SparkStreaming工作原理
一:SparkCore,SparkSQL和SparkStreaming的类似之处

(一)SparkCore
Spark Core主要是作为离线批处理(Batch Processing),每次处理的数据都是一个固定的数据集,而不是变化的
相关概念:
RDD:弹性分布式数据集
Spark Context:Spark的上下文,它负责与程序和spark集群进行交互,包括申请集群资源、创建RDD、accumulators及广播变量等。
(二)Spark SQL
Spark SQL用于交互式处理(interactive Processing),同样的,每次处理的数据都是一个固定的数据集,而不是变化的
相关概念:
DataFrame=RDD+Schema
DataFrame:相当于一个Row类型的DataSet,在Spark 2.x之后推荐使用DataSet
SQLContext:SQL的上下文
(三)Spark Streaming
Spark Streaming是一个流式数据处理(Stream Processing)的框架,要处理的数据就像流水一样源源不断的产生,就需要实时处理。
在Spark Streaming中,对于Spark Core进行了API的封装和扩展,将流式的数据切分为小批次(batch,称之为微批,按照时间间隔切分)进行处理,可以用于进行大规模、高吞吐量、容错的实时数据流的处理。---同Storm相比:Storm是来一条数据处理一条数据,是真正意义上的实时处理
支持从很多种数据源中读取数据,使用算子来进行数据处理,处理后的数据可以被保存到文件系统、数据库等存储中
相关概念:
DStream:离散流,相当于是一个数据的集合
StreamingContext:在创建StreamingContext的时候,会自动的创建SparkContext对象
对于电商来说,每时每刻都会产生数据(如订单,网页的浏览数据等),这些数据就需要实时的数据处理

将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果并展示。
二:Spark Streaming组成部分
(一)数据源
大多情况从Kafka中获取数据,还可以从Flume中直接获取,还能从TCP Socket中获取数据(一般用于开发测试)
(二)数据处理
主要通过DStream针对不同的业务需求使用不同的方法(算子)对数据进行相关操作。
企业中最多的两种类型统计:实时累加统计(如统计某电商销售额)会用到DStream中的算子updateStateBykey、实时统计某段时间内的数据(如对趋势进行统计分析,实时查看最近20分钟内各个省份用户点击广告的流量统计)会用到reduceByKeyAndWindow这个算子。
(三)存储结果
调用RDD中的API将数据进行存储,因为Spark Streaming是将数据分为微批处理的,所以每一批次就相当于一个RDD。
可以把结果存储到Console(控制台打印,开发测试)、Redis(基于内存的分布式Key-Value数据库)、HBase(分布式列式数据库)、RDBMS(关系型数据库,如MySQL,通过JDBC)
三:SparkStreaming的运行流程
(一)运行流程图
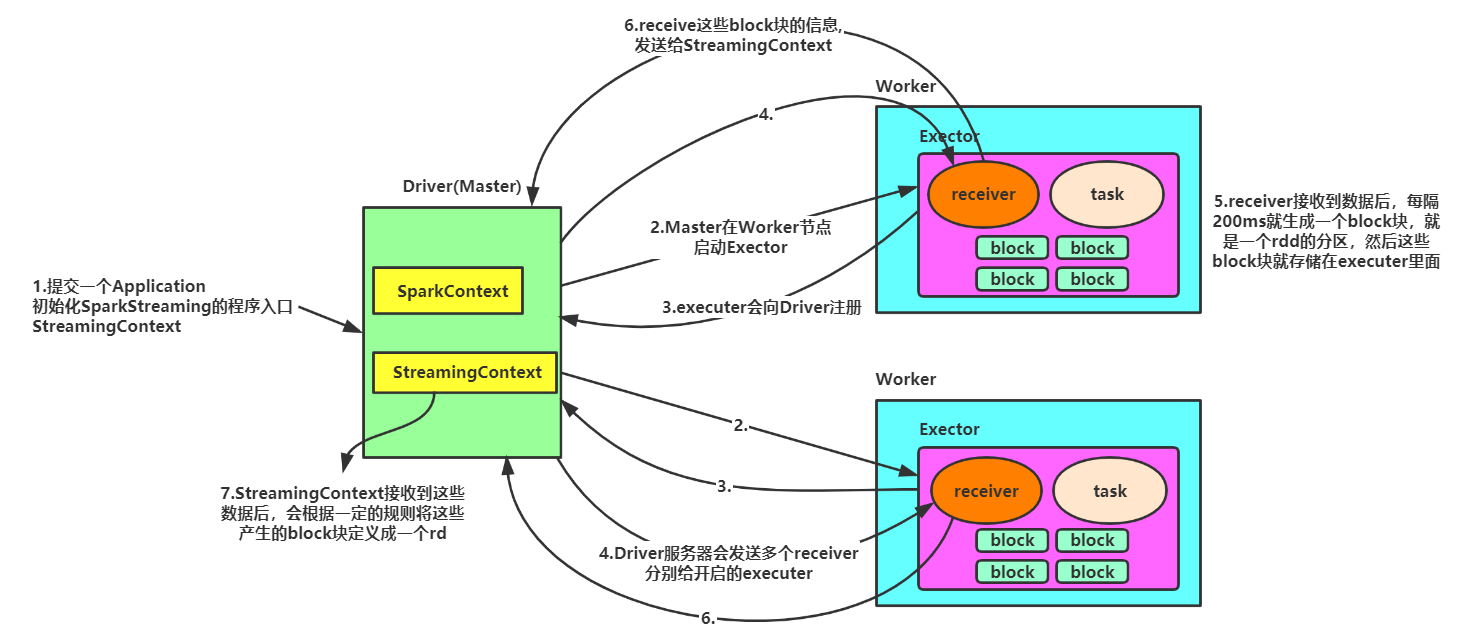
(二)运行流程
1、我们在集群中的其中一台机器上提交我们的Application Jar,然后就会产生一个Application,开启一个Driver,然后初始化SparkStreaming的程序入口StreamingContext;
