上方法,在ceph version 15.2.13 octopus 环境下测试报错
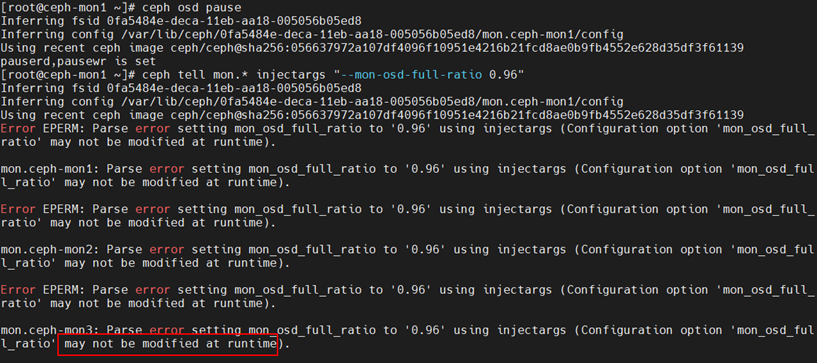
最终在官网找到了解决方法:
https://docs.ceph.com/en/latest/rados/operations/health-checks/#pool-near-full
OSD_FULL
One or more OSDs has exceeded the full threshold and is preventing the cluster from servicing writes.
Utilization by pool can be checked with:
ceph df
The currently defined full ratio can be seen with:
ceph osd dump | grep full_ratio
A short-term workaround to restore write availability is to raise the full threshold by a small amount:
ceph osd set-full-ratio <ratio>
New storage should be added to the cluster by deploying more OSDs or existing data should be deleted in order to free up space.
OSD_BACKFILLFULL
One or more OSDs has exceeded the backfillfull threshold, which will prevent data from being allowed to rebalance to this device. This is an early warning that rebalancing may not be able to complete and that the cluster is approaching full.
OSD_NEARFULL
One or more OSDs has exceeded the nearfull threshold. This is an early warning that the cluster is approaching full.
OSDMAP_FLAGS
One or more cluster flags of interest has been set. These flags include:
- full - the cluster is flagged as full and cannot serve writes
- pauserd, pausewr - paused reads or writes
- noup - OSDs are not allowed to start
- nodown - OSD failure reports are being ignored, such that the monitors will not mark OSDs down
- noin - OSDs that were previously marked out will not be marked back in when they start
- noout - down OSDs will not automatically be marked out after the configured interval
- nobackfill, norecover, norebalance - recovery or data rebalancing is suspended
- noscrub, nodeep_scrub - scrubbing is disabled
- notieragent - cache tiering activity is suspended
With the exception of full, these flags can be set or cleared with:
ceph osd set <flag>
ceph osd unset <flag>POOL_FULL
One or more pools has reached its quota and is no longer allowing writes.
Pool quotas and utilization can be seen with:
ceph df detail
You can either raise the pool quota with:
ceph osd pool set-quota <poolname> max_objects <num-objects>
ceph osd pool set-quota <poolname> max_bytes <num-bytes>or delete some existing data to reduce utilization.
设置 osd 禁止读写
ceph osd pause
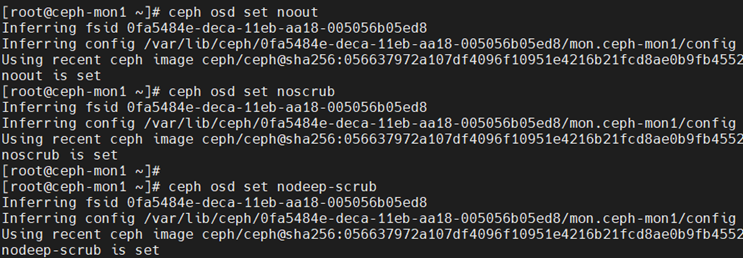
设置集群标记,避免恢复过程中其他任务引发其他问题
ceph osd set noout
ceph osd set noscrub
ceph osd set nodeep-scrub
![]()
ceph osd set-full-ratio 0.96 (不能调太高,要不再次到阈值了就没得再调整了)
ceph osd set-backfillfull-ratio 0.92
ceph osd set-nearfull-ratio 0.9
![]()
ceph osd dump | grep full_ratio
![]()
调整后,ceph显示Health OK
趁ceph临时可操作osd,赶紧整理删除没用的image数据或增加新的磁盘同步降低平均值。
cephadm shell -- ceph orch daemon add osd ceph-mon1:/dev/sdd
cephadm shell -- ceph orch daemon add osd ceph-mon2:/dev/sdd
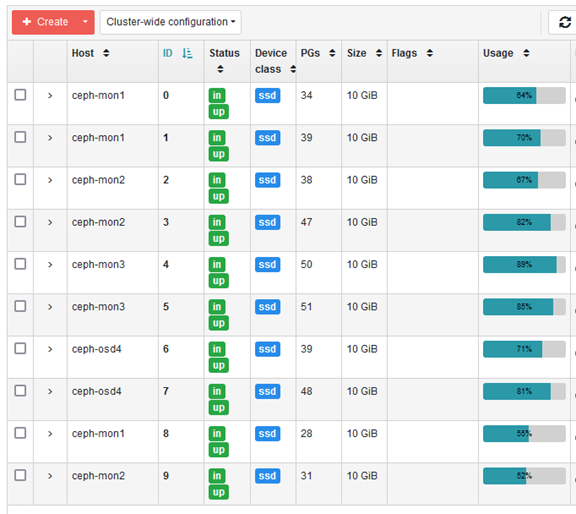
添加两磁盘后,使用率自动均衡降低了。
![]()
正常后恢复为初始值
ceph osd set-full-ratio 0.95
ceph osd set-backfillfull-ratio 0.90
ceph osd set-nearfull-ratio 0.85
最后解除OSD的禁止读写和群集标记
ceph osd unpause
ceph osd unset noout
ceph osd unset noscrub
ceph osd unset nodeep-scrub
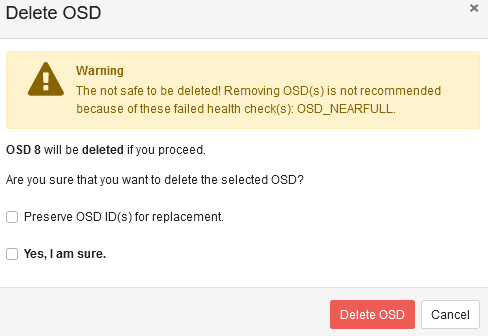
如果要删除OSD,需确保ceph是健康状态才操作。
![]()
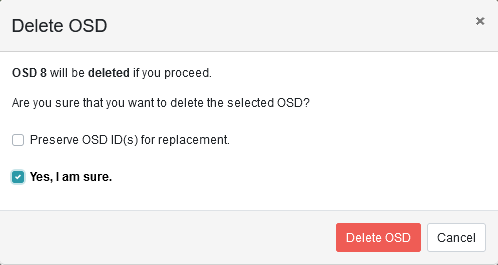
Health状态下无警告。
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号