支持向量机SMO算法实现(注释详细)
一:SVM算法
(一)见西瓜书及笔记
(二)统计学习方法及笔记
(三)推文https://zhuanlan.zhihu.com/p/34924821
(四)推文
支持向量机原理(一) 线性支持向量机
支持向量机原理(二) 线性支持向量机的软间隔最大化模型
二:SMO算法
(一)见西瓜书及笔记
(二)统计学习方法及笔记
(三)见机器学习实战及笔记
(四)推文
支持向量机原理(四)SMO算法原理
三:代码实现(一)SMO中的辅助函数
(一)加载数据集
import numpy as np import matplotlib.pyplot as plt #一:SMO算法中的辅助函数 #加载数据集 def loadDataSet(filename): dataSet = np.loadtxt(filename) m,n = dataSet.shape data_X = dataSet[:,0:n-1] data_Y = dataSet[:,n-1] return data_X,data_Y
(二)随机选取一个J值,作为α_2的下标索引
#随机选取一个数J,为后面内循环选取α_2做辅助(如果α选取不满足条件,就选择这个方法随机选取) def selectJrand(i,m): #主要就是根据α_1的索引i,从所有数据集索引中随机选取一个作为α_2的索引 j = i while j==i: j = np.int(np.random.uniform(0,m)) #从0~m中随机选取一个数,是进行整数化的 print("random choose index for α_2:%d"%(j)) return j #由于这里返回随机数,所以后面结果 可能导致不同
(三)根据关于α_1与α_2的优化问题对应的约束问题分析,对α进行截取约束

def clipAlpha(aj,H,L): #根据我们的SVM算法中的约束条件的分析,我们对获取的aj,进行了截取操作 if aj > H: aj = H if aj < L: aj = L return aj
四:代码实现(二)SMO中的支持函数
(一)定义一个数据结构,用于保存所有的重要值
#首先我们定义一个数据结构(类),来保存所有的重要值 class optStruct: def __init__(self,data_X,data_Y,C,toler): #输入参数分别是数据集、类别标签、常数C用于软间隔、和容错率toler self.X = data_X self.label = data_Y self.C = C self.toler = toler #就是软间隔中的ε,调节最大间隔大小 self.m = data_X.shape[0] self.alphas = np.zeros(self.m) #存放每个样本点的α值 self.b = 0 #存放阈值 self.eCache = np.zeros((self.m,2)) #用于缓存误差,每个样本点对应一个Ei值,第一列为标识符,标志是否为有效值,第二列存放有效值
(二)计算每个样本点k的Ek值,就是计算误差值=预测值-标签值
#计算每个样本点k的Ek值,就是计算误差值=预测值-标签值 def calcEk(oS,k): # 根据西瓜书6.24,我们可以知道预测值如何使用α值进行求解 fxk = np.multiply(oS.alphas,oS.label).T@(oS.X@oS.X[k,:])+oS.b #np.multiply之后还是(m,1),(oS.X@oS.X[k,:])之后是(m,1),通过转置(1,m)@(m,1)-->实数后+b即可得到预测值fx #获取误差值Ek Ek = fxk - oS.label[k] return Ek
(三)重点:内循环的启发式方法,获取最大差值|Ei-Ej|对应的Ej的索引J
#内循环的启发式方法,获取最大差值|Ei-Ej|对应的Ej的索引J def selectJ(i,oS,Ei): #注意我们要传入第一个α对应的索引i和误差值Ei,后面会用到 maxK = -1 #用于保存临时最大索引 maxDeltaE = 0 #用于保存临时最大差值--->|Ei-Ej| Ej = 0 #保存我们需要的Ej误差值 #重点:这里我们是把SMO最后一步(根据最新阈值b,来更新Ei)提到第一步来进行了,所以这一步是非常重要的 oS.eCache[i] = [1,Ei] #开始获取各个Ek值,比较|Ei-Ej|获取Ej的所有 #获取所有有效的Ek值对应的索引 validECacheList = np.where(oS.eCache[:,0]!=0)[0] #根据误差缓存中第一列非0,获取对应的有效误差值 if len(validECacheList) > 1: #如果有效误差缓存长度大于1(因为包括Ei),则正常进行获取j值,否则使用selectJradn方法选取一个随机J值 for k in validECacheList: if k == i: #相同则不处理 continue #开始计算Ek值,进行对比,获取最大差值 Ek = calcEk(oS,k) deltaE = abs(Ei - Ek) if deltaE > maxDeltaE: #更新Ej及其索引位置 maxK = k maxDeltaE = deltaE Ej = Ek return maxK,Ej #返回我们找到的第二个变量α_2的位置 else: #没有有效误差缓存,则随机选取一个索引,进行返回 j = selectJrand(i,oS.m) Ej = calcEk(oS,j) return j,Ej
(四)实现更新Ek操作
