Spark简介及安装
转载自:https://www.cnblogs.com/qingyunzong/p/8886338.html
一:Spark简介
(一)Spark介绍
spark是用于大规模数据处理的统一分析引擎。
spark是一个实现快速通用的集群计算平台。它是由加州大学伯克利分校AMP实验室开发的通用内存并行计算框架,用来构建大型的、低延迟的数据分析应用程序。它扩展了广泛使用的MapReduce计算模型。
高效的支撑更多计算模式,包括交互式查询和流处理。spark的一个主要特点是能够在内存中进行计算,即使依赖磁盘进行复杂的运算,Spark依然比MapReduce更加高效。
(二)Spark组成
Spark组成(BDAS):全称伯克利数据分析栈,通过大规模集成算法、机器、人之间展现大数据应用的一个平台。也是处理大数据、云计算、通信的技术解决方案。
主要组件有:
SparkCore:
将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
SparkSQL:
Spark Sql 是Spark来操作结构化数据的程序包,可以让我使用SQL语句的方式来查询数据,Spark支持 多种数据源,包含Hive表,parquest以及JSON等内容。
SparkStreaming:
是Spark提供的实时数据进行流式计算的组件。
MLlib:
提供常用机器学习算法的实现库。
GraphX:
提供一个分布式图计算框架,能高效进行图计算。
BlinkDB:
用于在海量数据上进行交互式SQL的近似查询引擎。
Tachyon:
以内存为中心高容错的的分布式文件系统。
(三)Spark的特点
1.基于内存,所以速度快,但同时也是缺点,因为Spark没有对内存进行管理,容易OOM(out of memory内存溢出),可以用Java Heap Dump对内存溢出问题进行分析
2.可以使用Scala、Java、Python、R等语言进行开发
3.兼容Hadoop
二:Spark与MapReduce对比
(一)IO输出对比---mapreduce过程中
1.MapReduce最大的缺点,Shuffle过程中会有很多I/O开销,可以看到这里有6个地方会产生IO,而Spark只会在1(写入数据到内存)和6(输出数据)的地方产生I/O,其他的过程都在内存中进行。
Hadoop基础---shuffle机制(进一步理解Hadoop机制)

(二)中间结果输出对比---ResouceManager资源分配中
2.基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。例如:mapreduce出现往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统(如HDFS)来存储每一个Stage的输出结果。Spark可以避免中间结果的输出。
Hadoop基础---shuffle机制(进一步理解Hadoop机制)

(三)Spark是MapReduce的替代方案,兼容Hive、HDFS、融入到Hadoop
三:Spark四大特性
补充:DAG(有向无环图)调度原理
有向无环图(Directed Acyclic Graph, DAG)是有向图的一种,特点是图中没有环。常常被用来表示事件之间的驱动依赖关系,管理任务之间的调度。拓扑排序是对DAG的顶点进行排序,使得对每一条有向边(u, v),均有u(在排序记录中)比v先出现。亦可理解为对某点v而言,只有当v的所有源点均出现了,v才能出现。
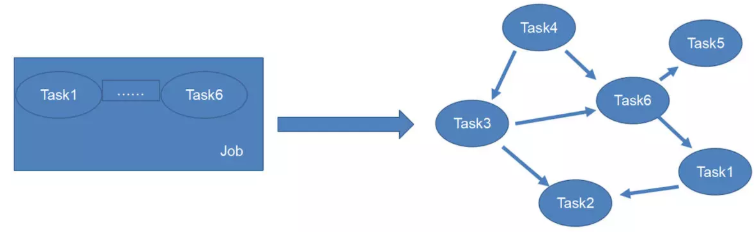
为了描述一个Job内所有Task相互依赖关系,可以将Job中的每个Task对应为一个节点,将一个Job描述为一张有向无环图DAG
有向无环图对于构造一个任务必须发生在另一个任务之前的这种依赖模型特别有效。
有向无环图对于构造一个任务必须发生在另一个任务之前的这种依赖模型特别有效。
(一)高效性---相比较Hadoop,运行速度提高100倍
Apache Spark使用最先进的DAG调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。

