机器学习作业---支持向量机SVM(二)垃圾邮件分类
------------------邮件数据预处理------------------
一:邮件数据读取
with open('emailSample1.txt','r') as fp: content = fp.read() #一次读取了全部数据 print(content)
二:预处理操作
(一)预处理内容
预处理主要包括以下9个部分:

1. 将大小写统一成小写字母;
2. 移除所有HTML标签,只保留内容。
3. 将所有的网址替换为字符串 “httpaddr”.
4. 将所有的邮箱地址替换为 “emailaddr”
5. 将所有dollar符号($)替换为“dollar”.
6. 将所有数字替换为“number”
7. 将所有单词还原为词源,词干提取
8. 移除所有非文字类型
9. 去除空字符串‘’
(二)预处理实现读取邮件
import re import nltk.stem as ns def preprocessing(email): #1. 将大小写统一成小写字母; email = email.lower() #2. 移除所有HTML标签,只保留内容 email = re.sub("<[^<>]>"," ",email) #找到<>标签进行替换,注意:我们匹配的<>标签中内部不能含有<>---<<>>---最小匹配,其他方法也可以实现 #3. 将所有的网址替换为字符串 “httpaddr”. email = re.sub("(http|https)://[^\s]*","httpaddr",email) #匹配网址,直到遇到空格 #4. 将所有的邮箱地址替换为 “emailaddr” email = re.sub('[^\s]+@[^\s]+', 'emailaddr', email) #匹配邮箱 @前后为空为截止 #5. 将所有dollar符号($)替换为“dollar” email = re.sub('[\$]+', 'dollar', email) #6. 将所有数字替换为“number” email = re.sub('[0-9]+', 'number', email) #7. 将所有单词还原为词源,词干提取 https://www.jb51.net/article/63732.htm tokens = re.split('[ \@\$\/\#\.\-\:\&\*\+\=\[\]\?\!\(\)\{\}\,\'\"\>\_\<\;\%]', email) #使用以上字符进行切分内容为单词 tokenlist = [] s = ns.SnowballStemmer('english') #一个词干提取器对象 for token in tokens: #8. 移除所有非文字类型 token = re.sub("[^a-zA-Z0-9]",'',token) #9. 去除空字符串‘’ if not len(token): continue # print("---: ",token) stemmed = s.stem(token) #获取词根 costs变为cost expecting变为expect # print("++++++: ",stemmed) tokenlist.append(stemmed) return tokenlist
with open('emailSample1.txt','r') as fp: content = fp.read() email = preprocessing(content)

(三)将Email转化为词向量
将提取的单词转换成特征向量:
![]()
def email2VocabIndices(email,vocab): """ 提取我们邮件email中的单词,在vocab单词表中出现的索引 """ token = preprocessing(email) #获取预处理后的邮件单词列表 #获取邮件单词在垃圾邮件单词表的索引位置 index_list = [i for i in range(len(vocab)) if vocab[i] in token] return index_list def email2FeatureVector(email): """ 将email转为词向量 """ #读取提供给我们的单词(被认为是垃圾邮件的单词) df = pd.read_table("vocab.txt",names=['words']) #读取数据 vocab = df.values #array类型 # print(vocab) vector = np.zeros(vocab.shape[0]) #查看我们我们的邮件中是否存在这些单词,如果存在则返回索引(是在上面vocab中的索引) index_list = email2VocabIndices(email,vocab) print(index_list) #将单词索引转向量 for i in index_list: vector[i] = 1 return vector
with open('emailSample1.txt','r') as fp: content = fp.read() vector = email2FeatureVector(content) print(vector)
[70, 85, 88, 161, 180, 237, 369, 374, 430, 478, 529, 530, 591, 687, 789, 793, 798, 809, 882, 915, 944, 960, 991, 1001, 1061, 1076, 1119, 1161, 1170, 1181, 1236, 1363, 1439, 1476, 1509, 1546, 1662, 1698, 1757, 1821, 1830, 1892, 1894, 1895] [0. 0. 0. ... 0. 0. 0.]
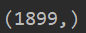
print(vector.shape)
------------------垃圾邮件过滤参数问题(线性核函数)------------------
注意:data/spamTrain.mat是对邮件进行预处理后(自然语言处理)获得的向量。
一:数据读取
data1 = sio.loadmat("spamTrain.mat") X,y = data1['X'],data1['y'].flatten() data2 = sio.loadmat("spamTest.mat") Xtest,ytest = data2['Xtest'],data2['ytest'].flatten()
print(X.shape,y.shape)

