机器学习实战---决策树CART回归树实现
机器学习实战---决策树CART简介及分类树实现
一:对比分类树
CART回归树和CART分类树的建立算法大部分是类似的,所以这里我们只讨论CART回归树和CART分类树的建立算法不同的地方。
首先,我们要明白,什么是回归树,什么是分类树。
两者的区别在于样本输出:
如果样本输出是离散值,那么这是一颗分类树。
如果果样本输出是连续值,那么那么这是一颗回归树。
除了概念的不同,CART回归树和CART分类树的建立和预测的区别主要有下面两点:
1)连续值的处理方法不同
2)决策树建立后做预测的方式不同。
对于连续值的处理,我们知道CART分类树采用的是用基尼系数的大小来度量特征的各个划分点的优劣情况,这比较适合分类模型。
但是对于回归模型,我们使用了常见的和方差的度量方式。
CART回归树的度量目标是,对于任意划分特征A,对应的任意划分点s两边划分成的数据集D1和D2,求出使D1和D2各自集合的均方差最小,同时D1和D2的均方差之和最小所对应的特征和特征值划分点。
表达式为:
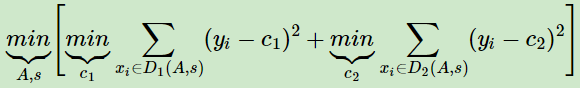
其中,c1为D1数据集的样本输出均值,c2为D2数据集的样本输出均值。
对于决策树建立后做预测的方式,上面讲到了CART分类树采用叶子节点里概率最大的类别作为当前节点的预测类别。而回归树输出不是类别,它采用的是用最终叶子的均值或者中位数来预测输出结果。
除了上面提到了以外,CART回归树和CART分类树的建立算法和预测没有什么区别。
二:回归树的实现
(一)实现叶子节点均值计算
def regLeaf(data_Y): #用于计算指定样本中标签均值表示回归y值 return np.mean(data_Y)
(二)实现计算数据集总方差
def regErr(data_Y): #使用均方误差作为划分依据 return np.var(data_Y)*data_Y.size #np.var是求解平均误差,我们这里需要总方差进行比较
(三)实现数据集切分
def binSplitDataSet(data_X,data_Y,fea_axis,fea_val): #进行数据集划分 dataGtIdx = np.where(data_X[:,fea_axis]>fea_val) dataLgIdx = np.where(data_X[:,fea_axis]<=fea_val) return data_X[dataGtIdx],data_Y[dataGtIdx],data_X[dataLgIdx],data_Y[dataLgIdx]
(四)实现选取最优特征及特征值(含预剪枝处理)
def chooseBestSplit(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): """ 选取的最好切分方式,使用回调方式调用叶节点计算和误差计算,函数中含有预剪枝操作 :param data_X: 传入数据集 :param data_Y: 传入标签值 :param leafType: 要调用计算的叶节点值 --- 虽然灵活,但是没必要 :param errType: 要计算误差的函数,这里是均方误差 --- 虽然灵活,但是没必要 :param ops: 包含了两个重要信息, tolS tolN用于控制函数的停止时机,tolS是容许的误差下降值,误差小于则不再切分,tosN是切分的最少样本数 :return: """ m,n = data_X.shape tolS = ops[0] tolN = ops[1] #之前都是将判断是否继续划分子树放入createTree方法中,这里可以提到chooseBestSplit中进行判别。 #当然可以放入createTree方法中处理 if np.unique(data_Y).size == 1: #1.如果标签值全部相同,则返回特征None表示不需要进行下一步划分,返回叶节点 return None,leafType(data_Y) #遍历获取最优特征和特征值 TosErr = errType(data_Y) #获取全部数据集的误差,后面计算划分后两个子集的总误差,如果误差下降小于tolS,则不进行划分,返回该叶子节点即可(预剪枝操作) bestErr = np.inf bestFeaIdx = 0 #注意:这里两个我们设置为0,而不是-1,因为我们必须保证可以取到一个特征(后面循环可能一直continue),我们需要在后面进行额外处理 bestFeaVal = 0 for i in range(n): #遍历所有特征 for feaval in np.unique(data_X[:,i]): dataGt_X,dataGt_Y,dataLg_X,dataLg_Y = binSplitDataSet(data_X,data_Y,i,feaval) #数据集划分 # print(dataGt_X.shape,dataLg_X.shape) if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: #不符合最小数据集,不进行计算 continue concErr = errType(dataLg_Y)+errType(dataGt_Y) # print(concErr) if concErr < bestErr: bestFeaIdx = i bestFeaVal = feaval bestErr = concErr #2.如果最后求解的误差,小于我们要求的误差距离,则不进行下一步划分数据集(预剪枝) if (TosErr - bestErr) < tolS: return None,leafType(data_Y) #3.如果我们上面的数据集本身较小,则无论如何切分,数据集都<tolN,我们就需要在这里再处理一遍,进行一下判断 dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, bestFeaIdx, bestFeaVal) # 数据集划分 if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: # 不符合最小数据集,不进行计算 return None,leafType(data_Y) return bestFeaIdx,bestFeaVal #正常情况下的返回结果
(五)实现决策树创建
def createTree(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): #建立回归树 feaIdx,feaVal = chooseBestSplit(data_X,data_Y,leafType,errType,ops) if feaIdx == None: #是叶子节点 return feaVal #递归建树 myTree = {} myTree['feaIdx'] = feaIdx myTree['feaVal'] = feaVal dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, feaIdx, feaVal) # 数据集划分 myTree['left'] = createTree(dataGt_X,dataGt_Y,leafType,errType,ops) myTree['right'] = createTree(dataLg_X,dataLg_Y,leafType,errType,ops) return myTree
(六)数据集加载及测试
import numpy as np def loadDataSet(filename): dataSet = np.loadtxt(filename) m,n = dataSet.shape data_X = dataSet[:,0:n-1] data_Y = dataSet[:,n-1] return data_X,data_Y
data_X,data_Y = loadDataSet("ex0.txt") print(createTree(data_X,data_Y))
结果显示:
{'feaIdx': 1, 'feaVal': 0.39435,
'left': {
'feaIdx': 1, 'feaVal': 0.582002,
'left': {
'feaIdx': 1, 'feaVal': 0.797583,
'left': 3.9871632,
'right': 2.9836209534883724
},
'right': 1.980035071428571
},
'right': {
'feaIdx': 1, 'feaVal': 0.197834,
'left': 1.0289583666666666,
'right': -0.023838155555555553
}
}
(七)全部代码


