数据结构(六)查找---散列表(哈希表)查找
一:概述
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
存储位置=f(关键字)
散列技术是在记录的存储位置和他的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。
查找时,根据这个确定的对应关系找到固定值key的映射f(key),若查找集合中存在这个记录,则必定在f(key)的位置上。
我们把这种对应关系f称为散列函数,又称为哈希函数(Hash)。采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或者哈希表
二:散列表查找步骤
(1)在存储时,通过散列函数计算记录的散列地址,并按此散列地址存储该记录;
(2)在查找时,通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录。
所以说,散列技术既是一种存储方法,也是一种查找方法。
散列技术最适合的求解问题就是查找与给定关健值对应的记录(一对一)。不过散列表不适合范围查找,比如查找一个班级18-22岁的同学,在散列表中没法进行。想获得表中记录的排序也不可能,像最大值、最小值等结果也都无法从散列表中计算出来。
三:散列函数的构造方法
要求:
1.计算简单
若是设计了一个算法可以保证所有关键字都不会发生冲突,但是这个算法需要大量的复杂计算,耗费很多时间,这对于频繁的查找来说,会大大的降低查找效率。
至少散列函数的计算时间不应该超过其他查找技术与关键字比较的时间;
2.散列地址分布均匀
这样可以保证存储空间的有效利用,并减少为处理冲突而耗费的时间。分布越不均匀,越易产生数据重叠等问题
(一)直接定址法(使用某个线性函数值作为散列地址<f(key)=a*key+b>)
f(key)=key 例如年龄和人口数
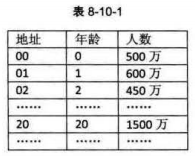
f(key)=a*key+b (a,b为常数) 例如出生年份和人口

简单,均匀,但是需要事先知道关键字分布,适合查找表较小且连续的情况。不适合分布不均数据
(二)数字分析法(取关键字)
假设某公司的员工登记表以员工的手机号作为关键字。
手机号一共11位。前3位是接入号,对应不同运营商的子品牌;中间4位表示归属地;最后4位是用户号。
不同手机号前7位相同的可能性很大,所以可以选择后4位作为散列地址,或者对后4位反转(1234 -> 4321)、循环右移(1234 -> 4123)、循环左移等等之后作为散列地址。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布比较均匀,就可以考虑这个方法。
(三)平方取中法
假设关键字是1234、平方之后是1522756、再抽取中间3位227,用作散列地址。
平方取中法比较适合于不知道关键字的分布,而位数又不是很大的情况。
(四)折叠法
将关键字从左到右分割成位数相等的几部分,最后一部分位数不够时可以短些,然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。 比如关键字是9876543210,散列表表长是3位,将其分为四组,然后叠加求和:987 + 654 + 321 + 0 = 1962,取后3位962作为散列地址。
折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。
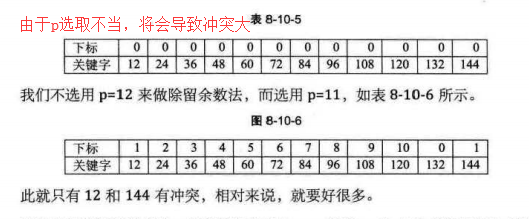
(五)除留余数法

m为散列表长。这种方法不仅可以对关键字直接取模,也可在折叠、平方取中后再取模。根据经验,若散列表表长为m,通常p为小于或等于表长(最好接近m)的最小质数,可以更好的减小冲突。
此方法为最常用的构造散列函数方法。

(六)随机数法
f(key) = random(key),这里random是随机函数。当关键字的长度不等时(种子不同,生成数唯一),采用这个方法构造散列函数是比较合适的。
总结:
实际应用中,应该视不同的情况采用不同的散列函数。
如果关键字是英文字符、中文字符、各种各样的符号,都可以转换为某种数字来处理,比如其unicode编码。
下面这些因素可以作为选取散列函数的参考:
(1)计算散列地址所需的时间;
(2)关键字长度;
(3)散列表大小;
(4)关键字的分布情况;
(5)查找记录的频率。
四:处理散列冲突的方法
冲突:
两个关键字key1和key2不同,但是通过我们的散列函数,得出的散列值相同,这种现象我们称为冲突,并且把key1和key2称为这个散列函数的同义词
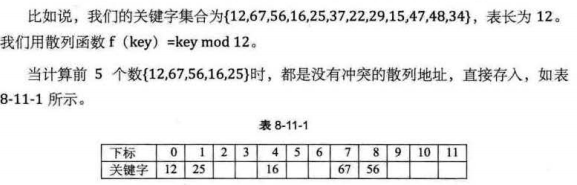
(一)开放定址法(线性探测法)
一旦发生了冲突,就去寻找下一个空的散列地址,只要只要散列表足够大,空的散列地址总能找到,并将记录存入。



