一:基本思想
快速排序是冒泡排序的改进版,也是最好的一种内排序,在很多面试题中都会出现,也是作为程序员必须掌握的一种排序方法。
1.在待排序的元素任取一个元素作为基准(通常选第一个元素,但最的选择方法是从待排序元素中随机选取一个作为基准),称为基准元素;
2.将待排序的元素进行分区,比基准元素大的元素放在它的右边,比其小的放在它的左边;
3.对左右两个分区重复以上步骤直到所有元素都是有序的。
二:图解实现过程
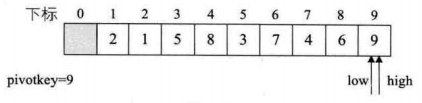
1:选取第一个点50作为枢轴位置,pivotkey是枢轴变量,设置两个标志为low,high表示是否遍历结束

2.比较low和high两个数据,较低的放在前面,进行交换
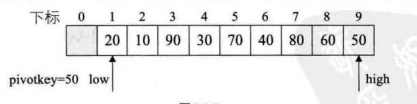
3.只要low<=high,我们就要继续循环,以枢轴为基准,现在调整low,使之++,直到low值大于枢轴值,再进行交换
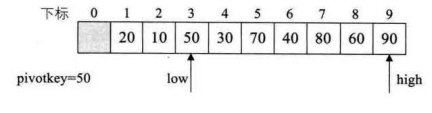
4.现在枢轴到low处,我们开始调整high进行比较,直到high的值小于枢轴值,进行交换