import numpy as np def loadDataSet(filename): dataSet = np.loadtxt(filename) m,n = dataSet.shape data_X = dataSet[:,0:n-1] data_Y = dataSet[:,n-1] return data_X,data_Y def regLeaf(data_Y): #用于计算指定样本中标签均值表示回归y值 return np.mean(data_Y) def regErr(data_Y): #使用均方误差作为划分依据 return np.var(data_Y)*data_Y.size def binSplitDataSet(data_X,data_Y,fea_axis,fea_val): #进行数据集划分 dataGtIdx = np.where(data_X[:,fea_axis]>fea_val) dataLgIdx = np.where(data_X[:,fea_axis]<=fea_val) return data_X[dataGtIdx],data_Y[dataGtIdx],data_X[dataLgIdx],data_Y[dataLgIdx] def chooseBestSplit(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): """ 选取的最好切分方式,使用回调方式调用叶节点计算和误差计算,函数中含有预剪枝操作 :param data_X: 传入数据集 :param data_Y: 传入标签值 :param leafType: 要调用计算的叶节点值 --- 虽然灵活,但是没必要 :param errType: 要计算误差的函数,这里是均方误差 --- 虽然灵活,但是没必要 :param ops: 包含了两个重要信息, tolS tolN用于控制函数的停止时机,tolS是容许的误差下降值,误差小于则不再切分,tosN是切分的最少样本数 :return: """ m,n = data_X.shape tolS = ops[0] tolN = ops[1] #之前都是将判断是否继续划分子树放入createTree方法中,这里可以提到chooseBestSplit中进行判别。 #当然可以放入createTree方法中处理 if np.unique(data_Y).size == 1: #1.如果标签值全部相同,则返回特征None表示不需要进行下一步划分,返回叶节点 return None,leafType(data_Y) #遍历获取最优特征和特征值 TosErr = errType(data_Y) #获取全部数据集的误差,后面计算划分后两个子集的总误差,如果误差下降小于tolS,则不进行划分,返回该叶子节点即可(预剪枝操作) bestErr = np.inf bestFeaIdx = 0 #注意:这里两个我们设置为0,而不是-1,因为我们必须保证可以取到一个特征(后面循环可能一直continue),我们需要在后面进行额外处理 bestFeaVal = 0 for i in range(n): #遍历所有特征 for feaval in np.unique(data_X[:,i]): dataGt_X,dataGt_Y,dataLg_X,dataLg_Y = binSplitDataSet(data_X,data_Y,i,feaval) #数据集划分 # print(dataGt_X.shape,dataLg_X.shape) if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: #不符合最小数据集,不进行计算 continue concErr = errType(dataLg_Y)+errType(dataGt_Y) # print(concErr) if concErr < bestErr: bestFeaIdx = i bestFeaVal = feaval bestErr = concErr #2.如果最后求解的误差,小于我们要求的误差距离,则不进行下一步划分数据集(预剪枝) if (TosErr - bestErr) < tolS: return None,leafType(data_Y) #3.如果我们上面的数据集本身较小,则无论如何切分,数据集都<tolN,我们就需要在这里再处理一遍,进行一下判断 dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, bestFeaIdx, bestFeaVal) # 数据集划分 if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: # 不符合最小数据集,不进行计算 return None,leafType(data_Y) return bestFeaIdx,bestFeaVal #正常情况下的返回结果 def createTree(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): #建立回归树 feaIdx,feaVal = chooseBestSplit(data_X,data_Y,leafType,errType,ops) if feaIdx == None: #是叶子节点 return feaVal #递归建树 myTree = {} myTree['feaIdx'] = feaIdx myTree['feaVal'] = feaVal dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, feaIdx, feaVal) # 数据集划分 myTree['left'] = createTree(dataGt_X,dataGt_Y,leafType,errType,ops) myTree['right'] = createTree(dataLg_X,dataLg_Y,leafType,errType,ops) return myTree data_X,data_Y = loadDataSet("ex0.txt") print(createTree(data_X,data_Y))
三:树剪枝
一棵树如果节点过多,表示该模型可能对数据进行了过拟合(使用测试集交叉验证法即可),这时就需要我们进行剪枝处理,避免过拟合
(一)预剪枝
前面建立决策树过程中,我们已经进行了预剪枝操作。即设置的ops参数,包含了两个重要信息, tolS tolN用于控制函数的停止时机,tolS是容许的误差下降值,误差小于则不再切分,tosN是切分的最少样本数。用于在建立决策树过程中进行预剪枝操作。
下面实例中,查看ops参数设置对剪枝的影响:
import numpy as np def loadDataSet(filename): dataSet = np.loadtxt(filename) m,n = dataSet.shape data_X = dataSet[:,0:n-1] data_Y = dataSet[:,n-1] return data_X,data_Y def regLeaf(data_Y): #用于计算指定样本中标签均值表示回归y值 return np.mean(data_Y) def regErr(data_Y): #使用均方误差作为划分依据 return np.var(data_Y)*data_Y.size def binSplitDataSet(data_X,data_Y,fea_axis,fea_val): #进行数据集划分 dataGtIdx = np.where(data_X[:,fea_axis]>fea_val) dataLgIdx = np.where(data_X[:,fea_axis]<=fea_val) return data_X[dataGtIdx],data_Y[dataGtIdx],data_X[dataLgIdx],data_Y[dataLgIdx] def chooseBestSplit(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): """ 选取的最好切分方式,使用回调方式调用叶节点计算和误差计算,函数中含有预剪枝操作 :param data_X: 传入数据集 :param data_Y: 传入标签值 :param leafType: 要调用计算的叶节点值 --- 虽然灵活,但是没必要 :param errType: 要计算误差的函数,这里是均方误差 --- 虽然灵活,但是没必要 :param ops: 包含了两个重要信息, tolS tolN用于控制函数的停止时机,tolS是容许的误差下降值,误差小于则不再切分,tosN是切分的最少样本数 :return: """ m,n = data_X.shape tolS = ops[0] tolN = ops[1] #之前都是将判断是否继续划分子树放入createTree方法中,这里可以提到chooseBestSplit中进行判别。 #当然可以放入createTree方法中处理 if np.unique(data_Y).size == 1: #1.