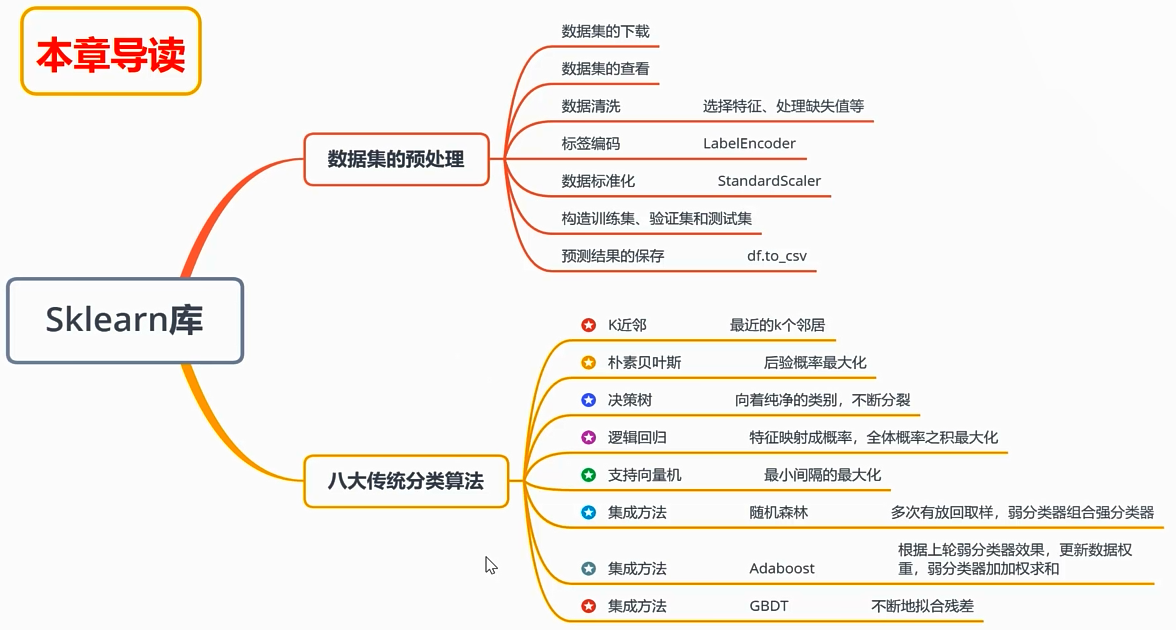
数据分析与展示---SKlearn库的学习
scikit-learn 库是当今最流行的机器学习算法库之一,可用来解决分类与回归问题
一:数据集的预处理
本章以鸢尾花数据集(公开数据集)为例,简单了解八大传统机器学习分类算法的sk-learn实现
(一)数据集的下载
import seaborn as sns #从seaborn库中下载数据集 iris = sns.load_dataset("iris")
如果出错如下:
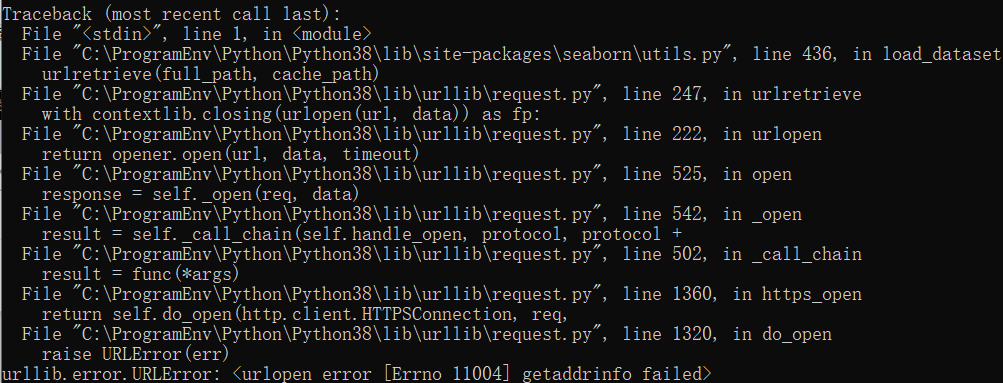
因为对象是https链接,导致出现getaddrinfo出错,解决方法:导入一个ssl模块就可以解决问题
import urllib.request
import ssl ssl._create_default_https_context = ssl._create_unverified_context
import seaborn as sns
iris = sns.load_dataset("iris")
(二)数据集的查看
>>> type(iris)
<class 'pandas.core.frame.DataFrame'>
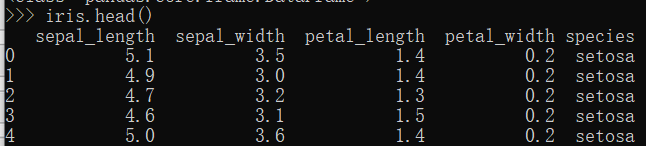
查看前5行数据
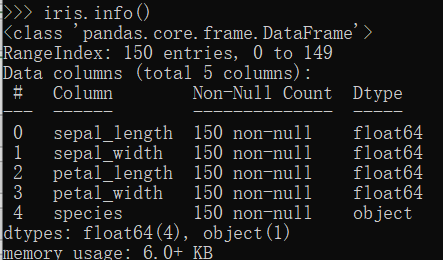
查看汇总信息,没有缺失值
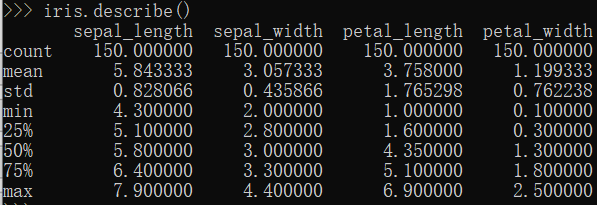
统计的数据信息
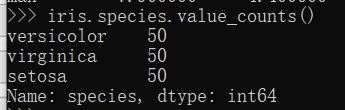
对species字段值进行统计
获取相关性视图