(二)易用性---多种语言、算法
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。

(三)通用性---不同应用中
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
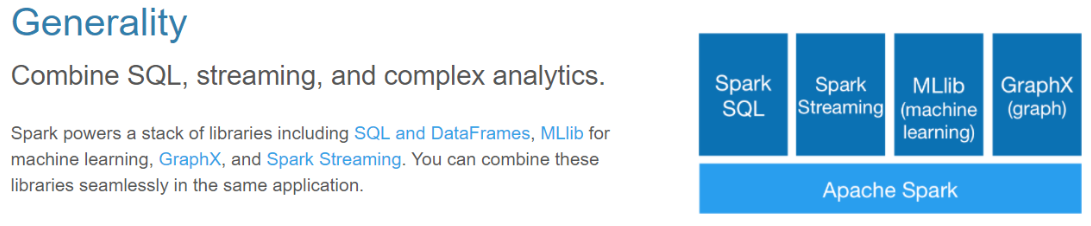
(四)兼容性---其他平台
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。

Mesos:Spark可以运行在Mesos里面(Mesos 类似于yarn的一个资源调度框架)
standalone:Spark自己可以给自己分配资源(master,worker)
YARN:Spark可以运行在yarn上面
Kubernetes:Spark接收 Kubernetes的资源调度
四:Spark应用场景
Yahoo将Spark用在Audience Expansion中的应用,进行点击预测和即席查询等
淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。应用于内容推荐、社区发现等
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上。
优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算。
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上。
优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算。
五:Spark体系结构
(一)Spark体系结构图