如果标签值全部相同,则返回特征None表示不需要进行下一步划分,返回叶节点 return None,leafType(data_Y) #遍历获取最优特征和特征值 TosErr = errType(data_Y) #获取全部数据集的误差,后面计算划分后两个子集的总误差,如果误差下降小于tolS,则不进行划分,返回该叶子节点即可(预剪枝操作) bestErr = np.inf bestFeaIdx = 0 #注意:这里两个我们设置为0,而不是-1,因为我们必须保证可以取到一个特征(后面循环可能一直continue),我们需要在后面进行额外处理 bestFeaVal = 0 for i in range(n): #遍历所有特征 for feaval in np.unique(data_X[:,i]): dataGt_X,dataGt_Y,dataLg_X,dataLg_Y = binSplitDataSet(data_X,data_Y,i,feaval) #数据集划分 # print(dataGt_X.shape,dataLg_X.shape) if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: #不符合最小数据集,不进行计算 continue concErr = errType(dataLg_Y)+errType(dataGt_Y) # print(concErr) if concErr < bestErr: bestFeaIdx = i bestFeaVal = feaval bestErr = concErr #2.如果最后求解的误差,小于我们要求的误差距离,则不进行下一步划分数据集(预剪枝) if (TosErr - bestErr) < tolS: return None,leafType(data_Y) #3.如果我们上面的数据集本身较小,则无论如何切分,数据集都<tolN,我们就需要在这里再处理一遍,进行一下判断 dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, bestFeaIdx, bestFeaVal) # 数据集划分 if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: # 不符合最小数据集,不进行计算 return None,leafType(data_Y) return bestFeaIdx,bestFeaVal #正常情况下的返回结果 def createTree(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): #建立回归树 feaIdx,feaVal = chooseBestSplit(data_X,data_Y,leafType,errType,ops) if feaIdx == None: #是叶子节点 return feaVal #递归建树 myTree = {} myTree['feaIdx'] = feaIdx myTree['feaVal'] = feaVal dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, feaIdx, feaVal) # 数据集划分 myTree['left'] = createTree(dataGt_X,dataGt_Y,leafType,errType,ops) myTree['right'] = createTree(dataLg_X,dataLg_Y,leafType,errType,ops) return myTree
1.默认参数ops(1,4)---表示误差大于1,样本数大于4的划分结果
data_X,data_Y = loadDataSet("ex2.txt") print(createTree(data_X,data_Y,ops=(1,4)))
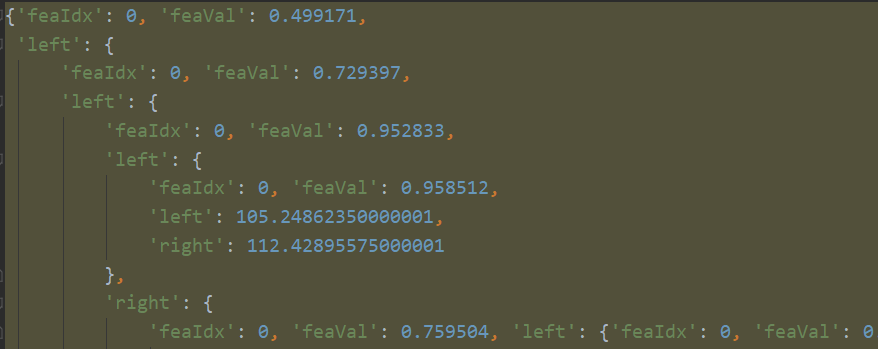
出现大量树分叉,过拟合
3.设置参数ops(1000,4)---表示误差大于1000,样本数大于4的划分结果
data_X,data_Y = loadDataSet("ex2.txt") print(createTree(data_X,data_Y,ops=(1000,4)))

拟合状态还不错。
3.设置参数ops(10000,4)---表示误差大于10000,样本数大于4的划分结果
data_X,data_Y = loadDataSet("ex2.txt") print(createTree(data_X,data_Y,ops=(10000,4)))

有点欠拟合。
(二)后剪枝
后剪枝通常比预剪枝保留更多的分支,欠拟合风险小。但是后剪枝是在决策树构造完成后进行的,其训练时间的开销会大于预剪枝。
后剪枝是基于已经建立好的树,进行的叶子节点合并操作。
使用后剪枝方法需要将数据集分为测试集和训练集。通过训练集和参数ops使用预剪枝方法构建决策树。然后使用构建的决策树和测试集数据进行后剪枝处理
后剪枝算法实现:
#开启后剪枝处理 def isTree(tree): return type(tree) == dict #是树的话返回字典,否则是数据 def getMean(tree): #获取当前树的合并均值REP---塌陷处理: 我们对一棵树进行塌陷处理,就是递归将这棵树进行合并返回这棵树的平均值。 if isTree(tree['right']): tree['right'] = getMean(tree['right']) if isTree(tree['left']): tree['left'] = getMean(tree['left']) return (tree['left'] + tree['right'])/2 #返回均值 def prune(tree,testData_X,testData_Y): #根据决策树和测试集数据进行后剪枝处理,不能按照训练集进行后剪枝,因为创建决策树时预剪枝操作中已经要求子树误差值小于根节点 #1.若是当测试集数据为空,则不需要后面的子树了,直接进行塌陷处理 if testData_X.shape[0] == 0: return getMean(tree) #2.如果当前测试集不为空,而且决策树含有左/右子树,则需要进入子树中进行剪枝操作---这里我们先将测试集数据划分 if isTree(tree['left']) or isTree(tree['right']): TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #3.根据子树进行下一步剪枝 if isTree(tree['left']): tree['left'] = prune(tree['left'],TestDataGT_X,TestDataGT_Y) #注意:这里是赋值操作,对树进行剪枝 if isTree(tree['right']): tree['right'] = prune(tree['right'],TestDataLG_X,TestDataLG_Y) #注意:这里是赋值操作,对树进行剪枝 #4.如果两个是叶子节点,我们开始计算误差,进行合并 if not isTree(tree['left']) and not isTree(tree['right']): #先划分测试集数据 TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #进行误差比较 #4-1.先获取没有合并的误差 errorNoMerge = np.sum(np.power(TestDataGT_Y-tree['left'],2)) + np.sum(np.power(TestDataLG_Y-tree['right'],2)) #4-2.再获取合并后的误差 treemean = (tree['left'] + tree['right'])/2 #因为是叶子节点,可以直接计算 errorMerge = np.sum(np.power(testData_Y- treemean,2)) #4-3.进行判断 if errorMerge < errorNoMerge: #可以剪枝 print("merging") #打印提示信息 return treemean #返回合并后的塌陷值 else: return tree #不进行合并,返回原树 return tree #返回树(但是该树的子树中可能存在剪枝合并情况由3可以知道
后剪枝算法测试:
data_X,data_Y = loadDataSet("ex2.txt") myTree = createTree(data_X,data_Y,ops=(0,1)) #设置0,1表示不进行预剪枝,我们只对比后剪枝 print(myTree) Testdata_X,Testdata_Y = loadDataSet("ex2test.txt") #获取测试集,开始进行后剪枝 myTree2 = prune(myTree,Testdata_X,Testdata_Y) print(myTree2)
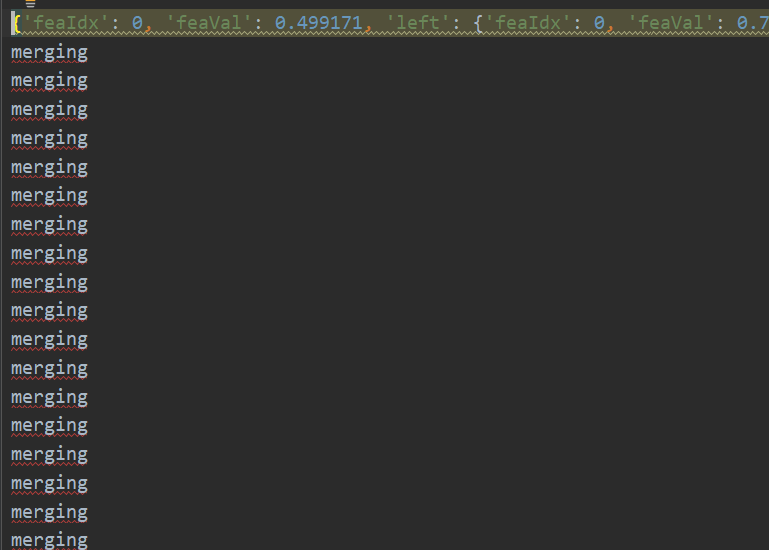
可以看到进行了大量的剪枝操作!