#实现更新Ek操作,因为除了最后我们需要更新Ei之外,我们在内循环中计算α_1与α_2时还是需要用到E1与E2, #因为每次的E1与E2由于上一次循环中更新了α值,所以这一次也是需要更新E1与E2值,所以单独实现一个更新Ek值的方法还是有必要的 def updateEk(oS,k): Ek = calcEk(oS,k) oS.eCache[k] = [1,Ek] #第一列1,表示为有效标识
五:代码实现(三)SMO中的内循环函数
外循环是要找违背KKT条件最严重的样本点(每个样本点对应一个α),这里我们将外循环的该判别条件放入内循环中考虑。
(一)补充违背KKT条件选取
对于SVM中的KKT条件如下:

一般来说,我们首先选择违反0<αi<C⇒yig(xi)=1这个条件的点。
如果这些支持向量都满足KKT条件,再选择违反αi=0⇒yig(xi)≥1和 αi=C⇒yig(xi)≤1的点。
(二)分析0<αi<C⇒yig(xi)=1条件
对于上面违反KKT条件实际应用时的两种情况(或状态):
1. 0<αi⇒yig(xi)>1违背KKT条件
之所以不考虑α<c的情况,因为当yig(xi)>1时,必然出现α≠c,又因为0<α<c,所以我们只用考虑0<α⇒yig(xi)>1即可。
2. αi <C⇒yig(xi)<1违背KKT条件
之所以不考虑α>0的情况,因为当yig(xi)<1时,必然出现α≠0,又因为0<α<c,所以我们只用考虑α<C⇒yig(xi)<1即可。
(三)软间隔分析(同上)
相比较于硬间隔状态,多了一个松弛变量,所以我们考虑的时候加上该松弛变量即可。
1. 0<αi⇒yig(xi)>1+ξ违背KKT条件
2. αi <C⇒yig(xi)<1-ξ违背KKT条件
(四)代码分析
if ((oS.label[i]*Ei < -oS.toler) and (oS.alphas[i] < oS.C)) or\ ((oS.label[i]*Ei > oS.toler) and (oS.alphas[i] > 0)): #注意:对于硬间隔,我们直接和1对比,对于软间隔,我们要和1 +或- ε对比
这里的代码和我们上面分析的违背KKT条件有所不同,所以下面进行推导:
主要看Ei的公式:Ei=g(xi)-yi
如(二)(三)分析可以知道,我们将进入优化的条件(即违背KKT条件)写成代码中形式:
(yiEi<-toler且α<C)或(yiEi>toler且α>C)
条件中yiEi=yi(g(xi)-yi)=yig(xi)-yi2
由于yi=±1,所以yi2=1
最后,我们就可以将代码中的原条件化简为:
(yig(xi)<1-toler且α<C)或(yig(xi)>1+toler且α>C)
即我们在(三)中的形式
(六)分析内循环中η值的性质
#计算η值=k_11+k_22-2k_12 eta = oS.X[i]@oS.X[i] + oS.X[j]@oS.X[j] - 2.0*oS.X[i]@oS.X[j] #eta性质可以知道是>=0的,所以我们只需要判断是否为0即可 if eta <= 0: print("eta <= 0") return 0
由下述η化简可以知道:
![]()
η的取值范围必然是η>=0。
又因为我们在推导SVM算法中知道:
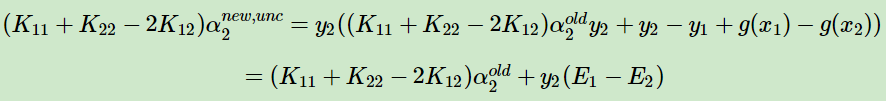
当η=0时,我们要求解的α无法更新,所以,我们只需要η>0即可。
所以,代码中判断η<=0时,不符合条件,退出即可。
(五)代码实现
#三:实现内循环函数,相比于外循环,这里包含了主要的更新操作 def innerL(i,oS): #由外循环提供i值(具体选取要违背kkT<这里实现>,使用交替遍历<外循环中实现>)---提供α_1的索引 Ei = calcEk(oS,i) #计算E1值,主要是为了下面KKT条件需要使用到 #如果下面违背了KKT条件,则正常进行α、Ek、b的更新,重点:后面单独说明下面是否满足违反KKT条件 if ((oS.label[i]*Ei < -oS.toler) and (oS.alphas[i] < oS.C)) or\ ((oS.label[i]*Ei > oS.toler) and (oS.alphas[i] > 0)): #注意:对于硬间隔,我们直接和1对比,对于软间隔,我们要和1 +或- ε对比 #开始在内循环中,选取差值最大的α_2下标索引 j,Ej = selectJ(i,oS,Ei) #因为后面要修改α_1与α_2的值,但是后面修改阈值b的时候需要用到新旧两个值,所以我们需要在更新α值之前进行保存旧值 alphaIold = oS.alphas[i].copy() alphaJold = oS.alphas[j].copy() #分析约束条件(是对所有α都适用),一会对我们新的α_2进行截取纠正,注意:α_1是由α_2推出的,所以不需要进行验证了。 #如果y_1!