Hadoop基础---RPC框架思想及HDFS源码解析
一:RPC框架封装思想
(一)实现原理
RPC(Remote Procedure Call)远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。
在OSI网络通信模型中,RPC跨越了传输层和应用层。
RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
RPC内部的结构一般如下图所示:
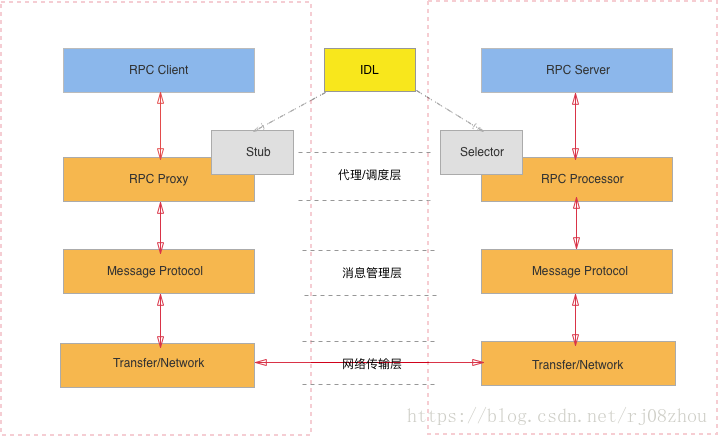
1.RPC Client: RPC协议的调用方。
2.RPC Server: 远程方法的提供方。
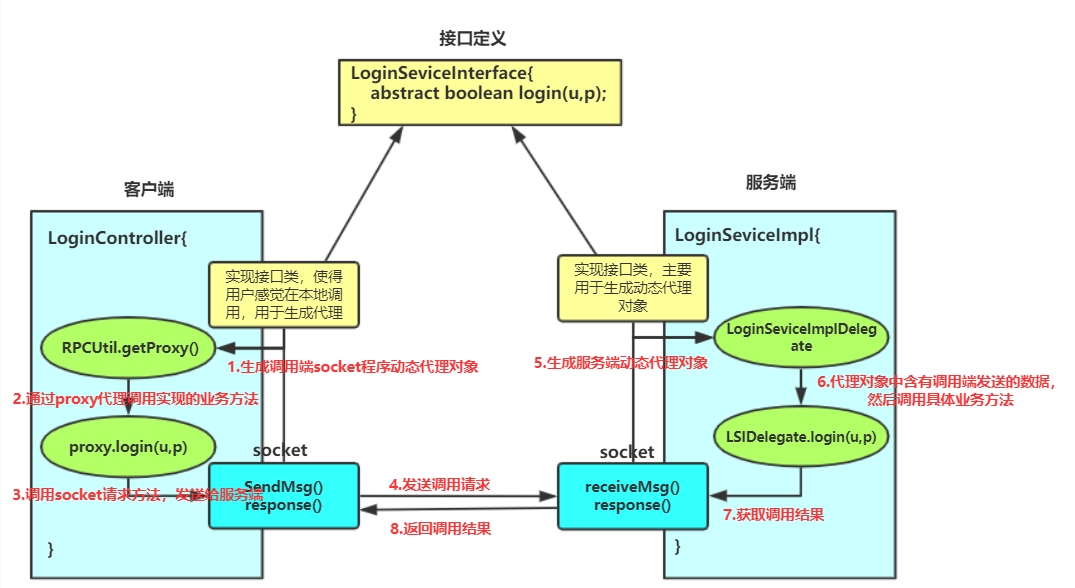
3.RPC Proxy/Stub: 存在于客户端,因为RPC协议的”透明性”,需要存在一个Stub层封装RPC远程调用的过程实现,让客户端觉得是在本地调用方法一样。
4.RPC Processor/Selector: 存在于服务端,由于服务器端某一个RPC接口的实现的特性(它并不知道自己是一个将要被RPC提供给第三方系统调用的服务),所以在RPC框架中应该有一种“负责执行RPC接口实现”的角色。它负责了包括:管理RPC接口的注册、判断客户端的请求权限、控制接口实现类的执行在内的各种工作。
5.MessageProtocol: 由于一次交互都有服务端和客户端两端都能识别的,共同约定的格式。消息管理层负责对消息的编码和解码。同时要保证消息序列化的高效性。
6.Transfer/Network: 负责管理RPC框架所使用的网络协议、网络IO模型。
7.IDL: 接口定义语言,为跨语言的特性设计的通用的消息格式。
二:Hadoop实现方法
注意:我们依旧需要导入公共jar包,因为我们需要用到hadoop-common下的ipc.RPC类
(一)服务端实现
1.LoginServiceInterface.java接口实现
package cn.hadoop.rpc; public interface LoginServiceInterface { public static final long versionID = 1L; //定义接口版本 public String login(String username,String password); //定义方法 }
2.LoginServiceInterface.java业务实现
package cn.hadoop.rpc; public class LoginServiceImpl implements LoginServiceInterface{ public String login(String username,String password) { return username + " logged in successfully"; } }
3.Starter.java服务端开启
package cn.hadoop.rpc; import java.io.IOException; import org.apache.hadoop.HadoopIllegalArgumentException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.ipc.RPC; import org.apache.hadoop.ipc.RPC.Builder; import org.apache.hadoop.ipc.Server; import cn.hadoop.rpc.LoginServiceImpl; import cn.hadoop.rpc.LoginServiceInterface; public class Starter { public static void main(String[] args) throws HadoopIllegalArgumentException, IOException { // TODO Auto-generated method stub Builder builder = new RPC.Builder(new Configuration()); builder.setBindAddress("hadoopH1").setPort(10000). setProtocol(LoginServiceInterface.class). //设置接口 setInstance(new LoginServiceImpl()); //设置接口实现业务 //builder用于设置参数,这个是RPC Server的一个构造者对象,可以通过RPC.Builder.build()方法构建一个服务器对象。 Server server = builder.build(); server.start(); //开启服务端 } }