2、Master(Driver是spark作业的Master)会为这个Application的运行分配资源,在集群中的一台或者多台Worker上面开启Executer,executer会向Driver注册;
3、Driver服务器会发送多个receiver给开启的executer,(receiver是一个接收器,是用来接收消息的,在excuter里面运行的时候,其实就相当于一个task任务)
每个作业包含多个Executor,每个Executor以线程的方式运行task,Spark Streaming至少包含一个receiver task。
4、receiver接收到数据后,每隔200ms就生成一个block块,就是一个rdd的分区,然后这些block块就存储在executer里面,block块的存储级别是Memory_And_Disk_2;
5、receiver产生了这些block块后会把这些block块的信息发送给StreamingContext;
6、StreamingContext接收到这些数据后,会根据一定的规则将这些产生的block块定义成一个rdd;
四:Spark Streaming工作原理
(一)SparkStreaming工作原理
补充:
BlockInterval:200ms 生成block块的依据,多久内的数据生成一个block块,默认值200ms生成一个block块,官网最小推荐值50ms。
BatchInterval:1s 我们将每秒的数据抽象为一个RDD。那么这个RDD里面包含了多个block(1s则是50个RDD),这些block是分散的存储在各个节点上的。
Spark Streaming内部的基本工作原理:

(二)SparkStreaming和Storm对比

1.对比优势
2.应用场景


1、建议在那种需要纯实时,不能忍受1s以上延迟的场景下使用,比如金融系统,要求纯实时进行金融交易和分析; 2、如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Strom; 3、如果需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源,也可以考虑用Storm; 4、如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么使用Storm是比较好的选择
1、如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming; 2、考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
五:DStream离散流
DStream可以通过输入数据源来创建,比如Kafka、Flume,也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window;
(一)DStream原理(与四中补充信息有关联)
DStream的内部,其实是一系列持续不断产生的RDD,RDD是Spark Core的核心抽象,即,不可变的,分布式的数据集;
DStream中的每个RDD都包含了一个时间段内的数据;
(二)DStream算子工作
对DStream应用的算子,其实在底层会被翻译为对DStream中每个RDD的操作。

(三)DStream算子
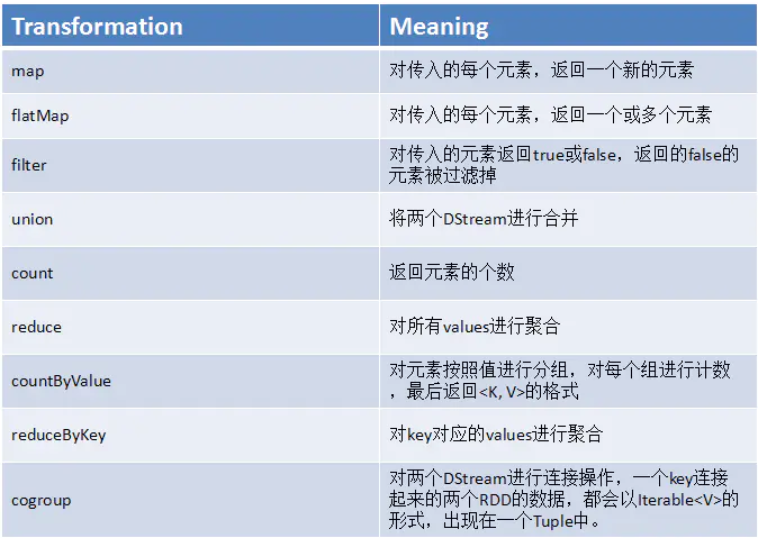
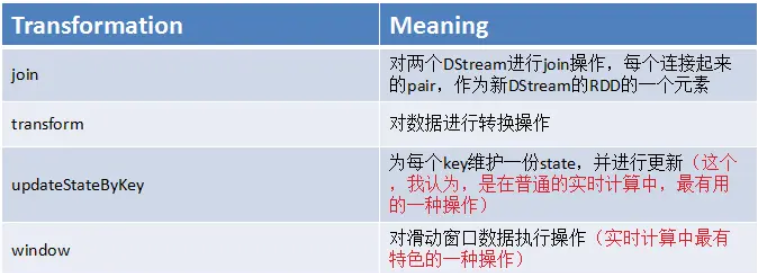
六:StreamingContext的使用
(一)StreamingContext的创建
