Hadoop基础---shuffle机制(进一步理解Hadoop机制)
一:MapReduce框架 (结合YARN框架)
补充:MapReduce框架知道我们写的map-reduce程序的运行逻辑。我们写的map-reduce中并没有管理层的任务运行分配逻辑,该逻辑被封装在MapReduce框架里面,被封装为MRAppMaster类,该类用于管理整个map-reduce的运行逻辑。(map-reduce程序的管理者)
MRAppMaster由YARN框架启动(动态启动,随机选取)
(一)框架流程图
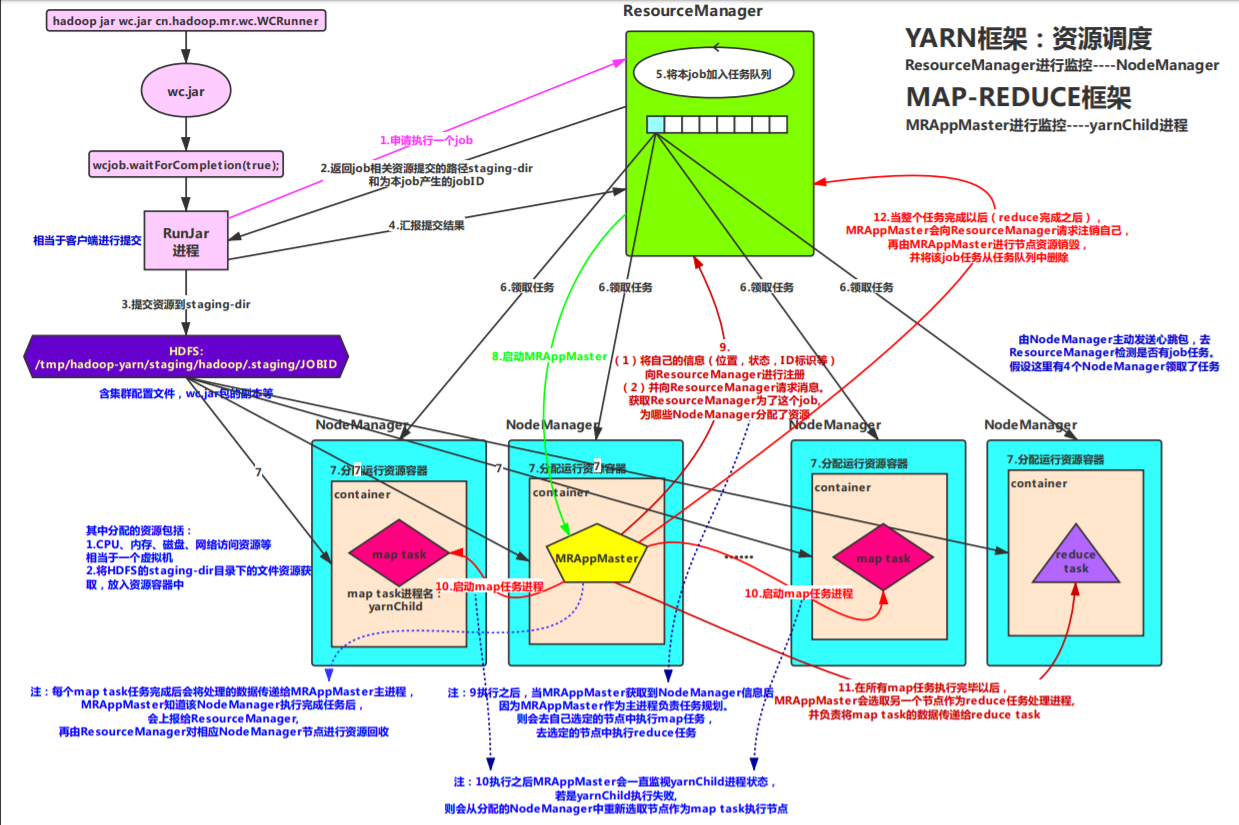
注:MRAppMaster和yarnChild(包括map task和reduce task)都是动态产生的。
注意:yarn框架只做资源的管理,如果要运行一个程序,则会为该程序分配节点、内存、cpu等资源,至于该程序如何运行,yarn框架不进行管理。故也不会知道mapreduce的运行逻辑 。同样因为这样的松耦合,yarn框架的使用范围更加广泛,可以兼容其他运行程序。
补充:MapReduce框架知道我们写的map-reduce程序的运行逻辑。我们写的map-reduce中并没有管理层的任务运行分配逻辑,该逻辑被封装在MapReduce框架里面,被封装为MRAppMaster类,该类用于管理整个map-reduce的运行逻辑。(map-reduce程序的管理者)
重点:步骤6中,由NodeManager主动发送心跳包,去ResourceManager检测是否有job任务,只当该NodeManager(即DataNode)有相关资源时,才会领取该job
MRAppMaster由YARN框架启动(动态启动,随机选取)
二:map task并发机制---split切片
1.若是一个block对应一个map任务,则如是文件夹下有众多小文件(即众多block),若是map进程过多,则效率太低
2.若是一个block过大,则使用一个map进程,则效率也会太低
因此,将block物理层,抽象为split切片逻辑层,可以更好的实现map任务并发数量控制