=y_2异号时: if oS.label[i] != oS.label[j]: L = max(0,alphaJold-alphaIold) H = min(oS.C,oS.C+alphaJold-alphaIold) else: #如果y_1==y_2同号时 L = max(0,alphaJold+alphaIold-oS.C) H = min(oS.C,alphaJold+alphaIold) #上面就是将α_j调整到L,H之间 if L==H: #如果L==H,之间返回0,跳出这次循环,不进行改变(单值选择,没必要) return 0 #计算η值=k_11+k_22-2k_12 eta = oS.X[i]@oS.X[i] + oS.X[j]@oS.X[j] - 2.0*oS.X[i]@oS.X[j] #eta性质可以知道是>=0的,所以我们只需要判断是否为0即可 if eta <= 0: print("eta <= 0") return 0 #当上面所有条件都满足以后,我们开始正式修改α_2值,并更新对应的Ek值 oS.alphas[j] += oS.label[j]*(Ei-Ej)/eta oS.alphas[j] = clipAlpha(oS.alphas[j],H,L) updateEk(oS,j) #查看α_2是否有足够的变化量,如果没有足够变化量,我们直接返回,不进行下面更新α_1,注意:因为α_2变化量较小,所以我们没有必要非得把值变回原来的旧值 if abs(oS.alphas[j] - alphaJold) < 0.00001: print("J not move enough") return 0 #开始更新α_1值,和Ek值 oS.alphas[i] += oS.label[i]*oS.label[j]*(alphaJold-oS.alphas[j]) updateEk(oS,i) #开始更新阈值b,正好使用到了上面更新的Ek值 b1 = oS.b - Ei - oS.label[i] * (oS.alphas[i] - alphaIold) * oS.X[i] @ oS.X[i] - oS.label[j] * ( oS.alphas[j] - alphaJold) * oS.X[i] @ oS.X[j] b2 = oS.b - Ej - oS.label[i] * (oS.alphas[i] - alphaIold) * oS.X[i] @ oS.X[j] - oS.label[j] * ( oS.alphas[j] - alphaJold) * oS.X[j] @ oS.X[j] #根据统计学习方法中阈值b在每一步中都会进行更新, #1.当新值alpha_1不在界上时(0<alpha_1<C),b_new的计算规则为:b_new=b1 #2.当新值alpha_2不在界上时(0 < alpha_2 < C),b_new的计算规则为:b_new = b2 #3.否则当alpha_1和alpha_2都不在界上时,b_new = 1/2(b1+b2) if oS.alphas[i] > 0 and oS.alphas[i] < oS.C: oS.b = b1 elif oS.alphas[j] > 0 and oS.alphas[j] < oS.C: oS.b = b2 else: oS.b = 1/2*(b1+b2) #注意:这里我们应该根据b_new更新一次Ei,但是我们这里没有写,因为我们将这一步提前到了最开始,即selectJ中 #以上全部更新完毕,开始返回标识 return 1 return 0 #没有违背KKT条件
六:代码实现(四)SMO中的外循环函数
(一)交替遍历
交替遍历一种方式是在所有的数据集上进行单遍扫描,另一种是在非边界上(不在边界0或C上的值)进行单遍扫描
交替遍历:
交替是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间交替:
一种方式是在所有数据集上进行单遍扫描,
另一种方式则是在非边界alpha中实现单遍扫描,所谓非边界alpha指的是那些不等于边界0或C的alpha值。
对整个数据集的扫描相当容易,
而实现非边界alpha值的扫描时,首先需要建立这些alpha值的列表,然后对这个表进行遍历。
同时,该步骤会跳过那些已知不变的alpha值。
(二)代码实现
#四:开始外循环,由于我们在内循环中实现了KKT条件的判断,所以这里我们只需要进行交替遍历即可 #交替遍历一种方式是在所有的数据集上进行单遍扫描,另一种是在非边界上(不在边界0或C上的值)进行单遍扫描 # 交替遍历: # 交替是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间交替: # 一种方式是在所有数据集上进行单遍扫描, # 另一种方式则是在非边界alpha中实现单遍扫描,所谓非边界alpha指的是那些不等于边界0或C的alpha值。 # 对整个数据集的扫描相当容易, # 而实现非边界alpha值的扫描时,首先需要建立这些alpha值的列表,然后对这个表进行遍历。 # 同时,该步骤会跳过那些已知不变的alpha值。 def smoP(data_X,data_Y,C,toler,maxIter): oS = optStruct(data_X,data_Y,C,toler) iter = 0 entireSet = True #标志是否应该遍历整个数据集 alphaPairsChanged = 0 #标志一次循环中α更新的次数 #开始进行迭代 #当iter >= maxIter或者((alphaPairsChanged == 0) and not entireSet)退出循环 #前半个判断条件很好理解,后面的判断条件中,表示上一次循环中,是在整个数据集中遍历,并且没有α值更新过,则退出 while iter < maxIter and ((alphaPairsChanged > 0) or entireSet): alphaPairsChanged = 0 if entireSet: #entireSet是true,则在整个数据集上进行遍历 for i in range(oS.m): alphaPairsChanged += innerL(i,oS) #调用内循环 print("full dataset, iter: %d