向量数据库
一:向量数据库原理
https://blog.csdn.net/zevjay/article/details/138022283
Faiss的核心在于其高效的索引结构和搜索算法
(一)索引结构
常见的索引结构包括:
Flat Index:最简单的索引结构,将所有向量存储在一起,适用于小规模数据集。搜索时需遍历整个数据集,计算查询向量与每个数据向量的相似度。
IVF (Inverted File Index) :基于聚类的思想,先将数据集划分为多个子集(聚类中心),再对每个子集内部使用其他索引结构(如Flat或Hierarchical Clustering)。搜索时先找到最相关的几个子集(近似搜索),再在子集中精确搜索。
HNSW (Hierarchical Navigable Small World) :基于图的近似最近邻搜索算法(K-近邻算法),构建多层图结构,每一层节点代表一个向量,节点间边代表相似度。搜索时通过层次跳跃快速缩小搜索范围,最终找到近似最近邻。https://www.cnblogs.com/ssyfj/p/13053055.html
https://nicksxs.me/2024/06/23/%E4%BB%8B%E7%BB%8D%E4%B8%80%E4%B8%8BHNSW%E7%AE%97%E6%B3%95/
PCA (Principal Component Analysis) / Product Quantization:通过降维或量化技术压缩向量,减少存储空间和计算复杂度。https://zhuanlan.zhihu.com/p/534004381
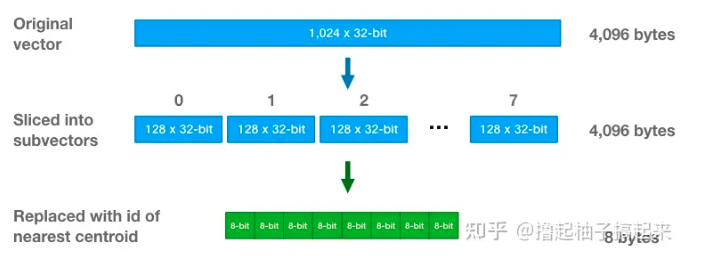
意思是说将原始向量分解成若干个低维向量的笛卡尔积,并对分解得到的低维向量空间做量化,这样原始向量便能通过低维向量的量化code表示。将N条D维向量分解,每个D维向量X分解成M组D/M维子向量Y,然后对每组子向量Y进行K-means聚类,这样每组子向量都可以有K个映射结果(每个结果可以用log2K位表示),最后原始向量就可以被压缩从D*32--->M*log2K
其中参数K=256和m=8被认为最佳参数,主要参数是m,如下
pq_m:子向量个数,影响压缩率与精度。一般设置为8或16,具体根据数据特性调整。以文章例子来看:
- 5w条1024维的数据,每条可以转为8*128(8组128维的子向量)---(每一维占一个int 32位)
- 然后对每一组子向量(5w条128维)进行k-means聚类,这里设置聚成256类(256可以用8位表示)
- 所以区别每个类只需要8bit,那么原始的一条数据1024*32位变成了8*8位
(二)搜索算法
Exact Search:精确搜索,计算查询向量与所有数据向量的相似度,返回最相似的结果。适用于数据量较小或对精度要求极高的场景。
Approximate Search:近似搜索,牺牲一定精度换取搜索速度,常用于大规模数据集。如IVF、HNSW等索引结构均支持近似搜索。
(三)索引类型选择和参数调优
根据数据集大小、查询速度要求、内存限制等因素,选择合适的索引类型至关重要。
小规模数据集(< 10^5向量):使用IndexFlatL2或IndexFlatIP进行精确搜索即可,简单且高效。
Flat 的意思是,入库的向量不会经过任何形式的预处理(例如归一化)或量化,它们以原始的、完整的形式存储。
并且在进行相似度检索时,会完整地扫库一次(俗称暴力搜索),所以它的计算结果一定是全局最优的
IndexFlatL2 是根据L2距离来衡量向量之间的相似度,L2距离越短,说明两个向量之间越相似
IndexFlatIP 则是根据内积(Inner Product)来衡量向量之间的相似度,内积越大,说明两个向量之间越相似中等规模数据集(10^5 - 10^8向量):考虑使用IndexIVFFlat或IndexIVFPQ。前者基于聚类的近似搜索,后者结合了Product Quantization进一步压缩向量。根据内存和精度需求调整nlist(聚类中心数)和nprobe(搜索时访问的聚类中心数)参数。
nlist:增大nlist可提高搜索速度,但可能导致精度下降。一般通过交叉验证确定最优值。
nprobe:增大nprobe可提高精度,但会增加搜索时间。在实际应用中,可设置为可配置项,根据实时性能需求动态调整。大规模数据集(> 10^8向量):推荐使用IndexHNSW或IndexIVFPQ。前者基于图的近似搜索,后者结合了量化压缩。适当调整M(HNSW层数,影响搜索)和efConstruction(构建图时扩展的邻居数量,影响构建)参数。
M:控制图的层数,影响搜索速度与精度。一般情况下,较大的M可提高精度,但会增加内存占用。可通过实验确定最优值。
efConstruction:构建图时扩展的邻居数量,影响索引构建时间和精度。通常设置为较大值(如200)以构建高质量图。二:使用案例
https://soulteary.com/2022/09/03/vector-database-guide-talk-about-the-similarity-retrieval-technology-from-metaverse-big-company-faiss.html
https://soulteary.com/2022/09/10/the-dimensionality-reduction-of-traditional-text-retrieval-methods-using-faiss-to-achieve-vector-semantic-retrieval.html
作者:山上有风景
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix