Netlink 内核实现分析(一):原理解析
转载自:Netlink 内核实现分析(一):创建
一:Netlink基础概念
Netlink 是一种IPC(Inter Process Commumicate)机制,它是一种用于内核与用户空间通信的机制,同时它也以用于进程间通信(Netlink 更多用于内核通信,进程之间通信更多使用Unix域套接字)。
在一般情况下,用户态和内核态通信会使用传统的Ioctl、sysfs属性文件或者procfs属性文件,这3种通信方式都是同步通信方式,由用户态主动发起向内核态的通信,内核无法主动发起通信。
而Netlink是一种异步全双工的通信方式,它支持由内核态主动发起通信,内核为Netlink通信提供了一组特殊的API接口,用户态则基于socket API,内核发送的数据会保存在接收进程socket 的接收缓存中,由接收进程处理。
(一)Netlink的优点:
1、双向全双工异步传输,支持由内核主动发起传输通信,而不需要用户空间出发(例如使用ioctl这类的单工方式)。如此用户空间在等待内核某种触发条件满足时就无需不断轮询,而异步接收内核消息即可。
2、支持组播传输,即内核态可以将消息发送给多个接收进程,这样就不用每个进程单独来查询了。
(二)Netlink框架
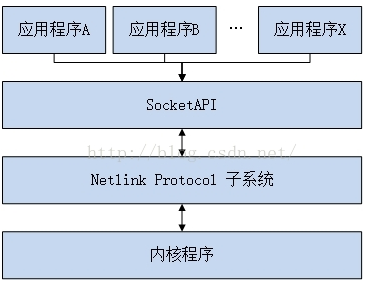
(三)Netlink协议类型
目前在Linux 4.1.x 的主线内核版本中,已经有许多内核模块使用netlink 机制,其中驱动模型中使用的uevent 就是基于netlink 实现。目前 netlink 协议族支持32种协议类型,它们定义在 include/uapi/linux/netlink.h 中:

#define NETLINK_ROUTE 0 /* 用于设置和查询路由表等网络核心模块*/ #define NETLINK_UNUSED 1 /* Unused number */ #define NETLINK_USERSOCK 2 /* Reserved for user mode socket protocols,保留用于用户态进程间通信 */ #define NETLINK_FIREWALL 3 /* Unused number, formerly ip_queue */ #define NETLINK_SOCK_DIAG 4 /* socket monitoring */ #define NETLINK_NFLOG 5 /* netfilter/iptables ULOG */ #define NETLINK_XFRM 6 /* ipsec */ #define NETLINK_SELINUX 7 /* SELinux event notifications */ #define NETLINK_ISCSI 8 /* Open-iSCSI */ #define NETLINK_AUDIT 9 /* auditing */ #define NETLINK_FIB_LOOKUP 10 #define NETLINK_CONNECTOR 11 #define NETLINK_NETFILTER 12 /* netfilter subsystem */ #define NETLINK_IP6_FW 13 #define NETLINK_DNRTMSG 14 /* DECnet routing messages */ #define NETLINK_KOBJECT_UEVENT 15 /* Kernel messages to userspace 用于uevent消息通信*/ #define NETLINK_GENERIC 16 //generic netlink /* leave room for NETLINK_DM (DM Events) */ #define NETLINK_SCSITRANSPORT 18 /* SCSI Transports */ #define NETLINK_ECRYPTFS 19 #define NETLINK_RDMA 20 #define NETLINK_CRYPTO 21 /* Crypto layer */ #define NETLINK_INET_DIAG NETLINK_SOCK_DIAG #define MAX_LINKS 32
现在4.1.x 的内核版本中已经定义了22种协议类型,其中NETLINK_ROUTE是用于设置和查询路由表等网络核心模块的,NETLINK_KOBJECT_UEVENT是用于uevent消息通信的......
对于在实际的项目中,可能会有一些定制化的需求,以上这几种专用的协议类型无法满足,这时可以在不超过最大32种类型的基础之上自行添加。
但是一般情况下这样做有些不妥,于是内核开发者就设计了一种通用netlink 协议类型(Generic Netlink)NETLINK_GENERIC,它就是一个Netlink复用器,便于用户自行扩展子协议类型(后面我会使用该Generic Netlink 编写一个示例程序用于演示内核和用户空间的通信)。
二:内核下Netlink的具体创建和通信流程
下面以linux 4.1.12版本的内核源码为例来分析。
(一) Netlink子系统初始化
内核Netlink的初始化在系统启动阶段完成,初始化代码在af_netlink.c的netlink_proto_init()函数中,整个初始化流程如下:
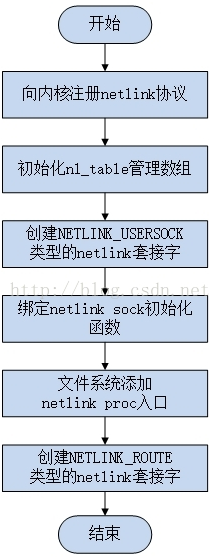
详细代码如下:位于:linux-4.x.x\net\netlink\Af_netlink.c
static int __init netlink_proto_init(void) { int i; int err = proto_register(&netlink_proto, 0);//向内核注册netlink协议 if (err != 0) goto out; BUILD_BUG_ON(sizeof(struct netlink_skb_parms) > FIELD_SIZEOF(struct sk_buff, cb)); nl_table = kcalloc(MAX_LINKS, sizeof(*nl_table), GFP_KERNEL);//创建并初始化了nl_table表数组 --------- 详解1 if (!nl_table) goto panic; for (i = 0; i < MAX_LINKS; i++) { if (rhashtable_init(&nl_table[i].hash, &netlink_rhashtable_params) < 0) { while (--i > 0) rhashtable_destroy(&nl_table[i].hash); kfree(nl_table); goto panic; } } INIT_LIST_HEAD(&netlink_tap_all); netlink_add_usersock_entry();//初始化应用层使用的NETLINK_USERSOCK协议类型的netlink(用于应用层进程间通信)---单独初始化,维持用户态进程间通信 sock_register(&netlink_family_ops); //-------------- 详解2 register_pernet_subsys(&netlink_net_ops); //------------------ 详解3 /* The netlink device handler may be needed early. */ rtnetlink_init(); //----------- 详解4 out: return err; panic: panic("netlink_init: Cannot allocate nl_table\n"); } core_initcall(netlink_proto_init);//内核初始化时调用
1.详解1 --- nl_table = kcalloc(MAX_LINKS, sizeof(*nl_table), GFP_KERNEL);
本初始化函数首先向内核注册netlink协议;然后创建并初始化了nl_table表数组,这个表是整个netlink实现的最关键的一步,每种协议类型占数组中的一项,后续内核中创建的不同种协议类型的netlink都将保存在这个表中,由该表统一维护,来简单看一些它的定义,有一个大概的印象:
struct netlink_table { struct rhashtable hash; //hash(哈希表)用来索引同种协议类型的不同netlink套接字实例 struct hlist_head mc_list; //为多播使用的sock散列表 struct listeners __rcu *listeners; //监听者掩码 unsigned int flags; unsigned int groups; //协议支持的最大多播组数量 struct mutex *cb_mutex; struct module *module; /*定义了一些函数指针,它们会在内核首次创建netlink时被赋值,后续应用层创建和绑定socket时调用到*/ int (*bind)(struct net *net, int group); void (*unbind)(struct net *net, int group); bool (*compare)(struct net *net, struct sock *sock); int registered; };
2.详解2 --- sock_register(&netlink_family_ops);
调用sock_register向内核注册协议处理函数,即将netlink的socket创建处理函数注册到内核中,如此以后应用层创建netlink类型的socket时将会调用该协议处理函数,其中netlink_family_ops函数的定义如下:
static const struct net_proto_family netlink_family_ops = { .family = PF_NETLINK, .create = netlink_create, .owner = THIS_MODULE, /* for consistency 8) */ };
这样以后应用层创建PF_NETLINK(AF_NETLINK)类型的socket()系统调用时将由netlink_create()函数负责处理。
3.详解3 --- register_pernet_subsys(&netlink_net_ops); (三)中还会使用
调用register_pernet_subsys向内核所有的网络命名空间注册”子系统“的初始化和去初始化函数,这里的"子系统”并非指的是netlink子系统,而是一种通用的处理方式,在网络命名空间创建和注销时会调用这里注册的初始化和去初始化函数,当然对于已经存在的网络命名空间,在注册的过程中也会调用其初始化函数。netlink_net_ops定义如下:
static struct pernet_operations __net_initdata netlink_net_ops = { .init = netlink_net_init, .exit = netlink_net_exit, };
其中netlink_net_init()会在文件系统中位每个网络命名空间创建一个proc入口,而netlink_net_exit()不用时销毁。
4.详解4 --- rtnetlink_init(); 在(三)中详细解释
调用rtnetlink_init()创建NETLINK_ROUTE协议类型的netlink,该种类型的netlink才是当初内核设计netlink的初衷,它用来传递网络路由子系统、邻居子系统、接口设置、防火墙等消息。至此整个netlink子系统初始化完成。
(二)内核Netlink套接字
下面首先来看一下内核netlink使用到的几个关键数据结构:
1.内核netlink配置结构:struct netlink_kernel_cfg
该结构包含了内核netlink的可选参数:
/* optional Netlink kernel configuration parameters */ struct netlink_kernel_cfg { unsigned int groups; unsigned int flags;
void (*input)(struct sk_buff *skb); struct mutex *cb_mutex;
int (*bind)(struct net *net, int group); void (*unbind)(struct net *net, int group); bool (*compare)(struct net *net, struct sock *sk); };
其中groups用于指定最大的多播组;
flags成员可以为NL_CFG_F_NONROOT_RECV或NL_CFG_F_NONROOT_SEND,这两个符号前者用来限定非超级用户是否可以绑定到多播组,后者用来限定非超级用户是否可以发送组播;
input指针用于指定回调函数,该回调函数用于接收和处理来自用户空间的消息(若无需接收来自用户空间的消息可不指定),
最后的三个函数指针实现sock的绑定和解绑定等操作,会添加到nl_table对应的项中去。
2.netlink属性头:struct nlattr
struct nlattr { __u16 nla_len; __u16 nla_type; };
netlink的消息头后面跟着的是消息的有效载荷部分,它采用的是格式为“类型——长度——值”,简写TLV。
其中类型和长度使用属性头nlattr来表示。其中nla_len表示属性长度;nla_type表示属性类型,它可以取值为以下几种类型(定义在include\net\netlink.h中):
enum { NLA_UNSPEC, NLA_U8, NLA_U16, NLA_U32, NLA_U64, NLA_STRING, NLA_FLAG, NLA_MSECS, NLA_NESTED, NLA_NESTED_COMPAT, NLA_NUL_STRING, NLA_BINARY, NLA_S8, NLA_S16, NLA_S32, NLA_S64, __NLA_TYPE_MAX, };
其中比较常用的NLA_UNSPEC表示类型和长度未知、NLA_U32表示无符号32位整形数、NLA_STRING表示变长字符串、NLA_NESTED表示嵌套属性(即包含一层 新的属性)。
3.netlink有效性策略:struct nla_policy
struct nla_policy { u16 type; u16 len; };
netlink协议可以根据消息属性定义其特定的消息有效性策略,即对于某一种属性,该属性的期望类型是什么,内核将在收到消息以后对该消息的属性进行有效性判断( 如果不设定len值,就不会执行有效性检查),只有判断一致的消息属性才算是合法的,否则只会默默的丢弃。
这种有效性属性使用nla_policy来描述,一般定义为一个有效性对象数组(当前这种netlink协议中的每一种attr属性(指定不是属性类型,而是用户定义的属性)有一个对应的数组项),这里type值同struct nlattr中的nla_type,len字段表示本属性的有效载荷长度。
4.netlink套接字结构:netlink_sock
struct netlink_sock { /* struct sock has to be the first member of netlink_sock */ struct sock sk; u32 portid; u32 dst_portid; u32 dst_group; u32 flags; u32 subscriptions; u32 ngroups; unsigned long *groups; unsigned long state; size_t max_recvmsg_len; wait_queue_head_t wait; bool bound; bool cb_running; struct netlink_callback cb; struct mutex *cb_mutex; struct mutex cb_def_mutex; void (*netlink_rcv)(struct sk_buff *skb); int (*netlink_bind)(struct net *net, int group); void (*netlink_unbind)(struct net *net, int group); struct module *module; #ifdef CONFIG_NETLINK_MMAP struct mutex pg_vec_lock; struct netlink_ring rx_ring; struct netlink_ring tx_ring; atomic_t mapped; #endif /* CONFIG_NETLINK_MMAP */ struct rhash_head node; struct rcu_head rcu; };
本结构用于描述一个netlink套接字,其中portid表示本套接字自己绑定的id号,对于内核来说它就是0,dst_portid表示目的id号,ngroups表示协议支持多播组数量,groups保存组位掩码,netlink_rcv保存接收到用户态数据后的处理函数,netlink_bind和netlink_unbind用于协议子协议自身特有的绑定和解绑定处理函数。
(三)创建内核Netlink套接字
内核中各种协议类型的netlink分别在不同的模块中进行创建和初始化,我以文中的NETLINK_ROUTE为例来分析一下内核中netlink套接字的创建流程。首先回到子系统初始化函数netlink_proto_init()的最后,来查看rtnetlink_init()函数的执行流程:
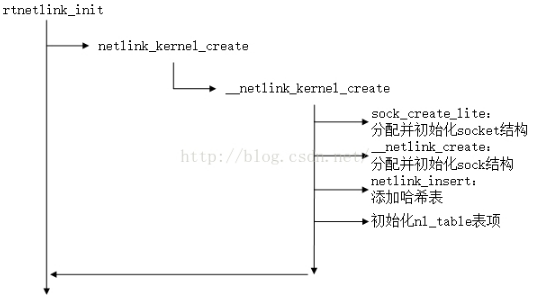
void __init rtnetlink_init(void) { if (register_pernet_subsys(&rtnetlink_net_ops)) //将rtnetlink的init函数和exit函数注册到内核的每个网络命名空间中 ------- 详解5 panic("rtnetlink_init: cannot initialize rtnetlink\n"); register_netdevice_notifier(&rtnetlink_dev_notifier); rtnl_register(PF_UNSPEC, RTM_GETLINK, rtnl_getlink, rtnl_dump_ifinfo, rtnl_calcit); rtnl_register(PF_UNSPEC, RTM_SETLINK, rtnl_setlink, NULL, NULL);
......
rtnl_register(PF_UNSPEC, RTM_GETSTATS, rtnl_stats_get, rtnl_stats_dump, NULL); }
1.详解5 --- register_pernet_subsys(&rtnetlink_net_ops)
static struct pernet_operations rtnetlink_net_ops = { .init = rtnetlink_net_init, //NETLINK_ROUTE入口函数 ------- 详解6 .exit = rtnetlink_net_exit, };
register_pernet_subsys在前文详解3中已经见过了,这里将rtnetlink的init函数(rtnetlink_net_init)和exit函数(rtnetlink_net_exit)注册到内核的每个网络命名空间中,对于已经存在的网络命名空间会调用其中的init函数,这里就是rtnetlink_net_init()函数了。
2.详解6 --- rtnetlink_net_init
static int __net_init rtnetlink_net_init(struct net *net) { struct sock *sk; struct netlink_kernel_cfg cfg = { .groups = RTNLGRP_MAX, .input = rtnetlink_rcv, //指定消息接收处理函数为rtnetlink_rcv .cb_mutex = &rtnl_mutex, .flags = NL_CFG_F_NONROOT_RECV, //这表明非超级用户可以绑定到多播组,可以接收消息 }; sk = netlink_kernel_create(net, NETLINK_ROUTE, &cfg); //创建NETLINK_ROUTE类型套接字------详解7 if (!sk) return -ENOMEM; net->rtnl = sk; return 0; }
首先这里定义了一个 netlink_kernel_cfg结构体实例,设置groups为RTNLGRP_MAX后指定消息接收处理函数为rtnetlink_rcv,
并设置flag为NL_CFG_F_NONROOT_RECV,这表明非超级用户可以绑定到多播组,但是没有设置NL_CFG_F_NONROOT_SEND,这表明非超级用户将不能发送组播消息。
随后init函数调用netlink_kernel_create()向当前的网络命名空间创建NETLINK_ROUTE类型的套接字,并指定定义的那个配置结构cfg。
3.详解7 --- netlink_kernel_create(net, NETLINK_ROUTE, &cfg);
进入netlink_kernel_create()函数内部:
netlink_kernel_create(struct net *net, int unit, struct netlink_kernel_cfg *cfg) { return __netlink_kernel_create(net, unit, THIS_MODULE, cfg); }
它其实就是__netlink_kernel_create()的一个封装而已, __netlink_kernel_create函数比较长:
struct sock * __netlink_kernel_create(struct net *net, int unit, struct module *module, struct netlink_kernel_cfg *cfg) { struct socket *sock; struct sock *sk; struct netlink_sock *nlk;struct listeners *listeners = NULL; struct mutex *cb_mutex = cfg ? cfg->cb_mutex : NULL; unsigned int groups; BUG_ON(!nl_table); if (unit < 0 || unit >= MAX_LINKS)//简单的参数判断 return NULL; if (sock_create_lite(PF_NETLINK, SOCK_DGRAM, unit, &sock))//创建了一个以PF_NETLINK为地址族的SOCK_DGRAM类型的 socket 套接字,其协议类型就是作为参数传入的NETLINK_ROUTE return NULL; if (__netlink_create(net, sock, cb_mutex, unit, 1) < 0)//向内核初始化netlink套接字 --------- 详解8 goto out_sock_release_nosk; sk = sock->sk; if (!cfg || cfg->groups < 32)---------------- 详解9 groups = 32; else groups = cfg->groups; listeners = kzalloc(sizeof(*listeners) + NLGRPSZ(groups), GFP_KERNEL);//分配listeners内存空间,这里边保存了监听者(监听套接字)的信息 if (!listeners) goto out_sock_release; sk->sk_data_ready = netlink_data_ready; if (cfg && cfg->input) nlk_sk(sk)->netlink_rcv = cfg->input;------- 详解10 if (netlink_insert(sk, 0)) ------------ 详解11 goto out_sock_release; nlk = nlk_sk(sk); nlk->flags |= NETLINK_F_KERNEL_SOCKET;//设置标识NETLINK_KERNEL_SOCKET表明这个netlink套接字是一个内核套接字 netlink_table_grab(); -------- 详解12 if (!nl_table[unit].registered) { nl_table[unit].groups = groups; rcu_assign_pointer(nl_table[unit].listeners, listeners); nl_table[unit].cb_mutex = cb_mutex; nl_table[unit].module = module; if (cfg) { nl_table[unit].bind = cfg->bind; nl_table[unit].unbind = cfg->unbind; nl_table[unit].flags = cfg->flags; if (cfg->compare) nl_table[unit].compare = cfg->compare; } nl_table[unit].registered = 1; } else { kfree(listeners); nl_table[unit].registered++; } netlink_table_ungrab(); return sk; ------- 详解13 out_sock_release: kfree(listeners); netlink_kernel_release(sk); return NULL; out_sock_release_nosk: sock_release(sock); return NULL; }
4.详解8 --- __netlink_create(net, sock, cb_mutex, unit, 1)
最核心的 __netlink_create()函数向内核初始化netlink套接字 (其实在下文中将会看到用户态创建netlink套接字也是间接调用到该函数)
static int __netlink_create(struct net *net, struct socket *sock, struct mutex *cb_mutex, int protocol, int kern) { struct sock *sk; struct netlink_sock *nlk; sock->ops = &netlink_ops;//将sock的操作函数集指针设置为netlink_ops sk = sk_alloc(net, PF_NETLINK, GFP_KERNEL, &netlink_proto, kern);//分配sock结构并进行初始化 if (!sk) return -ENOMEM; sock_init_data(sock, sk);//初始化发送接收消息队列 nlk = nlk_sk(sk);//初始化数据缓存 if (cb_mutex) { nlk->cb_mutex = cb_mutex; } else { nlk->cb_mutex = &nlk->cb_def_mutex; mutex_init(nlk->cb_mutex);//初始化互斥锁 lockdep_set_class_and_name(nlk->cb_mutex, nlk_cb_mutex_keys + protocol, nlk_cb_mutex_key_strings[protocol]); } init_waitqueue_head(&nlk->wait);//初始化等待队列 sk->sk_destruct = netlink_sock_destruct;//设置sk_destruct回调函数 sk->sk_protocol = protocol;//设置协议类型 return 0; }
其中netlink_ops静态变量赋值如下:
static const struct proto_ops netlink_ops = { .family = PF_NETLINK, .owner = THIS_MODULE, .release = netlink_release, .bind = netlink_bind, .connect = netlink_connect, .socketpair = sock_no_socketpair, .accept = sock_no_accept, .getname = netlink_getname, .poll = datagram_poll, .ioctl = netlink_ioctl, .listen = sock_no_listen, .shutdown = sock_no_shutdown, .setsockopt = netlink_setsockopt, .getsockopt = netlink_getsockopt, .sendmsg = netlink_sendmsg, .recvmsg = netlink_recvmsg, .mmap = sock_no_mmap, .sendpage = sock_no_sendpage, };