三:提交任务时获取切片split信息源码分析
job.waitForCompletion(true)
(一) job.class中方法waitForCompletion
public boolean waitForCompletion(boolean verbose ) throws IOException, InterruptedException, ClassNotFoundException { if (state == JobState.DEFINE) { submit(); } return isSuccessful(); }
(二)job.class中方法submit
public void submit() throws IOException, InterruptedException, ClassNotFoundException { return submitter.submitJobInternal(Job.this, cluster); }
(三)jobsummitter.class中submitJobInternal方法
JobStatus submitJobInternal(Job job, Cluster cluster){ Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); //从ResourceManager中获取资源配置存放路径 JobID jobId = submitClient.getNewJobID(); //获取jobid,用于创建目录 job.setJobID(jobId); Path submitJobDir = new Path(jobStagingArea, jobId.toString()); //生成完整路径 JobStatus status = null; try { copyAndConfigureFiles(job, submitJobDir); //提交jar包和配置文件到资源hdfs配置路径 int maps = writeSplits(job, submitJobDir); //获取切片信息,返回要启动的map任务数量 // Write job file to submit dir writeConf(conf, submitJobFile); //写描述文件xml到hdfs配置路径 } }
(四)jobsummitter.class中writeSplits方法,返回要启动的map任务数量
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job, Path jobSubmitDir) throws IOException, InterruptedException, ClassNotFoundException { JobConf jConf = (JobConf)job.getConfiguration(); int maps; maps = writeNewSplits(job, jobSubmitDir); return maps; }
(五)jobsummitter.class中writeNewSplits方法
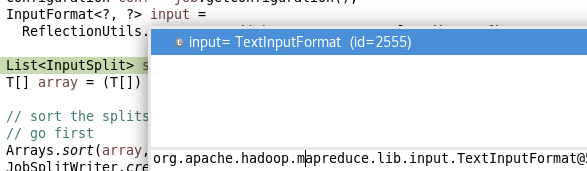
private <T extends InputSplit> int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = job.getConfiguration(); InputFormat<?, ?> input = //通过反射获取InputFormat实例---默认从TextInputFormat中获取 ReflectionUtils.newInstance(job.getInputFormatClass(), conf); List<InputSplit> splits = input.getSplits(job); //从实例中获取切片信息(有多个),放在list T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]); // sort the splits into order based on size, so that the biggest // go first Arrays.sort(array, new SplitComparator()); JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array); return array.length; }
(六)FileInputFormat.class中getSplits方法,获取切片信息《重点》
public List<InputSplit> getSplits(JobContext job) throws IOException { StopWatch sw = new StopWatch().start(); long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); long maxSize = getMaxSplitSize(job); // generate splits 生成切片 List<InputSplit> splits = new ArrayList<InputSplit>(); //list存放切片信息 List<FileStatus> files = listStatus(job); //获取:该job,所需要的输入数据所在的目录下的文件列表 for (FileStatus file: files) { //遍历所有的文件 Path path = file.getPath(); //获取文件完整路径 hdfs://hadoopH1:9000/wc/input/wcdata.txt long length = file.getLen(); //获取文件大小 160 if (length != 0) { //处理有内容的文件 BlockLocation[] blkLocations; //获取文件block信息---包括偏移量起止,主机名信息 if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { FileSystem fs = path.getFileSystem(job.getConfiguration()); blkLocations = fs.getFileBlockLocations(file, 0, length); } if (isSplitable(job, path)) { //查看该文件是否可以被切片,某些文件不允许切片 long blockSize = file.getBlockSize(); //获取文件块默认大小128M long splitSize = computeSplitSize(blockSize, minSize, maxSize); //计算切片大小,详细见(七),返回大小128M long bytesRemaining = length; //剩余未处理(未切片)字节数为160字节 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { //循环进行切片,若是剩余字节/切片大小>SPLIT_SLOP则进行切片,其中SPLIT_SLOP为1.1 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); bytesRemaining -= splitSize; } if (bytesRemaining != 0) { //单独对最后部分的剩余字节进行切片处理 此处bytesRemaining大小160字节,直接到此处切片 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); } } else { // not splitable splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(), blkLocations[0].getCachedHosts())); } } else { //Create empty hosts array for zero length files splits.add(makeSplit(path, 0, length, new String[0])); } } // Save the number of input files for metrics/loadgen job.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); sw.stop(); return splits; }
1.getFormatMinSplitSIze方法获取该格式最小切片字节数
protected long getFormatMinSplitSize() { return 1; }
2.getMinSplitSize获取切片最小值
public static long getMinSplitSize(JobContext job) { return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L); }
3.getMaxSplitSize获取切片最大值
public static long getMaxSplitSize(JobContext context) { return context.getConfiguration().getLong(SPLIT_MAXSIZE, Long.MAX_VALUE); }

