python---RabbitMQ(1)简单队列使用,消息依次分发(一对一),消息持久化处理
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。
MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取或者订阅队列中的消息。
RabbitMQ是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统。
推荐文章:
3.安装以及大致了解
4.windows下的安装(其中注意版本一致,Erlang版本不要太低)
补充:远程连接rabbitmq server需要配置权限
1.在服务端创建创建rabbitmq账号
sudo rabbitmqctl add_user 用户名 密码
2.为账号配置权限
sudo rabbitmqctl set_permissions -p / 账号 ".*" ".*" ".*"
set_permissions [-p vhost] {user} {conf} {write} {read}
该命令使用户具有/这个virtual host中所有资源的配置、写、读权限以便管理其中的资源
3.客户端连接时认证方式
#1.设置远程账号密码 credentials = pika.PlainCredentials('账号', '密码') #2.设置参数,创建连接,这是链接一个socket connection = pika.BlockingConnection(pika.ConnectionParameters( host='远程主机ip',端口号,'/',credentials #/代表的是服务端rabbitmq的虚拟主机资源目录 )) #3.根据socket连接,在其基础上创建Channel通道, channel = connection.channel()
python使用:
简单队列模型:(exchange交换机不工作模式)
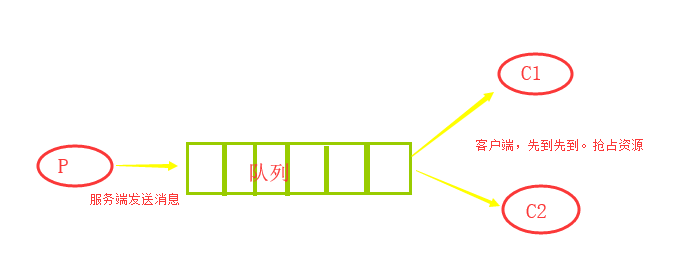
生产者:
import pika #1.设置参数,创建连接 connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost' )) #2.根据连接创建Channel通道 channel = connection.channel() #3.创建queue(名为hello)和channel进行绑定 channel.queue_declare(queue='hello') #4.生成消息,发布到队列中 channel.basic_publish(exchange='', routing_key='hello',#去相关队列中
body='Hello world')
print('Send Hello World th queue')
#5.关闭连接 connection.close()
持久化处理:服务端注意,当服务端断电或者其他情况,导致消息原本存在内存中的消失,更可靠的是将数据放到磁盘中保存,更安全,但是降低效率 。
决定权在于客户端是否设置应答,若是无应答,消息接收后立刻消失,不需要持久化,有应答时,需要将消息持久化处理,因为可能客户端在调用回调函数需要耗时太长,中途挂了,那么这个消息在服务器端需要再次恢复到消息队列中。
#3.创建queue(名为hello)和channel进行绑定 channel.queue_declare(queue='hello',durable=True) #durable持久化,将这个队列持久化,重启服务器,这个队列依旧存在 #4.生成消息,发布到队列中 channel.basic_publish(exchange='', routing_key='hello', body='Hello world', properties=pika.BasicProperties( #将消息保存在本地磁盘持久化处理,在上面durable基础上,将持久化队列中的消息一块持久化了 delivery_mode=2,#默认是1 ))
修改上面两处
消费者:
import pika #1.设置参数,获取一个connection连接 connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost' )) #2.利用connection创建一个channel通道 channel = connection.channel() #3.将channel通道和queue(之前生产者创建的队列)进行绑定 channel.queue_declare(queue='hello')#生产者和消费者只要有一个先声明,就会去创建这个队列,不会重复创建 #回调函数,处理消息内容 def callback(ch,method,properties,body): print("Recvived %s"%body) # consumer_callback(channel, method, properties, body) # channel: BlockingChannel,通道实例 # method: spec.Basic.Deliver,头部消息,附带一些数据 # properties: spec.BasicProperties, # body: str or unicode,数据内容,byte格式 #4.创建消费者进行消息处理 channel.basic_consume(callback, queue='hello', no_ack=True)#无应答,默认false print("Waiting for message") #5.开启消费者 channel.start_consuming()#这里开始堵塞,等待获取信息,开始消费,这个是IO循环一致等待,不会退出
客户端注意:no_ack=True/False #无应答/有应答
#回调函数,处理消息内容 def callback(ch,method,properties,body): import time time.sleep(10) #在此处可以进行中断测试,查看有无应答 print("Recvived %s"%body)
若是回调函数处理数据时,需要耗费大量时间,而客户端并未处理而退出,那么这条消息是否应该继续存在在队列中,当设置无应答no_ack=True时,消息从队列中取出后即消失。消息的安全性不够,但是效率高
当设置为有应答no_ack=False时,消息经过客户端成功处理后会返回响应码进行应答操作,确保消息被处理后,才会从消息队列中删除。安全性够好,但是等待过程效率低
在设置为有应答时,需要在回调函数末尾中添加:
ch.basic_ack(delivery_tag=method.delivery_tag) #唯一标识,自动生成,用于在回调函数中,进行应答
进行回应
另外:对于rabbitmq的消息分发,默认是按照顺序,有几个消费者,大家一个一个来,但是由于每个消费者的消费速度不一致,会导致时间上,某些消费者会产生空闲
所以需要修改这种状态,在消费者这地方修改,修改消费者取数据模式,添加:
channel.basic_qos(prefetch_count=1)
这样,谁空闲,谁就来获取数据