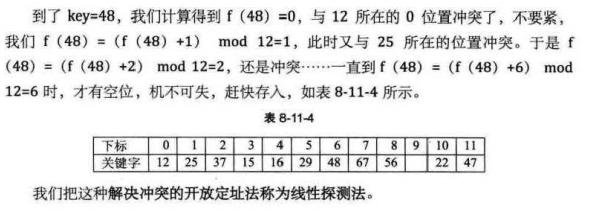
堆积:
例如上面的48和37这种本来都不是同义词f(key)不同,却要争夺一个地址的情况,我们称这种现象为堆积。显然,堆积的出现,使得我们的冲突增加,而且查找和插入的效率降低
二次探测法(双向):
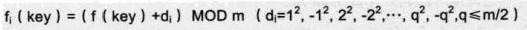
增加平方运算的目的是为了不让关键字都聚集在某一块区域,使用正负更可以双向进行探测。我们称之为二次探测法。
随机探测法:

在冲突时,对于位移量di采用随机函数计算得到,我们称之为随机探测法
总之:开放定址法只要在散列表未填满时,总是能够找到不发生冲突的地址,是我们常用的解决冲突的方法
(二)再散列函数法
我们事先准备多个散列函数,当第一个失效,我们就选择下一个去测试

这里RHi就是不同的散列函数。我们可以把我们之前的讲的所有方法全部用上。每当发生散列地址冲突,我们就换一个散列函数来计算。
可以使得关键字不聚集,但是增加了计算的时间
(三)链地址法
产生冲突不换地方,将所有的关键字为同义词的记录存储在一个单链表中,我们称之为同义词子表,在散列表中只存储所有同义词子表的头指针。无论有多少个冲突,都只是在给单链表增加结点
{12,67,56,16,25,37,22,29,15,4748,34}
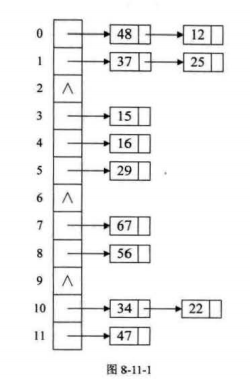
不会产生地址冲突,但是查找时需要遍历单链表会带来性能损耗
(四)公共溢出区法
将产生冲突的数据带走,为所有冲突的关键字建立一个公共的溢出区来存放
{12,67,56,16,25,37,22,29,15,4748,34}
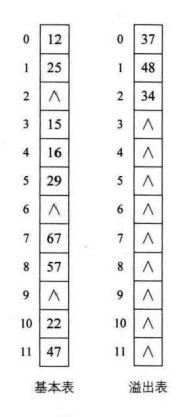
在冲突的数据很少的情况下,其性能还不错
五:散列表查找实现

#define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <stdlib.h> #define SUCCESS 1 #define UNSUCCESS 0 #define OK 1 #define ERROR 0 #define TRUE 1 #define FALSE 0 #define HASHSIZE 12 //定义初始散列表长为数组的长度 #define NULLKEY -32768 typedef int Status; typedef struct { int *elem; //数据元素存储基址 int count; //当前数据元素个数 }HashTable; int m=0; //全局存放散列表长 //初始散列表 Status InitHashTable(HashTable* H) { int i; m = HASHSIZE; H->count = m; H->elem = (int *)malloc(sizeof(int)*m); for (i = 0; i < m; i++) H->elem[i] = NULLKEY; return OK; } //设置散列函数,使用除留余数法 int Hash(int key) { return key % m; } //插入关键字进入散列表 void InsertHash(HashTable* H, int key) { int addr = Hash(key); //求散列地址 while (H->elem[addr]!=NULLKEY) //使用开放定址法解决冲突 addr = (addr + 1) % m; H->elem[addr] = key; } //散列表查找数据 Status SearchHash(HashTable H, int key, int *addr) { *addr = Hash(key); while (H.elem[*addr]!=key) { *addr = (*addr + 1) % m; if (H.elem[*addr] == NULLKEY || *addr == Hash(key)) return UNSUCCESS; //若是循环回到源点或者找不到数据,查找失败 } return SUCCESS; } int main() { HashTable H; int i,addr; int a[12] = { 12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34 }; char ch; InitHashTable(&H); for (i = 0; i < 12;i++) InsertHash(&H,a[i]); while (1) { printf("input cmd to operate:(S:Search Q:Quit)\n"); scanf("%c", &ch); if (ch == 'Q') break; printf("input number to search:\n"); scanf("%d", &i); if (SearchHash(H, i, &addr)) printf("find number in %d\n", addr); else printf("not find number\n"); getchar(); } system("pause"); return 0; }
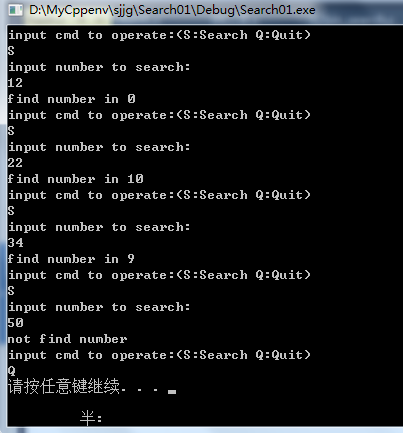
六:散列表查找性能分析



 浙公网安备 33010602011771号
浙公网安备 33010602011771号