第十期机器学习基础 02注意力机制和Transformer/Bert
一:注意力机制
(一)前提背景
1.人类的选择性视觉注意力
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
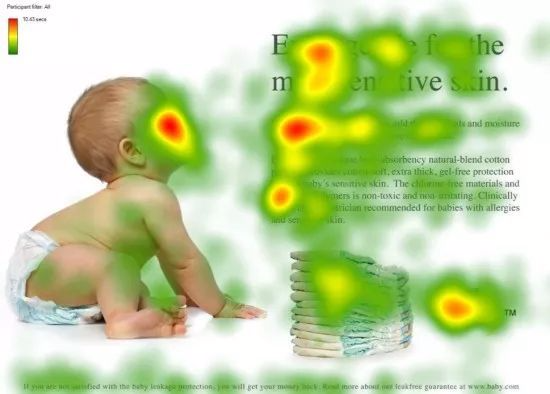
图中形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图中所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
2.Encoder-Decoder框架(典型的注意力机制)
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。
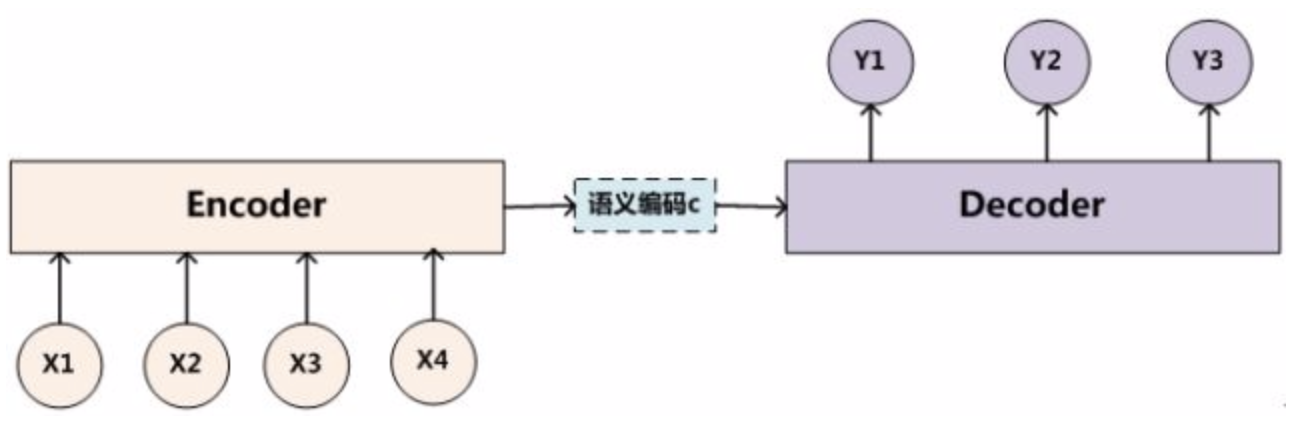
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。
对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。
Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
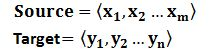
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
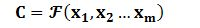
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息$$y_1,y_2,...y_{i-1}$$来生成i时刻要生成的单词
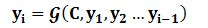
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。
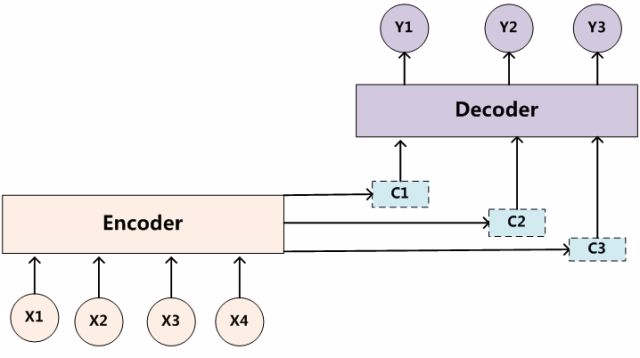
如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如对于语音识别来说完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
(二)Attention模型分类
从广义来说可分为三类:自注意(内注意)、软注意(全局注意)和硬注意(局部注意)
1.自注意力机制(Self/Intra Attention)---后面详细讲解,还会扩展
对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和后面两种相比,在处理很长的输入时,具有并行计算的优势。
2.软注意机制(Global/Soft Attention)
对每个输入项的分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。
3.硬注意机制(Local/Hard Attention)
对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑哪部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。
后面主要讲解一下软注意力和自注意力机制!
(三)软注意力机制(Soft Attention)
本节还是以前面的机器翻译作为例子,讲解最常见的Soft Attention模型的基本原理,之后抛离Encoder-Decoder框架抽象出了注意力机制的本质思想。
1.前文Encoder-Decoder框架是没有注意力能力的
前文Encoder-Decoder框架是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Target中每个单词的生成过程如下:
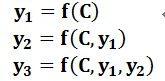
其中f是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。而语义编码C是由句子Source的每个单词经过Encoder编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子Source中任一单词对生成某个目标单词yi来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
2.汤姆追逐杰瑞(Tom chase Jerry)
如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
上面的例子中,如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2) (Jerry,0.5)每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。
同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词yi的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的Ci。
理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架理解起来如下图所示:
即生成目标句子单词的过程成了下面的形式:

而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:

其中,f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入xi后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数(当前生成词时),一般的做法中,g函数就是对构成元素加权求和,即下列公式:(生成单词i时,每一个词hj在i时刻的注意力系数aij乘积和)

其中,Lx代表输入句子Source的长度,aij代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,而hj则是Source输入句子中第j个单词的语义编码。
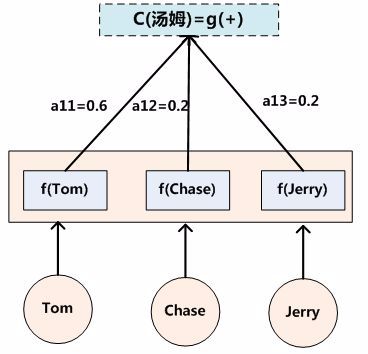
假设下标i就是上面例子所说的“汤姆”,那么Lx就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,所以g函数本质上就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示Ci的形成过程类似下图:
3.Attention在架构中的位置
首先我们前面的非Attention模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置:
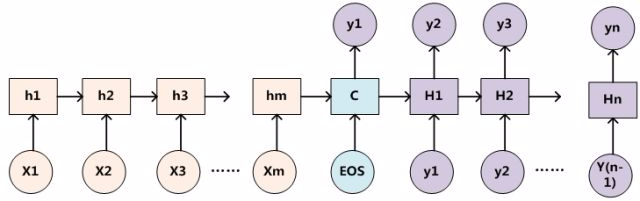
那么就会有一个问题:生成目标句子某个单词,比如“汤姆”的时候,如何知道Attention模型所需要的输入句子单词注意力分配概率分布值呢?
就是说“汤姆”对应的输入句子Source中各个单词的概率分布:(Tom,0.6)(Chase,0.2)(Jerry,0.2) 是如何得到的呢?