import numpy as np def loadDataSet(filename): dataSet = np.loadtxt(filename) m,n = dataSet.shape data_X = dataSet[:,0:n-1] data_Y = dataSet[:,n-1] return data_X,data_Y def regLeaf(data_Y): #用于计算指定样本中标签均值表示回归y值 return np.mean(data_Y) def regErr(data_Y): #使用均方误差作为划分依据 return np.var(data_Y)*data_Y.size def binSplitDataSet(data_X,data_Y,fea_axis,fea_val): #进行数据集划分 dataGtIdx = np.where(data_X[:,fea_axis]>fea_val) dataLgIdx = np.where(data_X[:,fea_axis]<=fea_val) return data_X[dataGtIdx],data_Y[dataGtIdx],data_X[dataLgIdx],data_Y[dataLgIdx] def chooseBestSplit(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): """ 选取的最好切分方式,使用回调方式调用叶节点计算和误差计算,函数中含有预剪枝操作 :param data_X: 传入数据集 :param data_Y: 传入标签值 :param leafType: 要调用计算的叶节点值 --- 虽然灵活,但是没必要 :param errType: 要计算误差的函数,这里是均方误差 --- 虽然灵活,但是没必要 :param ops: 包含了两个重要信息, tolS tolN用于控制函数的停止时机,tolS是容许的误差下降值,误差小于则不再切分,tosN是切分的最少样本数 :return: """ m,n = data_X.shape tolS = ops[0] tolN = ops[1] #之前都是将判断是否继续划分子树放入createTree方法中,这里可以提到chooseBestSplit中进行判别。 #当然可以放入createTree方法中处理 if np.unique(data_Y).size == 1: #1.如果标签值全部相同,则返回特征None表示不需要进行下一步划分,返回叶节点 return None,leafType(data_Y) #遍历获取最优特征和特征值 TosErr = errType(data_Y) #获取全部数据集的误差,后面计算划分后两个子集的总误差,如果误差下降小于tolS,则不进行划分,返回该叶子节点即可(预剪枝操作) bestErr = np.inf bestFeaIdx = 0 #注意:这里两个我们设置为0,而不是-1,因为我们必须保证可以取到一个特征(后面循环可能一直continue),我们需要在后面进行额外处理 bestFeaVal = 0 for i in range(n): #遍历所有特征 for feaval in np.unique(data_X[:,i]): dataGt_X,dataGt_Y,dataLg_X,dataLg_Y = binSplitDataSet(data_X,data_Y,i,feaval) #数据集划分 # print(dataGt_X.shape,dataLg_X.shape) if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: #不符合最小数据集,不进行计算 continue concErr = errType(dataLg_Y)+errType(dataGt_Y) # print(concErr) if concErr < bestErr: bestFeaIdx = i bestFeaVal = feaval bestErr = concErr #2.如果最后求解的误差,小于我们要求的误差距离,则不进行下一步划分数据集(预剪枝) if (TosErr - bestErr) < tolS: return None,leafType(data_Y) #3.如果我们上面的数据集本身较小,则无论如何切分,数据集都<tolN,我们就需要在这里再处理一遍,进行一下判断 dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, bestFeaIdx, bestFeaVal) # 数据集划分 if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: # 不符合最小数据集,不进行计算 return None,leafType(data_Y) return bestFeaIdx,bestFeaVal #正常情况下的返回结果 def createTree(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): #建立回归树 feaIdx,feaVal = chooseBestSplit(data_X,data_Y,leafType,errType,ops) if feaIdx == None: #是叶子节点 return feaVal #递归建树 myTree = {} myTree['feaIdx'] = feaIdx myTree['feaVal'] = feaVal dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, feaIdx, feaVal) # 数据集划分 myTree['left'] = createTree(dataGt_X,dataGt_Y,leafType,errType,ops) myTree['right'] = createTree(dataLg_X,dataLg_Y,leafType,errType,ops) return myTree #开启后剪枝处理 def isTree(tree): return type(tree) == dict #是树的话返回字典,否则是数据 def getMean(tree): #获取当前树的合并均值REP---塌陷处理: 我们对一棵树进行塌陷处理,就是递归将这棵树进行合并返回这棵树的平均值。 if isTree(tree['right']): tree['right'] = getMean(tree['right']) if isTree(tree['left']): tree['left'] = getMean(tree['left']) return (tree['left'] + tree['right'])/2 #返回均值 def prune(tree,testData_X,testData_Y): #根据决策树和测试集数据进行后剪枝处理,不能按照训练集进行后剪枝,因为创建决策树时预剪枝操作中已经要求子树误差值小于根节点 #1.若是当测试集数据为空,则不需要后面的子树了,直接进行塌陷处理 if testData_X.shape[0] == 0: return getMean(tree) #2.如果当前测试集不为空,而且决策树含有左/右子树,则需要进入子树中进行剪枝操作---这里我们先将测试集数据划分 if isTree(tree['left']) or isTree(tree['right']): TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #3.根据子树进行下一步剪枝 if isTree(tree['left']): tree['left'] = prune(tree['left'],TestDataGT_X,TestDataGT_Y) #注意:这里是赋值操作,对树进行剪枝 if isTree(tree['right']): tree['right'] = prune(tree['right'],TestDataLG_X,TestDataLG_Y) #注意:这里是赋值操作,对树进行剪枝 #4.如果两个是叶子节点,我们开始计算误差,进行合并 if not isTree(tree['left']) and not isTree(tree['right']): #先划分测试集数据 TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #进行误差比较 #4-1.先获取没有合并的误差 errorNoMerge = np.sum(np.power(TestDataGT_Y-tree['left'],2)) + np.sum(np.power(TestDataLG_Y-tree['right'],2)) #4-2.再获取合并后的误差 treemean = (tree['left'] + tree['right'])/2 #因为是叶子节点,可以直接计算 errorMerge = np.sum(np.power(testData_Y- treemean,2)) #4-3.进行判断 if errorMerge < errorNoMerge: #可以剪枝 print("merging") #打印提示信息 return treemean #返回合并后的塌陷值 else: return tree #不进行合并,返回原树 return tree #返回树(但是该树的子树中可能存在剪枝合并情况由3可以知道 data_X,data_Y = loadDataSet("ex2.txt") myTree = createTree(data_X,data_Y,ops=(0,1)) #设置0,1表示不进行预剪枝,我们只对比后剪枝 print(myTree) Testdata_X,Testdata_Y = loadDataSet("ex2test.txt") #获取测试集,开始进行后剪枝 myTree2 = prune(myTree,Testdata_X,Testdata_Y) print(myTree2)
四:模型树实现
(一)实现模型树叶节点生成函数和误差计算函数