i:%d,pairs changed:%d"%(iter,i,alphaPairsChanged)) iter += 1 #无论是否更新过,我们都计算迭代一次 else: #遍历非边界值 nonBounds = np.where((oS.alphas>0) & (oS.alphas<C))[0] #获取非边界值中的索引 for i in nonBounds: #开始遍历 alphaPairsChanged += innerL(i,oS) print("non bound, iter: %d i:%d,pairs changed:%d"%(iter,i,alphaPairsChanged)) iter += 1 #无论是否更新过,我们都计算迭代一次 #下面实现交替遍历 if entireSet: entireSet = False elif alphaPairsChanged == 0: #如果是在非边界上,并且α更新过。则entireSet还是False,下一次还是在非边界上进行遍历。可以认为这里是倾向于非边界遍历,因为非边界遍历的样本更符合内循环中的违反KKT条件 entireSet = True print("iteration number: %d"%iter) return oS.b,oS.alphas
七:根据α实现求解权重W值
(一)公式
根据西瓜书中6.37:
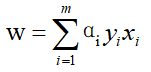
求解权重向量
(二)代码实现
def calcWs(alphas,data_X,data_Y): #根据西瓜书6.37求W m,n = data_X.shape w = np.zeros(n) for i in range(m): w += alphas[i]*data_Y[i]*data_X[i].T return w
八:测试SMO算法的实现
data_X,data_Y = loadDataSet("testSet.txt") C = 0.6 toler = 0.001 maxIter = 40 b,alphas = smoP(data_X,data_Y,C,toler,maxIter) ws = calcWs(alphas,data_X,data_Y) #含有随机操作,所以有多种可能性结果 print(ws) test = data_X[0]@ws+b print(test) test = data_X[2]@ws+b print(test) test = data_X[1]@ws+b print(test)
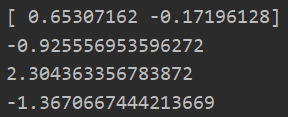
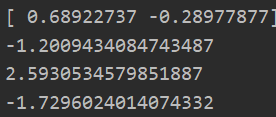
九:绘制图像和支持向量
(一)代码实现
#绘制图像 def plotFigure(weights, b,toler,data_X,data_Y): m,n = data_X.shape # 进行数据集分类操作 cls_1x = data_X[np.where(data_Y==1)] cls_1y = data_Y[np.where(data_Y==1)] cls_2x = data_X[np.where(data_Y!=1)] cls_2y = data_Y[np.where(data_Y!=1)] plt.scatter(cls_1x[:,0].flatten(), cls_1x[:,1].flatten(), s=30, c='r', marker='s') plt.scatter(cls_2x[:,0].flatten(), cls_2x[:,1].flatten(), s=30, c='g') # 画出 SVM 分类直线 xx = np.arange(0, 10, 0.1) # 由分类直线 weights[0] * xx + weights[1] * yy1 + b = 0 易得下式 yy1 = (-weights[0] * xx - b) / weights[1] # 由分类直线 weights[0] * xx + weights[1] * yy2 + b + 1 = 0 易得下式 yy2 = (-weights[0] * xx - b - 1 - toler) / weights[1] # 由分类直线 weights[0] * xx + weights[1] * yy3 + b - 1 = 0 易得下式 yy3 = (-weights[0] * xx - b + 1 + toler) / weights[1] plt.plot(xx, yy1.T) plt.plot(xx, yy2.T) plt.plot(xx, yy3.T) # 画出支持向量点 for i in range(m): if alphas[i] > 0.0: #注意:只要α>0,由KKT条件(西瓜书6.41)可以知道,该数据点是落在最大间隔边界处 plt.scatter(data_X[i, 0], data_X[i, 1], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red') plt.xlim((-2, 12)) plt.ylim((-8, 6)) plt.show() plotFigure(ws,b,toler,data_X,data_Y)
(二)图像显示
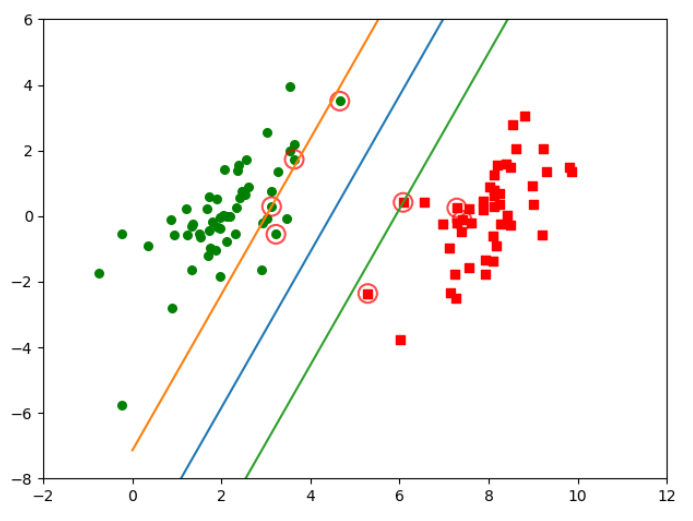
十:全部代码