(三)数据清洗
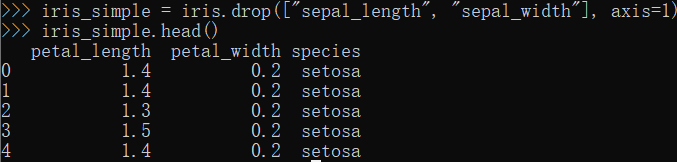
iris_simple = iris.drop(["sepal_length", "sepal_width"], axis=1) #丢弃这两列 iris_simple.head()
(四)标签编码
标签是字符串类型,有一些算法,在训练的时候需要使用到标签值,并且对标签的数据类型有一定的要求,比如:必选是数值类型。因此需要进行标签编码
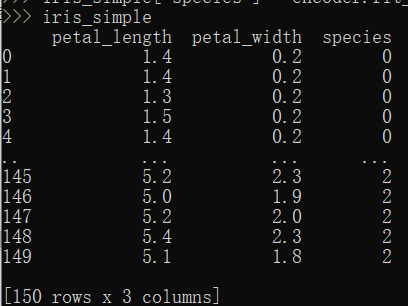
这里的数据集标签一共有3类:--->编码0,1,2
from sklearn.preprocessing import LabelEncoder encoder = LabelEncoder() #构造实例 iris_simple["species"] = encoder.fit_transform(iris_simple["species"]) #进行学习和转换编码
iris_simple
(五)数据的标准化(通过将各个数值保持在0-1之间:(X-X平均值)/(Xmax-Xmin)进行归一化)
有时不同特征之间数组的绝对值差距比较大。10000+,0.000+导致数值较大的将数值较小的特征掩盖掉,并且会影响算法收敛的速度。
from sklearn.preprocessing import StandardScaler #预处理模块中标准化工具StandardScaler import pandas as pd trans = StandardScaler() _iris_simple = trans.fit_transform(iris_simple[["petal_length", "petal_width"]]) #要训练的字段,其中[[]]是DataFrame类型,[]是series类型。返回归一化后的数组
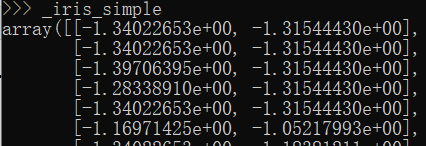
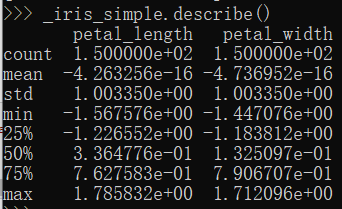
_iris_simple = pd.DataFrame(_iris_simple, columns = ["petal_length", "petal_width"]) #将数据转换为DataFrame类型 _iris_simple.describe() #获取统计信息
(六)构建训练集和测试集(本课暂不考虑验证集)