import numpy as np import matplotlib.pyplot as plt def linearSolve(data_X,data_Y): X = np.c_[np.ones(data_X.shape[0]), data_X] XTX = X.T @ X if np.linalg.det(XTX) == 0: raise NameError("this matrix can`t inverse") W = np.linalg.inv(XTX) @ (X.T @ data_Y) return W,X,data_Y def modelLeaf(data_X,data_Y): W,X,Y = linearSolve(data_X,data_Y) return W def modelErr(data_X,data_Y): W,X,Y = linearSolve(data_X,data_Y) yPred = X@W return sum(np.power(yPred-data_Y,2))
(二)修改原有函数
def binSplitDataSet(data_X,data_Y,fea_axis,fea_val): #进行数据集划分 dataGtIdx = np.where(data_X[:,fea_axis]>fea_val) dataLgIdx = np.where(data_X[:,fea_axis]<=fea_val) return data_X[dataGtIdx],data_Y[dataGtIdx],data_X[dataLgIdx],data_Y[dataLgIdx] def chooseBestSplit(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): """ 选取的最好切分方式,使用回调方式调用叶节点计算和误差计算,函数中含有预剪枝操作 :param data_X: 传入数据集 :param data_Y: 传入标签值 :param leafType: 要调用计算的叶节点值 --- 虽然灵活,但是没必要 :param errType: 要计算误差的函数,这里是均方误差 --- 虽然灵活,但是没必要 :param ops: 包含了两个重要信息, tolS tolN用于控制函数的停止时机,tolS是容许的误差下降值,误差小于则不再切分,tosN是切分的最少样本数 :return: """ m,n = data_X.shape tolS = ops[0] tolN = ops[1] #之前都是将判断是否继续划分子树放入createTree方法中,这里可以提到chooseBestSplit中进行判别。 #当然可以放入createTree方法中处理 if np.unique(data_Y).size == 1: #1.如果标签值全部相同,则返回特征None表示不需要进行下一步划分,返回叶节点 return None,leafType(data_X,data_Y) #遍历获取最优特征和特征值 TosErr = errType(data_X,data_Y) #获取全部数据集的误差,后面计算划分后两个子集的总误差,如果误差下降小于tolS,则不进行划分,返回该叶子节点即可(预剪枝操作) bestErr = np.inf bestFeaIdx = 0 #注意:这里两个我们设置为0,而不是-1,因为我们必须保证可以取到一个特征(后面循环可能一直continue),我们需要在后面进行额外处理 bestFeaVal = 0 for i in range(n): #遍历所有特征 for feaval in np.unique(data_X[:,i]): dataGt_X,dataGt_Y,dataLg_X,dataLg_Y = binSplitDataSet(data_X,data_Y,i,feaval) #数据集划分 # print(dataGt_X.shape,dataLg_X.shape) if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: #不符合最小数据集,不进行计算 continue concErr = errType(dataLg_X,dataLg_Y)+errType(dataGt_X,dataGt_Y) # print(concErr) if concErr < bestErr: bestFeaIdx = i bestFeaVal = feaval bestErr = concErr #2.如果最后求解的误差,小于我们要求的误差距离,则不进行下一步划分数据集(预剪枝) if (TosErr - bestErr) < tolS: return None,leafType(data_X,data_Y) #3.如果我们上面的数据集本身较小,则无论如何切分,数据集都<tolN,我们就需要在这里再处理一遍,进行一下判断 dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, bestFeaIdx, bestFeaVal) # 数据集划分 if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: # 不符合最小数据集,不进行计算 return None,leafType(data_X,data_Y) return bestFeaIdx,bestFeaVal #正常情况下的返回结果 def createTree(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): #建立回归树 feaIdx,feaVal = chooseBestSplit(data_X,data_Y,leafType,errType,ops) if feaIdx == None: #是叶子节点 return feaVal #递归建树 myTree = {} myTree['feaIdx'] = feaIdx myTree['feaVal'] = feaVal dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, feaIdx, feaVal) # 数据集划分 myTree['left'] = createTree(dataGt_X,dataGt_Y,leafType,errType,ops) myTree['right'] = createTree(dataLg_X,dataLg_Y,leafType,errType,ops) return myTree #开启后剪枝处理 def isTree(tree): return type(tree) == dict #是树的话返回字典,否则是数据 def getMean(tree): #获取当前树的合并均值REP---塌陷处理: 我们对一棵树进行塌陷处理,就是递归将这棵树进行合并返回这棵树的平均值。 if isTree(tree['right']): tree['right'] = getMean(tree['right']) if isTree(tree['left']): tree['left'] = getMean(tree['left']) return (tree['left'] + tree['right'])/2 #返回均值 def prune(tree,testData_X,testData_Y): #根据决策树和测试集数据进行后剪枝处理,不能按照训练集进行后剪枝,因为创建决策树时预剪枝操作中已经要求子树误差值小于根节点 #1.若是当测试集数据为空,则不需要后面的子树了,直接进行塌陷处理 if testData_X.shape[0] == 0: return getMean(tree) #2.如果当前测试集不为空,而且决策树含有左/右子树,则需要进入子树中进行剪枝操作---这里我们先将测试集数据划分 if isTree(tree['left']) or isTree(tree['right']): TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #3.根据子树进行下一步剪枝 if isTree(tree['left']): tree['left'] = prune(tree['left'],TestDataGT_X,TestDataGT_Y) #注意:这里是赋值操作,对树进行剪枝 if isTree(tree['right']): tree['right'] = prune(tree['right'],TestDataLG_X,TestDataLG_Y) #注意:这里是赋值操作,对树进行剪枝 #4.如果两个是叶子节点,我们开始计算误差,进行合并 if not isTree(tree['left']) and not isTree(tree['right']): #先划分测试集数据 TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #进行误差比较 #4-1.先获取没有合并的误差 errorNoMerge = np.sum(np.power(TestDataGT_Y-tree['left'],2)) + np.sum(np.power(TestDataLG_Y-tree['right'],2)) #4-2.再获取合并后的误差 treemean = (tree['left'] + tree['right'])/2 #因为是叶子节点,可以直接计算 errorMerge = np.sum(np.power(testData_Y- treemean,2)) #4-3.进行判断 if errorMerge < errorNoMerge: #可以剪枝 print("merging") #打印提示信息 return treemean #返回合并后的塌陷值 else: return tree #不进行合并,返回原树 return tree #返回树(但是该树的子树中可能存在剪枝合并情况由3可以知道
(三)测试函数
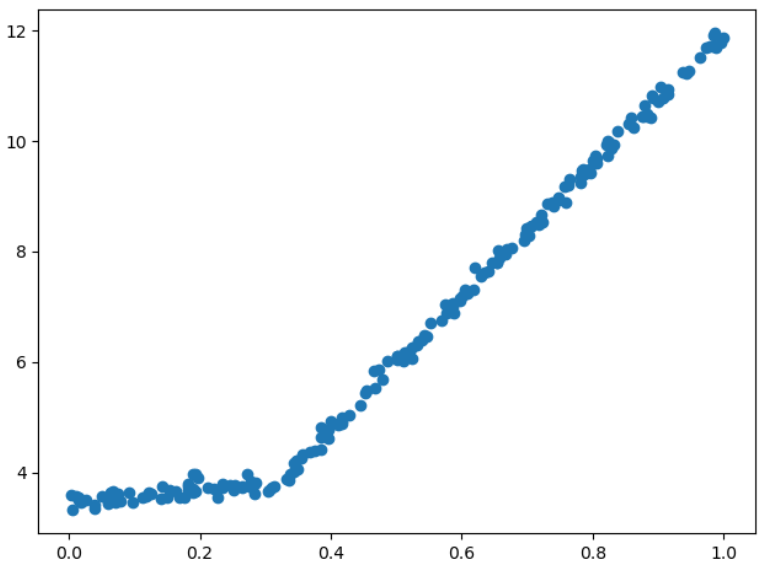
data_X,data_Y = loadDataSet("exp2.txt") myTree = createTree(data_X,data_Y,modelLeaf,modelErr,ops=(1,10)) #设置0,1表示不进行预剪枝,我们只对比后剪枝 print(myTree) plt.figure() plt.scatter(data_X.flatten(),data_Y.flatten()) plt.show()
![]()
五:实现回归树预测,对比决策树和线性回归
由于我上面没有很好的处理回归树和模型树的参数保持一致性,所以这里我对每一个预测使用不同代码(就是同上面一样,各自改变了参数,也可以该一下即可)
(一)实现决策树--回归树和模型树预测函数