import numpy as np import matplotlib.pyplot as plt #一:SMO算法中的辅助函数 #加载数据集 def loadDataSet(filename): dataSet = np.loadtxt(filename) m,n = dataSet.shape data_X = dataSet[:,0:n-1] data_Y = dataSet[:,n-1] return data_X,data_Y #随机选取一个数J,为后面内循环选取α_2做辅助(如果α选取不满足条件,就选择这个方法随机选取) def selectJrand(i,m): #主要就是根据α_1的索引i,从所有数据集索引中随机选取一个作为α_2的索引 j = i while j==i: j = np.int(np.random.uniform(0,m)) #从0~m中随机选取一个数,是进行整数化的 print("random choose index for α_2:%d"%(j)) return j #由于这里返回随机数,所以后面结果 可能导致不同 def clipAlpha(aj,H,L): #根据我们的SVM算法中的约束条件的分析,我们对获取的aj,进行了截取操作 if aj > H: aj = H if aj < L: aj = L return aj #二:SMO的支持函数 #首先我们定义一个数据结构(类),来保存所有的重要值 class optStruct: def __init__(self,data_X,data_Y,C,toler): #输入参数分别是数据集、类别标签、常数C用于软间隔、和容错率toler self.X = data_X self.label = data_Y self.C = C self.toler = toler #就是软间隔中的ε,调节最大间隔大小 self.m = data_X.shape[0] self.alphas = np.zeros(self.m) #存放每个样本点的α值 self.b = 0 #存放阈值 self.eCache = np.zeros((self.m,2)) #用于缓存误差,每个样本点对应一个Ei值,第一列为标识符,标志是否为有效值,第二列存放有效值 #计算每个样本点k的Ek值,就是计算误差值=预测值-标签值 def calcEk(oS,k): # 根据西瓜书6.24,我们可以知道预测值如何使用α值进行求解 fxk = np.multiply(oS.alphas,oS.label).T@(oS.X@oS.X[k,:])+oS.b #np.multiply之后还是(m,1),(oS.X@oS.X[k,:])之后是(m,1),通过转置(1,m)@(m,1)-->实数后+b即可得到预测值fx #获取误差值Ek Ek = fxk - oS.label[k] return Ek #内循环的启发式方法,获取最大差值|Ei-Ej|对应的Ej的索引J def selectJ(i,oS,Ei): #注意我们要传入第一个α对应的索引i和误差值Ei,后面会用到 maxK = -1 #用于保存临时最大索引 maxDeltaE = 0 #用于保存临时最大差值--->|Ei-Ej| Ej = 0 #保存我们需要的Ej误差值 #重点:这里我们是把SMO最后一步(根据最新阈值b,来更新Ei)提到第一步来进行了,所以这一步是非常重要的 oS.eCache[i] = [1,Ei] #开始获取各个Ek值,比较|Ei-Ej|获取Ej的所有 #获取所有有效的Ek值对应的索引 validECacheList = np.where(oS.eCache[:,0]!=0)[0] #根据误差缓存中第一列非0,获取对应的有效误差值 if len(validECacheList) > 1: #如果有效误差缓存长度大于1(因为包括Ei),则正常进行获取j值,否则使用selectJradn方法选取一个随机J值 for k in validECacheList: if k == i: #相同则不处理 continue #开始计算Ek值,进行对比,获取最大差值 Ek = calcEk(oS,k) deltaE = abs(Ei - Ek) if deltaE > maxDeltaE: #更新Ej及其索引位置 maxK = k maxDeltaE = deltaE Ej = Ek return maxK,Ej #返回我们找到的第二个变量α_2的位置 else: #没有有效误差缓存,则随机选取一个索引,进行返回 j = selectJrand(i,oS.m) Ej = calcEk(oS,j) return j,Ej #实现更新Ek操作,因为除了最后我们需要更新Ei之外,我们在内循环中计算α_1与α_2时还是需要用到E1与E2, #因为每次的E1与E2由于上一次循环中更新了α值,所以这一次也是需要更新E1与E2值,所以单独实现一个更新Ek值的方法还是有必要的 def updateEk(oS,k): Ek = calcEk(oS,k) oS.eCache[k] = [1,Ek] #第一列1,表示为有效标识 #三:实现内循环函数,相比于外循环,这里包含了主要的更新操作 def innerL(i,oS): #由外循环提供i值(具体选取要违背kkT<这里实现>,使用交替遍历<外循环中实现>)---提供α_1的索引 Ei = calcEk(oS,i) #计算E1值,主要是为了下面KKT条件需要使用到 #如果下面违背了KKT条件,则正常进行α、Ek、b的更新,重点:后面单独说明下面是否满足违反KKT条件 if ((oS.label[i]*Ei < -oS.toler) and (oS.alphas[i] < oS.C)) or\ ((oS.label[i]*Ei > oS.toler) and (oS.alphas[i] > 0)): #注意:对于硬间隔,我们直接和1对比,对于软间隔,我们要和1 +或- ε对比 #开始在内循环中,选取差值最大的α_2下标索引 j,Ej = selectJ(i,oS,Ei) #因为后面要修改α_1与α_2的值,但是后面修改阈值b的时候需要用到新旧两个值,所以我们需要在更新α值之前进行保存旧值 alphaIold = oS.alphas[i].copy() alphaJold = oS.alphas[j].copy() #分析约束条件(是对所有α都适用),一会对我们新的α_2进行截取纠正,注意:α_1是由α_2推出的,所以不需要进行验证了。 #如果y_1!=y_2异号时: if oS.label[i] != oS.label[j]: L = max(0,alphaJold-alphaIold) H = min(oS.C,oS.C+alphaJold-alphaIold) else: #如果y_1==y_2同号时 L = max(0,alphaJold+alphaIold-oS.C) H = min(oS.C,alphaJold+alphaIold) #上面就是将α_j调整到L,H之间 if L==H: #如果L==H,之间返回0,跳出这次循环,不进行改变(单值选择,没必要) return 0 #计算η值=k_11+k_22-2k_12 eta = oS.X[i]@oS.X[i] + oS.X[j]@oS.X[j] - 2.0*oS.X[i]@oS.X[j] #eta性质可以知道是>=0的,所以我们只需要判断是否为0即可 if eta <= 0: print("eta <= 0") return 0 #当上面所有条件都满足以后,我们开始正式修改α_2值,并更新对应的Ek值 oS.alphas[j] += oS.label[j]*(Ei-Ej)/eta oS.alphas[j] = clipAlpha(oS.alphas[j],H,L) updateEk(oS,j) #查看α_2是否有足够的变化量,如果没有足够变化量,我们直接返回,不进行下面更新α_1,注意:因为α_2变化量较小,所以我们没有必要非得把值变回原来的旧值 if abs(oS.alphas[j] - alphaJold) < 0.00001: print("J not move enough") return 0 #开始更新α_1值,和Ek值 oS.alphas[i] += oS.label[i]*oS.label[j]*(alphaJold-oS.alphas[j]) updateEk(oS,i) #开始更新阈值b,正好使用到了上面更新的Ek值 b1 = oS.b - Ei - oS.label[i] * (oS.alphas[i] - alphaIold) * oS.X[i] @ oS.X[i] - oS.label[j] * ( oS.alphas[j] - alphaJold) * oS.X[i] @ oS.X[j] b2 = oS.b - Ej - oS.label[i] * (oS.alphas[i] - alphaIold) * oS.X[i] @ oS.X[j] - oS.label[j] * ( oS.alphas[j] - alphaJold) * oS.X[j] @ oS.X[j] #根据统计学习方法中阈值b在每一步中都会进行更新, #1.当新值alpha_1不在界上时(0<alpha_1<C),b_new的计算规则为:b_new=b1 #2.当新值alpha_2不在界上时(0 < alpha_2 < C),b_new的计算规则为:b_new = b2 #3.否则当alpha_1和alpha_2都不在界上时,b_new = 1/2(b1+b2) if oS.alphas[i] > 0 and oS.alphas[i] < oS.C: oS.b = b1 elif oS.alphas[j] > 0 and oS.alphas[j] < oS.C: oS.b = b2 else: oS.b = 1/2*(b1+b2) #注意:这里我们应该根据b_new更新一次Ei,但是我们这里没有写,因为我们将这一步提前到了最开始,即selectJ中 #以上全部更新完毕,开始返回标识 return 1 return 0 #没有违背KKT条件 #四:开始外循环,由于我们在内循环中实现了KKT条件的判断,所以这里我们只需要进行交替遍历即可 #交替遍历一种方式是在所有的数据集上进行单遍扫描,另一种是在非边界上(不在边界0或C上的值)进行单遍扫描 # 交替遍历: # 交替是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间交替: # 一种方式是在所有数据集上进行单遍扫描, # 另一种方式则是在非边界alpha中实现单遍扫描,所谓非边界alpha指的是那些不等于边界0或C的alpha值。 # 对整个数据集的扫描相当容易, # 而实现非边界alpha值的扫描时,首先需要建立这些alpha值的列表,然后对这个表进行遍历。 # 同时,该步骤会跳过那些已知不变的alpha值。 