5.继续调整,选择枢轴值到了high,我们需要去调整low++,比较大小
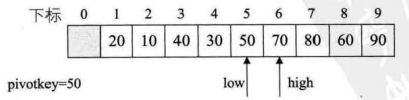
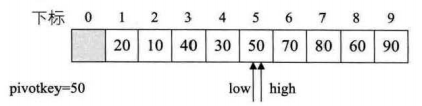
三:代码实现
#include <stdio.h>
#include <stdlib.h>
void swap(int k[], int low, int high)
{
int temp = k[low];
k[low] = k[high];
k[high] = temp;
}
//交换顺序表中子表记录,是枢轴记录到位,并返回其所在位置
//此时在他之前(后)的记录均不大(小)于它
int Partition(int k[], int low, int high)
{
int pivotkey;
pivotkey = k[low]; //用子表第一个记录左枢轴记录
while (low<high) //从表的两端交替向中间扫描
{
while (low<high&&k[high] >= pivotkey)
high--;
swap(k, high, low); //将比枢轴记录小的记录交换到低端
while (low < high&&k[low] <= pivotkey)
low++;
swap(k, low, high); //将比枢轴记录大的记录交换到高端
}
return low; //返回枢轴所在位置
}
void Qsort(int k[], int low, int high)
{
int pivot;
if (low<high)
{
pivot = Partition(k, low, high);
Qsort(k, low, pivot-1); //对低子表进行递归排序
Qsort(k, pivot + 1, high); //对高子表进行递归排序
}
}
int main()
{
int i;
int a[10] = { 5, 2, 6, 0, 3, 9, 1, 7, 4, 8 };
Qsort(a, 0, 9);
for (i = 0; i < 10; i++)
printf("%d ", a[i]);
system("pause");
return 0;
}
四:快速排序优化
(一)优化选取枢轴
如果我们选取的枢轴值正好是处于整个序列大小的中间位置,那么可以将序列分为小数集合和大数集合。但是若是我们第一个选取的是最大值呢?我们交换后实质变化并不大
改进方法
三数取中法:取三个关键字先解析排序,将中间数作为枢轴,一般取左端,右端和中间三个数
int Partition(int k[], int low, int high)
{
int pivotkey;
int m = low + (high - low) / 2;
//三数取中的判断
if (k[low] > k[high])
swap(k, low, high);
if (k[m] > k[high])
swap(k, m, high);
if (k[m] < k[low])
swap(k, m, low);
//此时low处是三个数中间值
pivotkey = k[low]; //用子表第一个记录左枢轴记录
while (low<high) //从表的两端交替向中间扫描
{
while (low<high&&k[high] >= pivotkey)
high--;
swap(k, high, low); //将比枢轴记录小的记录交换到低端
while (low < high&&k[low] <= pivotkey)
low++;
swap(k, low, high); //将比枢轴记录大的记录交换到高端
}
return low; //返回枢轴所在位置
}
(二)优化不必要的交换
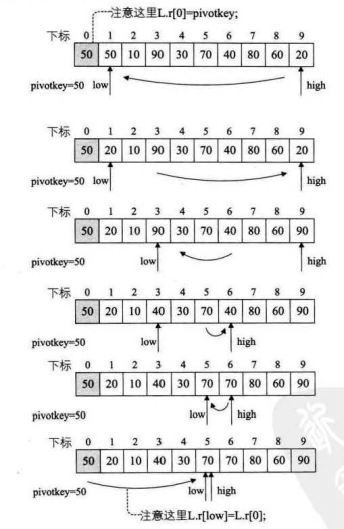
我们从图片发现,50这个关键字,其位置变化时1-9-3-6-5其最终目的还是在中间位置,所以我们在程序中的交换是不必要的,只需要进行覆盖即可
int Partition(int k[], int low, int high)
{
int pivotkey;
int m = low + (high - low) / 2;
//三数取中的判断
if (k[low] > k[high])
swap(k, low, high);
if (k[m] > k[high])
swap(k, m, high);
if (k[m] < k[low])
swap(k, m, low);
//此时low处是三个数中间值
pivotkey = k[low]; //用子表第一个记录左枢轴记录
while (low<high) //从表的两端交替向中间扫描
{
while (low<high&&k[high] >= pivotkey)
high--;
k[low] = k[high]; //直接进行覆盖即可
while (low < high&&k[low] <= pivotkey)
low++;
k[high] = k[low];
}
k[low] = pivotkey; //在最后将枢轴值直接放入
return low; //返回枢轴所在位置
}
(三)优化小数组
当数组非常小时,使用快排还不如直接插入的性能好,二这个数组大小的阈值我们一般选取7最好
#define MAX_LENGTH_INSERT_SORT 7 //数组阈值大小
void InsertSort(int k[], int n) //对数组部分进行快排
{
int i, j, temp;
for (i = 1; i < n;i++)
{
if (k[i]<k[i-1])
{
temp = k[i];
for (j = i - 1; k[j] > temp; j--)
k[j + 1] = k[j];
k[j + 1] = temp;
}
}
}
void Qsort(int k[], int low, int high)
{
int pivot;
if ((high-low)>MAX_LENGTH_INSERT_SORT) //条件是包含high>low
{
pivot = Partition(k, low, high);
Qsort(k, low, pivot - 1); //对低子表进行递归排序
Qsort(k, pivot + 1, high); //对高子表进行递归排序
}
else
{
InsertSort(k + low, high - low + 1); //对数组部分进行快排
}
}
(四)优化递归操作(尾递归)
尾递归
顾名思义,尾递归就是从最后开始计算, 每递归一次就算出相应的结果, 也就是说, 函数调用出现在调用者函数的尾部, 因为是尾部, 所以根本没有必要去保存任何局部变量.
直接让被调用的函数返回时越过调用者, 返回到调用者的调用者去。
尾递归就是把当前的运算结果(或路径)放在参数里传给下层函数,深层函数所面对的不是越来越简单的问题,而是越来越复杂的问题,因为参数里带有前面若干步的运算路径。
尾递归是极其重要的,不用尾递归,函数的堆栈耗用难以估量,需要保存很多中间函数的堆栈。比如f(n, sum) = f(n-1) + value(n) + sum; 会保存n个函数调用堆栈,而使用尾递归f(n, sum) = f(n-1, sum+value(n)); 这样则只保留后一个函数堆栈即可,之前的可优化删去。
普通递归
int FibonacciRecursive(int n)
{
if( n < 2)
return n;
return (FibonacciRecursive(n-1)+FibonacciRecursive(n-));
}
尾递归
int FibonacciTailRecursive(int n,int ret1,int ret2)
{
if(n==0)
return ret1;
return FibonacciTailRecursive(n-1,ret2,ret1+ret2);
}
代码实现
void Qsort(int k[], int low, int high)
{
int pivot;
if ((high-low)>MAX_LENGTH_INSERT_SORT) //条件是包含high>low
{
while (low<high)
{
pivot = Partition(k, low, high);
Qsort(k, low, pivot - 1); //对低子表进行递归排序
low = pivot + 1; //我们将是一个递归的改变的k值直接插入到下一个QSort中
}
}
else
{
InsertSort(k + low, high - low + 1); //对数组部分进行快排
}
}
五:性能分析


 浙公网安备 33010602011771号
浙公网安备 33010602011771号