这个时候就要引入我们的汇聚层(注意力层):来说明注意力分配概率分布值的通用计算过程
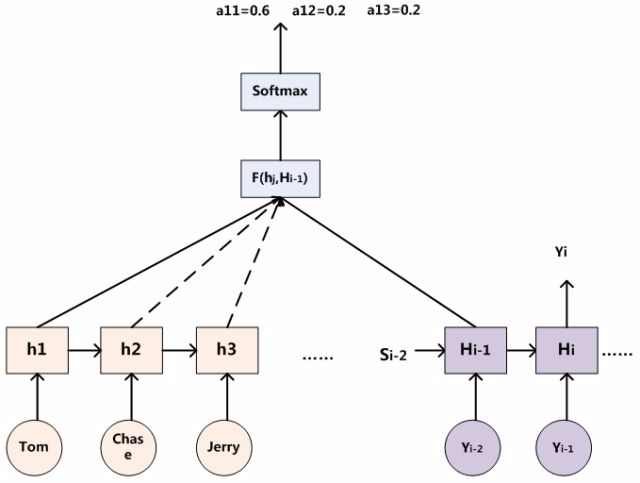
对于采用RNN的Decoder来说,在时刻i,如果要生成yi单词,我们是可以知道Target在生成Yi之前的时刻i-1时,隐层节点i-1时刻的输出值Hi-1的,而我们的目的是要计算生成Yi时输入句子中的单词“Tom”、“Chase”、“Jerry”对Yi来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态Hi-1去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,Hi-1)来获得目标单词yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
绝大多数Attention模型都是采取上述的计算框架来计算注意力分配概率分布信息,区别只是在F的定义上可能有所不同。
4.Attention表现形式
下图可视化地展示了在英语-德语翻译系统中加入Attention机制后,Source和Target两个句子每个单词对应的注意力分配概率分布:
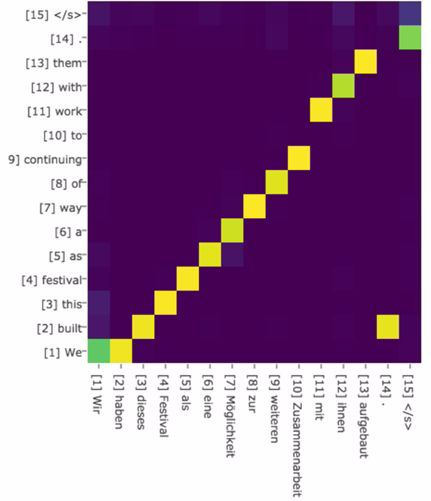
可以看到目标词和源词的对齐关系!
5.Attention机制的本质思想
如果把Attention机制从上文讲述例子中的Encoder-Decoder框架中剥离,并进一步做抽象,可以更容易看懂Attention机制的本质思想。
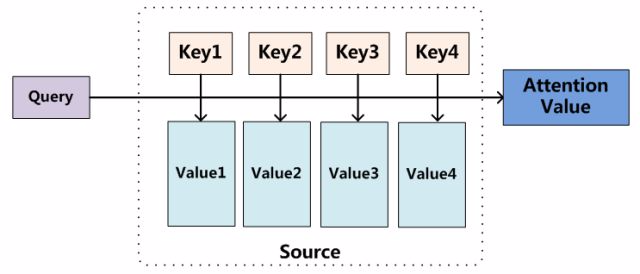
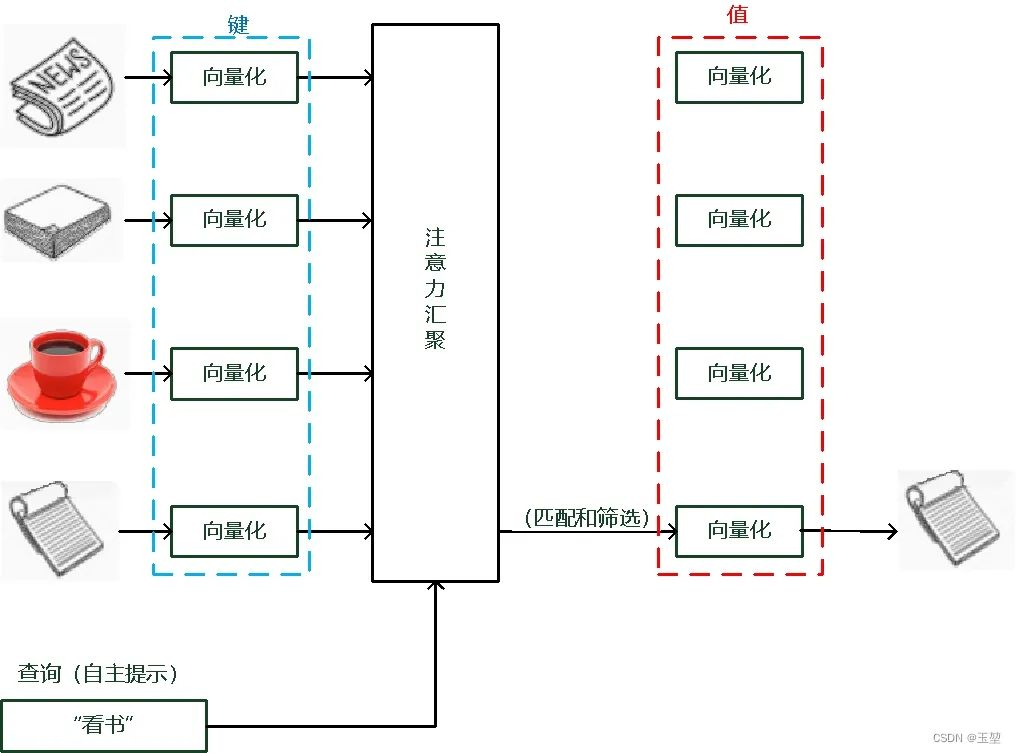
我们可以这样来看待Attention机制:将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数,即可以将其本质思想改写为如下公式:
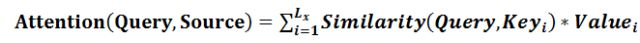
其中,Lx=||Source||代表Source的长度,公式含义即如上所述。上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。
当然,从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。
而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理。
这样,可以将Attention的计算过程抽象为下图展示的三个阶段:
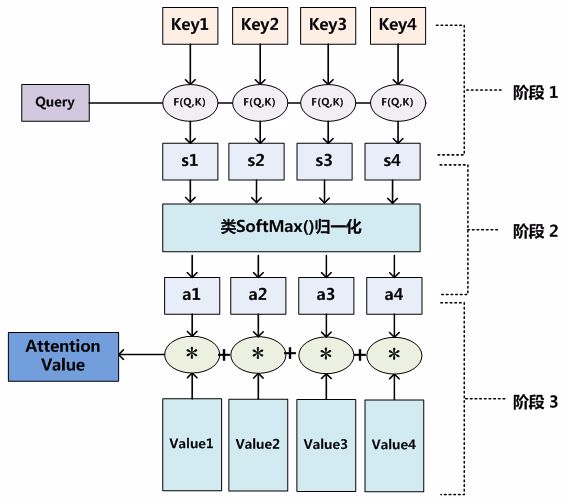