def smoP(data_X,data_Y,C,toler,maxIter): oS = optStruct(data_X,data_Y,C,toler) iter = 0 entireSet = True #标志是否应该遍历整个数据集 alphaPairsChanged = 0 #标志一次循环中α更新的次数 #开始进行迭代 #当iter >= maxIter或者((alphaPairsChanged == 0) and not entireSet)退出循环 #前半个判断条件很好理解,后面的判断条件中,表示上一次循环中,是在整个数据集中遍历,并且没有α值更新过,则退出 while iter < maxIter and ((alphaPairsChanged > 0) or entireSet): alphaPairsChanged = 0 if entireSet: #entireSet是true,则在整个数据集上进行遍历 for i in range(oS.m): alphaPairsChanged += innerL(i,oS) #调用内循环 print("full dataset, iter: %d i:%d,pairs changed:%d"%(iter,i,alphaPairsChanged)) iter += 1 #无论是否更新过,我们都计算迭代一次 else: #遍历非边界值 nonBounds = np.where((oS.alphas>0) & (oS.alphas<C))[0] #获取非边界值中的索引 for i in nonBounds: #开始遍历 alphaPairsChanged += innerL(i,oS) print("non bound, iter: %d i:%d,pairs changed:%d"%(iter,i,alphaPairsChanged)) iter += 1 #无论是否更新过,我们都计算迭代一次 #下面实现交替遍历 if entireSet: entireSet = False elif alphaPairsChanged == 0: #如果是在非边界上,并且α更新过。则entireSet还是False,下一次还是在非边界上进行遍历。可以认为这里是倾向于非边界遍历,因为非边界遍历的样本更符合内循环中的违反KKT条件 entireSet = True print("iteration number: %d"%iter) return oS.b,oS.alphas def calcWs(alphas,data_X,data_Y): #根据西瓜书6.37求W m,n = data_X.shape w = np.zeros(n) for i in range(m): w += alphas[i]*data_Y[i]*data_X[i].T return w #绘制图像 def plotFigure(weights, b,toler,data_X,data_Y): m,n = data_X.shape # 进行数据集分类操作 cls_1x = data_X[np.where(data_Y==1)] cls_1y = data_Y[np.where(data_Y==1)] cls_2x = data_X[np.where(data_Y!=1)] cls_2y = data_Y[np.where(data_Y!=1)] plt.scatter(cls_1x[:,0].flatten(), cls_1x[:,1].flatten(), s=30, c='r', marker='s') plt.scatter(cls_2x[:,0].flatten(), cls_2x[:,1].flatten(), s=30, c='g') # 画出 SVM 分类直线 xx = np.arange(0, 10, 0.1) # 由分类直线 weights[0] * xx + weights[1] * yy1 + b = 0 易得下式 yy1 = (-weights[0] * xx - b) / weights[1] # 由分类直线 weights[0] * xx + weights[1] * yy2 + b + 1 = 0 易得下式 yy2 = (-weights[0] * xx - b - 1 - toler) / weights[1] # 由分类直线 weights[0] * xx + weights[1] * yy3 + b - 1 = 0 易得下式 yy3 = (-weights[0] * xx - b + 1 + toler) / weights[1] plt.plot(xx, yy1.T) plt.plot(xx, yy2.T) plt.plot(xx, yy3.T) # 画出支持向量点 for i in range(m): if alphas[i] > 0.0: plt.scatter(data_X[i, 0], data_X[i, 1], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red') plt.xlim((-2, 12)) plt.ylim((-8, 6)) plt.show() data_X,data_Y = loadDataSet("testSet.txt") C = 0.6 toler = 0.001 maxIter = 40 b,alphas = smoP(data_X,data_Y,C,toler,maxIter) ws = calcWs(alphas,data_X,data_Y) #含有随机操作,所以有多种可能性结果 print(ws) test = data_X[0]@ws+b print(test) test = data_X[2]@ws+b print(test) test = data_X[1]@ws+b print(test) plotFigure(ws,b,toler,data_X,data_Y)
数据集太久了,忘了存放位置了....,下面放一个机器学习实战的数据集供测试。谁有好的数据集请分享一下,谢谢了.