#实现预测回归树 def regTreeEval(model,data_X): #对于回归树,直接返回model(预测值),对于模型树,通过model和我们传递的测试集数据进行预测 return model #实现预测模型树 def modelTreeEval(model,data_X): #为了使得回归树和模型树保持一致,所以我们上面为regTreeEval加了data_X X = np.c_[np.ones(data_X.shape[0]),data_X] return X@model #开始递归预测 def treeForeCast(tree,TestData,modelEval=regTreeEval): if not isTree(tree): return modelEval(tree,TestData) #如果是叶子节点,直接返回预测值 if TestData[tree['feaIdx']] > tree['feaVal']: #如果测试集指定特征上的值大于决策树特征值,则进入左子树 if isTree(tree['left']): return treeForeCast(tree['left'],TestData,modelEval) else: #如果左子树是叶子节点,直接返回预测值 return modelEval(tree['left'],TestData) else: #进入右子树 if isTree(tree['right']): return treeForeCast(tree['right'],TestData,modelEval) else: #如果左子树是叶子节点,直接返回预测值 return modelEval(tree['right'],TestData) def createForecast(tree,testData_X,modelEval = regTreeEval): #进行测试集数据预测 m,n = testData_X.shape yPred = np.zeros((m,1)) for i in range(m): #开始预测 yPred[i] = treeForeCast(tree,testData_X[i],modelEval) return yPred
(三)测试回归树预测结果和测试集标签相关性(R2越接近1越好)
import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): dataSet = np.loadtxt(filename) m,n = dataSet.shape data_X = dataSet[:,0:n-1] data_Y = dataSet[:,n-1] return data_X,data_Y def regLeaf(data_Y): #用于计算指定样本中标签均值表示回归y值 return np.mean(data_Y) def regErr(data_Y): #使用均方误差作为划分依据 return np.var(data_Y)*data_Y.size def binSplitDataSet(data_X,data_Y,fea_axis,fea_val): #进行数据集划分 dataGtIdx = np.where(data_X[:,fea_axis]>fea_val) dataLgIdx = np.where(data_X[:,fea_axis]<=fea_val) return data_X[dataGtIdx],data_Y[dataGtIdx],data_X[dataLgIdx],data_Y[dataLgIdx] def chooseBestSplit(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): """ 选取的最好切分方式,使用回调方式调用叶节点计算和误差计算,函数中含有预剪枝操作 :param data_X: 传入数据集 :param data_Y: 传入标签值 :param leafType: 要调用计算的叶节点值 --- 虽然灵活,但是没必要 :param errType: 要计算误差的函数,这里是均方误差 --- 虽然灵活,但是没必要 :param ops: 包含了两个重要信息, tolS tolN用于控制函数的停止时机,tolS是容许的误差下降值,误差小于则不再切分,tosN是切分的最少样本数 :return: """ m,n = data_X.shape tolS = ops[0] tolN = ops[1] #之前都是将判断是否继续划分子树放入createTree方法中,这里可以提到chooseBestSplit中进行判别。 #当然可以放入createTree方法中处理 if np.unique(data_Y).size == 1: #1.如果标签值全部相同,则返回特征None表示不需要进行下一步划分,返回叶节点 return None,leafType(data_Y) #遍历获取最优特征和特征值 TosErr = errType(data_Y) #获取全部数据集的误差,后面计算划分后两个子集的总误差,如果误差下降小于tolS,则不进行划分,返回该叶子节点即可(预剪枝操作) bestErr = np.inf bestFeaIdx = 0 #注意:这里两个我们设置为0,而不是-1,因为我们必须保证可以取到一个特征(后面循环可能一直continue),我们需要在后面进行额外处理 bestFeaVal = 0 for i in range(n): #遍历所有特征 for feaval in np.unique(data_X[:,i]): dataGt_X,dataGt_Y,dataLg_X,dataLg_Y = binSplitDataSet(data_X,data_Y,i,feaval) #数据集划分 # print(dataGt_X.shape,dataLg_X.shape) if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: #不符合最小数据集,不进行计算 continue concErr = errType(dataLg_Y)+errType(dataGt_Y) # print(concErr) if concErr < bestErr: bestFeaIdx = i bestFeaVal = feaval bestErr = concErr #2.如果最后求解的误差,小于我们要求的误差距离,则不进行下一步划分数据集(预剪枝) if (TosErr - bestErr) < tolS: return None,leafType(data_Y) #3.如果我们上面的数据集本身较小,则无论如何切分,数据集都<tolN,我们就需要在这里再处理一遍,进行一下判断 dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, bestFeaIdx, bestFeaVal) # 数据集划分 if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: # 不符合最小数据集,不进行计算 return None,leafType(data_Y) return bestFeaIdx,bestFeaVal #正常情况下的返回结果 def createTree(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): #建立回归树 feaIdx,feaVal = chooseBestSplit(data_X,data_Y,leafType,errType,ops) if feaIdx == None: #是叶子节点 return feaVal #递归建树 myTree = {} myTree['feaIdx'] = feaIdx myTree['feaVal'] = feaVal dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, feaIdx, feaVal) # 数据集划分 myTree['left'] = createTree(dataGt_X,dataGt_Y,leafType,errType,ops) myTree['right'] = createTree(dataLg_X,dataLg_Y,leafType,errType,ops) return myTree #开启后剪枝处理 def isTree(tree): return type(tree) == dict #是树的话返回字典,否则是数据 def getMean(tree): #获取当前树的合并均值REP---塌陷处理: 我们对一棵树进行塌陷处理,就是递归将这棵树进行合并返回这棵树的平均值。 if isTree(tree['right']): tree['right'] = getMean(tree['right']) if isTree(tree['left']): tree['left'] = getMean(tree['left']) return (tree['left'] + tree['right'])/2 #返回均值 def prune(tree,testData_X,testData_Y): #根据决策树和测试集数据进行后剪枝处理,不能按照训练集进行后剪枝,因为创建决策树时预剪枝操作中已经要求子树误差值小于根节点 #1.若是当测试集数据为空,则不需要后面的子树了,直接进行塌陷处理 if testData_X.shape[0] == 0: return getMean(tree) #2.如果当前测试集不为空,而且决策树含有左/右子树,则需要进入子树中进行剪枝操作---这里我们先将测试集数据划分 if isTree(tree['left']) or isTree(tree['right']): TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #3.根据子树进行下一步剪枝 if isTree(tree['left']): tree['left'] = prune(tree['left'],TestDataGT_X,TestDataGT_Y) #注意:这里是赋值操作,对树进行剪枝 if isTree(tree['right']): tree['right'] = prune(tree['right'],TestDataLG_X,TestDataLG_Y) #注意:这里是赋值操作,对树进行剪枝 #4.如果两个是叶子节点,我们开始计算误差,进行合并 if not isTree(tree['left']) and not isTree(tree['right']): #先划分测试集数据 TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #进行误差比较 #4-1.