1.直接使用sparkconf配置创建
val conf = new SparkConf().setAppName(appName).setMaster("local"); val ssc = new StreamingContext(conf, Seconds(1));
2.使用已创建的sparkcontext创建
val sc = new SparkContext(conf) val ssc = new StreamingContext(sc, Seconds(1)); //batch interval可以根据你的应用程序的延迟要求以及可用的集群资源情况来设置
(二)StreamingContext的使用
1.通过创建输入DStream来创建输入数据源。
2.通过对DStream定义transformation和output算子操作,来定义实时计算逻辑。
3.调用StreamingContext的start()方法,来开始实时处理数据。
4.调用StreamingContext的awaitTermination()方法,来等待应用程序的终止。可以使用CTRL+C手动停止,或者就是让它持续不断的运行进行计算。
5.也可以通过调用StreamingContext的stop()方法,来停止应用程序。
(三)注意事项
1.只要一个StreamingContext启动之后,就不能再往其中添加任何计算逻辑了。比如执行start()方法之后,还给某个DStream执行一个算子。
2.一个StreamingContext停止之后,是肯定不能够重启的,调用stop()之后,不能再调用start()
3.一个JVM同时只能有一个StreamingContext启动,在你的应用程序中,不能创建两个StreamingContext。
4.调用stop()方法时,会同时停止内部的SparkContext,如果不希望如此,还希望后面继续使用SparkContext创建其他类型的Context,比如SQLContext,那么就用stop(false)。
5.一个SparkContext可以创建多个StreamingContext,只要上一个先用stop(false)停止,再创建下一个即可。
七:代码编写
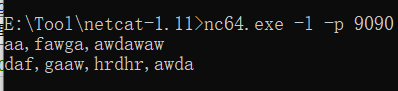
(一)从Socket获取数据---用于测试
def main(args:Array[String]):Unit={ val conf = new SparkConf().setAppName("WordCount").setMaster("local[5]") val sc = new SparkContext(conf) //设置streamingcontext val scc = new StreamingContext(sc,Seconds(2)) //数据输入 val inDStream:ReceiverInputDStream[String] = scc.socketTextStream("localhost", 9090) inDStream.print() //数据打印 //数据处理 val resultDStream:DStream[(String,Int)]=inDStream.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_) //数据输出 resultDStream.print() //启动应用程序 scc.start() scc.awaitTermination() scc.stop() }
