

微博深度学习平台架构和实践——阅读心得
微博在Feed CTR、反垃圾、图片分类、明星识别、视频推荐、广告等业务上广泛使用深度学习技术,同时广泛使用TensorFlow、Caffe、Keras、MXNet等深度学习框架。为了融合各个深度学习框架,有效利用CPU和GPU资源,充分利用大数据、分布式存储、分布式计算服务,微博设计开发了微博深度学习平台。
微博深度学习平台支持如下特性:
方便易用:支持数据输入、数据处理、模型训练、模型预测等工作流,可以通过简单配置就能完成复杂机器学习和深度学习任务。特别是针对深度学习,仅需选择框架类型和计算资源规模,就能模型训练。
灵活扩展:支持通用的机器学习算法和模型,以及用户自定义的算法和模型。
多种深度学习框架:目前支持TensorFlow、Caffe等多种主流深度学习框架,并进行了针对性优化。
异构计算:支持GPU和CPU进行模型训练,提高模型训练的效率。
资源管理:支持用户管理、资源共享、作业调度、故障恢复等功能。
模型预测:支持一键部署深度学习模型在线预测服务。
微博深度学习平台架构和实践
微博深度学习平台是微博机器学习平台的重要组成部分,除继承微博机器学习平台的特性和功能以外,支持TensorFlow、Caffe等多种主流深度学习框架,支持GPU等高性能计算集群。微博深度学习平台架构如图1所示。
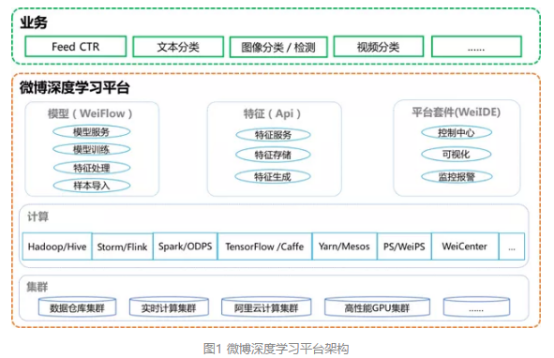
下面将以机器学习工作流、控制中心、深度学习模型训练集群、模型在线预测服务等典型模块为例,介绍微博深度学习平台的实践。
机器学习工作流WeiFlow
微博深度学习和机器学习工作流中,原始数据收集、数据处理、特征工程、样本生成、模型评估等流程占据了大量的时间和精力。为了能够高效地端到端进行深度学习和机器学习的开发,我们引入了微博机器学习工作流框架WeiFlow。
WeiFlow的设计初衷就是将微博机器学习流的开发简单化、傻瓜化,让业务开发人员从纷繁复杂的数据处理、特征工程、模型工程中解脱出来,将宝贵的时间和精力投入到业务场景的开发和优化当中,彻底解放业务人员的生产力,大幅提升开发效率。
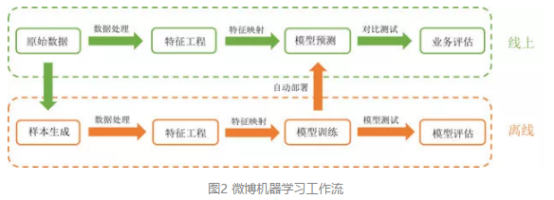
WeiFlow的诞生源自于微博机器学习的业务需求。在微博的机器学习工作流中(如图2所示),多种数据流经过实时数据处理,存储至特征工程并生成离线的原始样本。在离线系统,对原始样本进行各式各样的数据处理、特征处理、特征映射,从而生成训练样本;业务人员根据实际业务场景(排序、推荐),选择不同的算法模型,进行模型训练、预测、测试和评估;待模型迭代满足要求后,通过自动部署将模型文件和映射规则部署到线上。线上系统根据模型文件和映射规则,从特征工程中拉取相关特征,根据映射规则进行预处理,生成可用于预测的样本格式,进行线上实时预测,最终将预测结果(用户对微博内容的兴趣程度)输出,供线上服务调用。
为了应对微博多样的计算环境,WeiFlow采用了双层的DAG任务流设计,如图3所示。外层的DAG由不同的Node构成,每一个Node是一个内层的DAG,具备独立的执行环境,即上文提及的Spark、TensorFlow、Hive、Storm、Flink等计算引擎。

外层DAG设计的初衷是利用各个计算引擎的特长,同时解决各个计算引擎间的依赖关系和数据传输问题。内层的DAG,利用引擎的特性与优化机制,实现不同的抽象作为DAG中计算模块之间数据交互的载体。
