re模块
一、正则表达式
正则表达式的定义:只跟字符串有关,是一种规则,来约束字符串的规则
使用场景:
① 判断某一个字符串是否符合规则(注册页-表单验证)
② 将符合规则的内容从一个庞大的字符串体系当中提取出来(爬虫、日志分析)
字符串格式:[]
一个字符组只能约束一个字符的内容
在字符组中所有的字符都可以匹配任意一个字符位置上能出现的内容,如果在字符串中有任意一个字符是字符组中的内容,那么就是匹配上的项
字符组是元字符的一个
一个字符不满足才使用字符组[]
匹配所有的数字是从小到大,所有的范围根据ascii编码,编码小的值指向大的值
数字[0-9]
大写字母[A-Z]
小写字母[a-z]
数字或者字母[0-9a-zA-Z]
元字符:
-
\d : 任何数字
-
\D : 不是数字
-
\s : 任何 white space, 如 [\t\n\r\f\v]
-
\S : 不是 white space
-
\w : 任何大小写字母, 数字和下划线 [a-zA-Z0-9]
-
\W : 不是 \w
-
\b : 空白字符 (只在某个字的开头或结尾)
-
\B : 空白字符 (不在某个字的开头或结尾)
-
\\ : 匹配 \
-
. : 匹配任何字符 (除了 \n) (在字符组里是普通的点)
-
^ : 匹配开头
-
$ : 匹配结尾
-
? : 前面的字符可有可无
-
a|b:匹配字符a或字符b(较长的放在前面)
-
() :匹配括号内的表达式,也表示一个组
-
[...] :匹配字符组中的字符
-
[^...] :匹配除了字符组中字符的所有字符
-
\n 匹配一个换行符
-
\t 匹配一个制表符
量词(一个量词跟在元字符后面,并且约束一个元字符):
-
*: 重复零次或多次 -
+: 重复一次或多次 -
?:重复零次或者一次
-
{n, m}: 重复 n 至 m 次 -
{n}: 重复 n 次 -
{n} :重复n次或以上
分组:
我们甚至可以为找到的内容分组, 使用 () 能轻松实现这件事. 通过分组, 我们能轻松定位所找到的内容. 比如在这个 (\d+) 组里, 需要找到的是一些数字, 在 (.+) 这个组里, 我们会找到 “Date: “ 后面的所有内容. 当使用 match.group() 时, 他会返回所有组里的内容, 而如果给 .group(2) 里加一个数, 它就能定位你需要返回哪个组里的信息.
match = re.search(r"(\d+), Date: (.+)", "ID: 021523, Date: Feb/12/2017")
print(match.group()) # 021523, Date: Feb/12/2017
print(match.group(1)) # 021523
print(match.group(2)) # Date: Feb/12/2017
有时候, 组会很多, 光用数字可能比较难找到自己想要的组, 这时候, 如果有一个名字当做索引, 会是一件很容易的事. 我们字需要在括号的开头写上这样的形式 ?P<名字> 就给这个组定义了一个名字. 然后就能用这个名字找到这个组的内容.
match = re.search(r"(?P<id>\d+), Date: (?P<date>.+)", "ID: 021523, Date: Feb/12/2017")
print(match.group('id')) # 021523
print(match.group('date')) # Date: Feb/12/2017
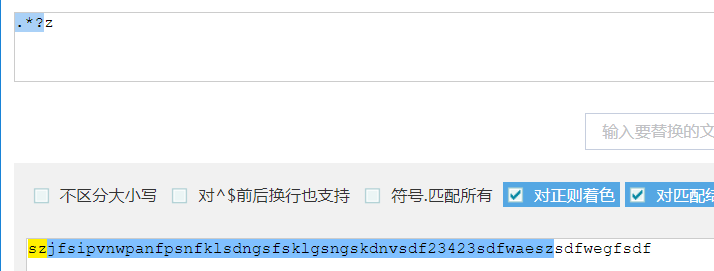
贪婪匹配:尽量匹配多的字符,贪婪匹配的算法是回溯算法
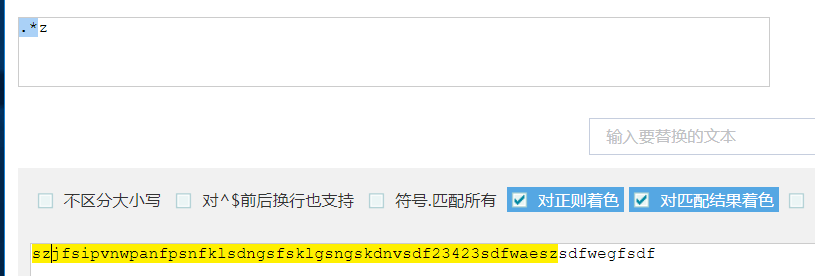
惰性匹配(非贪婪匹配):尽量少匹配
逐个字符的匹配是不是最后一个,遇到就停
使用方式:在量词后面加?