Driver Program可以理解为是客户端,而右边的可以理解为服务器端。 Cluster Manager是主节点,主节点并不负责真正任务的执行(负责任务调度),任务的执行由Worker Node完成。
(二)Spark体系结构详细架构图
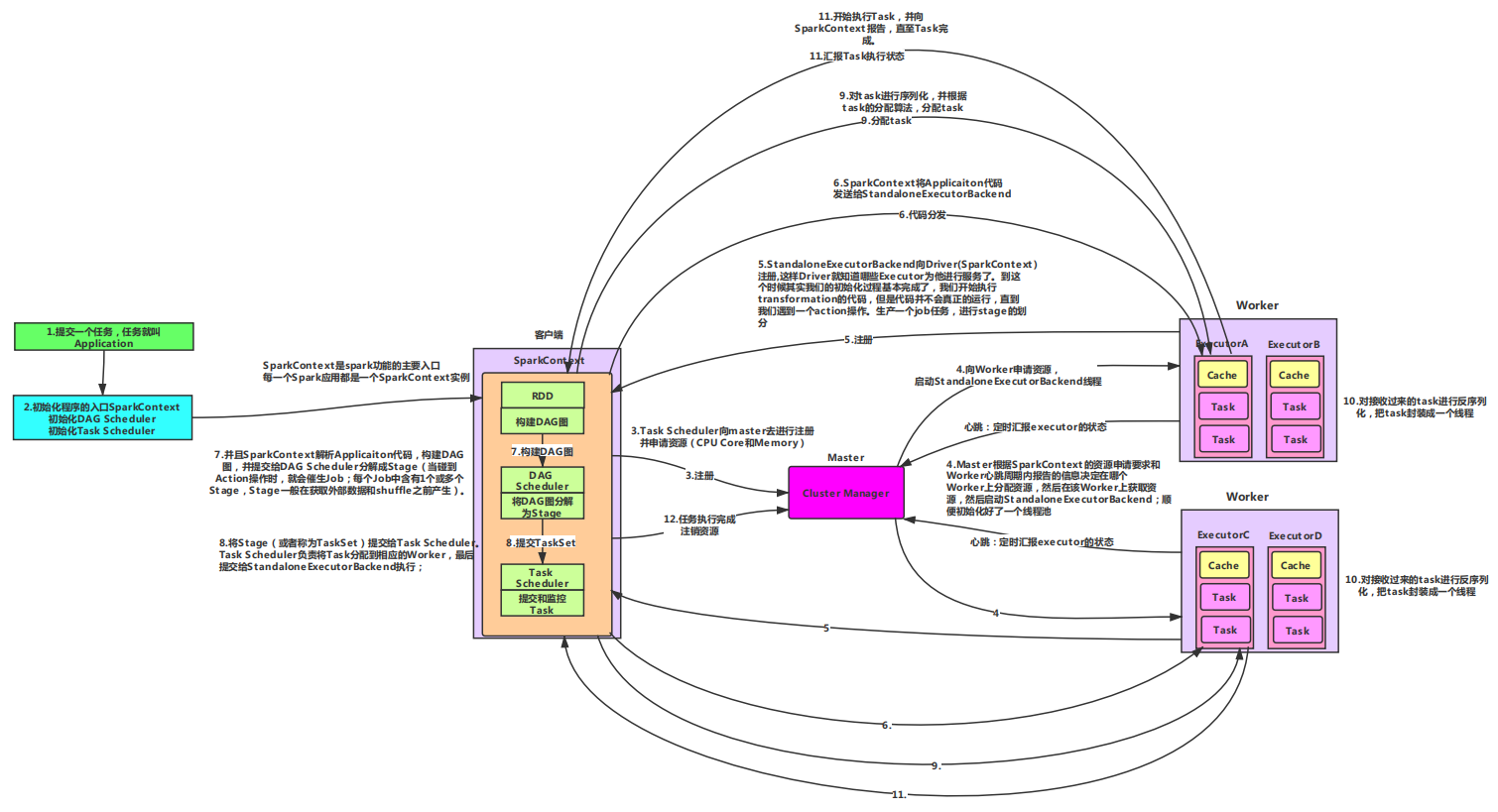
1.我们提交一个任务,任务就叫Application 2.初始化程序的入口SparkContext, 2.1 初始化DAG Scheduler 2.2 初始化Task Scheduler 3.Task Scheduler向master去进行注册并申请资源(CPU Core和Memory) 4.Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;顺便初 始化好了一个线程池 5.StandaloneExecutorBackend向Driver(SparkContext)注册,这样Driver就知道哪些Executor为他进行服务了。 到这个时候其实我们的初始化过程基本完成了,我们开始执行transformation的代码,但是代码并不会真正的运行,直到我们遇到一个action操作。生产一个job任务,进行stage的划分 6.SparkContext将Applicaiton代码发送给StandaloneExecutorBackend; 7.并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作 时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生)。 8.将Stage(或者称为TaskSet)提交给Task Scheduler。Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行; 9.对task进行序列化,并根据task的分配算法,分配task 10.对接收过来的task进行反序列化,把task封装成一个线程 11.开始执行Task,并向SparkContext报告,直至Task完成。 12.资源注销
其他框架下spark运行流程:https://www.cnblogs.com/qingyunzong/p/8945933.html
六: 安装Spark伪分布式环境
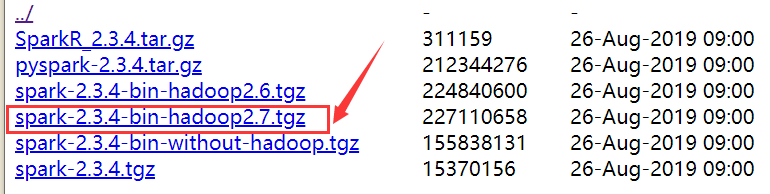
(一)下载Spark
![]()
根据Hadoop版本,选取spark版本下载
http://mirrors.hust.edu.cn/apache/spark/spark-2.3.4/
(二)伪分布式安装
1.安装java环境
2.安装Hadoop环境
Hadoop的安装(2)---Hadoop配置
3.安装Scala
https://www.scala-lang.org/download/all.html
解压,添加环境变量:(修改/etc/profile)文件
![]()
4.spark的安装
tar解压、添加环境变量