4.List<FileStatus> files = listStatus(job); //获取:该job,所需要的输入数据所在的目录下的文件列表
//指定要处理的输入数据存放的路径 FileInputFormat.setInputPaths(wcjob, new Path("hdfs://hadoopH1:9000/wc/input"));

[ LocatedFileStatus{
path=hdfs://hadoopH1:9000/wc/input/wcdata.txt;
isDirectory=false;
length=160;
replication=1;
blocksize=134217728;
modification_time=1582019683334;
access_time=1582336696735;
owner=hadoop;
group=supergroup;
permission=rw-r--r--;
isSymlink=false}
]
5.getBlockLocations获取文件偏移量信息
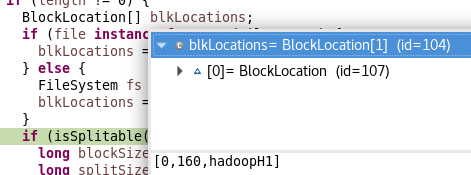
BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { FileSystem fs = path.getFileSystem(job.getConfiguration()); blkLocations = fs.getFileBlockLocations(file, 0, length); }
6.切片处理(重点),规划切片信息
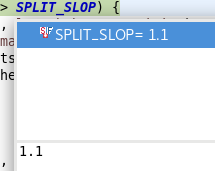
long blockSize = file.getBlockSize(); //获取文件块默认大小128M long splitSize = computeSplitSize(blockSize, minSize, maxSize); //计算切片大小,详细见(七),返回大小128M long bytesRemaining = length; //剩余未处理(未切片)字节数为160字节 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { //循环进行切片,若是剩余字节/切片大小>SPLIT_SLOP则进行切片,其中SPLIT_SLOP为1.1 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); bytesRemaining -= splitSize; } if (bytesRemaining != 0) { //单独对最后部分的剩余字节进行切片处理 此处bytesRemaining大小160字节,直接到此处切片 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); //传入block位置,和切片偏移量,获取该block当前的索引值 splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, // blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); }
splits信息:
[hdfs://hadoopH1:9000/wc/input/wcdata.txt:0+160] //列表 每个元素《切片》后面是切片的起始地址和终止地址
7.getBlockIndex根据切片偏移量,获取block索引(重点)
protected int getBlockIndex(BlockLocation[] blkLocations, long offset) { for (int i = 0 ; i < blkLocations.length; i++) { //获取该文件偏移量所在的文件块block中,----逻辑转物理 // is the offset inside this block? if ((blkLocations[i].getOffset() <= offset) && (offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){ return i; } } BlockLocation last = blkLocations[blkLocations.length -1]; long fileLength = last.getOffset() + last.getLength() -1; throw new IllegalArgumentException("Offset " + offset + " is outside of file (0.." + fileLength + ")"); }
8.makeSplit创建切片
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
传入信息:
文件路径 hdfs://hadoopH1:9000/wc/input/wcdata.txt 切片偏移量 0 剩余字节数 160 当前文件块所在的主机名 [hadoopH1]
获取管理块的缓存副本的主机列表(主机名) [] 因为我们伪分布设置副本为1,所以为空
(七)FileInputFormat.class中computeSplitSize方法,计算切片大小
protected long computeSplitSize(long blockSize, long minSize, long maxSize) { return Math.max(minSize, Math.min(maxSize, blockSize)); //其中blockSize大小默认128M maxSize为long类型最大值,minSize为1 }
四:Shuffle机制

(一)map task
1.每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阈值0.8(io.sort.spill.percent),一个后台线程把内容写到磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件
2.写磁盘前,要进行分组,排序。存放在内存缓存、溢出写文件、合并文件中的数据全部是分组、排序后的数据。
3.等map task最后记录写完,合并全部溢出写文件为一个分区且排序的文件
(二)reduce task
1. reducer通过http方式得到输出文件的分区。每个reduce task处理一个分组数据
2.TaskTracker为分区文件运行reduce任务。复制阶段把Map输出复制到reducer的内存或者磁盘。一个Map任务完成,reduce就开始复制输出。
3.map和reduce阶段使用归并方法对各个阶段数据进行合并排序操作
五:基于MRappMaster(监控调度机制)实现的shuffle机制


 浙公网安备 33010602011771号
浙公网安备 33010602011771号