5.详解9 --- !cfg || cfg->groups < 32
if (!cfg || cfg->groups < 32) groups = 32; else groups = cfg->groups;
校验groups,默认最小支持32个组播地址(因为后文会看到用户层在绑定地址时最多绑定32个组播地址),但内核也有可能支持大于32个组播地址的情况(Genetlink就属于这种情况)
6.详解10 --- nlk_sk(sk)->netlink_rcv = cfg->input;
初始化函数指针,这里将前文详解6中定义的rtnetlink_rcv注册到了nlk_sk(sk)->netlink_rcv中,这样就设置完了内核态的消息处理函数
7.详解11 --- netlink_insert(sk, 0)
调用netlink_insert()函数将本次创建的这个套接字添加到nl_table中去(其核心是调用__netlink_insert()),注册的套接字是通过nl_table中的哈希表来管理的。
8.详解12 --- netlink_table_grab
接下来继续初始化nl_table表中对应传入 NETLINK_ROUTE协议类型的数组项,首先会判断是否已经先有同样协议类型的已经注册过了,如果有就不再初始化该表项了,直接释放刚才申请的listeners内存空间然后递增注册个数并返回。这里假定是首次注册NETLINK_ROUTE协议类型的套接字,这里依次初始化了nl_table表项中的groups、listeners、cb_mutex、module、bind、unbind、flags和compare字段。
netlink_table_grab(); if (!nl_table[unit].registered) { nl_table[unit].groups = groups; rcu_assign_pointer(nl_table[unit].listeners, listeners); nl_table[unit].cb_mutex = cb_mutex; nl_table[unit].module = module; if (cfg) { nl_table[unit].bind = cfg->bind; nl_table[unit].unbind = cfg->unbind; nl_table[unit].flags = cfg->flags; if (cfg->compare) nl_table[unit].compare = cfg->compare; } nl_table[unit].registered = 1; } else { kfree(listeners); nl_table[unit].registered++; } netlink_table_ungrab();
通过前文中cfg的实例分析,这里的初始化的值分别如下:
nl_table[NETLINK_ROUTE].groups = RTNLGRP_MAX; nl_table[NETLINK_ROUTE].cb_mutex = &rtnl_mutex; nl_table[ NETLINK_ROUTE ].module = THIS_MODULE; nl_table[NETLINK_ROUTE].bind = NULL; nl_table[NETLINK_ROUTE].unbind = NULL; nl_table[NETLINK_ROUTE].compare = NULL; nl_table[NETLINK_ROUTE].flags= NL_CFG_F_NONROOT_RECV;
这些值在后面的通信流程中就会使用到。
9.详解13 --- return sk = sock->sk;
在函数的最后返回成功创建的netlink套接字中的sock指针,它会在最先前的rtnetlink_net_init()函数中被保存到net->rtnl中去,注意只有NETLINK_ROUTE协议类型的套接字才会执行这个步骤,因为网络命名空间中专门为其预留了一个sock指针。
三:用户态下Netlink的具体创建和通信流程
应用层通过标准的sock API即可使用Netlink完成通信功能(如socket()、sendto()、recv()、sendmsg()和recvmsg()等),这些都是系统调用,内核中对应的定义为sys_xxx。用户层netlink套接字创建流程如下图所示:

首先来看一些基本的数据结构及创建流程:
(一)套接字地址数据结构sockaddr_nl
struct sockaddr_nl { __kernel_sa_family_t nl_family; /* AF_NETLINK */ unsigned short nl_pad; /* zero */ __u32 nl_pid; /* port ID */ __u32 nl_groups; /* multicast groups mask */ };
(1)nl_family始终为AF_NETLINK;
(2)nl_pad始终为0;
(3)nl_pid为netlink套接字的单播地址,在发送消息时用于表示目的套接字的地址,在用户空间绑定时可以指定为当前进程的PID号(对于内核来说这个值为0)或者干脆不设置(在绑定bind时由内核调用netlink_autobind()设置为当前进程的PID),但需要注意的是当用户同一个进程中需要创建多个netlink套接字时则必须保证这个值是唯一的(一般在多线程中可以使用”pthread_self() << 16 | getpid()“这样的方法进行设置);
(4)nl_groups表示组播组。在发送消息时用于表示目的多播组,在绑定地址时用于表示加入的多播组。这里nl_groups为一个32位无符号数,其中的每一位表示一个 多播组,一个netlink套接字可以加入多个多播组用以接收多个多播组的多播消息(最多支持32个)。
(二)创建Netlink套接字
应用层通过socket()系统调用创建Netlink套接字,socket系统调用的第一个参数可以是AF_NETLINK或PF_NETLINK(在Linux系统中它俩实际为同一种宏),第二个参数可以是SOCK_RAW或SOCK_DGRAM(原始套接字或无连接的数据报套接字),最后一个参数为netlink.h中定义的协议类型,用户可以按需求自行创建上述不同种类的套接字。
例如:调用socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE) 即创建了一个NETLINK_ROUTE类型的Netlink套接字。
下面跟进这个系统调用,查看内核是如何为用户层创建这个套接字然后又做了哪些初始化动作,net\socket.c:
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol) { int retval; struct socket *sock; int flags; /* Check the SOCK_* constants for consistency. */ BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC); BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK); BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK); BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK); flags = type & ~SOCK_TYPE_MASK; if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK)) return -EINVAL; type &= SOCK_TYPE_MASK; if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK)) flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK; retval = sock_create(family, type, protocol, &sock); if (retval < 0) goto out; retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK)); if (retval < 0) goto out_release; out: /* It may be already another descriptor 8) Not kernel problem. */ return retval; out_release: sock_release(sock); return retval; }
该函数首先做了一些参数检查之后就调用sock_create()函数创建套接字,在创建完成后向内核申请描述符并返回该描述符。
int sock_create(int family, int type, int protocol, struct socket **res) { return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0); }
进入sock_create()函数内部,它是__sock_create()的一层封装(内核中往往前面带两个下划线的函数才是做事实的,嘿嘿),这里要注意的是调用时又多了两个个参数,一是当前进程绑定的网络命名空间,而是最后一个kern参数,这里传入0表明是从应用层创建的套接字。__sock_create()函数比较长:
int __sock_create(struct net *net, int family, int type, int protocol, struct socket **res, int kern) { int err; struct socket *sock; const struct net_proto_family *pf; //参数判断 /* * Check protocol is in range */ if (family < 0 || family >= NPROTO) return -EAFNOSUPPORT; if (type < 0 || type >= SOCK_MAX) return -EINVAL; /* Compatibility. This uglymoron is moved from INET layer to here to avoid deadlock in module load. */ if (family == PF_INET && type == SOCK_PACKET) { static int warned; if (!warned) { warned = 1; pr_info("%s uses obsolete (PF_INET,SOCK_PACKET)\n", current->comm); } family = PF_PACKET; } err = security_socket_create(family, type, protocol, kern);---------- 详解1 if (err) return err; /* * Allocate the socket and allow the family to set things up. if * the protocol is 0, the family is instructed to select an appropriate * default. */ sock = sock_alloc();//分配socket实例,它会为其创建和初始化索引节点 if (!sock) { net_warn_ratelimited("socket: no more sockets\n"); return -ENFILE; /* Not exactly a match, but its the closest posix thing */ } sock->type = type;//将sock->type赋值为传入的SOCK_RAW #ifdef CONFIG_MODULES /* Attempt to load a protocol module if the find failed. * * 12/09/1996 Marcin: But! this makes REALLY only sense, if the user * requested real, full-featured networking support upon configuration. * Otherwise module support will break! */ if (rcu_access_pointer(net_families[family]) == NULL)-------- 详解2 request_module("net-pf-%d", family); #endif rcu_read_lock(); pf = rcu_dereference(net_families[family]); err = -EAFNOSUPPORT; if (!pf) goto out_release; /* * We will call the ->create function, that possibly is in a loadable * module, so we have to bump that loadable module refcnt first. */ if (!try_module_get(pf->owner))//获取模块的引用计数 goto out_release; /* Now protected by module ref count */ rcu_read_unlock(); err = pf->create(net, sock, protocol, kern);--------- 详解3 if (err < 0) goto out_module_put; /* * Now to bump the refcnt of the [loadable] module that owns this * socket at sock_release time we decrement its refcnt. */ if (!try_module_get(sock->ops->owner)) goto out_module_busy; /* * Now that we're done with the ->create function, the [loadable] * module can have its refcnt decremented */ module_put(pf->owner); err = security_socket_post_create(sock, family, type, protocol, kern); if (err) goto out_sock_release; *res = sock; return 0; }
1.详解1 --- security_socket_create(family, type, protocol, kern);
对创建socket执行安全性检查,security_socket_create这个函数在内核没有启用CONFIG_SECURITY_NETWORK配置时是一个空函数直接返回0,这里可先不考虑。
2.详解2 --- if (rcu_access_pointer(net_families[family]) == NULL)
在启用内核模块的情况下,这里会到内核net_families数组中查找该family(AF_NETLINK)是否已经注册,如果没有注册就会尝试加载网络子系统模块。其实在内核的netlink初始化函数中已经调用sock_register()完成注册了(见上文详解2)。接下来从net_families数组中获取已经注册的struct net_proto_family结构实例,这里就是上面描述过的netlink_family_ops。
3.详解3 --- err = pf->create(net, sock, protocol, kern);
调用netlink协议的creat()钩子函数执行进一步的创建和初始化操作(即netlink_family_ops中定义的netlink_create()了,见上文第一节详解2),完成之后就释放锁同时释放当前模块的引用计数并返回创建成功的socket。
进入netlink_create内部,查看创建和初始化流程,net\netlink\af_netlink.c
static int netlink_create(struct net *net, struct socket *sock, int protocol, int kern) { struct module *module = NULL; struct mutex *cb_mutex; struct netlink_sock *nlk; int (*bind)(struct net *net, int group); void (*unbind)(struct net *net, int group); int err = 0; sock->state = SS_UNCONNECTED; //将socket的状态标记为未连接 if (sock->type != SOCK_RAW && sock->type != SOCK_DGRAM)//判断套接字的类型是否是SOCK_RAW或SOCK_DGRAM类型的,若不是就不能继续创建 return -ESOCKTNOSUPPORT; if (protocol < 0 || protocol >= MAX_LINKS)-------- 详解4 return -EPROTONOSUPPORT; netlink_lock_table(); #ifdef CONFIG_MODULES if (!nl_table[protocol].registered) { netlink_unlock_table(); request_module("net-pf-%d-proto-%d", PF_NETLINK, protocol); netlink_lock_table(); } #endif if (nl_table[protocol].registered && try_module_get(nl_table[protocol].module)) module = nl_table[protocol].module; else err = -EPROTONOSUPPORT; cb_mutex = nl_table[protocol].cb_mutex; bind = nl_table[protocol].bind; unbind = nl_table[protocol].unbind; netlink_unlock_table(); if (err < 0) goto out; err = __netlink_create(net, sock, cb_mutex, protocol, kern);------- 详解5 if (err < 0) goto out_module; local_bh_disable(); sock_prot_inuse_add(net, &netlink_proto, 1);//添加协议的引用计数 local_bh_enable(); //赋值 nlk = nlk_sk(sock->sk); nlk->module = module; nlk->netlink_bind = bind; nlk->netlink_unbind = unbind; out: return err; out_module: module_put(module); goto out; }
4.详解4 --- if (protocol < 0 || protocol >= MAX_LINKS)
接着判断该协议类型的netlink是否已经注册了,由于前文中内核在初始化netlink子系统时已经初始化了NETLINK_ROUTE内核套接字并向nl_table注册,所以这里的几个赋值结果如下:
cb_mutex = nl_table[NETLINK_ROUTE].cb_mutex = &rtnl_mutex; module = nl_table[NETLINK_ROUTE].module = THIS_MODULE; bind = nl_table[NETLINK_ROUTE].bind = NULL; unbind = nl_table[NETLINK_ROUTE].unbind = NULL;
5.详解5 --- __netlink_create(net, sock, cb_mutex, protocol, kern)
调用__netlink_create()完成核心的创建初始化.上文详解8.