先获取没有合并的误差 errorNoMerge = np.sum(np.power(TestDataGT_Y-tree['left'],2)) + np.sum(np.power(TestDataLG_Y-tree['right'],2)) #4-2.再获取合并后的误差 treemean = (tree['left'] + tree['right'])/2 #因为是叶子节点,可以直接计算 errorMerge = np.sum(np.power(testData_Y- treemean,2)) #4-3.进行判断 if errorMerge < errorNoMerge: #可以剪枝 print("merging") #打印提示信息 return treemean #返回合并后的塌陷值 else: return tree #不进行合并,返回原树 return tree #返回树(但是该树的子树中可能存在剪枝合并情况由3可以知道 #实现预测回归树 def regTreeEval(model,data_X): #对于回归树,直接返回model(预测值),对于模型树,通过model和我们传递的测试集数据进行预测 return model #实现预测模型树 def modelTreeEval(model,data_X): #为了使得回归树和模型树保持一致,所以我们上面为regTreeEval加了data_X X = np.c_[np.ones(data_X.shape[0]),data_X] return X@model #开始递归预测 def treeForeCast(tree,TestData,modelEval=regTreeEval): if not isTree(tree): return modelEval(tree,TestData) #如果是叶子节点,直接返回预测值 if TestData[tree['feaIdx']] > tree['feaVal']: #如果测试集指定特征上的值大于决策树特征值,则进入左子树 if isTree(tree['left']): return treeForeCast(tree['left'],TestData,modelEval) else: #如果左子树是叶子节点,直接返回预测值 return modelEval(tree['left'],TestData) else: #进入右子树 if isTree(tree['right']): return treeForeCast(tree['right'],TestData,modelEval) else: #如果左子树是叶子节点,直接返回预测值 return modelEval(tree['right'],TestData) def createForecast(tree,testData_X,modelEval = regTreeEval): #进行测试集数据预测 m,n = testData_X.shape yPred = np.zeros((m,1)) for i in range(m): #开始预测 yPred[i] = treeForeCast(tree,testData_X[i],modelEval) return yPred data_X,data_Y = loadDataSet("bikeSpeedVsIq_train.txt") #训练集数据 myTree = createTree(data_X,data_Y,ops=(1,20)) #训练集数据建决策模型树 print(myTree) testData_X,testData_Y = loadDataSet('bikeSpeedVsIq_test.txt') #测试集数据 yPred = createForecast(myTree,testData_X) #使用模型树预测 print(np.corrcoef(yPred,testData_Y,rowvar=0)[0,1]) plt.figure() plt.scatter(data_X.flatten(),data_Y.flatten()) plt.show()
data_X,data_Y = loadDataSet("bikeSpeedVsIq_train.txt") #训练集数据 myTree = createTree(data_X,data_Y,ops=(1,20)) #训练集数据建决策模型树 print(myTree) testData_X,testData_Y = loadDataSet('bikeSpeedVsIq_test.txt') #测试集数据 yPred = createForecast(myTree,testData_X) #使用模型树预测 print(np.corrcoef(yPred,testData_Y,rowvar=0)[0,1]) plt.figure() plt.scatter(data_X.flatten(),data_Y.flatten()) plt.show()

(四)测试模型树预测结果和测试集标签相关性(R2越接近1越好)
import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): dataSet = np.loadtxt(filename) m,n = dataSet.shape data_X = dataSet[:,0:n-1] data_Y = dataSet[:,n-1] return data_X,data_Y def regLeaf(data_Y): #用于计算指定样本中标签均值表示回归y值 return np.mean(data_Y) def regErr(data_Y): #使用均方误差作为划分依据 return np.var(data_Y)*data_Y.size def linearSolve(data_X,data_Y): X = np.c_[np.ones(data_X.shape[0]), data_X] XTX = X.T @ X if np.linalg.det(XTX) == 0: raise NameError("this matrix can`t inverse") W = np.linalg.inv(XTX) @ (X.T @ data_Y) return W,X,data_Y def modelLeaf(data_X,data_Y): W,X,Y = linearSolve(data_X,data_Y) return W def modelErr(data_X,data_Y): W,X,Y = linearSolve(data_X,data_Y) yPred = X@W return sum(np.power(yPred-data_Y,2)) def binSplitDataSet(data_X,data_Y,fea_axis,fea_val): #进行数据集划分 dataGtIdx = np.where(data_X[:,fea_axis]>fea_val) dataLgIdx = np.where(data_X[:,fea_axis]<=fea_val) return data_X[dataGtIdx],data_Y[dataGtIdx],data_X[dataLgIdx],data_Y[dataLgIdx] def chooseBestSplit(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): """ 选取的最好切分方式,使用回调方式调用叶节点计算和误差计算,函数中含有预剪枝操作 :param data_X: 传入数据集 :param data_Y: 传入标签值 :param leafType: 要调用计算的叶节点值 --- 虽然灵活,但是没必要 :param errType: 要计算误差的函数,这里是均方误差 --- 虽然灵活,但是没必要 :param ops: 包含了两个重要信息, tolS tolN用于控制函数的停止时机,tolS是容许的误差下降值,误差小于则不再切分,tosN是切分的最少样本数 :return: """ m,n = data_X.shape tolS = ops[0] tolN = ops[1] #之前都是将判断是否继续划分子树放入createTree方法中,这里可以提到chooseBestSplit中进行判别。 #当然可以放入createTree方法中处理 if np.unique(data_Y).size == 1: #1.如果标签值全部相同,则返回特征None表示不需要进行下一步划分,返回叶节点 return None,leafType(data_X,data_Y) #遍历获取最优特征和特征值 TosErr = errType(data_X,data_Y) #获取全部数据集的误差,后面计算划分后两个子集的总误差,如果误差下降小于tolS,则不进行划分,返回该叶子节点即可(预剪枝操作) bestErr = np.inf bestFeaIdx = 0 #注意:这里两个我们设置为0,而不是-1,因为我们必须保证可以取到一个特征(后面循环可能一直continue),我们需要在后面进行额外处理 bestFeaVal = 0 for i in range(n): #遍历所有特征 for feaval in np.unique(data_X[:,i]): dataGt_X,dataGt_Y,dataLg_X,dataLg_Y = binSplitDataSet(data_X,data_Y,i,feaval) #数据集划分 # print(dataGt_X.shape,dataLg_X.shape) if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: #不符合最小数据集,不进行计算 continue concErr = errType(dataLg_X,dataLg_Y)+errType(dataGt_X,dataGt_Y) # print(concErr) if concErr < bestErr: bestFeaIdx = i bestFeaVal = feaval bestErr = concErr #2.如果最后求解的误差,小于我们要求的误差距离,则不进行下一步划分数据集(预剪枝) if (TosErr - bestErr) < tolS: return None,leafType(data_X,data_Y) #3.