数据结构(三)串---KMP模式匹配算法实现及优化
KMP算法实现


#define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <stdlib.h> #include <string.h> #define OK 1 #define ERROR 0 #define TRUE 1 #define FALSE 0 #define MAXSIZE 40 typedef int ElemType; typedef int Status; //设置串的存储结构 typedef char String[MAXSIZE+1]; //生成串相关 Status StrAssign(String S,char *chars); //生成一个其值等于字符串常量的chars的串T Status StrCopy(String T, String S); //串S存在,由串S复制得到串T Status Concat(String T, String S1, String S2); //用T返回由S1和S2连接而成的新串 //基础操作相关 Status ClearString(String S); //串S存在,将串清空 Status StringEmpty(String S); //若串为空,返回true,否则false int StringLength(String S); //返回串S的元素个数,长度 //比较串,索引串相关 int StrCompare(String S, String T); //若S > T返回 > 0, = 返回0, < 返回 < 0 Status SubString(String Sub, String S,int pos,int len); //串S存在,返回S由pos起,长度为len的子串到Sub int Index(String S, String T,int pos); //主串S,子串T,返回T在S中位置 //增删改相关 Status Replace(String S, String T, String V); //串S,T和V存在,T非空,用V替换主串S中T串 Status StrInsert(String S, int pos, String T); //在主串S中的pos位置插入串T Status StrDelete(String S,int pos,int len); //串S存在,从串S中删除第pos个字符串起长度为len的子串 void PrintStr(String S); //生成串相关 //生成一个其值等于字符串常量的chars的串T Status StrAssign(String S, char *chars) { int i; if (strlen(chars) > MAXSIZE) return ERROR; else { S[0] = strlen(chars); for (i = 1; i <= S[0];i++) S[i] = *(chars+i-1); return OK; } } //串S存在,由串S复制得到串T Status StrCopy(String T, String S) { int i; for (i = 0; i <= S[0];i++) T[i] = S[i]; return OK; } //用T返回由S1和S2连接而成的新串,若是超出,会截断,但是会进行连接,返回FALSE Status Concat(String T, String S1, String S2) { int i,j,interLen; //interLen是截断后S2剩余长度 if (S1[0] + S2[0] > MAXSIZE) interLen = MAXSIZE - S1[0]; else interLen = S2[0]; T[0] = S1[0] + S2[0]; for (i = 1; i <= S1[0]; i++) T[i] = S1[i]; for (j = 1; j <= interLen; j++) T[i+j-1] = S2[j]; if (interLen != S2[0]) return ERROR; return OK; } //基础操作相关 //串S存在,将串清空 Status ClearString(String S) { S[0] = 0; return OK; } //若串为空,返回true,否则false Status StringEmpty(String S) { if (S[0] != 0) return FALSE; return TRUE; } //返回串S的元素个数,长度 int StringLength(String S) { return S[0]; } //比较串,索引串相关 //若S > T返回 > 0, = 返回0, < 返回 < 0 int StrCompare(String S, String T) { int i; for (i = 1; i <= S[0] && i <= T[0]; i++) if (S[i] != T[i]) return S[i] - T[i]; return S[0]-T[0]; //若是相同比较长度即可 } //串S存在,返回S由pos起,长度为len的子串到Sub Status SubString(String Sub, String S, int pos,int len) { int i; if (pos<1 || len<0 || pos + len - 1 > S[0] || pos>S[0]) return ERROR; for (i = 0; i < len;i++) Sub[i + 1] = S[pos + i]; Sub[0] = len; return OK; } //主串S,子串T,返回T在S中位置,pos代表从pos开始匹配 //或者一次截取一段进行比较为0则找到 int Index(String S, String T, int pos) { int i, j; i = pos; j = 1; while (i<=S[0]-T[0]+1&&j<=T[0]) { if (S[i]==T[j]) { j++; i++; } else { i = i - j + 2; //注意这个索引的加2 j = 1; } } if (j > T[0]) return i - T[0]; return 0; } //增删改相关 //串S,T和V存在,T非空,用V替换主串S中T串 Status Replace(String S, String T, String V) { int idx=1; if (StringEmpty(T)) return ERROR; while (idx) { idx = Index(S, T, idx); if (idx) { StrDelete(S, idx, StringLength(T)); StrInsert(S, idx, V); idx += StringLength(V); } } return OK; } //在主串S中的pos位置插入串T,注意:若是串满,则只插入部分 Status StrInsert(String S, int pos, String T) { int i,interLength; if (S[0] + T[0] > MAXSIZE) //长度溢出 interLength = MAXSIZE - S[0]; else interLength = T[0]; for (i = S[0]; i >= pos;i--) S[interLength + i] = S[i]; //将后面的数据后向后移动 //开始插入数据 for (i = 1; i <= interLength; i++) S[pos + i - 1] = T[i]; S[0] += interLength; if (interLength != T[0]) return ERROR; return OK; } //串S存在,从串S中删除第pos个字符串起长度为len的子串 Status StrDelete(String S, int pos,int len) { int i; if (pos < 1 || len<1 || pos + len - 1>S[0]) return ERROR; //将数据前移 for (i = pos+len; i <= S[0];i++) S[i-len] = S[i]; S[0] -= len; return OK; } void PrintStr(String S) { int i; for (i = 1; i <= StringLength(S);i++) { printf("%c", S[i]); } printf("\n"); }