nc下载地址:https://eternallybored.org/misc/netcat/,在cmd中使用:
(二)设置hdfs获取数据
scc.textFileStream("hdfs://ns:9000/streaming")
八:缓存与持久化机制
与RDD类似,Spark Streaming也可以让开发人员手动控制,将数据流中的数据持久化到内存中,对DStream调用persist()方法,就可以让Spark Streaming自动将该数据流中的所有产生的RDD都持久化到内存中。如果要对一个DStream多次执行操作,那么,对DSteram持久化是非常有用的。因为多次操作,可以共享使用内存中的一份缓存数据。
对于基础窗口的操作,比如reduceByWindow、reduceByKeyAndWindow,以及基于状态的操作,比如updateStateByKey,默认就隐式开启了持久化机制,即Spark Streaming默认就会将上述操作产生的DStream中的数据,缓存到内存中,不需要开发人员手动调用persist()方法。
对于通过网络接收数据的输入流,比如Socket、Kafka、Flume等,默认的持久化级别是将数据复制一份,以便于容错,相当于用的是MEMORY_ONLY_SER_2。
与Spark Core中的RDD不同的是,默认的持久化级别,统一都是要序列化的。
九:Checkpoint机制
每一个Spark Streaming应用,正常来说都是要7x24小时运转的,这就是实时计算程序的特点。要持续不断的对数据进行计算,必须要能够对于应用程序逻辑无关的失败进行容错。
对于一些将多个batch的数据进行聚合的,有状态的transformation操作,这是非常有用的。在这种transformation操作中,生成的RDD是依赖之前的batch中的RDD的,这样就会随着时间的推移,依赖链条越来越长,从而导致失败恢复时间也变得越来越差。有状态的transformation操作执行过程当中产生的RDD要定期的被checkpoint到可靠的存储上,这样做可以消减RDD的依赖链条,从而缩短恢复时间。
当使用了有状态的transformation操作时,必须要开启checkpoint机制,提供checkpoint目录。
注意,并不是所有的Spark Streaming应用程序都要启用checkpoint机制
如何启用Checkpoint机制:
1.配置一个文件系统(比如HDFS)的目录,作为checkpoint目录
2.使用StreamingContext的checkpoint方法,填入配置好的目录作为参数即
十: 注意事项
如果要在实时计算应用中并行接收多条数据流,可以创建多个输入DStream,这样就会创建多个Receiver,从而并行地接收多个数据流。这里有一个问题,一个Spark Streaming应用程序的executor是一个长期运行的任务,所以它会独占分配给Spark Streaming应用程序的CPU core,所以只要Spark Streaming运行起来之后,这个节点上的CPU core数就没有办法给其他的应用所使用了,因为会被Receiver所独占。
使用本地模式运行程序时,必须使用local[n],n>=2绝对不能用local和local[1],因为就会给执行输入DStream的executor分配一个线程,Spark Streaming底层的原理需要至少有两个线程,一个线程分配给Receiver接收数据,另一个线程用来处理接收到的数据。如果线程小于2的话,那么程序只会接收数据,不会处理数据。
如果直接将Spark Streaming应用提交到集群上运行,需要保证有足够资源。