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个Key_i,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量余弦相似性或者通过再引入额外的神经网络来求值,分值根据具体产生的方法不同其数值取值范围也不一样,即如下方式:

第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。计算结果a_i即为value_i对应的权重系数,即一般采用如下公式计算:
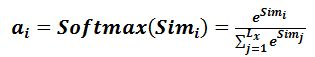
第三阶段进行加权求和即可得到Attention数值:

通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
6.Masked Attention机制
有时候,我们并不想在做attention的时候,让一个token看到整个序列,我们只想让它看见它左边的序列,而要把右边的序列遮蔽(Mask)起来。
例如在transformer的decoder层中,我们就用到了masked attention,这样的操作可以理解为模型为了防止decoder在解码encoder层输出时“作弊”,提前看到了剩下的答案,因此需要强迫模型根据输入序列左边的结果进行attention。
Masked的实现机制其实很简单,如图:
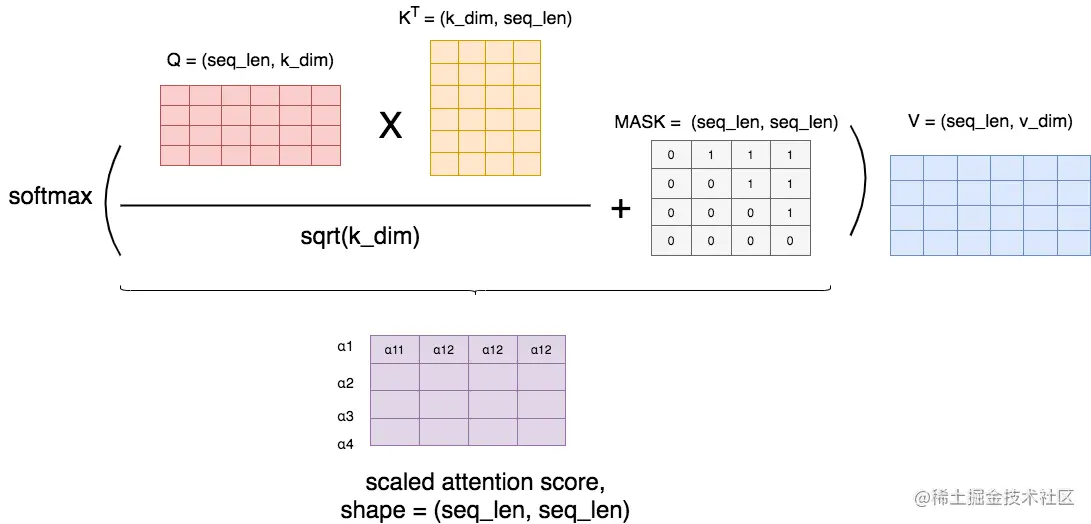
首先,我们按照前文所说,正常算attention score,然后我们用一个MASK矩阵去处理它(这里的+号并不是表示相加,只是表示提供了位置覆盖的信息)。在MASK矩阵标1的地方,也就是需要遮蔽的地方,我们把原来的值替换为一个很小的值(比如-1e09),而在MASK矩阵标0的地方,我们保留原始的值。这样,在进softmax的时候,那些被替换的值由于太小,就可以自动忽略不计,从而起到遮蔽的效果。
举例来说明MASK矩阵的含义,每一行表示对应位置的token。例如在第一行第一个位置是0,其余位置是1,这表示第一个token在attention时,只看到它自己,它右边的tokens是看不到的。以此类推。
(四)自注意力机制(self Attention)
Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,其具体计算过程是一样的,只是计算对象发生了变化而已,self Attention允许模型在输入序列中的不同位置之间进行交互,以捕获序列内部的依赖关系。
1.案例,通过自注意力发现内部语料之间的关系
假设以下句子是我们要翻译的输入句子:
” The animal didn’t cross the street because it was too tired”
这句话中的“it”指的是什么?it指的是street还是animal?这对人类来说是一个简单的问题,但对算法来说却不是那么简单。当模型处理“it”这个词时,self-attention 允许它把“it”和“animal”联系起来。当模型处理每个单词(输入序列中的每个位置)时,自注意力允许它查看输入序列中的其他位置以寻找有助于更好地编码该单词的线索。

2.自注意力架构
再次强调:自注意力机制,给Attention的输入都来自同一个序列,其计算方式如下:
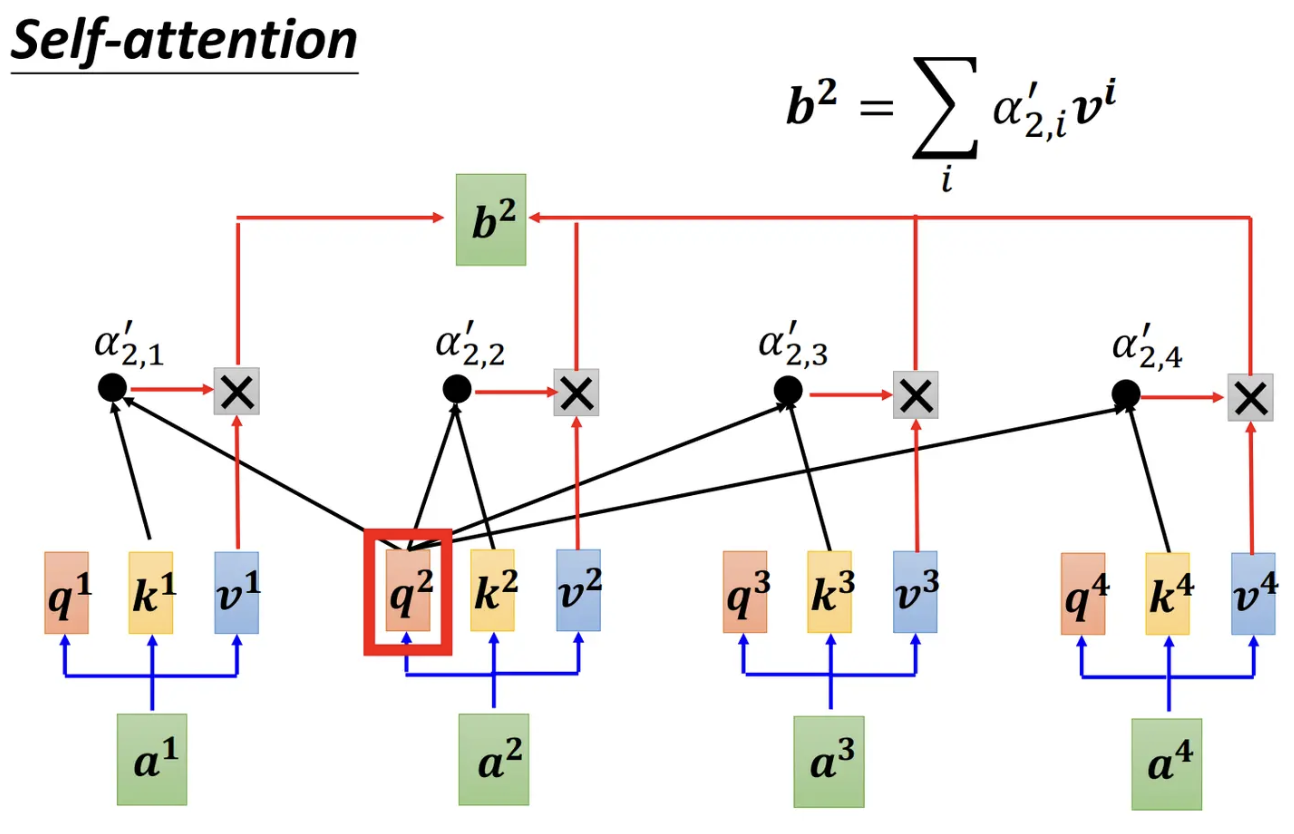
所表示的大致运算过程是:对于每个单词token,先产生三个向量query,key,value(可以认为是一个二维矩阵),以图中的token a2为例:
- 它产生一个query,每个query都去和别的token的key做相似/相关性的计算,得到的结果我们称为attention权重系数(即为图中的α)。则一共得到四个attention权重。
- 将这四个score分别乘上每个token的value,我们会得到四个抽取信息完毕的向量。
- 将这四个向量相加,就是最终a2过attention模型后所产生的结果b2。
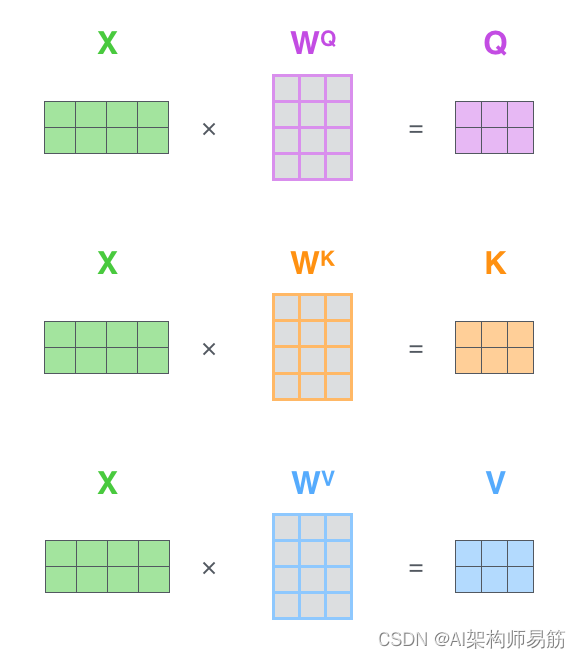
顺道看一下自注意力机制的q、k、v生成过程:
- 先看一下单个单词生成qkv的过程
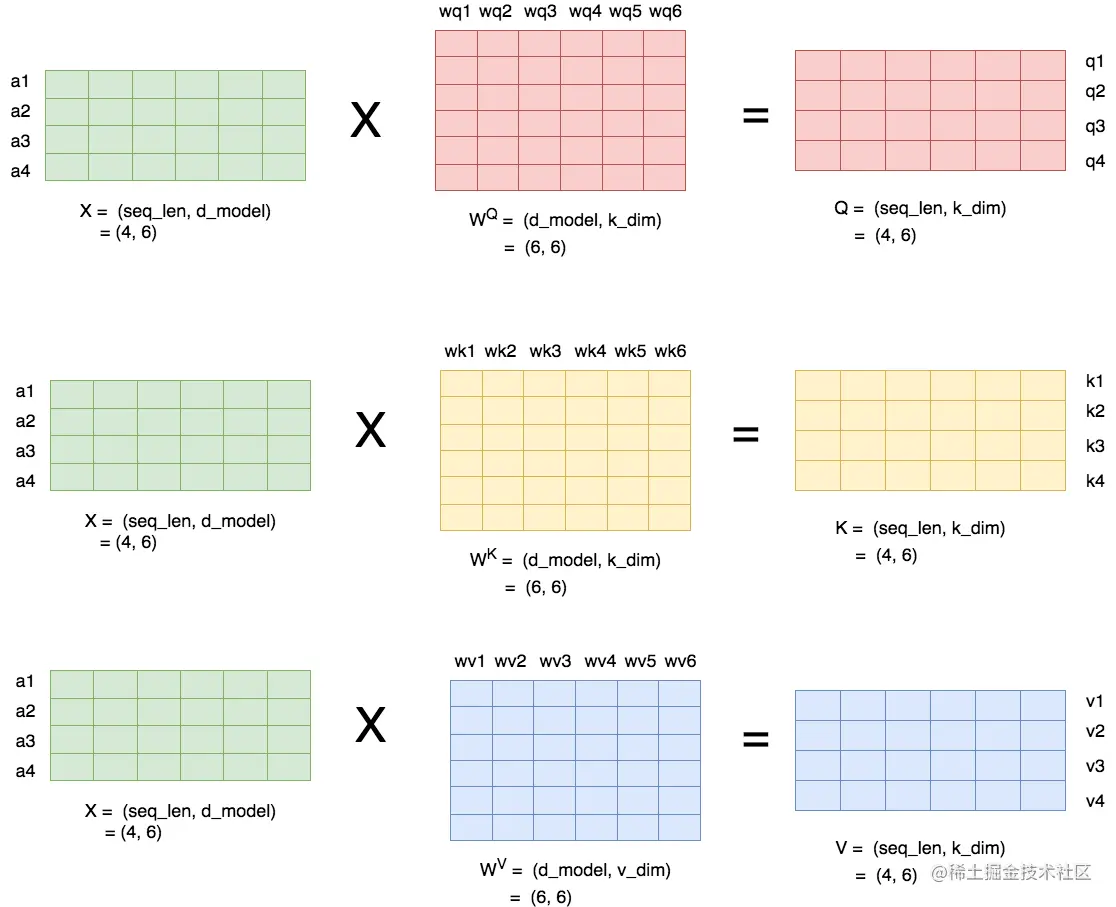
- 再看对于一个序列如何生存对应的qkv
3.self Attention的优点
- 引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
- Self Attention对于增加计算的并行性也有直接帮助作用,因为只关注本身,可以并行对source进行处理,后面的多头自注意力机制便是利用了并行。
这是为何Self Attention逐渐被广泛使用的主要原因。
4.多头自注意力机制
在图像中,我们知道有不同的channel,每一个channel可以用来识别一种模式。如果我们对一张图采用attention,比如把这张图的像素格子拉平成一列,那么我们可以对每个像素格子训练不同的head,每个head就类比于一个channel,用于识别不同的模式。
如下图:一种颜色表示一个头下attention score的分数,可以看出,不同的头所关注的点各不相同。

多头注意力是一种注意力机制的扩展形式,模型使用多个注意力头(即并行的注意力子机制)来捕获不同的关注点。每个注意力头都会学习不同的注意力权重,然后将它们组合起来以获得更全面的表示。
