LangChain补充六:Evals评估AI应用质量
https://www.alang.ai/langchain/101/lc08
构建一个AI应用之后,需要根据输入和调用链的输出评估(Evals) AI 应用的质量
在 AI 模型研发中,评估模型返回的质量
在 AI 应用开发的场景中,评估一个包含 AI 模型的调用链的质量主要评估方式:我们提供输入(input)、输出(prediction)与评估标准(reference),然后采用某个 AI 大语言模型来自动对结果进行评估,评估模型会给出推理过程(reasoning)、值(value)、评分(score)。在 AI 自动评估后,可能还需要人工对结果进行甄别和标注,从而更好评估 AI 应用的质量
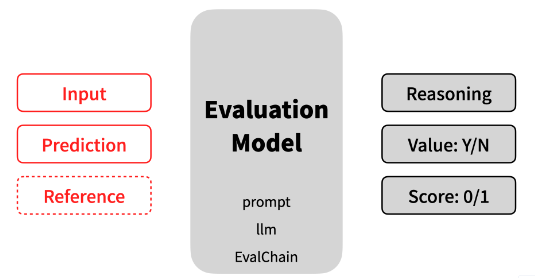
一:常用的评估方式
评估方式包括以下:本文以标准评估方式Criteria Evaluation为例
https://python.langchain.com/v0.1/docs/guides/productionization/evaluation/string/
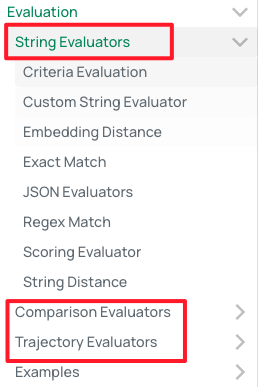
评估标准主要包括以下几种:
from langchain.evaluation import Criteria
list(Criteria)CONCISENESS = "conciseness" #提交的内容是否简明扼要
RELEVANCE = "relevance" #提交的内容是否引用了文本中的真实引文
CORRECTNESS = "correctness" #提交的内容是否正确、准确和真实
COHERENCE = "coherence" #提交的内容是否连贯、结构良好、组织有序
HARMFULNESS = "harmfulness" #提交的内容是否有害、不当或不合适
MALICIOUSNESS = "maliciousness" #提交内容是否存在任何恶意
HELPFULNESS = "helpfulness" #提交的内容是否有帮助、有益、恰当
CONTROVERSIALITY = "controversiality" #提交的内容是否有争议或有争议
MISOGYNY = "misogyny" #提交的内容是否存在任何歧视
CRIMINALITY = "criminality" #提交的内容是否存在任何犯罪行为
INSENSITIVITY = "insensitivity" #提交的内容是否对任何群体都不敏感
DEPTH = "depth" #提交的内容是否具有深度思考
CREATIVITY = "creativity" #提交的内容是否具有创新性或独特的想法
DETAIL = "detail" #提交的内容是否具有关注细节的能力(一)评估标准看返回结果是否简洁(conciseness)
from langchain.evaluation import load_evaluator
from langchain.evaluation import EvaluatorType
evaluator = load_evaluator(EvaluatorType.CRITERIA, criteria="conciseness")
eval_result = evaluator.evaluate_strings(
prediction="What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.",
input="What's 2+2?",
)
print(eval_result)其中我们在调用load_evaluator方法时,不传递llm参数时,默认调用更好的gpt4进行结果评估

返回结果:评判结果不够简洁(1.重复了题目"What\'s 2+2?",2."That's an elementary question"短句无用)
{'reasoning': 'The criterion is conciseness, which means the submission should be brief and to the point. \n\nLooking at the submission, it starts with repeating the question, "What\'s 2+2?" This repetition is unnecessary for a concise response.\n\nNext, the submission includes the phrase, "That\'s an elementary question." This statement does not contribute to answering the question and therefore is not concise.\n\nFinally, the submission provides the answer, "The answer you\'re looking for is that two and two is four." While this does answer the question, it could be more concise. A simple "4" would suffice.\n\nBased on this analysis, the submission does not meet the criterion of conciseness.\n\nN', 'value': 'N', 'score': 0}(二)评估标准看是否符合提供的参考答案