1.训练集:用于训练算法。得到收敛的模型
2.验证集:用来验证我们训练出来的算法是否足够优秀
3.经过多次训练和验证,得到最后的模型,可以用于测试集中使用
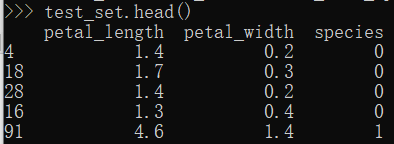
from sklearn.model_selection import train_test_split train_set, test_set = train_test_split(iris_simple, test_size=0.2) #test_size设置全部数据的20%的数据是测试集,80%是训练集 test_set.head() #查看测试集,发现数据选取是随机的
iris_x_test = test_set[["petal_length", "petal_width"]] #将测试集中:这两个字段提取 iris_y_test = test_set["species"].copy() #将标签提取,需要使用copy操作,不能使用视图
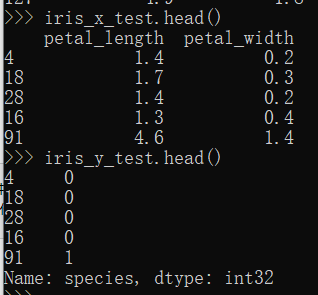
iris_x_train = train_set[["petal_length", "petal_width"]] #将训练集中:这两个字段提取 iris_x_train.head()
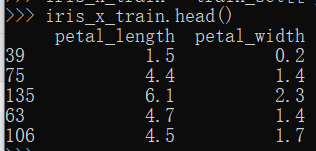
iris_y_train = train_set["species"].copy() #将标签提取,需要使用copy操作,不能使用视图 iris_y_train.head()
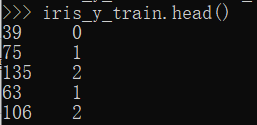
上面操作达到将数据和标签分离的目的:因为训练时,需要分别输入这两个数据集
二:传统分类算法
(一)k近邻算法
将待预测点最近的训练数据集中的k个邻居取出来,把k个近邻中最常见的类别预测为带预测点的类别
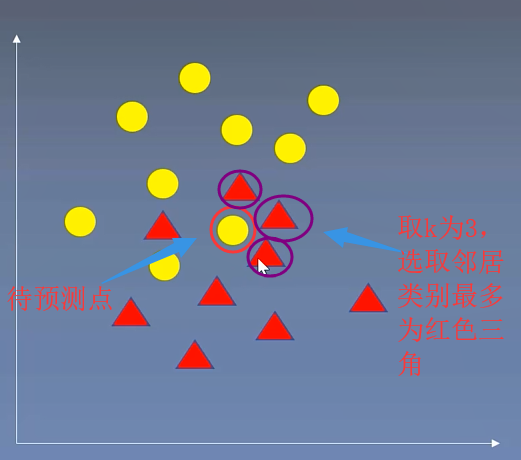
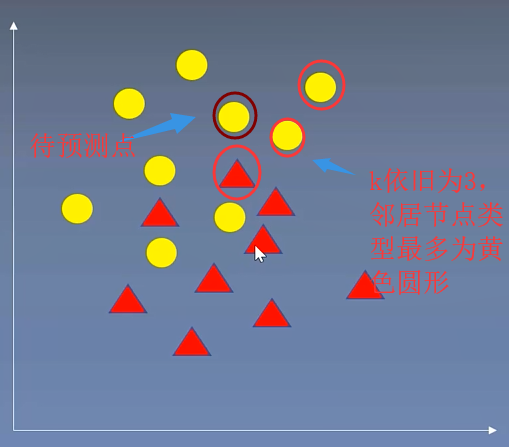
from sklearn.neighbors import KNeighborsClassifier #sklearn库中K邻近算法实现
clf = KNeighborsClassifier() #构建分类器对象
clf

