机器学习实战---朴素贝叶斯算法
一:准备数据
(一)加载原始数据

import numpy as np def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #每一行词表,代表一个文档 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0,1,0,1,0,1] #标签值 1 is abusive, 0 not return postingList,classVec
(二)创建词汇列表 将多个文档单词归为一个
def createVocabList(dataSet): #创建词汇列表 将多个文档单词归为一个 VocabSet = set([]) #使用集合,方便去重 for document in dataSet: VocabSet = VocabSet | set(document) #保持同类型 --- 这里并集导致随机序列出现,所以在下面进行排序,方便对比。 但是单独测试得时候并没有出现随机现象,多次调试,结果唯一,这里每次都不唯一 VocabList = list(VocabSet) VocabList.sort() #列表数据排序 return VocabList
(三)根据我们上面得到的全部词汇列表,将我们输入得inputSet文档向量化
def WordSet2Vec(VocaList,inputSet): #根据我们上面得到的全部词汇列表,将我们输入得inputSet文档向量化 returnVec = [0]*len(VocaList) for word in inputSet: if word in VocaList: returnVec[VocaList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!"%word) return returnVec
(四)数据测试
DocData,classVec = loadDataSet() voclist = createVocabList(DocData) print(voclist) print(WordSet2Vec(voclist,DocData[0])) print(WordSet2Vec(voclist,DocData[3]))

二:根据训练集训练贝叶斯模型
(一)代码实现
def trainNB0(trainMatrix,trainCategory): #训练朴素贝叶斯模型 传入numpy数组类型 trainMatrix所有文档词汇向量矩阵(m*n矩阵 m个文档,每个文档都是n列,代表词汇向量大小),trainCategory每篇文档得标签 numTrainDoc = len(trainMatrix) #文档数量 pC1 = np.sum(trainCategory)/numTrainDoc #p(c1)得概率 p(c0)=1-p(c1) wordVecNum = len(trainMatrix[0]) #因为每个文档转换为词汇向量后都是一样得长度 #初始化p1,p0概率向量 p1VecNum,p0VecNum = np.zeros(wordVecNum),np.zeros(wordVecNum) p1Sum,p0Sum = 0,0 #循环每一个文档 for i in range(numTrainDoc): if trainCategory[i] == 1: #侮辱性文档 p1VecNum += trainMatrix[i] #统计侮辱性文档中,每个单词出现频率 p1Sum += np.sum(trainMatrix[i]) #统计侮辱性文档中出现得全部单词数 每个单词出现概率就是单词出现频率/全部单词 else: #正常文档 p0VecNum += trainMatrix[i] p0Sum += np.sum(trainMatrix[i]) p1Vect = p1VecNum / p1Sum #统计各类文档中的单词出现频率 p0Vect = p0VecNum / p0Sum return p1Vect,p0Vect,pC1
DocData,classVec = loadDataSet() voclist = createVocabList(DocData) #获取全部文档词汇向量矩阵 trainMulList = [] for doc in DocData: trainMulList.append(WordSet2Vec(voclist,doc)) #将我们需要的词汇列表和标签列表转为numpy.ndarray类型 trainMat = np.array(trainMulList) trainClassVec = np.array(classVec) #获取训练模型 p1vec,p0vec,pc1 = trainNB0(trainMat,trainClassVec) print(p1vec) print(p0vec) print(pc1)
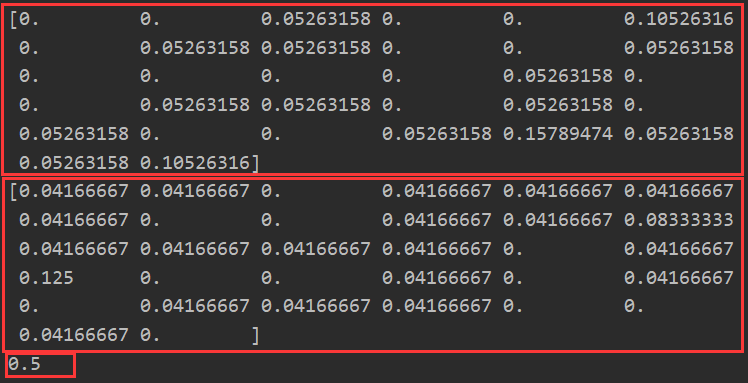
(二)全部代码


