
读《现代前端技术解析》有感
一、简单介绍
这本书标榜的是现在前端技术,但是里面设计到的部分技术还是相对比较落后的,但不妨碍这本书成为一本好的查漏补缺的指南,如果是在实际的工作中这本书可以说是起不到什么的效果,但是对于即将毕业,或者刚刚出来工作,又或者是求职找工作的人来说可以起到极好的引导作用,日常面试的各个方面都有涉及(仅针对小公司的面试),但是不深刻。里面重点展示的是技术的应用层面上的东西,所以也比较好理解,一些像设计模式,算法,数据结构,JS语法深入部分这本书不曾提及,所以如果为了全面了解,为了找工作,建议读一读这本书;为了更好地工作,还是建议大家抽空看看经典的读物。
二、重点知识梳理
2.1 web Component
一种原生的支持模块化的方法,但是目前仅仅在chrome新版得到全面的支持,其他浏览器暂时不支持此特性,这个特性的好处是可以直接将模块与页面进行解耦操作,目前虽然原生没有全面的支持,但是通过webpack打包等形式都已经可以实现了,例如vue中的模块化开发就是基于这个思想。目前虽然不是主流,但是未来可能会成为一种标准。
用法是通过document.registerElement接口来注册。
例如,我们注册一个插件名为X-foo,那么我们这样操作
document.registerElement('x-foo', {
prototype: Object.create(HTMLElement.prototype, {
createdCallback: {
value: function() { ... }
},
...
})
})
如下形式去调用
<div> <x-foo></x-foo> </div>
2.2 怎样加快页面的显示
1. 使用异步的方式来加载页面,先让一部分的内容先展示出来,再根据用户的操作加载更多的内容
2. 将图片替换成为压缩比更高的webp格式图片
3. 打开重复的页面使用304状态码,达到利用浏览器缓存
2.3 页面是怎样从请求发起到展现出来的
1. 用户输入一个网址,浏览器开启一个线程处理请求,对用户输入的URL进行分析处理,如果是使用了HTT协议的话,那么会用HTTP来处理
2. 调用JavaScript引擎的方法,例如,webview调用loadUrl方法,分析并加载这个URL
3. 连同浏览器的cookie,userAgent等信息向网站目的地IP发起GET请求
4. 进入后台web服务器处理请求
5. 进入部署好的后台应用,找到对应的处理逻辑,这期间可能会读取服务器缓存或者读取数据库
6. 服务器处理请求并返回响应报文,浏览器的缓存资源的时间会跟服务器的最后修改记录时间做对比,一致返回304,否则返回200
7. 如果为200的时候,下载对应的HTML文档,304直接读取缓存
2.4 浏览器的组成结构
示意图如下:
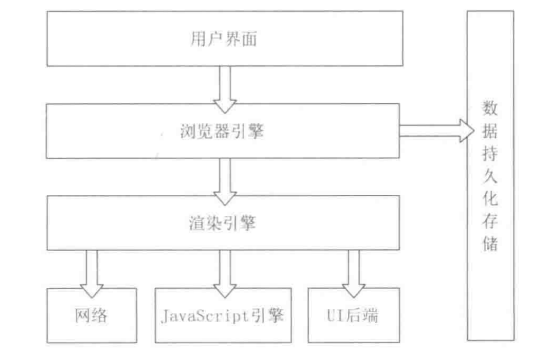
1. 如图我们可以知道浏览器引擎和JavaScript引擎不是同一回事,这个也就说明了为什么JavaScript是单线程但是浏览器可以异步发起请求的问题。
2. 我们重点关注的是渲染引擎和一些存储,因为其他部分开发者无法操作
2.5 各个浏览器渲染引擎之间的差异与渲染引擎是怎样工作的
以webkit内核和Gecko内核为例:
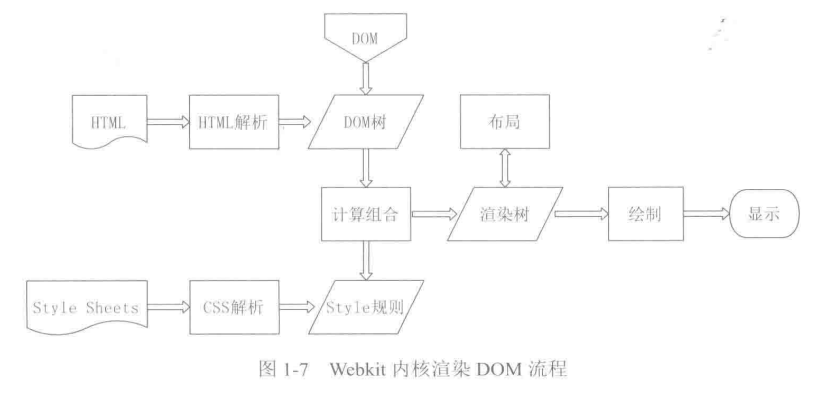
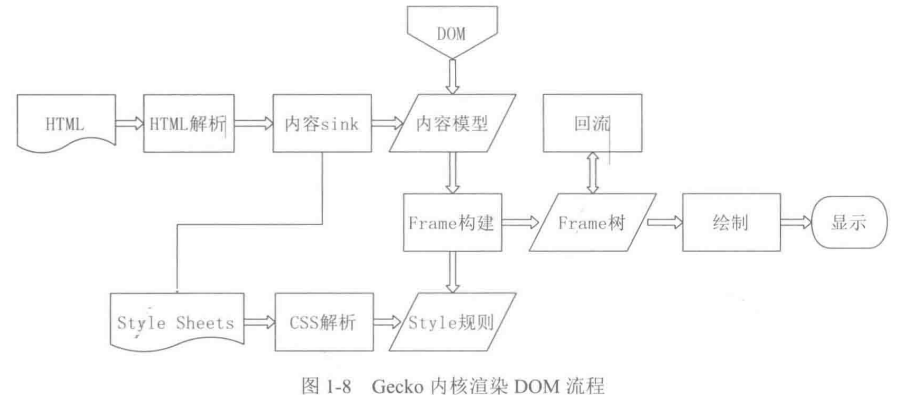