//通过计算返回子串T的next数组 void get_next(String T, int* next) { int m, j; j = 1; //j是后缀的末尾下标 m = 0; //m代表的是前缀结束时的下标 next[1] = 0; while (j < T[0]) { if (m == 0 || T[m] == T[j]) //T[m]表示前缀的最末尾字符,T[j]是后缀的最末尾字符 { ++m; ++j; next[j] = m; } else m = next[m]; //若是字符不相同,则m回溯 } }
int Index_KMP(String S, String T, int pos) { int i = pos; int j = 1; int next[MAXSIZE]; get_next(T, next); while (i<=S[0]&&j<=T[0]) //其实现与BF算法相似,不过不同的是i不进行回溯,而是将j进行了修改 { if (j==0||S[i]==T[j]) { ++i; ++j; //若完全匹配后,j就会比模式串T的长度大一 } else //不匹配时,就使用next数组获取下一次匹配位置 { j = next[j]; } } if (j > T[0]) return i - T[0]; else return 0; }
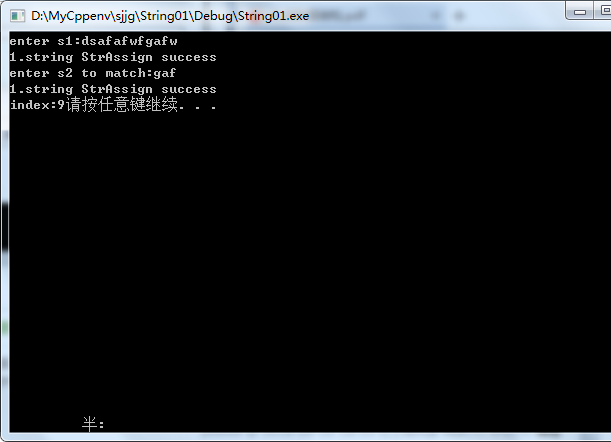
int main() { int i, j; String s1,s2,t; char *str = (char*)malloc(sizeof(char) * 40); memset(str, 0, 40); printf("enter s1:"); scanf("%s", str); if (!StrAssign(s1, str)) printf("1.string length is gt %d\n", MAXSIZE); else printf("1.string StrAssign success\n"); printf("enter s2 to match:"); scanf("%s", str); if (!StrAssign(s2, str)) printf("1.string length is gt %d\n", MAXSIZE); else printf("1.string StrAssign success\n"); i = Index_KMP(s1, s2, 1); printf("index:%d", i); system("pause"); return 0; }
KMP算法优化---对next数组获取进行优化
原来我们获取的next数组是由缺陷的
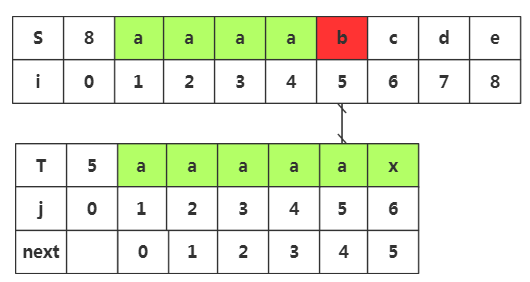
我们可以发现j5与i5失配,所以按照上面的next值,会去匹配j4-j3-j2-j1,但是我们从前面的思路启发知道,当我们知道j1=j2=j3=j4=j5,而j5≠i5,那么我们完全可以知道j1到j4也是不与i5匹配,
所以,我们这里做了太多的重复匹配。这就是我们需要优化的地方
由于T串的第二三四五位的字符都与首位的'a'相等,那么可以用首位next[1]的值去取代与他相等的字符后续的next[j]值
改进方法:
我们将新获取的next值命名为nextval,则新的nextval与他同列的next值有关,我们找的一next[j]为列值的新的j列,将字符进行比较,若是相同,则将该列的next值变为现在的nextval
例如:
推导1:
第一步:当j=1时,nextval=0
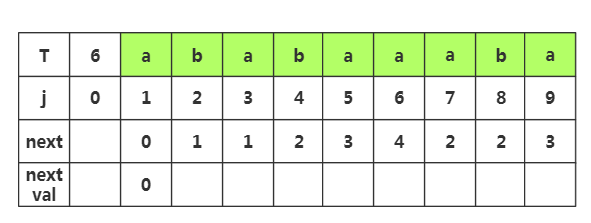
第二步:获取j=2时,nextval[2]的值,首先我们需要获取next[2]值为1,然后我们将这个值作为新得前缀获取j=1时的T串数据'a',发现他与当前j=2处的字符'b'不同,那么nextval[2]不变,与原来的next[2]值一样,为1