注意:由于Hadoop和Spark的脚本有冲突,设置环境变量的时候,只能设置一个
5.修改spark配置文件
cp spark-env.sh.template spark-env.sh #先进入spark根目录下conf目录中
vi spark-env.sh 修改配置文件,在文件末尾添加
export JAVA_HOME=/home/hadoop/App/jdk1.8.0_241 export SCALA_HOME=/home/hadoop/App/scala-2.11.8 export HADOOP_HOME=/home/hadoop/App/hadoop-2.7.1 export HADOOP_CONF_DIR=/home/hadoop/App/hadoop-2.7.1/etc/hadoop export SPARK_MASTER_IP=haddopH1 export SPARK_MASTER_PORT=7077
6.spark启动测试
注意:spark命令,可能和Hadoop冲突,所以使用相对路径或者绝对路径进行启动

7.web访问

七:Spark HA集群环境安装
全分布式的部署与伪分布式类似,在每个节点上都解压压缩包,修改conf/spark-env.sh(稍微有些不同)。在主节点上的slaves文件中填入从节点的主机名,然后在每个节点上启动集群即可。

(一)安装Zookeeper集群---spark Master依赖于zookeeper集群实现HA
(二)Spark安装
1.除了配置文件,其他同伪分布式一致。
2.修改配置文件 spark-env.sh
export JAVA_HOME=/home/hadoop/App/jdk1.8.0_241
#如果没有安装scala,可以不进行配置,照样可以启动 export SCALA_HOME=/home/hadoop/App/scala-2.11.8 export HADOOP_HOME=/home/hadoop/App/hadoop-2.7.1 export HADOOP_CONF_DIR=/home/hadoop/App/hadoop-2.7.1/etc/hadoop export SPARK_WORKER_MEMORY=500m export SPARK_WORKER_CORES=1 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoopH5:2181,hadoopH6:2181,hadoopH7:2181 -Dspark.deploy.zookeeper.dir=/spark"
-Dspark.deploy.zookeeper.dir是保存spark的元数据,保存了spark的作业运行状态;
zookeeper会保存spark集群的所有的状态信息,包括所有的Workers信息,所有的Applactions信息,所有的Driver信息,如果集群
3.修改配置文件 slaves
hadoopH5
hadoopH6
hadoopH7
(三)将安装目录拷贝到其他节点
拷贝文件目录到hadoopH2,hadoopH3,hadoopH5,hadoopH6,hadoopH7。
(四)启动zookeeper集群

(五)启动HDFS集群
start-dfs.sh
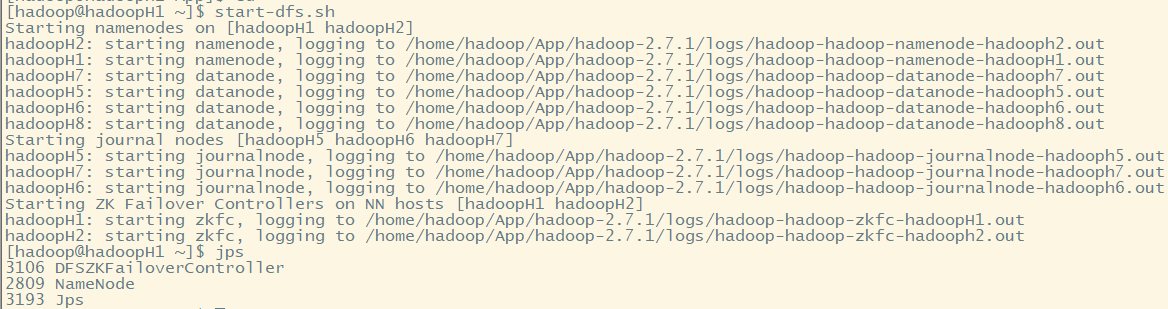
(六)启动Spark集群
start-all.sh