clf.fit(iris_x_train, iris_y_train) #训练集进行训练,传入数据和标签

res = clf.predict(iris_x_test) #测试集进行预测
print(res) #预测结果
print(iris_y_test.values) #测试集正确的标签,与预测结果对比

encoder.inverse_transform(res) #翻转操作,反编码,将标签编码转换为字符串类型

accuracy = clf.score(iris_x_test, iris_y_test) #评估,获取预测准确率 print("预测正确率:{:.0%}".format(accuracy))

out = iris_x_test.copy() #构造DataFrame进行存储 out["y"] = iris_y_test #原来测试集标签 out["pre"] = res #预测的测试集标签 out
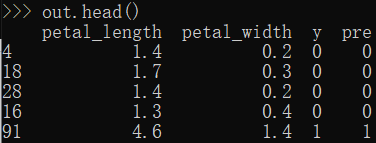
out.to_csv("iris_predict.csv") #将结果存储到本地的csv文件中
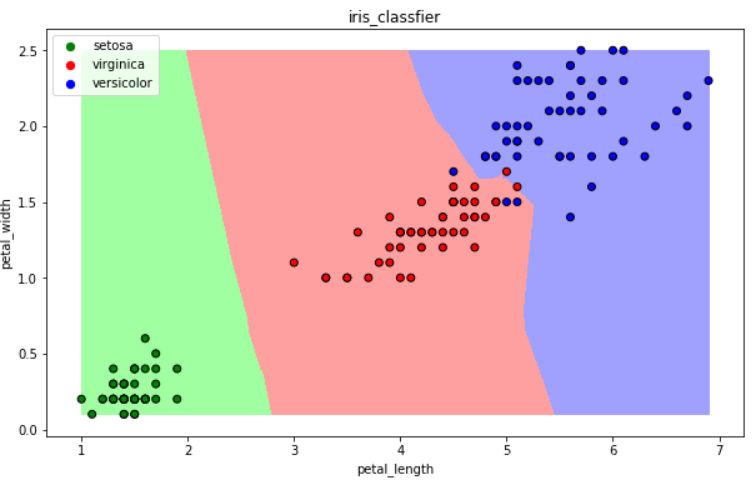
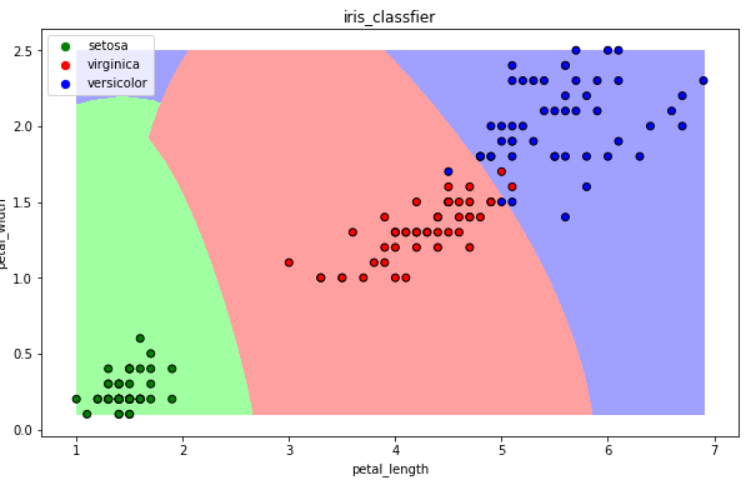
补充:可视化---为3类花,画出明显边界
import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt def draw(clf): # 网格化 M, N = 500, 500 x1_min, x2_min = iris_simple[["petal_length", "petal_width"]].min(axis=0) #将两类特征最大最小,分为500个区域 x1_max, x2_max = iris_simple[["petal_length", "petal_width"]].max(axis=0) t1 = np.linspace(x1_min, x1_max, M) t2 = np.linspace(x2_min, x2_max, N) x1, x2 = np.meshgrid(t1, t2) # 预测 x_show = np.stack((x1.flat, x2.flat), axis=1) y_predict = clf.predict(x_show) # 配色 cm_light = mpl.colors.ListedColormap(["#A0FFA0", "#FFA0A0", "#A0A0FF"]) cm_dark = mpl.colors.ListedColormap(["g", "r", "b"]) # 绘制预测区域图 plt.figure(figsize=(10, 6)) plt.pcolormesh(t1, t2, y_predict.reshape(x1.shape), cmap=cm_light) # 绘制原始数据点 plt.scatter(iris_simple["petal_length"], iris_simple["petal_width"], label=None, c=iris_simple["species"], cmap=cm_dark, marker='o', edgecolors='k') plt.xlabel("petal_length") plt.ylabel("petal_width") # 绘制图例 color = ["g", "r", "b"] species = ["setosa", "virginica", "versicolor"] for i in range(3): plt.scatter([], [], c=color[i], s=40, label=species[i]) # 利用空点绘制图例 plt.legend(loc="best") plt.title('iris_classfier')