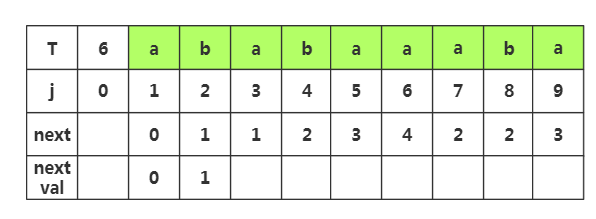
第三步:获取j=3时,nextval[3]的值,我们先获取next[3]的值为1,然后将这个值作为新的索引获取j=该值处的字符T[1]='a',发现T[3]=T[1],所以当前的nextval值为j=1处的nextval值,即nextval[3]=nextval[1]=0

第四步:获取j=4时,nextval[4]的值,相应的next[4]为2,获取T[2]字符‘b’,与当前所以T[4]='b'相同,那么当前nextval[4]=nextval[2]=1
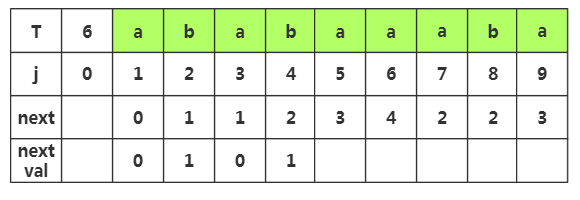
第五步:获取j=5时,nextval[5]的值,相应next[5]=3,查看T[3]字符为'a',而当前T[5]='a',相同,那么nextval[5]=nextval[3]=0
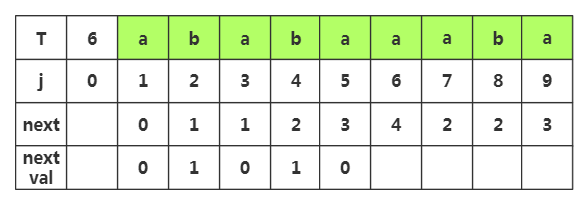
第六步:获取j=6时,nextval[6]的值,相应next[6]=4,查看T[4]字符为'b',而当前T[6]='a',不相同,那么nextval[5]就等于原来的next[5]值为4

第七步:获取j=7时,nextval[7]的值,相应next[7]=2,查看T[2]字符为'b',而当前T[7]='a',不相同,那么nextval[7]就等于原来的next[7]值为2

第八步:获取j=8时,nextval[8]的值,相应next[8]=2,查看T[2]字符为'b',而当前T[8]='b',相同,那么nextval[7]=nextval[2]=1
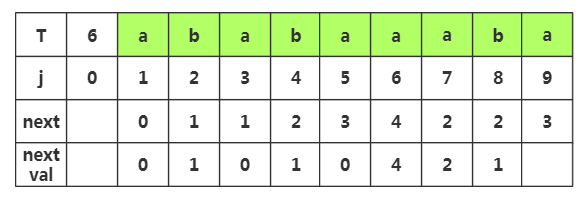
第九步:获取j=9时,nextval[9]的值,相应next[9]=3,查看T[3]字符为'a',而当前T[9]='a',相同,那么nextval[9]=nextval[3]=0
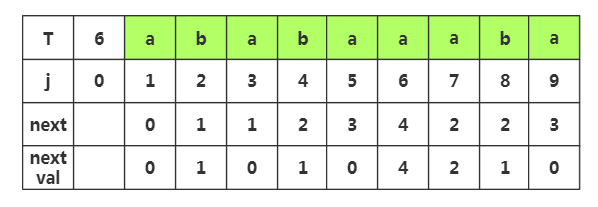
推导2:对上面进行优化的步骤演示
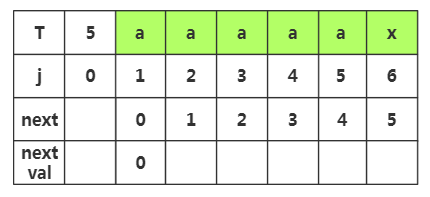
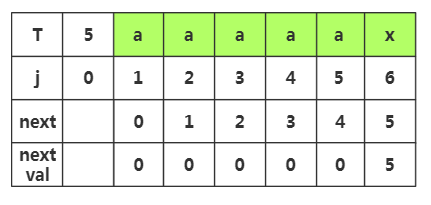
第一步:当j=1时,nextval=0
第二步:当j=2时,next[2]=1,T[2]=T[1]='a',nextval[2]=nextval[1]=0
第三步:当j=3时,next[3]=2,T[3]=T[2]='a',nextval[3]=nextval[2]=0
第四步:当j=4时,next[4]=3,T[4]=T[3]='a',nextval[4]=nextval[3]=0
第五步:当j=5时,next[5]=4,T[5]=T[4]='a',nextval[5]=nextval[4]=0
第六步:当j=6时,next[6]=5,T[6]='x',T[5]='a',T[6]≠T[5],nextval[6]=next[6]=5
nextval数组优化代码
void get_nextval(String T, int* nextval) { int m, j; j = 1; //j是后缀的末尾下标 m = 0; //m代表的是前缀结束时的下标 nextval[1] = 0; while (j < T[0]) { if (m == 0 || T[m] == T[j]) //T[m]表示前缀的最末尾字符,T[j]是后缀的最末尾字符 { ++m; ++j; if (T[j] != T[m]) //若当前字符与前缀字符不同 nextval[j] = m; //则当前的j为nextval在i位置的值 else nextval[j] = nextval[m]; //若与前缀字符相同,则将前缀字符的nextval值赋给nextval在i位置的值 } else m = nextval[m]; //若是字符不相同,则m回溯 } }
总结:
若是迷迷糊糊,不如在演草纸上多默写几遍,慢慢就会有思路了...

