数据结构(六)查找---有序表查找(三种查找方式:折半,插值,斐波拉契查找)
前提
有序表查找要求我们的数据是有序的,是排序好的,我们只需要进行查找即可
我们下面将介绍折半查找(二分查找),插值查找,斐波那契查找
一:折半查找
(一)定义
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
(二)查找过程
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;
否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。
重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
(三)代码实现
int Binary_Search(int *a, int n, int key) { int low, high, mid; low = 0; high = n - 1; while (low<=high) { mid = (low + high) / 2; if (a[mid] < key) low = mid + 1; else if (a[mid]>key) high = mid - 1; else return mid; } return -1; } int main() { int a[10] = { 1, 6, 12, 21, 30, 31, 32, 42, 49, 52 }; int index; index=Binary_Search(a, 10, 49); if (index != -1) printf("find key in %d\n", index); else printf("not find key\n"); system("pause"); return 0; }

(四)性能分析
其时间复杂度是O(logn),不过由于折半查找的前提是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,这样的算法是比较好的。但是对于需要频繁插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,不建议使用。
二:插值查找(按比例查找法)
(一)算法分析:
对于前面的折半查找,为啥一定要折一般,而不是1/4或者其他? 比如:我们查字典Apple,我们会先从中间查找,还是有一定目的的向前找。
或者在0-1000个数之间有200个元素从小到大均匀分布排序,我们若是需要查找到15,我们会去中间查找500,还是直接去前面开始查找。 以上都说明我们上面的折半查找可以再进行改进
首先我们对折半公式进行改写:
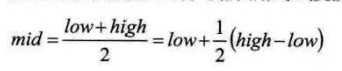
折半查找这种查找方式,不是自适应的(也就是说是傻瓜式的),其前面的查找系数(比例参数)始终是1/2
通过类比,我们可以将查找的点改进为如下:
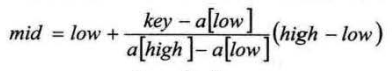
也就是将上述的比例参数1/2改进为自适应的,根据关键字在整个有序表中所处的位置,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
(二)基本思想:
基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,插值查找也属于有序查找。
(三)代码实现:
int Insert_Search(int *a, int n, int key) { int low, high, mid; low = 0; high = n - 1; while (low <= high) { mid = low + (key - a[low]) / (a[high] - a[low])*(high - low); if (a[mid] < key) low = mid + 1; else if (a[mid]>key) high = mid - 1; else return mid; } return -1; }
实现方法和折半一样,只是修改了mid
(四)性能分析:
而插值查找则比较灵活,并不是简单的从中间进行的,它是根据我们需要查询的值的渐进进行搜索的.
插值查找的不同点在于每一次并不是从中间切分,而是根据离所求值的距离进行搜索的.
对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
时间复杂度:平均情况O(loglog(n)),最坏O(log(n))
三:斐波那契查找(仅使用加法减法实现二分查找)
除了插值查找之外,我们再介绍一种有序查找,可以对折半进行优化,那就是斐波那契查找,利用了黄金分割原理来实现的
斐波那契查找与折半查找很相似,他是根据斐波那契序列的特点对有序表进行分割的。他要求开始表中记录的个数为某个斐波那契数小1,即n=F(k)-1;
(一)斐波那契数列
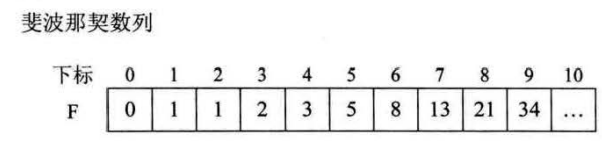
越向后,每两个数之间相除越接近黄金比例
(二)斐波拉契查找实现
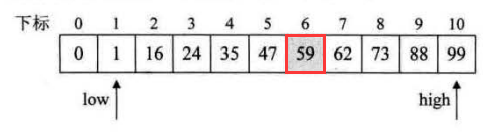
1.首先我们要创建一个斐波拉契数列
2.获取我们的数组大小n(我们不考虑0下标,因为我们的斐波那契数列从0开始,无法构成黄金比例),在斐波拉契数列中的位置
例如上面的查找数组大小为n=10,F[6]<n<F[7],所以得出其位置为k=7
3.因为我们的k=7,F[7]=13,而a数组最大为10,我们需要对其按照F[7]=13补齐数组,使其长度为F[7]-1=12,将a[11]=a[10],a[12]=a[10]

4.开始正式查找,按照上图mid=low+F[k-1]-1;


(三)思考:n=F(k)-1, 表中记录的个数为某个斐波那契数小1。这是为什么呢?
是为了格式上的统一,以方便递归或者循环程序的编写。
表中的数据是F(k)-1个,使用mid值进行分割又用掉一个,那么剩下F(k)-2个。
正好分给两个子序列,每个子序列的个数分别是F(k-1)-1与F(k-2)-1个,格式上与之前是统一的。
不然的话,每个子序列的元素个数有可能是F(k-1),F(k-1)-1,F(k-2),F(k-2)-1个,写程序会非常麻烦。
(四)算法实现


void Fibonacci(int **Fb, int n) { int f1, f2,ft; int count=3; f1 = 1; f2 = 1; while (f2<n) { ft = f1 + f2; f1 = f2; f2 = ft; count++; } (*Fb) = (int *)malloc(count*sizeof(int)); (*Fb)[0] = 0; (*Fb)[1] = 1; for (f1 = 2; f1 <= count - 1; f1++) (*Fb)[f1] = (*Fb)[f1 - 1] + (*Fb)[f1 - 2]; }
int Fibonacci_Search(int *a, int n, int key) { int low, high, mid, i, j,k; int *Fb,*temp; //根据实际情况来初始化 low = 1; high = n; Fibonacci(&Fb, n); k = 0; while (n > Fb[k]) //计算n位于斐波那契数列位置 k++; temp = (int *)malloc((Fb[k] - 1 + 1)*sizeof(int));//后面加1是因为还有个下标0空间 memcpy(temp, a, n*sizeof(n + 1)); for (i = n + 1; i <= Fb[k] - 1; i++) //我们要查找的是数组1到F[k]-1,而实际数组长要包括一个下标0空间 temp[i] = a[n]; while (low<=high) { mid = low + Fb[k - 1] - 1; if (key == temp[mid]) { //分情况,是前半段,正常输出,后半段判断是不是在我们补充的数组里面,这时我们返回原数组最后一个下标 if (mid <= n) return mid; else return n; } else if (key>temp[mid]) { low = mid + 1; k = k - 2; } else { high = mid - 1; k = k - 1; } } return 0; //0是未找到,0下标使无意义的 }
int main() { int a[11] = { 0,1,16,24,35,47,59,62,73,88,99}; int index; index = Fibonacci_Search(a, 10, 73); if (index != -1) printf("find key in %d\n", index); else printf("not find key\n"); system("pause"); return 0; }

(五)性能分析
其时间复杂度也是O(logn),就平均性能来说,斐波那契查找由于折半查找。但是若是最坏情况,比如key=1,始终处于左侧长半区查找,则效率低于折半查找。
四:总结