常用.*?x 表示任意字符任意长度,遇到x就立即停止
![]()
转义符
在正则表达式转移后,在python中加r
比如:r'\\n'
二、re模块的方法
import re
findall
语法:re.findall(正则表达式,字符串)
不节省内存
使用方式:接收两个参数,正则表达式和待匹配的字符串,返回值是一个列表,所有匹配到的项
import re
ret = re.findall('\d+','sdfsdf2sfdfws345sfsdf3435234sfsgwsg') print(ret) # ['2', '345', '3435234']
findall的特点:会优先显示分组中的内容(即先显示括号的内容),在括号里面加?:取消分组优先
ret = re.findall('(www)\.(baidu|google)\.(com)','www.baidu.com')
print(ret) # [('www', 'baidu', 'com')]
search
re.search(正则表达式,字符串)
返回时一个SRE_Match对象,要通过对象.group()取值,且只包含第一个匹配到的值
没匹配到值会返回None,先用if判断
节省内存
import re
ret = re.search('\d','sdfwqfsddfsdfsdf') print(ret) # None if ret: print(ret)
对象.group(n) 数字,可以分别获取分组的内容
import re
ret = re.search('(www)\.(baidu|google)\.(com)','www.baidu.com') print(ret.group()) # www.baidu.com print(ret.group(1)) # www print(ret.group(2)) # baidu
解决分组中的小数问题
① 获取字符串的全部整数和小数
import re
ret = re.findall('\d+\.\d+|\d+','1+2-3+(4.5-5)*7/8')
print(ret) # ['1', '2', '3', '4.5', '5', '7', '8']
② 获取字符串的全部整数
import re
ret = re.findall('\d+\.\d+|(\d+)','1+2-3+(4.5-5)*7/8')
print(ret) # ['1', '2', '3', '', '5', '7', '8']
ret.remove('')
print(ret) # ['1', '2', '3', '5', '7', '8']
match
语法:re.match(正则表达式,字符串)
返回的结果是一个对象,对象里有索引和match的值,要通过group()获取值
match就是给正则表达式加了^,只匹配开头
同样的search也能实现match的方法,在开头加^
① 开头无检测到正则表达式的结果,无匹配值,返回None
import re
ret = re.match('\d+','sdfsdf234234sdfsdf2f33423sdf234')
print(ret) # None
② 匹配到结果会返回一个对象,通过group()方法取值
import re
ret = re.match('\d+','123s234dfsdf234234sdfsdf2f33423sdf234')
print(ret) # <_sre.SRE_Match object; span=(0, 3), match='123'>
print(ret.group()) # 123
③ search模拟match方法
import re
ret = re.search('^\d+','123s234dfsdf234234sdfsdf2f33423sdf234')
print(ret) # <_sre.SRE_Match object; span=(0, 3), match='123'>
print(ret.group()) # 123
split 切割
语法:re.split(正则表达式,待切割的字符串)
split根据正则表达式来切割
正则表达式加上分组,结果会同时保留分组的内容
import re
ret = re.split('\d+','abcde12345zxcvb6789mnlk098aa')
print(ret) # ['abcde', 'zxcvb', 'mnlk', 'aa']
ret = re.split('(\d+)','abcde12345zxcvb6789mnlk098aa') # 正则表达式加分组
print(ret) # ['abcde', '12345', 'zxcvb', '6789', 'mnlk', '098', 'aa'
sub 替换
语法:re.sub(’正则表达式',新的值,替换的字符串,替换个数(可不填))
返回替换后的结果
import re
ret1 = re.sub('\d+','-','abcde12345zxcvb6789mnlk098aa') # 把数字替换成-
print(ret1) # abcde-zxcvb-mnlk-aa
ret2 = re.sub('\d+','-','abcde12345zxcvb6789mnlk098aa',2) # 把数字替换成-,替换2次