对比之后我们可以发现Gecko内核是需要先解析HTML然后再解析CSS,webkit内核是并行执行的。所以webkit内核在解析CSS这方面会相对高效
2.6 CSS的权重问题
!important(最高权重) > 内联样式规则(权重1000) > id选择器(权重100) > 类选择器(权重10) > 元素选择器
2.7 cookie的种类与区别
cookie一般是有两种:session cookie和持久型 cookie
1. session cookie一般未设置过期时间,只要关闭浏览器窗口,cookie就会消失
2. 持久型cookie一般会设置cookie过期时间,关闭后再次打开浏览器窗口都有效
2.8 前端开发工具
1. 前端高效开发工具:vscode、webstorm、sublime
2. 前端调试工具: chrome devtool
3. 网络辅助工具:fiddler charles wireshark
4. 前端远程调试工具:vorlon.js weinre VConsole
2.9 web安全知识有哪些?大致介绍一下?
主要的web安全有XSS,SQL注入,CSRF
XSS:通常是由页面可解析的内容未经过处理就直接插入到页面导致。例如插入document.cookie来获取cookie
SQL注入:输入框的内容未经过处理就直接传给数据库,导致SQL插入到数据库中
CSRF:举一个例子,假设有一个假冒网站,用户向其中提交用户名和密码,这个时候假冒网站就会向真实的网站发起请求,跳转到真实的网站,但是这个时候假冒网站已经就记录下了用户的用户名和密码。
2.10 网络劫持
前端主要的网络劫持有DNS劫持和HTTP劫持
1. DNS劫持:DNS被篡改解析的路径导致网站解析出错,目前这种劫持较少,这要发生这种劫持是运营商所为
2. HTTP劫持:一般来说这种劫持的HTML,CSS ,JS都是正常的。但是在网站response的时候,网络运营商会劫持添加一些脚本,主要表现在使用HTTP请求有时候会莫名其妙的出现一些小广告之类的。解决的方法是HTTP换成HTTPS
2.11 native交互协议
web调用native
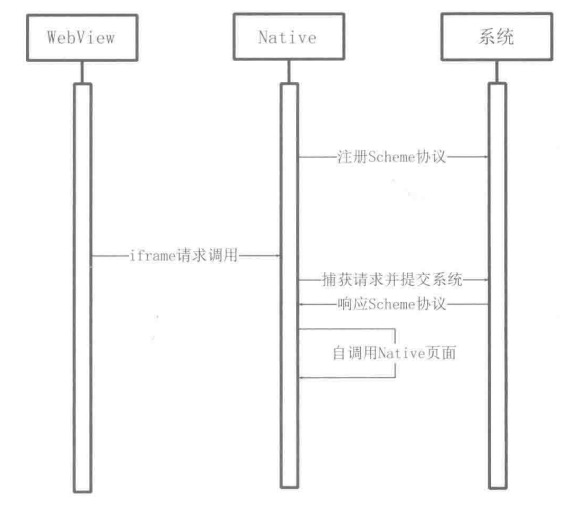
主要web调用native的流程是通过uri和addJavascriptInterface接口来实现的
主要的途径是uri,是通过url向native发起请求,native调用系统的底层来实现的
native协议调用web
原理是:HTML5编写的Javascript暴露到全局中,然后在native中调用loadUrl方法来实现调用javascript
2.12 怎样提交元素的加载解析?
1. 直接通过懒加载来实现
2. 通过使用AMP来实现HTML元素的懒加载(对于video,table等耗时的元素这样做会加快页面的加载速度,但是目前这些方案并不是前端的主流解决方法【博主观点】)
2.13 HTML5中新增了哪些新的标签或者属性?
<header> <video> <source /> <article> <time> <datalist> <command />
<input>新增了 autocomplete,placeholder,autofocus,required属性,新增了email,number,color,range,search,date
三、总体评价
这本书说不上好,也说不上特别的不好,总体上就是用来查漏补缺的,面试可用。书中的内容越往后越稀薄,建议读读前几章就好了。