只启动了本机Master和slaves下的worker进程



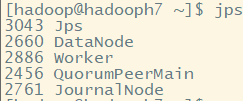
需要手动启动其他几个主机中的Master,其他节点都要执行:
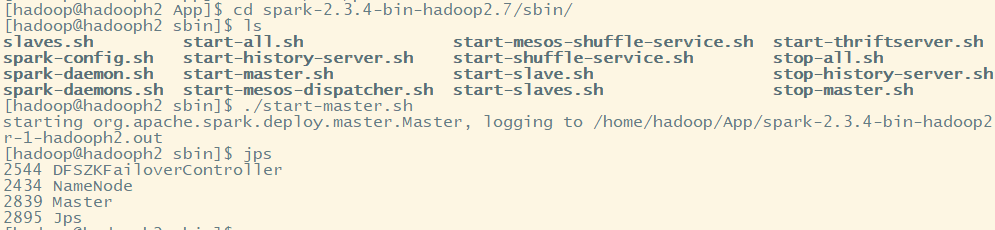
(七)启动验证
1.web查看Master状态


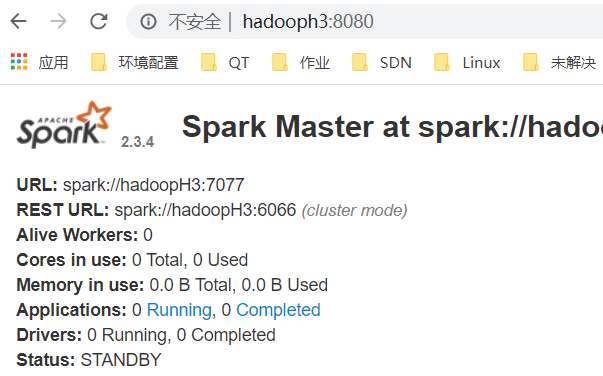
2.HA验证。kill hadoopH1 后,hadoopH2变成alive状态

八:Spark shell使用
(一)启动Spark shell

spark-shell --master spark://hadoopH1:7077 --executor-memory 500m --total-executor-cores 1
至少分配450m内存大小,负责可能报错!!

(二) 参数说明
--master spark://hadoop1:7077 指定Master的地址 --executor-memory 500m:指定每个worker可用内存为500m --total-executor-cores 1: 指定整个集群使用的cpu核数为1个
(三)重点补充
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
Spark Shell中已经默认将SparkSQl类初始化为对象spark。用户代码如果需要用到,则直接应用spark即可
(四)在spark shell中实现wordcount程序
1.上传文件到hdfs中

补充:当hadoop无法对hdfs修改时,出现: Name node is in safe mode
hadoop dfsadmin -safemode leave
退出安全模式
2.使用scala语言,编写spark程序
sc.textFile("/spark/input/c.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/spark/output")
![]()

参数说明:
sc是SparkContext对象,该对象是提交spark程序的入口 textFile("/spark/input/c.txt") 从hdfs中读取数据 flatMap(_.split(" ")) 先字符串分割,后map map((_,1)) 将单词和1构成map reduceByKey(_+_)按照key进行reduce,并将value累加 saveAsTextFile("/spark/out")将结果写入到hdfs中
九:Spark在不同框架运行
(一)执行Spark程序on standalone
spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoopH1:7077 --executor-memory 500m --total-executor-cores 1 ../examples/jars/spark-examples_2.11-2.3.4.jar 100
后面100是指进行100次运算

(二)执行Spark程序on YARN
1.需要我们启动hdfs、yarn、zookeeper集群
2.启动Spark on YARN
spark-shell --master yarn --deploy-mode client
3.内存太小导致SparkContext初始化错误,问题解决:
先停止YARN服务,然后修改yarn-site.xml,增加如下内容:
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>