在使用方面,业务人员根据事先约定好的规范和格式,将双层DAG的计算逻辑定义在XML配置文件中。依据用户在XML指定的依赖关系和处理模块,WeiFlow自动生成DAG任务流图,并在运行时阶段调用处理模块的实现来完成用户指定的任务流。通过在XML配置文件中将所需计算模块按照依赖关系堆叠,即可以搭积木的方式完成配置化、模块化的流水线作业开发。
控制中心WeiCenter
控制中心WeiCenter的目标就是简单、方便、易用,让大家便利地使用微博深度学习平台。下面将介绍控制中心的作业管理、数据管理和调度管理等部分。
- 作业管理:我们在进行深度学习、大规模机器学习、实时处理的过程中,由于需要各种不同框架的配合使用共同完成一个任务,比如TensorFlow适合进行高性能学习、Spark适合大规模亿维特征训练、Storm或者Flink适合实时特征生成以及实时模型生成等,将这些结合到一起才能完成从离线训练到线上实时预测。以前这需要开发者去学习各种框架复杂的底层开发,现在通过控制中心选择不同的作业类型,可以方便地生成各种类型的作业任务。用户只需要在可视化UI上进行作业类型选择、数据源选择、输出目的地选择或者使用WeiFlow进行编程,就能生成一个高大上的深度学习或机器学习作业。
- 数据管理:当大数据的数据量,每天按P级增长,使用人员每天上百人时,数据管理就显得尤为重要。如果模型训练的集群和数据所在的集群,不是同一个集群,如何高效地将数据同步到模型训练的集群是一个难点。并且在完成模型训练后,能自动根据训练结果作出评估,对训练数据进行删除。由于使用集群的开发人员素质不齐,你会发现总是有很多冗余数据没删除,而且总有无用数据生成,这个时候需要一个统一的数据管理平台,去约束大家生成数据的同时删除数据,去各个平台上探测长时间无访问的数据并进行确认清理。
- 调度管理:作业有多种分类,按重要程度分:高、中、低;按占用资源量分:占用多、占用一般、占用少;按调度器分:Yarn、Mesos、Kubernetes等。Spark、Hadoop利用Yarn调度解决了优先级高的作业和资源占用多作业之间的矛盾;TensorFlow利用成熟的Kubernetes或Mesos调度TensorFlow节点进行GPU集群化任务管理;普通离线作业和服务部署利用Mesos进行资源调度。控制中心集成了多种调度器,利用各种成熟的解决方案,简化了作业负责调度这一难题。
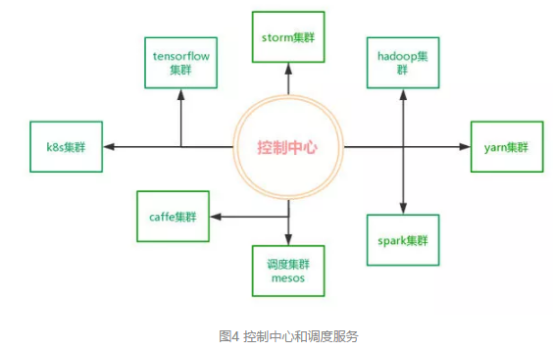
总之,控制中心负责用户权限控制、作业图依赖管理、数据依赖管理等,调度服务负责具体的作业执行、资源抽象、资源管理。控制中心和调度服务如图4所示。
深度学习模型训练集群
微博深度学习训练集群与传统HPC集群有重大区别,分别体现在计算服务器选型、分布式训练、网络设备、存储系统、作业调度系统。
单机多GPU卡:深度学习模型训练大部分情况下单机运算,且几乎完全依靠GPU,因此选用能挂载2/4/8块GPU的服务器,尽量提高单机运算能力。
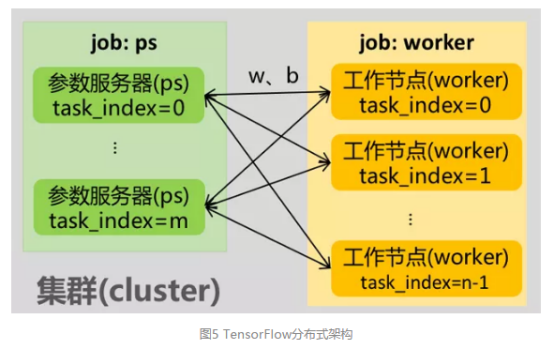