import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt def draw(clf): M, N = 500, 500 x1_min, x2_min = iris_simple[["petal_length", "petal_width"]].min(axis=0) x1_max, x2_max = iris_simple[["petal_length", "petal_width"]].max(axis=0) t1 = np.linspace(x1_min, x1_max, M) t2 = np.linspace(x2_min, x2_max, N) x1, x2 = np.meshgrid(t1, t2) x_show = np.stack((x1.flat, x2.flat), axis=1) y_predict = clf.predict(x_show) cm_light = mpl.colors.ListedColormap(["#A0FFA0", "#FFA0A0", "#A0A0FF"]) cm_dark = mpl.colors.ListedColormap(["g", "r", "b"]) plt.figure(figsize=(10, 6)) plt.pcolormesh(t1, t2, y_predict.reshape(x1.shape), cmap=cm_light) plt.scatter(iris_simple["petal_length"], iris_simple["petal_width"], label=None, c=iris_simple["species"], cmap=cm_dark, marker='o', edgecolors='k') plt.xlabel("petal_length") plt.ylabel("petal_width") color = ["g", "r", "b"] species = ["setosa", "virginica", "versicolor"] for i in range(3): plt.scatter([], [], c=color[i], s=40, label=species[i]) plt.legend(loc="best") plt.title('iris_classfier')
draw(clf) #传入训练的模型,进行绘制
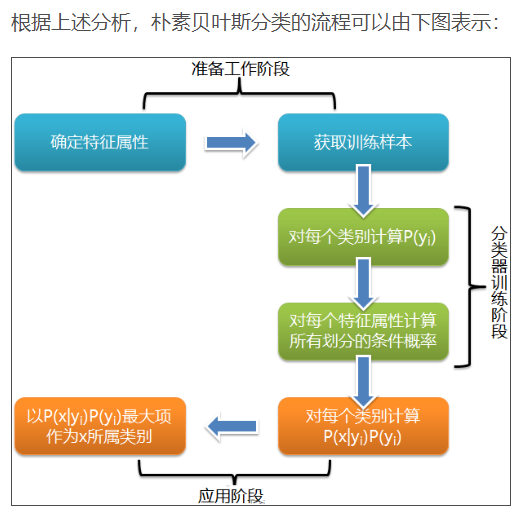
(二)朴素贝叶斯算法
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。

其他详细讲解看:https://blog.csdn.net/guoyunfei20/article/details/78911721
from sklearn.naive_bayes import GaussianNB #sklearn实现 clf = GaussianNB() #构建分类器 clf

clf.fit(iris_x_train, iris_y_train) #训练
res = clf.predict(iris_x_test) #预测
print(res)
print(iris_y_test.values)

accuracy = clf.score(iris_x_test, iris_y_test) #评估 print("预测正确率:{:.0%}".format(accuracy))