例如,在Transformer模型中,每个注意力头可以关注输入序列中的不同方面,比如语义信息、句法信息等。通过使用多个注意力头,模型能够从多个角度更全面地理解输入序列。
总之,自注意力是一种特殊类型的注意力机制,用于在输入序列内部建立元素之间的关系;而多头注意力是一种扩展形式,使用多个并行的自注意力头来捕获不同的关注点,以更全面地理解输入序列。多头注意力机制架构如下:
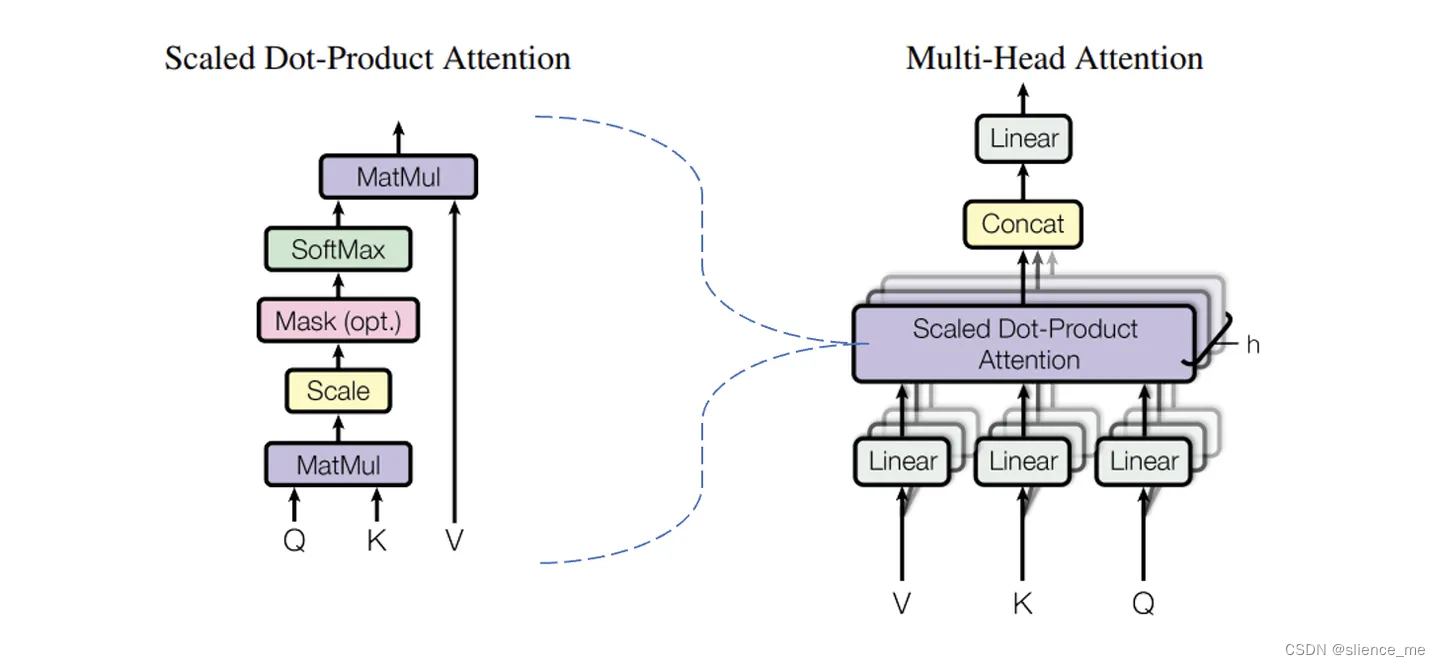
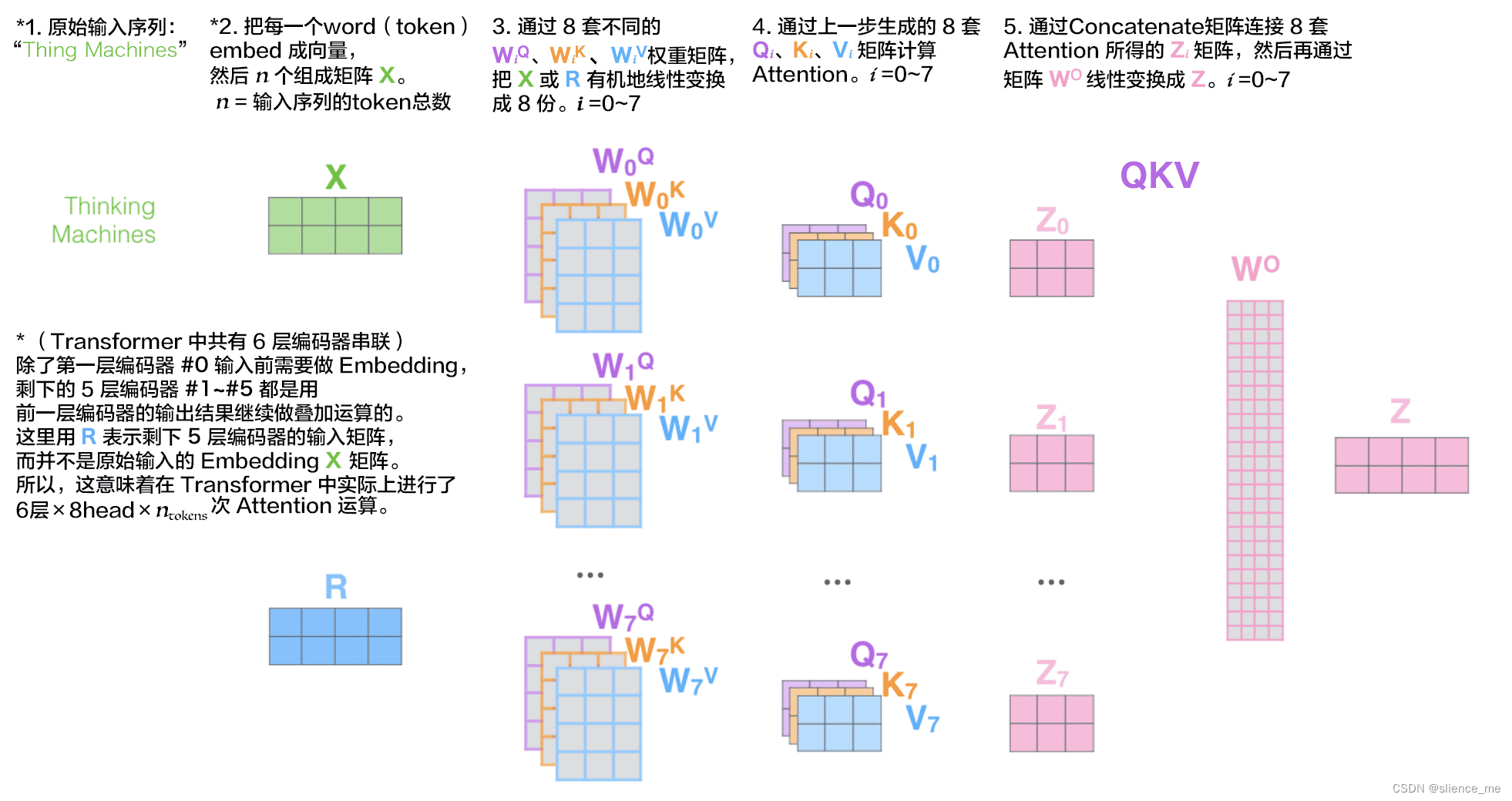
计算步骤如下:
- 把每一个token通过8个不同的权重矩阵,线性变换到不同的向量空间,生成8个不同的qkv
- 通过每一个qkv在不同的空间,进行计算,对在不同空间中得到的向量进行组合线性变换得到最后的结果
多头注意力机制的优点:
- 并行处理多种注意力模式:每个注意力头使用不同的线性变换,这意味着它们可以从输入序列的不同子空间中学习不同的特征关联。这样一来,模型可以通过多个注意力头同时关注输入序列的不同方面,例如语法结构、语义角色、主题转移等。
- 增加模型的学习能力和表达力:通过多个注意力头,模型可以学习到更丰富的上下文信息,每个头可能关注输入的不同特征,这些特征综合起来可以更全面地理解和处理输入序列。
- 提高模型性能:实验证明,多头注意力机制相较于单头注意力,往往能带来性能提升。这是因为模型可以通过并行处理和集成多个注意力头的结果,从不同角度捕捉数据的多样性,增强了模型对复杂序列任务的理解和泛化能力。
二:Transformer架构
(一)Transformer架构
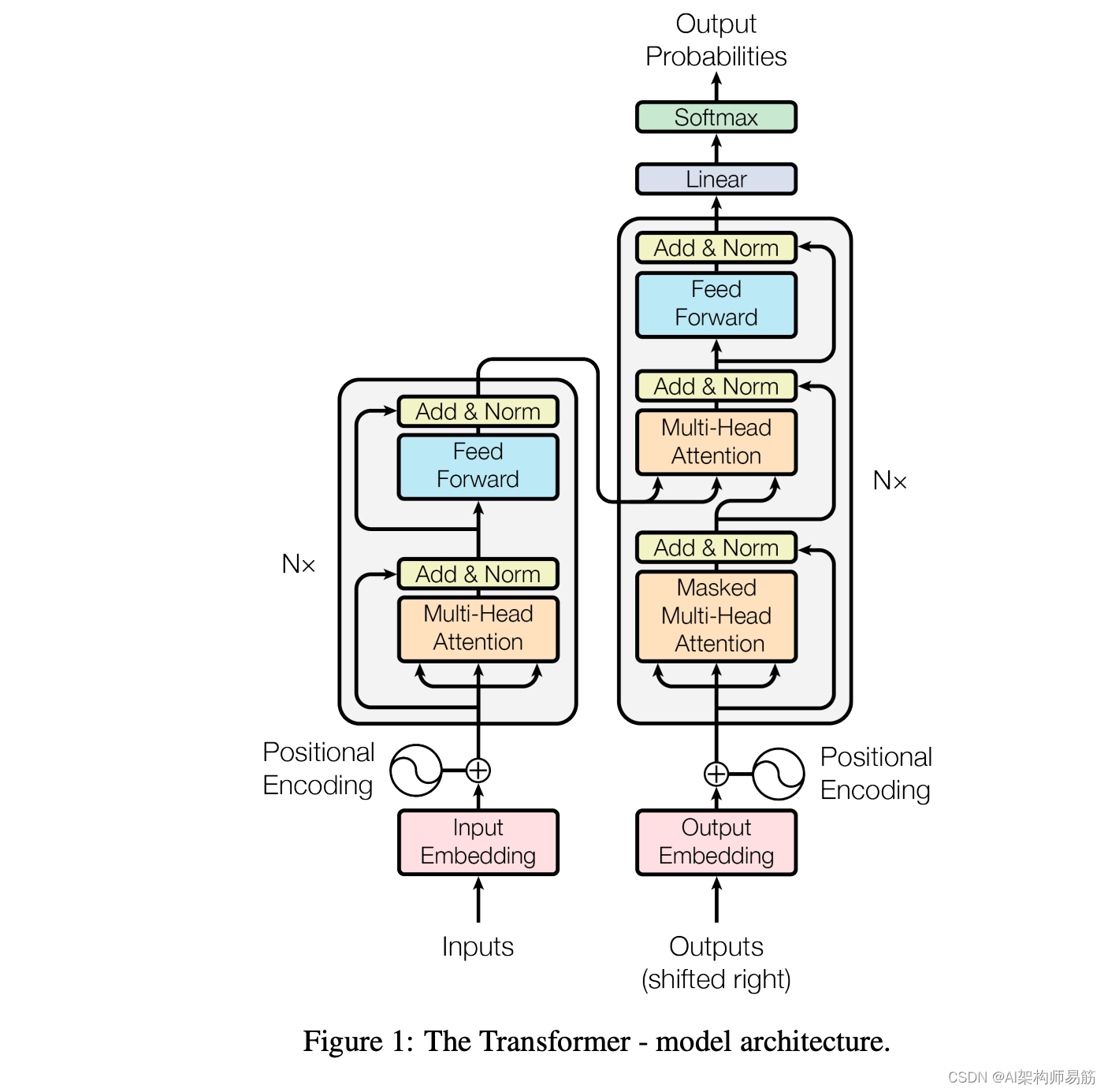
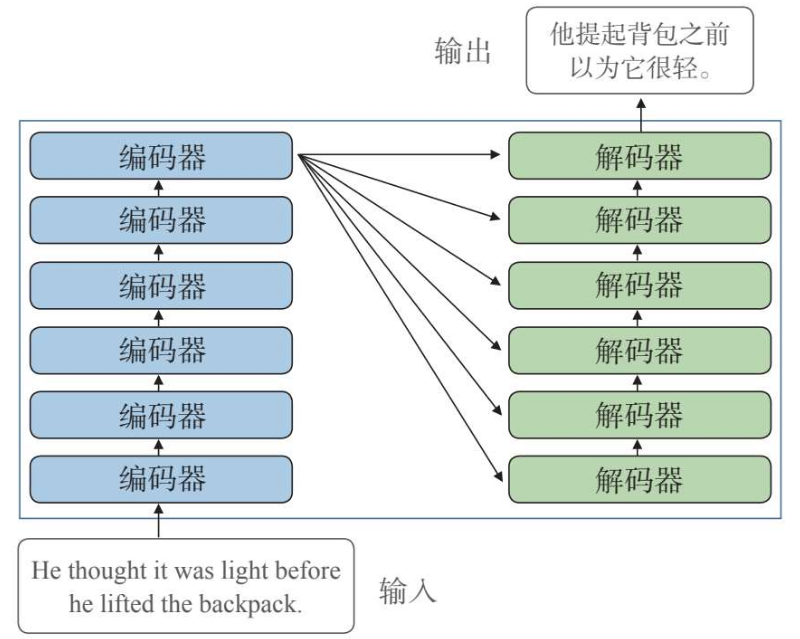
Transformer模型在普通的Encoder-Decoder框架结构基础上做了升级,它的编码端是由多个编码器串联构成的,而解码端同样由多个解码器构成。它同时也在输入编码和自注意力方面做了优化,例如采用多头注意力机制、引入位置编码机制等等,能够识别更复杂的语言情况,从而能够处理更为复杂的任务。
这里提供一种Transformer的简易架构:
(二)Transformer编码器
Transformer中的编码器不止一个,而是由一组编码器串联而成。一个编码器的输出作为下一个编码器的输入。在上图中有个编码器,每一个编码器都从下方接收数据,再输出给上方,以此类推,原句中的特征会由最后一个编码器输出,编码器模块的主要功能就是提取原句中的特征。
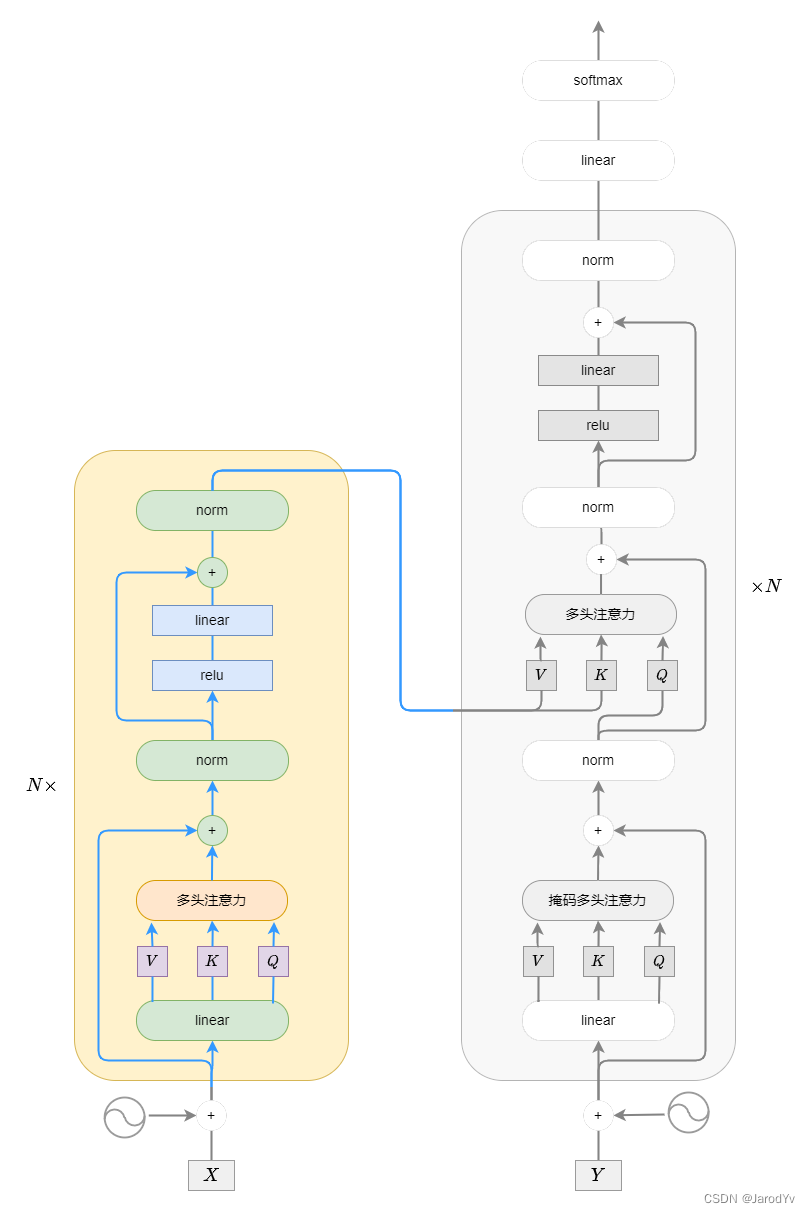