import numpy as np def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #每一行词表,代表一个文档 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0,1,0,1,0,1] #标签值 1 is abusive, 0 not return postingList,classVec def createVocabList(dataSet): #创建词汇列表 将多个文档单词归为一个 VocabSet = set([]) #使用集合,方便去重 for document in dataSet: VocabSet = VocabSet | set(document) #保持同类型 VocabList = list(VocabSet) VocabList.sort() return VocabList def WordSet2Vec(VocaList,inputSet): #根据我们上面得到的全部词汇列表,将我们输入得inputSet文档向量化 returnVec = [0]*len(VocaList) for word in inputSet: if word in VocaList: returnVec[VocaList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!"%word) return returnVec def trainNB0(trainMatrix,trainCategory): #训练朴素贝叶斯模型 传入numpy数组类型 trainMatrix所有文档词汇向量矩阵(m*n矩阵 m个文档,每个文档都是n列,代表词汇向量大小),trainCategory每篇文档得标签 numTrainDoc = len(trainMatrix) #文档数量 pC1 = np.sum(trainCategory)/numTrainDoc #p(c1)得概率 p(c0)=1-p(c1) wordVecNum = len(trainMatrix[0]) #因为每个文档转换为词汇向量后都是一样得长度 #初始化p1,p0概率向量 p1VecNum,p0VecNum = np.zeros(wordVecNum),np.zeros(wordVecNum) p1Sum,p0Sum = 0,0 #循环每一个文档 for i in range(numTrainDoc): if trainCategory[i] == 1: #侮辱性文档 p1VecNum += trainMatrix[i] #统计侮辱性文档中,每个单词出现频率 p1Sum += np.sum(trainMatrix[i]) #统计侮辱性文档中出现得全部单词数 每个单词出现概率就是单词出现频率/全部单词 else: #正常文档 p0VecNum += trainMatrix[i] p0Sum += np.sum(trainMatrix[i]) p1Vect = p1VecNum / p1Sum #统计各类文档中的单词出现频率 p0Vect = p0VecNum / p0Sum return p1Vect,p0Vect,pC1 DocData,classVec = loadDataSet() voclist = createVocabList(DocData) #获取全部文档词汇向量矩阵 trainMulList = [] for doc in DocData: trainMulList.append(WordSet2Vec(voclist,doc)) #将我们需要的词汇列表和标签列表转为numpy.ndarray类型 trainMat = np.array(trainMulList) trainClassVec = np.array(classVec) #获取训练模型 p1vec,p0vec,pc1 = trainNB0(trainMat,trainClassVec) print(p1vec) print(p0vec) print(pc1)
三:实现预测函数
(一)更新训练模型函数---拉普拉斯修正和对数防止下溢
def trainNB0(trainMatrix,trainCategory): #训练朴素贝叶斯模型 传入numpy数组类型 trainMatrix所有文档词汇向量矩阵(m*n矩阵 m个文档,每个文档都是n列,代表词汇向量大小),trainCategory每篇文档得标签 numTrainDoc = len(trainMatrix) #文档数量 pC1 = np.sum(trainCategory)/numTrainDoc #p(c1)得概率 p(c0)=1-p(c1) wordVecNum = len(trainMatrix[0]) #因为每个文档转换为词汇向量后都是一样得长度 #初始化p1,p0概率向量---改进为拉普拉斯平滑 p1VecNum,p0VecNum = np.ones(wordVecNum),np.ones(wordVecNum) p1Sum,p0Sum = 2.0,2.0 #N*1 N表示分类数 #循环每一个文档 for i in range(numTrainDoc): if trainCategory[i] == 1: #侮辱性文档 p1VecNum += trainMatrix[i] #统计侮辱性文档中,每个单词出现频率 p1Sum += np.sum(trainMatrix[i]) #统计侮辱性文档中出现得全部单词数 每个单词出现概率就是单词出现频率/全部单词 else: #正常文档 p0VecNum += trainMatrix[i] p0Sum += np.sum(trainMatrix[i]) p1Vect = np.log(p1VecNum / p1Sum) #统计各类文档中的单词出现频率 p0Vect = np.log(p0VecNum / p0Sum) #使用对数避免下溢 return p1Vect,p0Vect,pC1
(二)实现预测函数
def classifyNB(testVec,p0Vec,p1Vec,pC1): p1 = sum(testVec*p1Vec)+np.log(pC1) #使用对数之后变为求和 p0 = sum(testVec*p0Vec)+np.log(1-pC1) if p1 > p0: return 1 else: return 0
(三)设置测试集进行预测
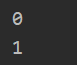
DocData,classVec = loadDataSet() voclist = createVocabList(DocData) #获取全部文档词汇向量矩阵 trainMulList = [] for doc in DocData: trainMulList.append(WordSet2Vec(voclist,doc)) #将我们需要的词汇列表和标签列表转为numpy.ndarray类型 trainMat = np.array(trainMulList) trainClassVec = np.array(classVec) #获取训练模型 p1vec,p0vec,pc1 = trainNB0(trainMat,trainClassVec) #设置测试集进行测试 testEntry01 = ["love","my","dalmation"] VecEntry01 = WordSet2Vec(voclist,testEntry01) clf = classifyNB(VecEntry01,p0vec,p1vec,pc1) print(clf) testEntry02 = ["stupid","garbage"] VecEntry02 = WordSet2Vec(voclist,testEntry02) clf = classifyNB(VecEntry02,p0vec,p1vec,pc1) print(clf)
作者:山上有风景
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2019-07-05 算法习题---4-2正方形(UVa201)
2019-07-05 算法习题---4-1象棋(UVa1589)
2018-07-05 OpenCV---直方图反向投影
2018-07-05 OpenCV---直方图的应用(均衡化和图像比较)
2018-07-05 OpenCV---图像直方图
2018-07-05 OpenCV---边缘保留滤波EPF
2018-07-05 OpenCV---高斯模糊(均值模糊的另一种)