print(ret2) # abcde-zxcvb-mnlk098aa
subn 替换
语法:re.sub(’正则表达式',新的值,替换的字符串,替换个数(可不填))
返回替换后结果和替换的次数的元组
import re
ret1 = re.subn('\d+','-','abcde12345zxcvb6789mnlk098aa') # 把数字替换成-
print(ret1) # ('abcde-zxcvb-mnlk-aa', 3)
ret2 = re.subn('\d+','-','abcde12345zxcvb6789mnlk098aa',2) # 把数字替换成-,替换2次
print(ret2) # ('abcde-zxcvb-mnlk098aa', 2)
finditer
语法:re.finditer(正则表达式,待匹配的字符串)
finditer是节省空间的方法,返回的结果是迭代器。
通过for返回的是对象,需要通过group()方法取值
import re
ret = re.finditer('\d+','abcde12345zxcvb6789mnlk098aa')
print(ret) # 得到的是迭代器 <callable_iterator object at 0x000002A12B4481D0>
for i in ret:
print(i) # 循环迭代器返回一个对象 <callable_iterator object at 0x000001B46CFD8550>
print(i.group()) # 通过对象.group()取值 12345
'''
<callable_iterator object at 0x000001B46CFD8550>
<_sre.SRE_Match object; span=(5, 10), match='12345'>
12345
<_sre.SRE_Match object; span=(15, 19), match='6789'>
6789
<_sre.SRE_Match object; span=(23, 26), match='098'>
098
'''
compile
每次使用正则表达式,机器都会进行编译,编译过程如下:
正则表达式 --> re模块 翻译 --> 字符串操作 --> 编译 --> 字节码 --> 解释器执行代码
语法 re.compile(正则表达式) 返回的是编译后的规则,用变量接收
使用变量来调用re的方法,不需要传入表达式
同时可以配合finditer使用,即节省时间又节省空间
import re
com = re.compile('\d+') # 把正则表达式编译
ret = com.findall('abcde12345zxcvb6789mnlk098aa') # 通过编译后的结果来执行re的方法
print(ret) # ['12345', '6789', '098']
re方法中flag参数:
flags有很多可选值:
re.I(IGNORECASE)忽略大小写,括号内是完整的写法
re.M(MULTILINE)多行模式,改变^和$的行为
re.S(DOTALL)点可以匹配任意字符,包括换行符
re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用
re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag
re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
分组命名
语法:<(?P<name>.*?)>.*?</(?P=name)>
一般用于获取网页的信息,根据标签筛选
结果能获取标签的内容,同时也能获取标签
import re
pattern = '<(?P<name>.*?)>(.*?)</(?P=name)>'
ret = re.search(pattern,'<a>表情</a>')
print(ret.group()) # <a>表情</a>
print(ret.group(2)) # 表情
print(ret.group('name')) # a
使用\1复用第一个分组的内容
import re
pattern = r'<(.*?)>.*?</\1>'
ret = re.search(pattern,'<a>表情</a>')
print(ret.group()) # <a>表情</a>
print(ret.group(1)) # a
使用\1复用第一个分组的内容
import re
pattern = '<(.*?)>.*?</\\1>'
ret = re.search(pattern,'<a>表情</a>')
print(ret.group()) # <a>表情</a>
print(ret.group(1)) # a
分组约束:
(?:正则表达式) 表示取消优先显示功能
(?P<组名>正则表达式) 表示给这个组起一个名字
(?P=组名) 表示引用之前组的名字,引用部分匹配到的内容必须和之前那个组中的内容一模一样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号