(二)客户端实现
1.LoginServiceInterface.java接口实现
package cn.hadoop.rpc; public interface LoginServiceInterface { public static final long versionID = 1L; public String login(String username,String password); }
2.LoginController.java客户端实现
package cn.hadoop.rpc; import java.io.IOException; import java.net.InetSocketAddress; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.ipc.RPC; public class LoginController { public static void main(String[] args) throws IOException { LoginServiceInterface proxy = RPC.getProxy(LoginServiceInterface.class, 1L, new InetSocketAddress("hadoopH1", 10000), new Configuration()); String result = proxy.login("ssyfj", "123456"); System.out.println(result); } }
三:源码分析
//要访问hdfs,需要获取FileSystem类(必须是org.apache.hadoop.fs包下)的实例对象 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); //fs对象就是HDFS的客户端,用fs就可以读文件,写文件,查看文件... //下载文件 Path f = new Path("hdfs://hadoopH1:9000/jdk-7u80-linux-x64.tar.gz"); //指定路径 FSDataInputStream in = fs.open(f); //打开hdfs输入流 FileOutputStream out = new FileOutputStream("E:\\jdk.tar.gz"); //打开文件输出流,输入文件路径 IOUtils.copy(in, out);
四:分析FileSystem fs = FileSystem.get(conf);从文件系统实例对象中解析NameNode
(一)FileSystem实例获取
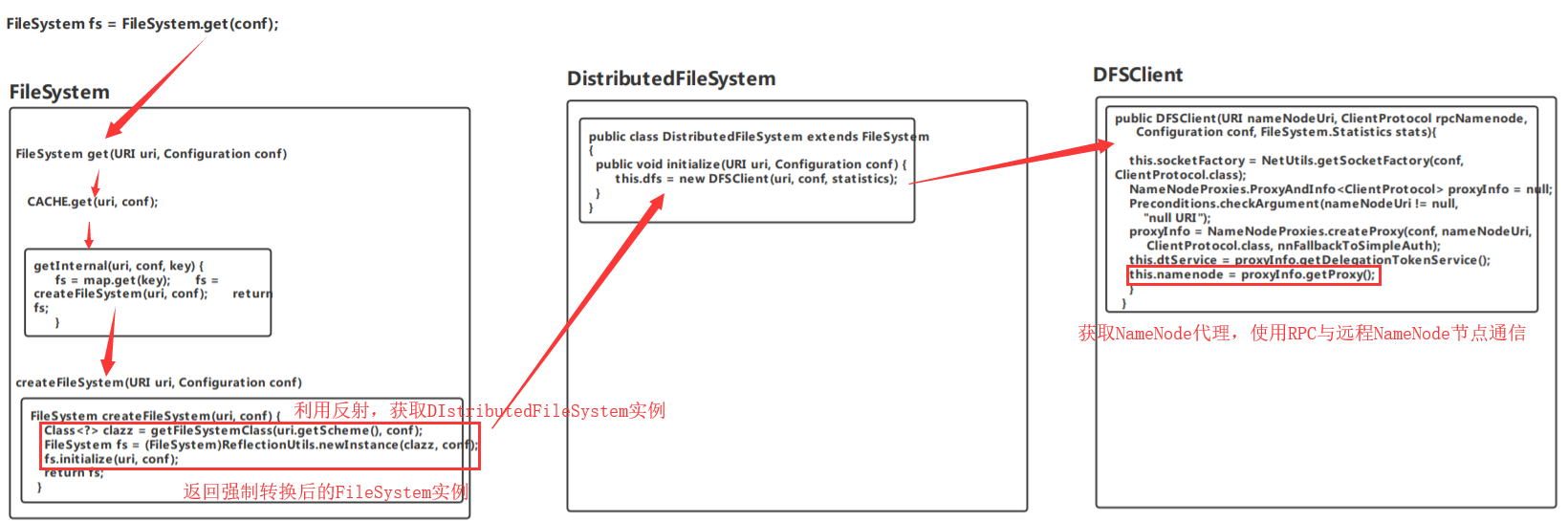
1.FileSystem.get(conf)获取文件系统实例对象,靠fs对象,对集群机器进行RPC通信
其中conf内容:
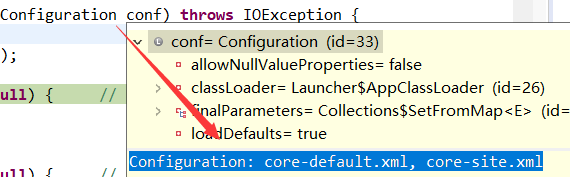
默认是从这两个xml文件中获取配置信息。
public static FileSystem get(Configuration conf) throws IOException { return get(getDefaultUri(conf), conf); }
2.FileSystem get(URI uri, Configuration conf)
其中uri内容:
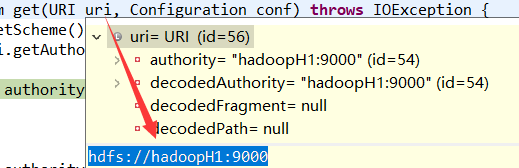
其中scheme和authority变量信息:
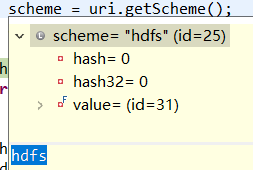
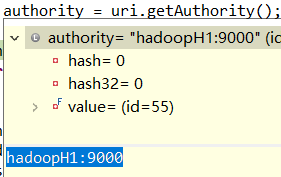
public static FileSystem get(URI uri, Configuration conf) throws IOException { String scheme = uri.getScheme(); String authority = uri.getAuthority(); ...... return CACHE.get(uri, conf); }
3.CACHE.get(uri, conf);