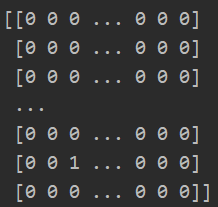
print(X) #每一行代表一个邮件样本,每个样本有1899个特征,特征为1表示在跟垃圾邮件有关的语义库中找到相关单词
print(y) # 每一行代表一个邮件样本,等于1表示为垃圾邮件

这里用于判断垃圾邮件的词汇,还是我们预处理中的vocab.txt的单词。
二:获取最佳准确率和参数C(线性核只有C)
def get_best_params(X,y,Xval,yval): # C 和 σ 的候选值 Cvalues = [3, 0.03, 100, 0.01, 0.1, 0.3, 1, 10, 30] # 9 best_score = 0 #用于存放最佳准确率 best_params = 0 #用于存放参数C for c in Cvalues: clf = svm.SVC(c,kernel='linear') clf.fit(X,y) # 用训练集数据拟合模型 score = clf.score(Xval,yval) # 用验证集数据进行评分 if score > best_score: best_score = score best_params = c return best_score,best_params
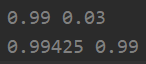
best_score,best_params = get_best_params(X,y,Xtest,ytest) print(best_score,best_params) clf = svm.SVC(best_params,kernel="linear") clf.fit(X,y) score_train = clf.score(X,y) score_test = clf.score(Xtest,ytest) print(score_train,score_test)
三:根据我们训练的结果,判断最有可能被判为垃圾邮件的单词
best_params = 0.3 clf = svm.SVC(best_params,kernel="linear") clf.fit(X,y) #进行训练 # 读取提供给我们的单词(被认为是垃圾邮件的单词) df = pd.read_table("vocab.txt", names=['words']) # 读取数据 vocab = df.values # array类型 #先获取训练结果中,各个特征的重要性 ---- coef_:各特征的系数(重要性)https://www.cnblogs.com/xxtalhr/p/11166848.html print(clf.coef_) indices = np.argsort(clf.coef_).flatten()[::-1] #因为argsort是小到大排序,提取其对应的index(索引),我们设置步长为-1,倒序获取特征系数 print(indices) #打印索引 for i in range(15): #我们获取前15个最有可能判为垃圾邮件的单词 print("{}---{:0.6f}".format(vocab[indices[i]],clf.coef_.flatten()[indices[i]]))
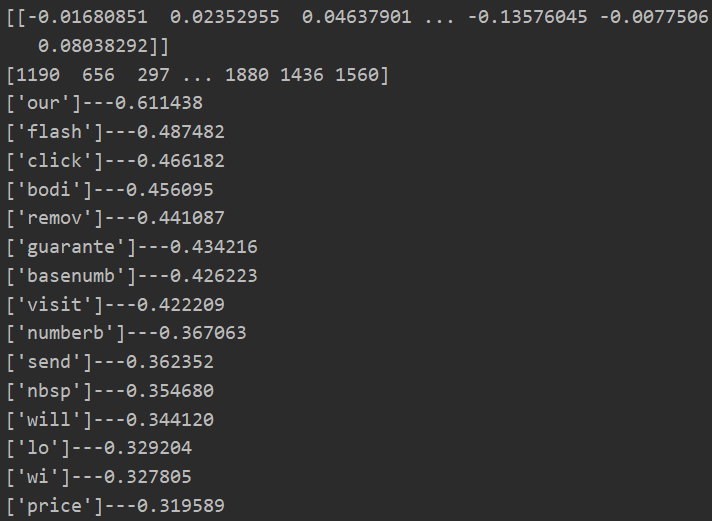
------------------垃圾邮件判断------------------
一:邮件数据
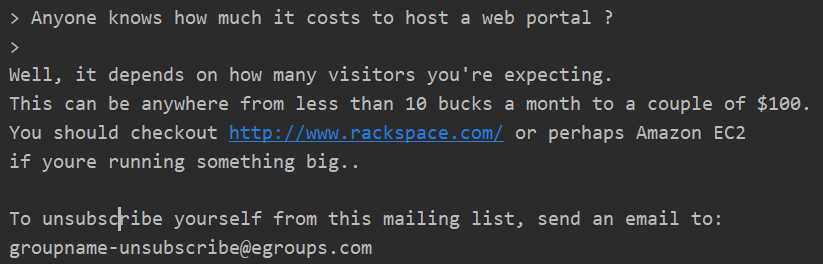
(一)正常邮件