draw(clf) #可视化

(三)决策树分类
CART算法:每次通过一个特征,将所有的数据尽可能的分为纯净的两类,递归的分下去
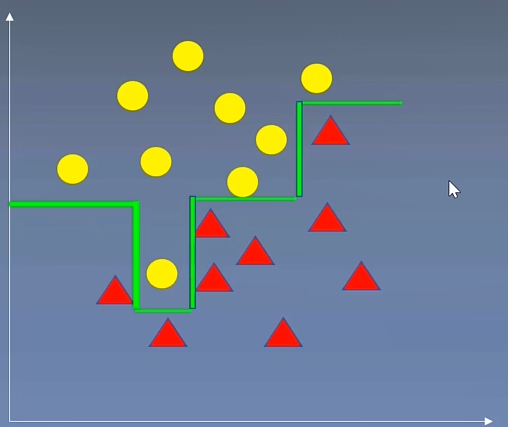
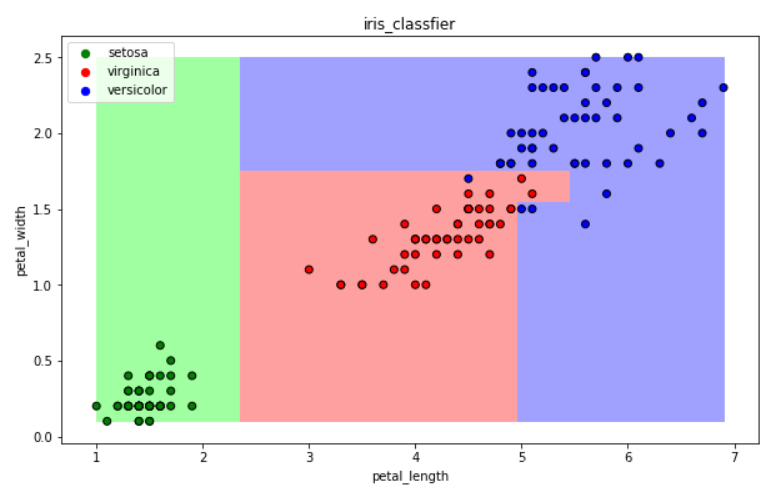
递归获取分类边界,理论上完全分开。但是可能过拟合,导致误差增大
from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier() clf

clf.fit(iris_x_train, iris_y_train) #训练
res = clf.predict(iris_x_test) #预测
print(res)
print(iris_y_test.values)

accuracy = clf.score(iris_x_test, iris_y_test) #评估 print("预测正确率:{:.0%}".format(accuracy))

draw(clf) #可视化
(四)逻辑回归算法
逻辑回归就是一个分类的算法,常见用在二分类当中,就是把我们的输入值在线性回归中转化为预测值,然后映射到Sigmoid 函数中,将值作为x轴的变量,y轴作为一个概率,预测值对应的Y值越接近于1说明完全符合预测结果。但是拟合的越好,不代表效果就越好,有可能拟合过度。
详细见:https://www.cnblogs.com/hum0ro/p/9652674.html(简单理解)
补充见:https://blog.csdn.net/kun_csdn/article/details/88876524(详细推导)

from sklearn.linear_model import LogisticRegression clf = LogisticRegression(solver='saga', max_iter=1000) clf

clf.fit(iris_x_train, iris_y_train) #训练
res = clf.predict(iris_x_test) #预测
print(res)
print(iris_y_test.values)
accuracy = clf.score(iris_x_test, iris_y_test) #评估 print("预测正确率:{:.0%}".format(accuracy))

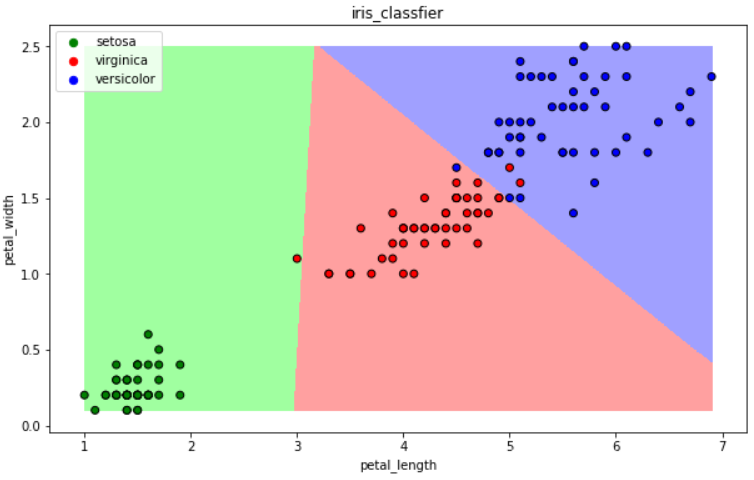
(五)支持向量机算法
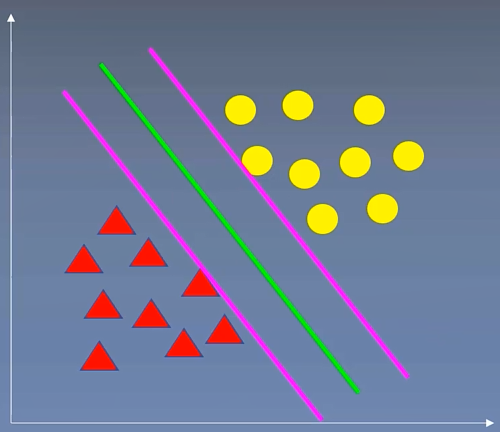
用一个超平面将两类数据完全分开,且最近点到平面的距离最大
https://blog.csdn.net/qq_31347869/article/details/88071930
https://zhuanlan.zhihu.com/p/31886934
from sklearn.svm import SVC clf = SVC() clf