如果我们上面的数据集本身较小,则无论如何切分,数据集都<tolN,我们就需要在这里再处理一遍,进行一下判断 dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, bestFeaIdx, bestFeaVal) # 数据集划分 if dataGt_X.shape[0] < tolN or dataLg_X.shape[0] < tolN: # 不符合最小数据集,不进行计算 return None,leafType(data_X,data_Y) return bestFeaIdx,bestFeaVal #正常情况下的返回结果 def createTree(data_X,data_Y,leafType=regLeaf,errType=regErr,ops=(1,4)): #建立回归树 feaIdx,feaVal = chooseBestSplit(data_X,data_Y,leafType,errType,ops) if feaIdx == None: #是叶子节点 return feaVal #递归建树 myTree = {} myTree['feaIdx'] = feaIdx myTree['feaVal'] = feaVal dataGt_X, dataGt_Y, dataLg_X, dataLg_Y = binSplitDataSet(data_X, data_Y, feaIdx, feaVal) # 数据集划分 myTree['left'] = createTree(dataGt_X,dataGt_Y,leafType,errType,ops) myTree['right'] = createTree(dataLg_X,dataLg_Y,leafType,errType,ops) return myTree #开启后剪枝处理 def isTree(tree): return type(tree) == dict #是树的话返回字典,否则是数据 def getMean(tree): #获取当前树的合并均值REP---塌陷处理: 我们对一棵树进行塌陷处理,就是递归将这棵树进行合并返回这棵树的平均值。 if isTree(tree['right']): tree['right'] = getMean(tree['right']) if isTree(tree['left']): tree['left'] = getMean(tree['left']) return (tree['left'] + tree['right'])/2 #返回均值 def prune(tree,testData_X,testData_Y): #根据决策树和测试集数据进行后剪枝处理,不能按照训练集进行后剪枝,因为创建决策树时预剪枝操作中已经要求子树误差值小于根节点 #1.若是当测试集数据为空,则不需要后面的子树了,直接进行塌陷处理 if testData_X.shape[0] == 0: return getMean(tree) #2.如果当前测试集不为空,而且决策树含有左/右子树,则需要进入子树中进行剪枝操作---这里我们先将测试集数据划分 if isTree(tree['left']) or isTree(tree['right']): TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #3.根据子树进行下一步剪枝 if isTree(tree['left']): tree['left'] = prune(tree['left'],TestDataGT_X,TestDataGT_Y) #注意:这里是赋值操作,对树进行剪枝 if isTree(tree['right']): tree['right'] = prune(tree['right'],TestDataLG_X,TestDataLG_Y) #注意:这里是赋值操作,对树进行剪枝 #4.如果两个是叶子节点,我们开始计算误差,进行合并 if not isTree(tree['left']) and not isTree(tree['right']): #先划分测试集数据 TestDataGT_X,TestDataGT_Y,TestDataLG_X,TestDataLG_Y = binSplitDataSet(testData_X,testData_Y,tree['feaIdx'],tree['feaVal']) #进行误差比较 #4-1.先获取没有合并的误差 errorNoMerge = np.sum(np.power(TestDataGT_Y-tree['left'],2)) + np.sum(np.power(TestDataLG_Y-tree['right'],2)) #4-2.再获取合并后的误差 treemean = (tree['left'] + tree['right'])/2 #因为是叶子节点,可以直接计算 errorMerge = np.sum(np.power(testData_Y- treemean,2)) #4-3.进行判断 if errorMerge < errorNoMerge: #可以剪枝 print("merging") #打印提示信息 return treemean #返回合并后的塌陷值 else: return tree #不进行合并,返回原树 return tree #返回树(但是该树的子树中可能存在剪枝合并情况由3可以知道 #实现预测回归树 def regTreeEval(model,data_X): #对于回归树,直接返回model(预测值),对于模型树,通过model和我们传递的测试集数据进行预测 return model #实现预测模型树 def modelTreeEval(model,data_X): #为了使得回归树和模型树保持一致,所以我们上面为regTreeEval加了data_X X = np.c_[np.ones(data_X.shape[0]),data_X] return X@model #开始递归预测 def treeForeCast(tree,TestData,modelEval=regTreeEval): if not isTree(tree): return modelEval(tree,TestData) #如果是叶子节点,直接返回预测值 if TestData[tree['feaIdx']] > tree['feaVal']: #如果测试集指定特征上的值大于决策树特征值,则进入左子树 if isTree(tree['left']): return treeForeCast(tree['left'],TestData,modelEval) else: #如果左子树是叶子节点,直接返回预测值 return modelEval(tree['left'],TestData) else: #进入右子树 if isTree(tree['right']): return treeForeCast(tree['right'],TestData,modelEval) else: #如果左子树是叶子节点,直接返回预测值 return modelEval(tree['right'],TestData) def createForecast(tree,testData_X,modelEval = regTreeEval): #进行测试集数据预测 m,n = testData_X.shape yPred = np.zeros((m,1)) for i in range(m): #开始预测 yPred[i] = treeForeCast(tree,testData_X[i],modelEval) return yPred data_X,data_Y = loadDataSet("bikeSpeedVsIq_train.txt") #训练集数据 myTree = createTree(data_X,data_Y,modelLeaf,modelErr,ops=(1,20)) #训练集数据建决策模型树 print(myTree) testData_X,testData_Y = loadDataSet('bikeSpeedVsIq_test.txt') #测试集数据 yPred = createForecast(myTree,testData_X,modelTreeEval) #使用模型树预测 print(np.corrcoef(yPred,testData_Y,rowvar=0)[0,1]) plt.figure() plt.scatter(data_X.flatten(),data_Y.flatten()) plt.show()
data_X,data_Y = loadDataSet("bikeSpeedVsIq_train.txt") #训练集数据 myTree = createTree(data_X,data_Y,modelLeaf,modelErr,ops=(1,20)) #训练集数据建决策模型树 print(myTree) testData_X,testData_Y = loadDataSet('bikeSpeedVsIq_test.txt') #测试集数据 yPred = createForecast(myTree,testData_X,modelTreeEval) #使用模型树预测 print(np.corrcoef(yPred,testData_Y,rowvar=0)[0,1]) plt.figure() plt.scatter(data_X.flatten(),data_Y.flatten()) plt.show()

可以看到模型树优于回归树
(五)一般线性回归
利用我们上面实现的linearSolve方法,获取训练集的参数向量权重即可!!
data_X,data_Y = loadDataSet("bikeSpeedVsIq_train.txt") #训练集数据 testData_X,testData_Y = loadDataSet('bikeSpeedVsIq_test.txt') #测试集数据 W,X,Y = linearSolve(data_X,data_Y) yPred2 = np.zeros((testData_X.shape[0],1)) testDX = np.c_[np.ones(testData_X.shape[0]),testData_X] for i in range(testData_X.shape[0]): yPred2[i] = testDX[i]@W print(np.corrcoef(yPred2,testData_Y,rowvar=0)[0,1])

所以,树回归方法在预测复杂数据时,会比简单的线性模型更加有效

