数据结构(五)图---最短路径(弗洛伊德算法)
一:定义
弗洛伊德算法是用来求所有顶点到所有顶点的时间复杂度。
虽然我们可以直接对每个顶点通过迪杰斯特拉算法求得所有的顶点到所有顶点的时间复杂度,时间复杂度为O(n*3),但是弗洛伊德算法更加简洁优雅
二:弗洛伊德的使用介绍
若是求一个顶点到其他顶点的最短距离,例如迪杰斯特拉算法,我们的距离数组和路径数组使用一维即可,但是我们这里是获取所有顶点到其余顶点的最短距离,所以我们对于数组和路径都需要使用二维数组来表示
下面我们使用一个有三个顶点的图来进行讲解:
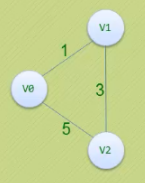
(1)我们先定义两个二维数组D0[3][3]和P0[3][3]
D0表示顶点到顶点的最短路径权值和的矩阵。
P0表示对于顶点的最小路径前驱矩阵
将D0初始化为他的初始的图的邻接矩阵 将P0初始化为图中所示每行从0-n
(2)处理两个数组

上面的公式是以v0作为中转点,实际上我们可以使用所有邻接点作为中转点,所以我们程序使用的是下面的转化公式
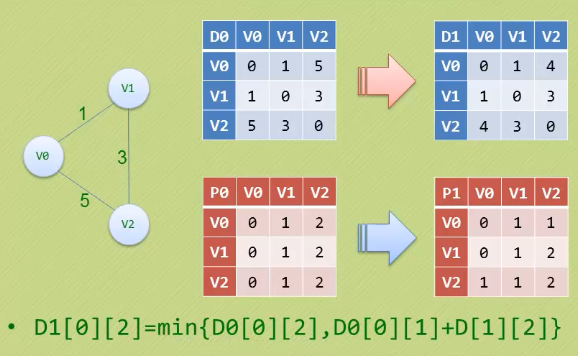
注意(重点):
D1数组是我们获取的最短路径,我们直接使用顶点对应的行即可获得所有的从该顶点出发的到其他顶点的最短路径权重和
P1数组是我们获取的前驱结点,我们使用的不是顶点所对应的行,而是其对应的列,这个才是我们需要的路径
上面只是使用了一个简单的图来讲解,对于复杂的图我们依旧可以使用它
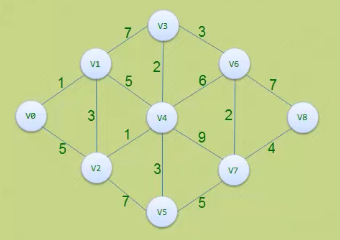
初始化
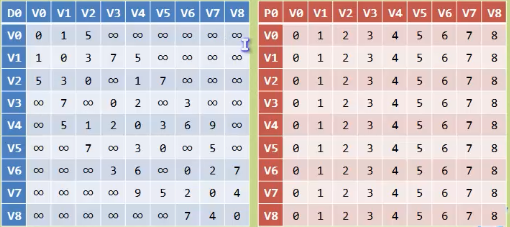
处理后
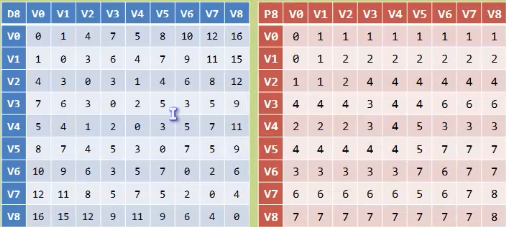
三:弗洛伊德基本思想
弗洛伊德算法定义了两个二维矩阵:
矩阵D记录顶点间的最小路径
例如D[0][3]= 10,说明顶点0 到 3 的最短路径为10;
矩阵P记录顶点间最小路径中的中转点
例如P[0][3]= 1 说明,0 到 3的最短路径轨迹为:0 -> 1 -> 3。
它通过3重循环,k为中转点,v为起点,w为终点,循环比较D0[v][w] 和 D0[v][k] + D0[k][w] 最小值,如果D0[v][k] + D0[k][w] 为更小值,则把D0[v][k] + D0[k][w] 覆盖保存在D1[v][w]中。
核心思想是:
D1[v][w] = min{D0[v][k] + D0[k][w],D0[v][w]}
其中D0代表原来未更新前的数据,D1表示我们修改更新后的新的数据
四:代码实现
(一)结构定义
//邻接矩阵结构 typedef struct { VertexType vers[MAXVEX]; //顶点表 EdgeType arc[MAXVEX][MAXVEX]; //邻接矩阵,可看作边表 int numVertexes, numEdges; //图中当前的顶点数和边数 }MGraph;
(二)弗洛伊德算法
//使用弗洛伊德核心算法,三层循环求解 for (k = 0; k < G.numVertexes;k++) { for (i = 0; i < G.numVertexes;i++) { for (j = 0; j < G.numVertexes;j++) { if ((*dist)[i][j]>((*dist)[i][k]+(*dist)[k][j])&&i!=j) //i!=j使不更新中间自己到自己的数据和路径 { //将权值和更新,路径也变为中转点 (*dist)[i][j] = (*dist)[i][k] + (*dist)[k][j]; (*path)[i][j] = (*path)[i][k]; } } } }
(三)打印最短路径


void ShowDistAndPath(Path P, Dist D,int n) { int i, j; printf("Printf Dist:\n"); for (i = 0; i < n;i++) { for (j = 0; j < n; j++) { if (i==j) printf(" 0"); //需要将我们的无穷转换一下再显示 else printf("%5d", D[i][j]); } printf("\n"); } printf("Printf Path:\n"); for (i = 0; i < n; i++) { for (j = 0; j < n; j++) printf("%5d", P[i][j]); printf("\n"); } }