分布式训练:如果训练时间长或者样本规模大,超过单台服务器能力时,需要支持分布式训练。以TensorFlow分布式运行方式为例进行说明,如图5所示。一个TensorFlow分布式程序对应一个抽象的集群,集群(cluster)由工作节点(worker)和参数服务器(parameter server)组成。工作节点(worker)承担矩阵乘、向量加等具体计算任务,计算出相应参数(weight和bias),并把参数汇总到参数服务器;参数服务器(parameter server)把从众多工作节点收集参数汇总并计算,并传递给相应工作节点,由工作节点进行下一轮计算,如此循环往复。
万兆以太网络:参数更新过程中,通信粒度大,而且允许异步通信,对延时没有严格要求。因此,训练集群没有选用HPC集群必备的InfiniBand或Omini-Path低延时网络设备,而是选用普通的以太网设备。
HDFS分布式文件系统:TensorFlow分布式工作节点读取训练样本文件时,不同工作节点读取的数据段不交叉,训练过程中也不会交换样本数据。写出模型文件也只有某一个工作节点负责,不涉及工作节点间的数据交换。因此,深度学习训练作业不要求HPC机群中常见的并行文件系统,只要是一个能被所有工作节点同时访问文件系统就可以。实际上,微博深度学习平台采用HDFS,不但满足要求,而且方便与其它业务共享数据。
定制的作业调度系统:TensorFlow分布式参数服务器进程不会自动结束,需要手动杀死,而HPC应用中的MPI进程同时开始同时结束。设计作业调度方案时必须考虑这个特点,使之能够在所有工作节点都运行结束后自动杀死参数服务器进程。
模型在线预测服务WeiServing
模型在线预测服务是深度学习平台的一个重要功能。由于微博业务场景需求,模型在线预测服务并发量大,对延时、可用性要求极高。考虑到这些业务需求以及服务本身以后的高扩展性,微博分布式模型在线预测服务WeiServing的架构如图6所示。
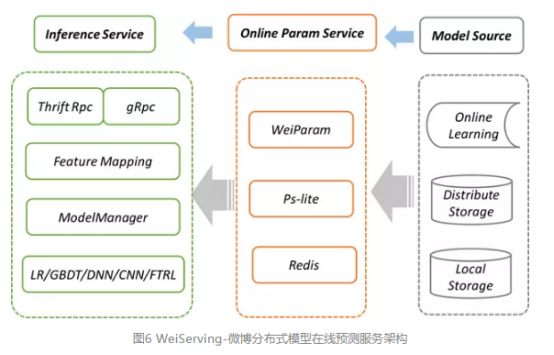
特征处理多样化:模型在线预测服务首先要解决的问题是,将在线的原始特征数据,映射成模型可以处理的数据格式。基于大量的业务模型实践与调优,微博机器学习工作流框架WeiFlow抽象出了一套特征处理函数,来提升开发效率和业务效果。WeiServing与WeiFlow在特征处理方面一脉相承,支持一系列特征处理函数,包括piecewise、pickcat、descartes、combinehash等映射函数,对特征进行归一化、离散化、ID化、组合等特征处理。
多模型多版本支持:由于微博业务场景多种多样,不同的业务场景对模型与特征有不同的需求,WeiServing支持同一个集群为多个业务提供服务,通过docker+k8s进行资源隔离与负载均衡。在相同特征情况下,可以选择不同的模型算法进行处理。另外,对于同一个模型,WeiServing支持在线升级与多版本同时在线,为业务灰度测试提供可能。所有的差异化都被映射到配置文件中,通过简单的配置来完成线上模型的转换。
分布式服务支持:为了应对大规模模型服务与在线机器学习,WeiServing参考通用的参数服务器解决方案,实现了WeiParam分布式服务架构,除了支持传统的PS功能之外,WeiParam针对在线服务需求,通过分布式调度系统,提供多副本、高可用、高性能的系统机制。
多源支持:对于普通离线学习,模型会导出到文件中,WeiServing通过ModelManager模块管理模型加载,支持本地存储与分布式存储。同时,WeiServing为支持在线机器学习,提供对实时流接口对接,在线训练的模型参数可以实时推送到WeiParam中,为线上提供服务。