clf.fit(iris_x_train, iris_y_train) #训练
res = clf.predict(iris_x_test) #预测
print(res)
print(iris_y_test.values)
accuracy = clf.score(iris_x_test, iris_y_test) #评估 print("预测正确率:{:.0%}".format(accuracy))
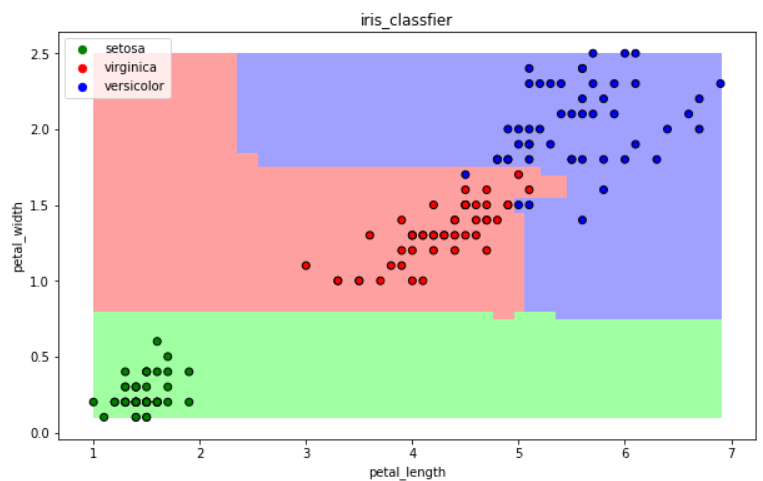
(六)集成方法---随机森林
训练集m,有放回的随机抽取m个数据,构成一组,共抽取n组采样集
n组采样集训练得到n个弱分类器 弱分类器一般用决策树或神经网络
将n个弱分类器进行组合得到强分类器
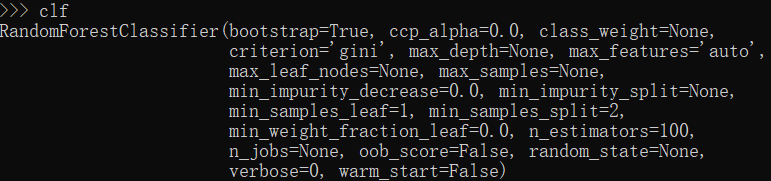
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier() clf
clf.fit(iris_x_train, iris_y_train) #训练
res = clf.predict(iris_x_test) #预测
print(res)
print(iris_y_test.values)
accuracy = clf.score(iris_x_test, iris_y_test) #评估 print("预测正确率:{:.0%}".format(accuracy))
(七)集成方法——Adaboost
训练集m,用初始数据权重训练得到第一个弱分类器,根据误差率计算弱分类器系数,更新数据的权重
使用新的权重训练得到第二个弱分类器,以此类推
根据各自系数,将所有弱分类器加权求和获得强分类器
from sklearn.ensemble import AdaBoostClassifier clf = AdaBoostClassifier() clf