> Anyone knows how much it costs to host a web portal ? > Well, it depends on how many visitors you're expecting. This can be anywhere from less than 10 bucks a month to a couple of $100. You should checkout http://www.rackspace.com/ or perhaps Amazon EC2 if youre running something big.. To unsubscribe yourself from this mailing list, send an email to: groupname-unsubscribe@egroups.com
Folks, my first time posting - have a bit of Unix experience, but am new to Linux. Just got a new PC at home - Dell box with Windows XP. Added a second hard disk for Linux. Partitioned the disk and have installed Suse 7.2 from CD, which went fine except it didn't pick up my monitor. I have a Dell branded E151FPp 15" LCD flat panel monitor and a nVidia GeForce4 Ti4200 video card, both of which are probably too new to feature in Suse's default set. I downloaded a driver from the nVidia website and installed it using RPM. Then I ran Sax2 (as was recommended in some postings I found on the net), but it still doesn't feature my video card in the available list. What next? Another problem. I have a Dell branded keyboard and if I hit Caps-Lock twice, the whole machine crashes (in Linux, not Windows) - even the on/off switch is inactive, leaving me to reach for the power cable instead. If anyone can help me in any way with these probs., I'd be really grateful - I've searched the 'net but have run out of ideas. Or should I be going for a different version of Linux such as RedHat? Opinions welcome. Thanks a lot, Peter -- Irish Linux Users' Group: ilug@linux.ie http://www.linux.ie/mailman/listinfo/ilug for (un)subscription information. List maintainer: listmaster@linux.ie
(二)垃圾邮件
Do You Want To Make $1000 Or More Per Week? If you are a motivated and qualified individual - I will personally demonstrate to you a system that will make you $1,000 per week or more! This is NOT mlm. Call our 24 hour pre-recorded number to get the details. 000-456-789 I need people who want to make serious money. Make the call and get the facts. Invest 2 minutes in yourself now! 000-456-789 Looking forward to your call and I will introduce you to people like yourself who are currently making $10,000 plus per week! 000-456-789 3484lJGv6-241lEaN9080lRmS6-271WxHo7524qiyT5-438rjUv5615hQcf0-662eiDB9057dMtVl72
Best Buy Viagra Generic Online Viagra 100mg x 60 Pills $125, Free Pills & Reorder Discount, Top Selling 100% Quality & Satisfaction guaranteed! We accept VISA, Master & E-Check Payments, 90000+ Satisfied Customers! http://medphysitcstech.ru
二:获取各个邮件的词向量特征(预处理获得)
with open('emailSample1.txt','r') as fp: content = fp.read() with open('emailSample2.txt','r') as fp: content2 = fp.read() with open('spamSample1.txt','r') as fp: content3 = fp.read() with open('spamSample2.txt','r') as fp: content4 = fp.read() vector = email2FeatureVector(content) vector2 = email2FeatureVector(content2) vector3 = email2FeatureVector(content3) vector4 = email2FeatureVector(content4)
三:提供训练的参数,进行预测邮件是否为垃圾邮件
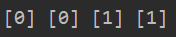
res = clf.predict(np.array([vector])) res2 = clf.predict(np.array([vector2])) res3 = clf.predict(np.array([vector3])) res4 = clf.predict(np.array([vector4])) print(res,res2,res3,res4)
作者:山上有风景
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构