将新的yarn-site.xml文件分发到其他Hadoop节点对应的目录下,最后在重新启动YARN。
4. 打开YARN的web界面,查看Spark shell应用程序
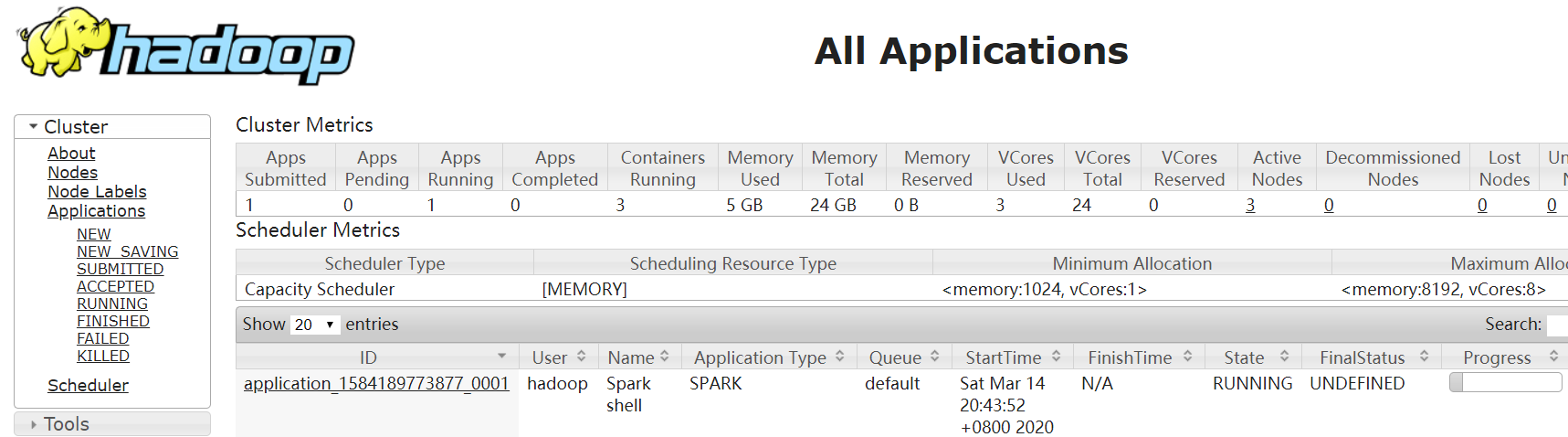

5.在spark shell中运行程序
scala> val array = Array(1,2,3,4,5) array: Array[Int] = Array(1, 2, 3, 4, 5) scala> val rdd = sc.makeRDD(array) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:26 scala> val rdd = sc.makeRDD(array) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:26 scala> rdd.count res0: Long = 5 scala>
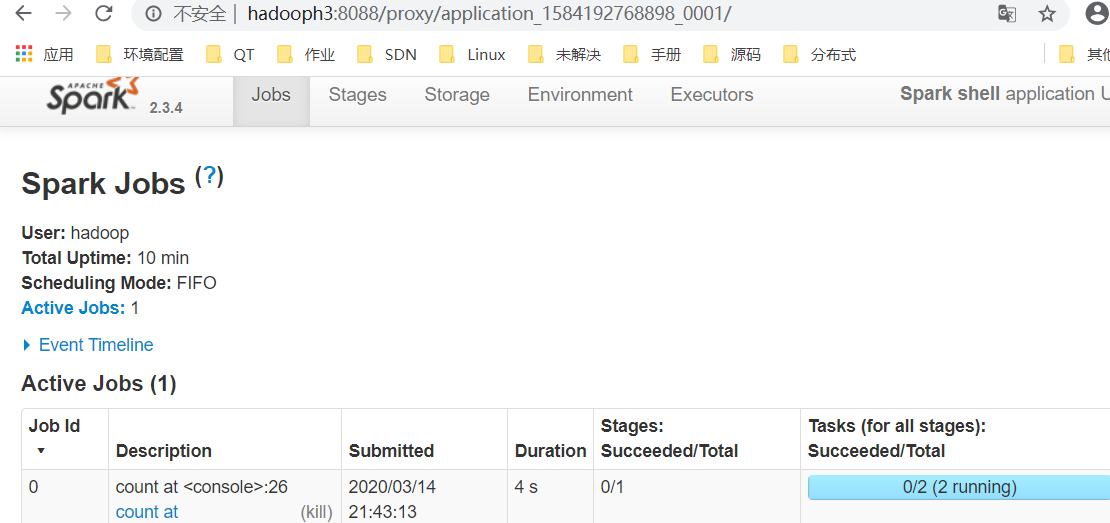

6. 使用示例程序求圆周率
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 500m --executor-memory 500m --executor-cores 1 /home/hadoop/App/spark-2.3.4-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.3.4.jar 10