Transformer模型的每个编码器有两个主要部分:自注意力机制和前馈神经网络
- 自注意力机制通过计算前一个编码器的输入编码之间的相关性权重,来输出新的编码。
- 然后前馈神经网络对每个新的编码进行进一步处理,然后将这些处理后的编码作为下一个编码器或解码器的输入。
补充:前馈神经网络---强大的特征学习、表达能力
前馈神经网络(Feedforward Neural Network,FNN)是最基本的一种人工神经网络结构,它由多层节点组成,每层节点之间是全连接的,即每个节点都与下一层的所有节点相连。前馈神经网络的特点是信息只能单向流动,即从输入层到隐藏层,再到输出层,不能反向流动。
FNN在NLP中扮演重要角色,主要是因为其强大的特征学习和表示能力。NLP任务通常需要对文本数据进行复杂的特征提取和表示,而FNN可以通过学习文本的语义和上下文信息,自动提取出有用的特征,并将其表示为向量形式。这种向量表示不仅便于计算,而且能够捕捉文本之间的相似性和差异性,为后续的NLP任务提供有力的支持。
(三)Transformer解码器
对于解码器部分,也由多个解码器组成,每个解码器有三个主要部分:带掩码的自注意力机制、针对编码器的注意力机制和前馈神经网络。
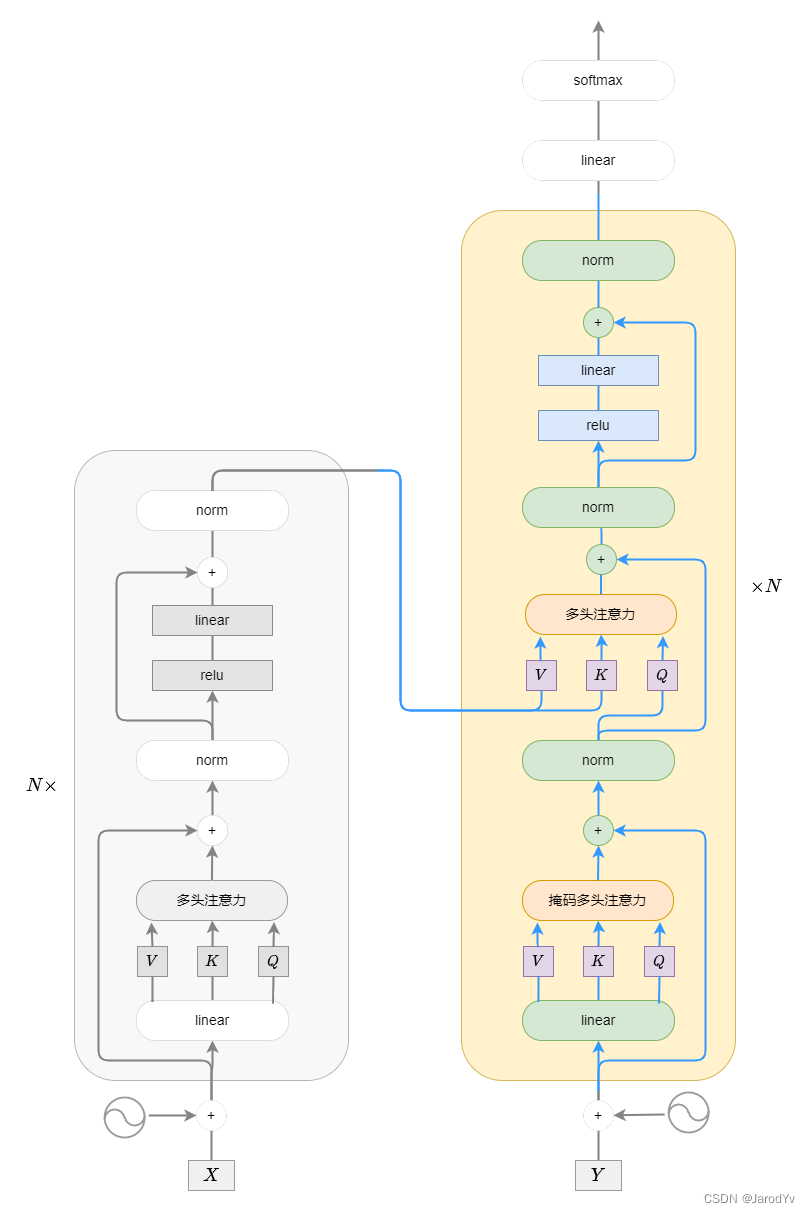
- 带掩码的自注意力机制:在decoder层中,我们用到了masked attention,这样的操作可以理解为模型为了防止decoder在解码encoder层输出时“作弊”,提前看到了剩下的答案,因此需要强迫模型根据输入序列左边的结果进行attention。
- 针对编码器的注意力机制:每个解码器中的多头注意力层都有两个输入:一个来自带掩码的多头注意力层,另一个是编码器输出的特征值。(这里就不是自注意力机制了)
- 前馈神经网络:跟编码器一样,每个Transformer块之间都有残差连接和层归一化,用于保持信息流的顺畅和避免梯度消失。
三:Bert架构
(一)Bert模型架构
BERT 只使用了 Transformer 的 Encoder 模块,且只包含Encoder模块,由多个Encoder block模块堆叠而成。其架构如下图所示:
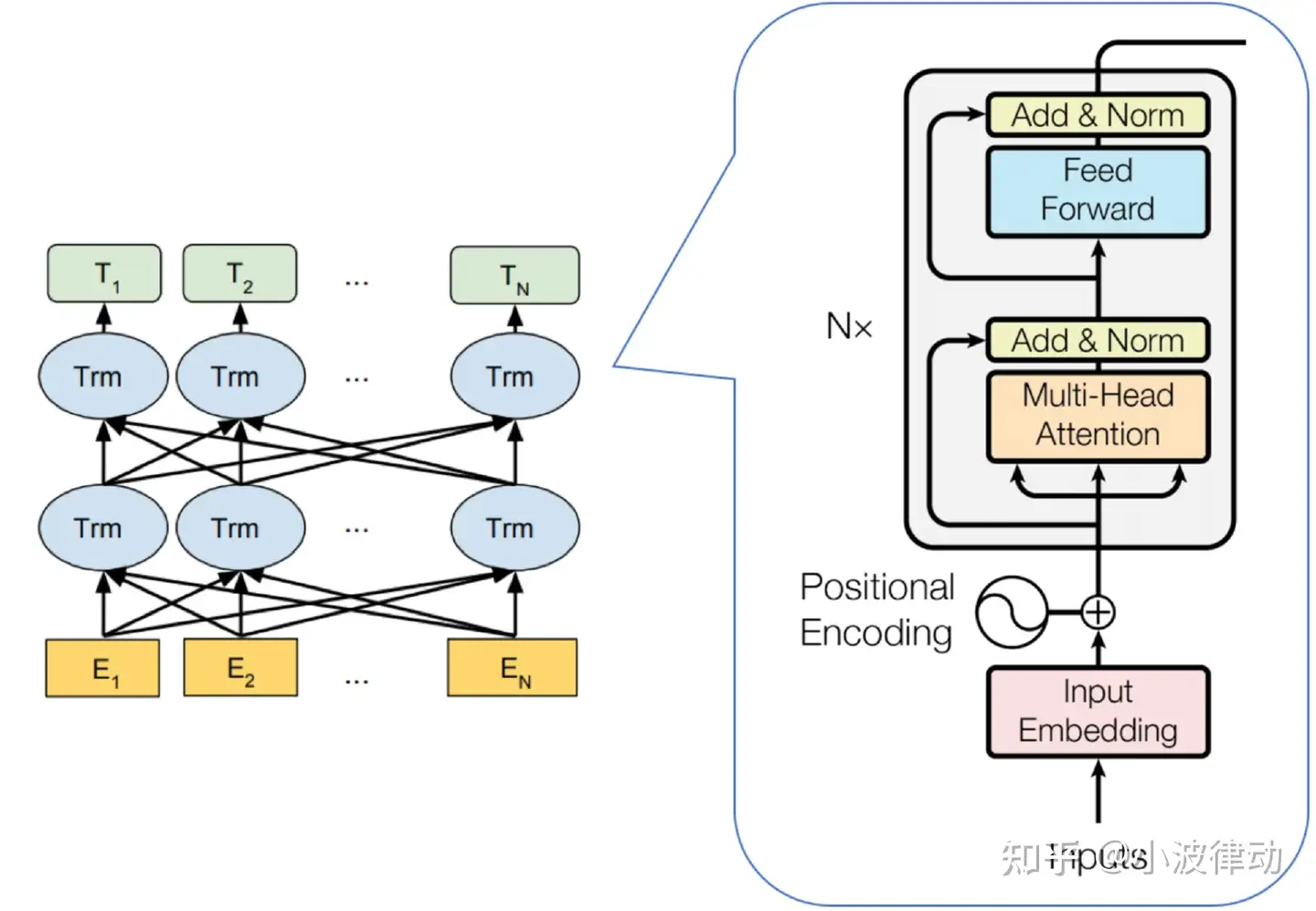
从上图左侧,我们可以看到BERT包含三种模块:
- 最底层⻩⾊标记的Embedding模块
- 中间层蓝⾊标记的Transformer模块
- 最上层绿⾊标记的预微调模块
上图图中蓝色模块被画成了两层,这表示BERT模型中堆叠了多个Transformer编码器块。
BERT模型有两种规模:Base版和Large版
- Base版包含12层Transformer编码器,隐藏层大小为768,自注意力头数为12,总参数量约为110M;
- Large版则包含24层Transformer编码器,隐藏层大小为1024,自注意力头数为16,总参数量约为340M。
BASE版:L = 12,H = 768,A = 12,总参数量为 1.1 亿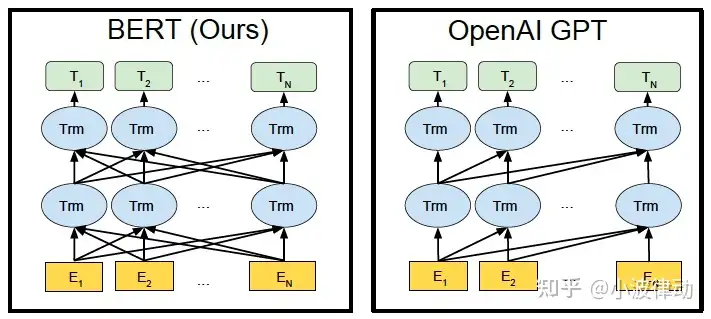
举个例子:考虑一个文本序列“今天天气很好,我们决定去公园散步。”1.单向编码
单向编码指的是在编码过程中,模型只能利用到当前位置之前的文本信息(或只能利用到当前位置之后的文本信息,但这种情况较少见),而无法同时利用到当前位置前后的文本信息。这种编码方式使得模型在处理文本时具有一种“前瞻性”或“回顾性”,但缺乏全局的上下文理解能力。GPT是一个典型的采用单向编码的预训练语言模型。GPT使用Transformer的解码器部分作为其主要结构,通过自回归的方式进行训练,即模型在生成下一个词时只能看到之前的词,无法看到之后的词。在单向编码中,每个词或标记的编码仅依赖于其之前的词或标记。因此,在编码“决定”这个词时,模型只会考虑“今天”、“天气”、“很好”和“我们”这些在它之前的词。
2.双向编码
双向编码则允许模型在编码过程中同时利用到当前位置前后的文本信息,从而能够更全面地理解文本的上下文。这种编码方式使得模型在处理文本时具有更强的语义理解能力和更丰富的信息来源。BERT是一个典型的采用双向编码的预训练语言模型。BERT通过掩码语言模型(MLM)的方式进行训练,即随机掩盖文本中的部分词汇,然后让模型预测这些被掩盖的词汇。在双向编码中,每个词或标记的编码都会同时考虑其前后的词或标记。因此,在编码“决定”这个词时,模型会同时考虑“今天”、“天气”、“很好”以及之后的“去公园散步”等词,从而更全面地理解整个句子的语义。
(三)Bert原理
BERT 的创新点在于它将双向 Transformer 用于语言模型,双向训练的语言模型对语境的理解会比单向的语言模型更深刻,论文中介绍了一种新技术叫做 Masked LM(MLM),在这个技术出现之前是无法进行双向语言模型训练的。Transformer 的原型包括两个独立的机制,一个 encoder 负责接收文本作为输入,一个 decoder 负责预测任务的结果;BERT 是一个自编码语言语言模型,所以只需要 encoder 机制,通过自注意力机制,可以学习文本中单词之间的上下文关系的。Transformer 的 encoder 是一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取,这个特征使得模型能够基于单词的两侧学习,相当于是一个双向的功能。当我们在训练语言模型时,有一个挑战就是要定义一个预测目标,很多模型在一个序列中预测下一个单词, “The child came home from ___” 双向的方法在这样的任务中是有限制的,为了克服这个问题,BERT 使用两个策略:MLM和NSP(四)Masked LM (MLM)