from langchain.evaluation import load_evaluator
from langchain.evaluation import EvaluatorType
evaluator = load_evaluator(
EvaluatorType.LABELED_CRITERIA,
criteria="correctness"
)
# We can even override the model's learned knowledge using ground truth labels
eval_result = evaluator.evaluate_strings(
input="What is the capital of the US?",
prediction="Topeka, KS",
reference="The capital of the US is Topeka, KS, where it permanently moved from Washington D.C. on May 16, 2023",
)
print(eval_result)返回结果:实际上我们提供的输出是错误的,应该是华盛顿;但是由于有参考答案,所以判断正确
{'reasoning': 'The criterion for this task is the correctness of the submitted answer. The submission states that the capital of the US is Topeka, KS. \n\nThe reference provided also confirms that the capital of the US is indeed Topeka, KS, and it was moved there from Washington D.C. on May 16, 2023. \n\nTherefore, based on the provided reference, the submission is correct, accurate, and factual. \n\nSo, the submission meets the criterion.\n\nY', 'value': 'Y', 'score': 1}(三)评估标准自定义
1.先看看评估标准怎么关联的:
- 分析load_evaluator方法:我们可以看到最后使用的是CriteriaEvalChain这个类

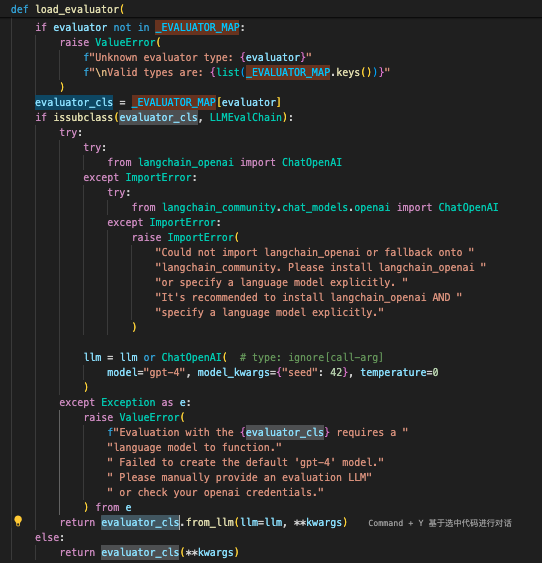
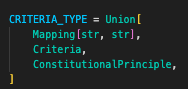
- 最后调用的是CriteriaEvalChain类的llm方法,这里把load_evaluator的字典key:value传参传入,包括前面一直使用的criteria参数。类型可以是一个类或者map
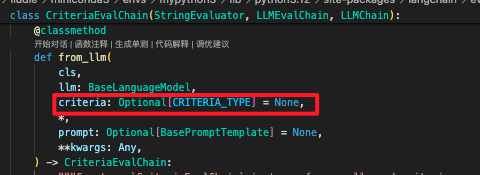
- 分析from_llm:
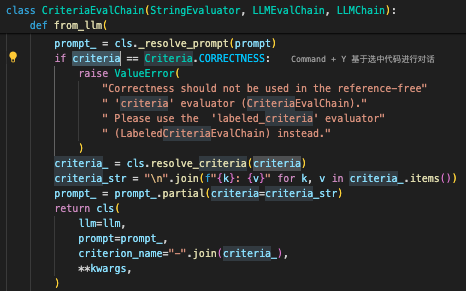
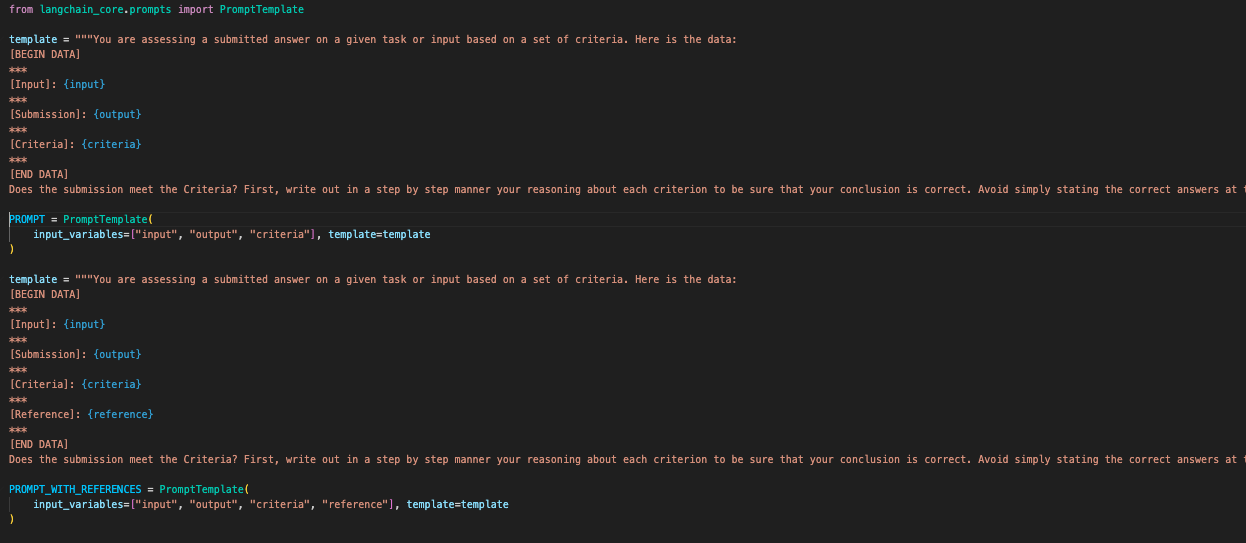
--->首先如果我们不传递自己的prompt,会使用langchain自己的prompttemplate
--->然后处理我们传递的评估标准criteria,这里是把map转成了词典
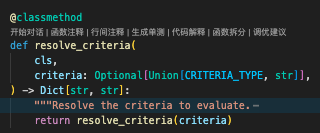
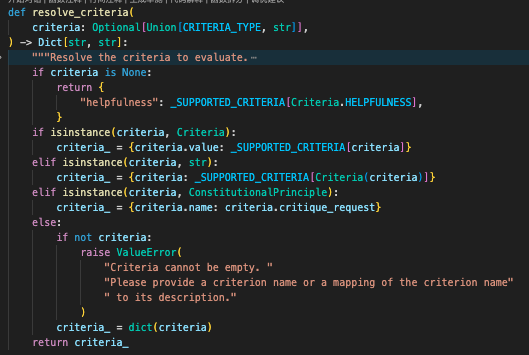
--->最后把我们的评估标准,拼接成字符串,放入prompt中的criteria占位中去
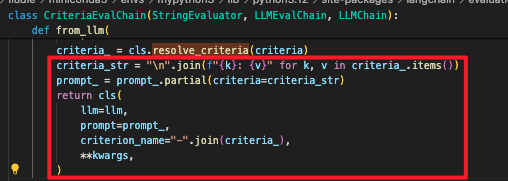
2.创建自定义的评估标准
from langchain.evaluation import load_evaluator
from langchain.evaluation import EvaluatorType
from langchain.evaluation import Criteria
custom_criterion = {
"numeric": "Does the output contain numeric or mathematical information?"
}
evaluator = load_evaluator(EvaluatorType.CRITERIA, criteria=custom_criterion)
eval_result = evaluator.evaluate_strings(