(三)绑定套接字系统调用
在创建完成套接字后需要调用bind()函数进行绑定,将该套接字绑定到一个特定的地址或者加入一个多播组中,以后内核或其他应用层套接字向该地址单播或向该多播组发送组播消息时即可通过recv()或recvmsg()函数接收消息了。绑定地址时需要使用到sockaddr_nl地址结构,如果使用使用单播则需要将地址本地地址信息填入nl_pid变量并设置nl_groups为0,如果使用多播则将nl_pid设置为0并填充nl_groups为多播地址,如下可将当前进程的PID号作为单播地址进行绑定:
struct sockaddr_nl local; fd = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE); memset(&local, 0, sizeof(local)); local.nl_family = AF_NETLINK; local.nl_pid = getpid(); bind(fd, (struct sockaddr *) &local, sizeof(local));
bind()系统调用分析整个绑定的过程如下
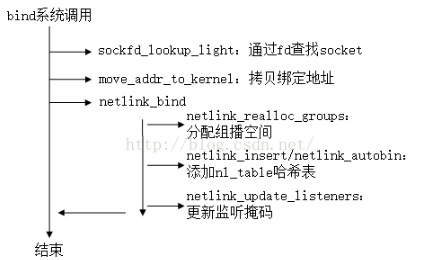
bind(fd, (struct sockaddr *) &local, sizeof(local));
其中bind()的第一个参数:为刚创建的Netlink套接字描述符;
第二个参数:需要绑定的套接字地址;
最后一个参数:地址的长度。这个绑定操作同创建TCP套接字类似,需要制定绑定的端口。
套接字的绑定是由系统调用bind()实现:
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; sock = sockfd_lookup_light(fd, &err, &fput_needed);//根据用户传入的fd文件描述符向内核查找对应的socket结构 if (sock) { err = move_addr_to_kernel(umyaddr, addrlen, &address);//将用户空间传入的地址struct sockaddr拷贝到内核中(会使用到copy_from_user()) if (err >= 0) { err = security_socket_bind(sock, (struct sockaddr *)&address, addrlen);//空函数,跳过安全检查 if (!err) err = sock->ops->bind(sock, (struct sockaddr *) &address, addrlen);//------ 详解6 } fput_light(sock->file, fput_needed); } return err; }
1.详解6 --- sock->ops->bind(sock, (struct sockaddr *) &address, addrlen)
然后调用sock->ops->bind()。在创建套接字时调用的__netlink_create()函数中已经将sock->ops赋值为netlink_ops了,如上文详解8所示,为netlink_bind函数。
static int netlink_bind(struct socket *sock, struct sockaddr *addr, int addr_len) { struct sock *sk = sock->sk; struct net *net = sock_net(sk); struct netlink_sock *nlk = nlk_sk(sk); struct sockaddr_nl *nladdr = (struct sockaddr_nl *)addr;//将用户传入的地址类型强制转换成了sockaddr_nl类型的地址结构 int err; long unsigned int groups = nladdr->nl_groups; bool bound; if (addr_len < sizeof(struct sockaddr_nl)) return -EINVAL; if (nladdr->nl_family != AF_NETLINK) return -EINVAL; /* Only superuser is allowed to listen multicasts */ if (groups) {//如果用户设定了需要绑定的多播地址 -------- 详解7 if (!netlink_allowed(sock, NL_CFG_F_NONROOT_RECV)) return -EPERM; err = netlink_realloc_groups(sk);//-------- 详解8 if (err) return err; } bound = nlk->bound; if (bound) {//如果已绑定 /* Ensure nlk->portid is up-to-date. */ smp_rmb(); if (nladdr->nl_pid != nlk->portid)//检查新需要绑定的id号是否等于已经绑定的id号 return -EINVAL;//若不相等则返回失败 } if (nlk->netlink_bind && groups) { ----- 详解9 int group; for (group = 0; group < nlk->ngroups; group++) { if (!test_bit(group, &groups)) continue; err = nlk->netlink_bind(net, group + 1); if (!err) continue; netlink_undo_bind(group, groups, sk); return err; } } /* No need for barriers here as we return to user-space without * using any of the bound attributes. */ if (!bound) {-------- 详解10 err = nladdr->nl_pid ? netlink_insert(sk, nladdr->nl_pid) : netlink_autobind(sock);------ 详解11 if (err) { netlink_undo_bind(nlk->ngroups, groups, sk); return err; } } if (!groups && (nlk->groups == NULL || !(u32)nlk->groups[0]))--------- 详解12 return 0; netlink_table_grab(); netlink_update_subscriptions(sk, nlk->subscriptions + hweight32(groups) - hweight32(nlk->groups[0])); nlk->groups[0] = (nlk->groups[0] & ~0xffffffffUL) | groups; netlink_update_listeners(sk); netlink_table_ungrab(); return 0; }