3.542485 1.977398 -1 3.018896 2.556416 -1 7.551510 -1.580030 1 2.114999 -0.004466 -1 8.127113 1.274372 1 7.108772 -0.986906 1 8.610639 2.046708 1 2.326297 0.265213 -1 3.634009 1.730537 -1 0.341367 -0.894998 -1 3.125951 0.293251 -1 2.123252 -0.783563 -1 0.887835 -2.797792 -1 7.139979 -2.329896 1 1.696414 -1.212496 -1 8.117032 0.623493 1 8.497162 -0.266649 1 4.658191 3.507396 -1 8.197181 1.545132 1 1.208047 0.213100 -1 1.928486 -0.321870 -1 2.175808 -0.014527 -1 7.886608 0.461755 1 3.223038 -0.552392 -1 3.628502 2.190585 -1 7.407860 -0.121961 1 7.286357 0.251077 1 2.301095 -0.533988 -1 -0.232542 -0.547690 -1 3.457096 -0.082216 -1 3.023938 -0.057392 -1 8.015003 0.885325 1 8.991748 0.923154 1 7.916831 -1.781735 1 7.616862 -0.217958 1 2.450939 0.744967 -1 7.270337 -2.507834 1 1.749721 -0.961902 -1 1.803111 -0.176349 -1 8.804461 3.044301 1 1.231257 -0.568573 -1 2.074915 1.410550 -1 -0.743036 -1.736103 -1 3.536555 3.964960 -1 8.410143 0.025606 1 7.382988 -0.478764 1 6.960661 -0.245353 1 8.234460 0.701868 1 8.168618 -0.903835 1 1.534187 -0.622492 -1 9.229518 2.066088 1 7.886242 0.191813 1 2.893743 -1.643468 -1 1.870457 -1.040420 -1 5.286862 -2.358286 1 6.080573 0.418886 1 2.544314 1.714165 -1 6.016004 -3.753712 1 0.926310 -0.564359 -1 0.870296 -0.109952 -1 2.369345 1.375695 -1 1.363782 -0.254082 -1 7.279460 -0.189572 1 1.896005 0.515080 -1 8.102154 -0.603875 1 2.529893 0.662657 -1 1.963874 -0.365233 -1 8.132048 0.785914 1 8.245938 0.372366 1 6.543888 0.433164 1 -0.236713 -5.766721 -1 8.112593 0.295839 1 9.803425 1.495167 1 1.497407 -0.552916 -1 1.336267 -1.632889 -1 9.205805 -0.586480 1 1.966279 -1.840439 -1 8.398012 1.584918 1 7.239953 -1.764292 1 7.556201 0.241185 1 9.015509 0.345019 1 8.266085 -0.230977 1 8.545620 2.788799 1 9.295969 1.346332 1 2.404234 0.570278 -1 2.037772 0.021919 -1 1.727631 -0.453143 -1 1.979395 -0.050773 -1 8.092288 -1.372433 1 1.667645 0.239204 -1 9.854303 1.365116 1 7.921057 -1.327587 1 8.500757 1.492372 1 1.339746 -0.291183 -1 3.107511 0.758367 -1 2.609525 0.902979 -1 3.263585 1.367898 -1 2.912122 -0.202359 -1 1.731786 0.589096 -1 2.387003 1.573131 -1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号