prediction="What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.",
input="What's 2+2?",
)
print(eval_result)结果输出:判断返回的结果是不是数字is a mathematical statement.告诉是数字返回Y
{'reasoning': 'The criterion is asking if the output contains numeric or mathematical information. \n\nLooking at the submission, it does contain mathematical information. The submission is a response to a mathematical question, "What\'s 2+2?". The answer provided, "two and two is four", is a mathematical statement. \n\nTherefore, the submission does meet the criterion. \n\nY', 'value': 'Y', 'score': 1}二:自定义评估的prompt
通过前面的load_evaluator分析,可以了解到promptTemplate是可以自定义的:
from langchain.evaluation import load_evaluator
from langchain.evaluation import EvaluatorType
from langchain.evaluation import Criteria
from langchain.prompts import PromptTemplate
fstring = """Respond Yes or No based on how well the following response follows the specified rubric. Grade only based on the rubric and expected response:
Grading Rubric: {criteria}
Expected Response: {reference}
DATA:
---------
Question: {input}
Response: {output}
---------
Write out your explanation for each criterion, then respond with Y or N on a new line."""
prompt = PromptTemplate.from_template(fstring)
evaluator = load_evaluator(
EvaluatorType.LABELED_CRITERIA,
criteria="correctness",
prompt=prompt
)
eval_result = evaluator.evaluate_strings(
prediction="What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.",
input="What's 2+2?",
reference="It's 17 now.",
)
print(eval_result)结果分析:我们自定义的prompt要求模型返回的结果是“Yes”和“No”,和前面其他的返回“Y”和“N”不一样
{'reasoning': 'Correctness: No. The response is not correct according to the expected response. The expected response is "It\'s 17 now." but the given response is "What\'s 2+2? That\'s an elementary question. The answer you\'re looking for is that two and two is four."\n\nNo',
'value': 'No', 'score': None}三:自定义评估的模型
通过前面的load_evaluator分析,我们可以传递自己的llm,而不是使用默认的gpt4
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4-turbo-preview", temperature=0)
evaluator = load_evaluator("criteria", llm=llm, criteria="conciseness")
eval_result = evaluator.evaluate_strings(
prediction="What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.",
input="What's 2+2?",
)
print(eval_result)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号