2.详解7 -- if (groups)
如果用户设定了需要绑定的多播地址,这里会去检擦nl_table中注册的套接字是否已经设置了NL_CFG_F_NONROOT_RECV标识,如果没有设置将拒绝用户绑定到组播组,显然在前文中已经看到了NETLINK_ROUTE类型的套接字是设置了这个标识的,所以这里会调用netlink_realloc_groups分配组播空间。
3.详解8 --- err = netlink_realloc_groups(sk)
这里会比较验证一下当前套接字中指定的组播地址上限是否大于NETLINK_ROUTE套接字支持的最大地址(这里为RTNLGRP_MAX),由于这个套接字是前面刚刚创建的,所以nlk->ngroups = 0。
然后为其分配内存空间,分配的空间大小为NLGRPSZ(groups)(这是一个取整对齐的宏),分配完成后将新分配的空间清零,
首地址保存在nlk->groups中,最后更新nlk->ngroups变量。
static int netlink_realloc_groups(struct sock *sk) { struct netlink_sock *nlk = nlk_sk(sk); unsigned int groups; unsigned long *new_groups; int err = 0; netlink_table_grab(); groups = nl_table[sk->sk_protocol].groups; if (!nl_table[sk->sk_protocol].registered) { err = -ENOENT; goto out_unlock; } if (nlk->ngroups >= groups) goto out_unlock; new_groups = krealloc(nlk->groups, NLGRPSZ(groups), GFP_ATOMIC); if (new_groups == NULL) { err = -ENOMEM; goto out_unlock; } memset((char *)new_groups + NLGRPSZ(nlk->ngroups), 0, NLGRPSZ(groups) - NLGRPSZ(nlk->ngroups)); nlk->groups = new_groups; nlk->ngroups = groups; out_unlock: netlink_table_ungrab(); return err; }
4.详解9 --- if (nlk->netlink_bind && groups)
如果netlink套接字子协议存在特有的bind函数且用户指定了需要绑定的组播地址,则调用之为其绑定到特定的组播组中去。现由于NETLINK_ROUTE套接字并不存在nlk->netlink_bind()函数实现,所以这里并不会调用。
5.详解10 --- if (!bound)
如果本套接字并没有被绑定过(目前就是这种情况),这里会根据用户是否指定了单播的绑定地址来调用不同的函数。首先假定用户空间指定了单播的绑定地址,这里会调用netlink_insert()函数将这个套接字插入到nl_table[NETLINK_ROUTE]数组项的哈希表中去,同时设置nlk_sk(sk)->bound = nlk_sk(sk)->portid = nladdr->nl_pid。我们再假定用户空间没有设置单播的绑定地址,这里会调用netlink_autobind()动态的绑定一个地址。
6.详解11 --- netlink_autobind(sock);
函数netlink_autobind()动态的绑定一个地址
static int netlink_autobind(struct socket *sock) { struct sock *sk = sock->sk; struct net *net = sock_net(sk); struct netlink_table *table = &nl_table[sk->sk_protocol]; s32 portid = task_tgid_vnr(current); int err; s32 rover = -4096; bool ok; retry: /*先尝试选用当前的进程ID作为端口地址,如果当前进程ID已经绑定过其他的相同protocol套接字则会选用一个负数作为ID号(查找直到存在可用的)*/ cond_resched(); rcu_read_lock(); ok = !__netlink_lookup(table, portid, net); rcu_read_unlock(); if (!ok) { /* Bind collision, search negative portid values. */ if (rover == -4096) /* rover will be in range [S32_MIN, -4097] */ rover = S32_MIN + prandom_u32_max(-4096 - S32_MIN); else if (rover >= -4096) rover = -4097; portid = rover--; goto retry; } err = netlink_insert(sk, portid); if (err == -EADDRINUSE) goto retry; /* If 2 threads race to autobind, that is fine. */ if (err == -EBUSY) err = 0; return err; }
7.详解12 --- if (!groups && (nlk->groups == NULL || !(u32)nlk->groups[0]))
如果没有指定组播地址且没有分配组播的内存,绑定工作到这里就已经结束了,可以直接返回了。现假定用户指定了需要绑定的组播地址,这里首先调用netlink_update_subscriptions绑定sk->sk_bind_node到nl_table[sk->sk_protocol].mc_list中,同时将加入的组播组数目记录到nlk->subscriptions中,并将组播地址保存到nlk->groups[0]中,最后更新netlink监听位掩码。至此绑定操作结束。
作者:山上有风景
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
2019-05-08 Arduino---ESP8266 WIFI模块