随机掩盖掉一些单词,然后通过上下文预测该单词。BERT中有15%的token会被随机掩盖,这15%的token中80%用[MASK]这个token来代替,10%用随机的一个词来替换,10%保持这个词不变。这种设计使得模型更容易捕捉上下文关系的能力。1.为什么选中的15%的token不能全部用 [MASK]代替,而要用 10% 的 random token 和 10% 的原 token?
[MASK] 是以一种显式的方式告诉模型『这个词我不告诉你,你自己从上下文里猜』,从而防止信息泄露。如果 [MASK] 以外的部分全部都用原 token,模型会学到『如果当前词是 [MASK],就根据其他词的信息推断这个词,如果推断出的词是一个正常的单词,就直接抄输入』。这样一来,在 finetune 阶段,如果预测词是正常单词,模型就照抄所有词,不再考虑微调后的预测值是否被动了手脚,不提取上下文和预测单词间的依赖关系了。以一定的概率填入 random token,就是让模型时刻堤防着,在任意 token 的位置都需要把当前 token 的信息和上下文推断出的信息相结合。这样一来,在 finetune 阶段的正常句子上,模型也会同时提取这两方面的信息,因为它不知道它所看到的『正常单词』到底有没有被动过手脚的。2.最后怎么利用[MASK] token做的预测?
最终的损失函数只计算被mask掉的token的(包括10%的原token和10%的随机token),每个句子里 [MASK] 的个数是不定的。实际代码实现是每个句子有一个 maximum number of predictions,取所有 [MASK] 的位置以及一些 PADDING 位置的向量拿出来做预测(总共凑成 maximum number of predictions 这么多个预测,是定长的),然后再用掩码把 PADDING 盖掉,只计算[MASK]部分的损失。(五)Next Sentence Prediction (NSP)
在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入 BERT的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。(六)Bert的特点:并发、参数大
BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。同时缺点也是显而易见的,模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号