clf.fit(iris_x_train, iris_y_train) #训练
res = clf.predict(iris_x_test) #预测
print(res)
print(iris_y_test.values)
accuracy = clf.score(iris_x_test, iris_y_test) #评估 print("预测正确率:{:.0%}".format(accuracy))
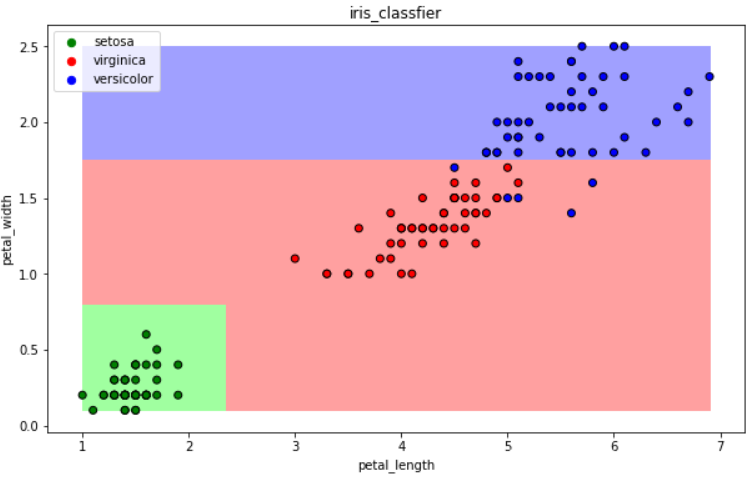
(八)集成方法——梯度提升树GBDT
训练集m,获得第一个弱分类器,获得残差,然后不断地拟合残差
所有弱分类器相加得到强分类器
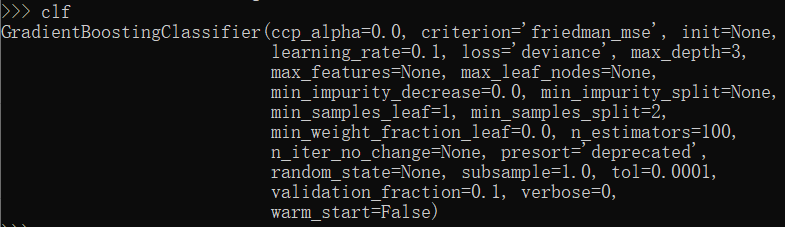
from sklearn.ensemble import GradientBoostingClassifier clf = GradientBoostingClassifier() clf
clf.fit(iris_x_train, iris_y_train) #训练
res = clf.predict(iris_x_test) #预测
print(res)
print(iris_y_test.values)
accuracy = clf.score(iris_x_test, iris_y_test) #评估 print("预测正确率:{:.0%}".format(accuracy))
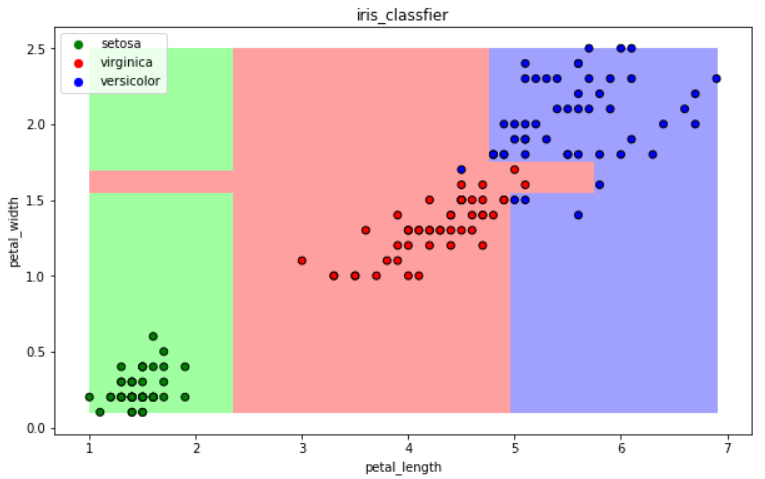
三:补充其他算法(大杀器)
(一)xgboost
GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开
XGBoost损失函数对误差部分做二阶泰勒展开
更加准确,更快收敛
(二)lightgbm
微软:快速的,分布式的,高性能的基于决策树算法的梯度提升框架
速度更快
(三)stacking
堆叠或者叫模型融合
先建立几个简单的模型进行训练,第二级学习器会基于前级模型的预测结果进行再训练