五:全部代码实现
#define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <stdlib.h> #include <string.h> #include <stdbool.h> #include "queue.h" #define MAXVEX 100 //最大顶点数 #define INFINITY 65535 //用0表示∞ typedef char VertexType; //顶点类型,字符型A,B,C,D... typedef int EdgeType; //边上权值类型10,15,... //邻接矩阵结构 typedef struct { VertexType vers[MAXVEX]; //顶点表 EdgeType arc[MAXVEX][MAXVEX]; //邻接矩阵,可看作边表 int numVertexes, numEdges; //图中当前的顶点数和边数 }MGraph; typedef int Dist[MAXVEX][MAXVEX]; //存放各个顶点到其余顶点的最短路径权值和 typedef int Path[MAXVEX][MAXVEX]; //存放各个顶点到其余顶点前驱顶点位置 //创建邻接矩阵 void CreateMGraph(MGraph* G); //显示邻接矩阵 void showGraph(MGraph G); void Floyd(MGraph G,Path* path,Dist* dist); void ShowDistAndPath(Path P, Dist D,int n); void Floyd(MGraph G, Path* path, Dist* dist) { int i,j,k; //初始化path和dist for (i = 0; i < G.numVertexes;i++) { for (j = 0; j < G.numVertexes;j++) { (*dist)[i][j] = G.arc[i][j]; (*path)[i][j] = j; //初始化为这个的一个好处就是自己到自己的路径就是自己,我们不用修改 } } //使用弗洛伊德核心算法,三层循环求解 for (k = 0; k < G.numVertexes;k++) { for (i = 0; i < G.numVertexes;i++) { for (j = 0; j < G.numVertexes;j++) { if ((*dist)[i][j]>((*dist)[i][k]+(*dist)[k][j])&&i!=j) { //将权值和更新,路径也变为中转点 (*dist)[i][j] = (*dist)[i][k] + (*dist)[k][j]; (*path)[i][j] = (*path)[i][k]; } } } } } void ShowDistAndPath(Path P, Dist D,int n) { int i, j; printf("Printf Dist:\n"); for (i = 0; i < n;i++) { for (j = 0; j < n; j++) { if (i==j) printf(" 0"); //需要将我们的无穷转换一下再显示 else printf("%5d", D[i][j]); } printf("\n"); } printf("Printf Path:\n"); for (i = 0; i < n; i++) { for (j = 0; j < n; j++) printf("%5d", P[i][j]); printf("\n"); } } int main() { MGraph MG; CreateMGraph(&MG); showGraph(MG); Path path; Dist dist; Floyd(MG, &path, &dist); ShowDistAndPath(path, dist, MG.numVertexes); system("pause"); return 0; } //生成邻接矩阵 void CreateMGraph(MGraph* G) { int i, j, k, w; G->numVertexes = 9; G->numEdges = 16; //读入顶点信息 G->vers[0] = 'A'; G->vers[1] = 'B'; G->vers[2] = 'C'; G->vers[3] = 'D'; G->vers[4] = 'E'; G->vers[5] = 'F'; G->vers[6] = 'G'; G->vers[7] = 'H'; G->vers[8] = 'I'; //getchar(); //可以获取回车符 for (i = 0; i < G->numVertexes; i++) for (j = 0; j < G->numVertexes; j++) G->arc[i][j] = INFINITY; //邻接矩阵初始化 //创建了有向邻接矩阵 G->arc[0][1] = 1; G->arc[0][2] = 5; G->arc[1][2] = 3; G->arc[1][3] = 7; G->arc[1][4] = 5; G->arc[2][4] = 1; G->arc[2][5] = 7; G->arc[3][4] = 2; G->arc[3][6] = 3; G->arc[4][5] = 3; G->arc[4][6] = 6; G->arc[4][7] = 9; G->arc[5][7] = 5; G->arc[6][7] = 2; G->arc[6][8] = 7; G->arc[7][8] = 4; for (i = 0; i < G->numVertexes;i++) for (k = i; k < G->numVertexes;k++) G->arc[k][i] = G->arc[i][k]; } //显示邻接矩阵 void showGraph(MGraph G) { for (int i = 0; i < G.numVertexes; i++) { for (int j = 0; j < G.numVertexes; j++) { if (G.arc[i][j] != INFINITY) printf("%5d", G.arc[i][j]); else printf(" 0"); } printf("\n"); } }

六:循环分析
问:可不可以先循环i和j,然后把k放到最内层呢?
答案是不行的,如果打乱了i、j、k的顺序,则程序无法得出正确的结果。
可以把k想象成一个阶段,即k为中转点时,枚举i、j,通过k的变动不停地松弛i、j之间的最短路。因为i、j可以重复遍历,但k不能。如果k在内层循环,程序无法进行多次的松弛操作,也就是程序出错的原因。
我们可以认为,我们每一次的整个数组的变化都是建立在同一个中转k值基础上才能够得到正确的数据,我们每次更新完整个数组后才可以去变化k值,去重新更新一次新的,正确的数组
当我们将k放入内层,数组的每次内部更新变为动态了,我们不确定那些是正确的最短路径,因为某些数据没有得到正确的结果,就被拿到下一次继续使用了
错误实验:
for (i = 0; i < G.numVertexes;i++) { for (j = 0; j < G.numVertexes;j++) { for (k = 0; k < G.numVertexes; k++) { if ((*dist)[i][j]>((*dist)[i][k] + (*dist)[k][j]) && i != j) { //将权值和更新,路径也变为中转点 (*dist)[i][j] = (*dist)[i][k] + (*dist)[k][j]; (*path)[i][j] = (*path)[i][k]; } } } }

七:性能分析
Floyd算法适用于APSP(All Pairs Shortest Paths,多源最短路径),是一种动态规划算法,稠密图效果最佳,边权可正可负。
此算法简单有效,由于三重循环结构紧凑,对于稠密图,效率要高于执行|V|次Dijkstra算法,也要高于执行|V|次SPFA算法。
优点:容易理解,可以算出任意两个节点之间的最短距离,代码编写简单。
缺点:时间复杂度比较高O(n*3),不适合计算大量数据。
补充:
无论是迪杰斯特拉算法还是弗洛伊德算法,对于有向图,无向图都是可以使用的。
另外我们的最短路径一般都是针对有环图,无环图使用拓扑排序可以获得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号