FileSystem get(URI uri, Configuration conf) throws IOException{ Key key = new Key(uri, conf); return getInternal(uri, conf, key); }
4.getInternal(URI uri, Configuration conf, Key key)
private FileSystem getInternal(URI uri, Configuration conf, Key key) throws IOException{ fs = map.get(key); ..... fs = createFileSystem(uri, conf); ..... return fs; }
5.FileSystem createFileSystem(URI uri, Configuration conf):反射DistributedFileSystem对象,并进行初始化
private static FileSystem createFileSystem(URI uri, Configuration conf ) throws IOException { Class<?> clazz = getFileSystemClass(uri.getScheme(), conf); FileSystem fs = (FileSystem)ReflectionUtils.newInstance(clazz, conf); fs.initialize(uri, conf); return fs; }
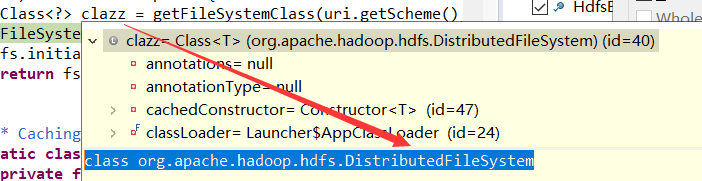
利用配置对象和类clazz反射DIstractedFileSystem对象
(二)DistributedFileSystem实例对象获取
6.进入DIstributedFileSystem类,进行初始化操作
public class DistributedFileSystem extends FileSystem { @Override public void initialize(URI uri, Configuration conf) throws IOException { ......this.dfs = new DFSClient(uri, conf, statistics); ...... }
(三)DFSClient实例对象获取NameNode代理
7.new DFSClient(uri, conf, statistics);获取DFS客户端对象
public DFSClient(URI nameNodeUri, Configuration conf, FileSystem.Statistics stats) throws IOException { this(nameNodeUri, null, conf, stats); }
8.用RPC框架根据去创建一个和NameNode通信用的客户端代理对象
public DFSClient(URI nameNodeUri, ClientProtocol rpcNamenode, Configuration conf, FileSystem.Statistics stats) throws IOException { this.conf = conf; this.stats = stats; this.socketFactory = NetUtils.getSocketFactory(conf, ClientProtocol.class); this.dtpReplaceDatanodeOnFailure = ReplaceDatanodeOnFailure.get(conf); this.ugi = UserGroupInformation.getCurrentUser(); this.authority = nameNodeUri == null? "null": nameNodeUri.getAuthority(); this.clientName = "DFSClient_" + dfsClientConf.taskId + "_" + DFSUtil.getRandom().nextInt() + "_" + Thread.currentThread().getId(); int numResponseToDrop = conf.getInt( DFSConfigKeys.DFS_CLIENT_TEST_DROP_NAMENODE_RESPONSE_NUM_KEY, DFSConfigKeys.DFS_CLIENT_TEST_DROP_NAMENODE_RESPONSE_NUM_DEFAULT); NameNodeProxies.ProxyAndInfo<ClientProtocol> proxyInfo = null; AtomicBoolean nnFallbackToSimpleAuth = new AtomicBoolean(false); { Preconditions.checkArgument(nameNodeUri != null, "null URI"); proxyInfo = NameNodeProxies.createProxy(conf, nameNodeUri, ClientProtocol.class, nnFallbackToSimpleAuth); this.dtService = proxyInfo.getDelegationTokenService(); this.namenode = proxyInfo.getProxy(); } }
注意:NomeNode节点实例存在于DFSClient实例对象的成员变量中
(四)RPC解析NameNode程序图
五:通过NameNode获取文件分块信息和DataNode节点实例对象
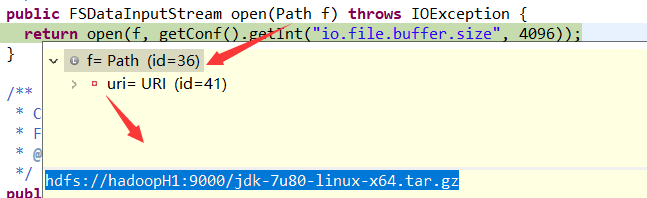
Path f = new Path("hdfs://hadoopH1:9000/jdk-7u80-linux-x64.tar.gz"); //指定路径 FSDataInputStream in = fs.open(f); //打开hdfs输入流
(一)获取FileSystem实例对象,打开HDFS输入流
1.打开指定路径下的文件系统数据输入流
public FSDataInputStream open(Path f) throws IOException { return open(f, getConf().getInt("io.file.buffer.size", 4096)); }
(二)获取DistributedFileSystem实例,调用DFSClient
2.调用DistributedFileSystem下的open方法
public class DistributedFileSystem extends FileSystem { @Override public FSDataInputStream open(Path f, final int bufferSize) throws IOException { statistics.incrementReadOps(1); Path absF = fixRelativePart(f); 转换为绝对路径,因为有可能我们传入的是相对路径 return new FileSystemLinkResolver<FSDataInputStream>() { @Override public FSDataInputStream doCall(final Path p) throws IOException, UnresolvedLinkException { final DFSInputStream dfsis = dfs.open(getPathName(p), bufferSize, verifyChecksum); return dfs.createWrappedInputStream(dfsis); } @Override public FSDataInputStream next(final FileSystem fs, final Path p) throws IOException { return fs.open(p, bufferSize); } }.resolve(this, absF); 会去调用上面匿名对象中docall方法,返回一个DFSInputStream实例 } }
注意:dfs是我们在(一)6中DistributedFileSystem类实例中获取的成员变量
this.dfs = new DFSClient(uri, conf, statistics);
(三)通过DFSClient打开DFSInputStream
3.dfs实例调用DFSClient类中的open方法:创建一个输入流,从namenode获取节点列表及文件信息
public DFSInputStream open(String src, int buffersize, boolean verifyChecksum) throws IOException, UnresolvedLinkException { checkOpen(); // Get block info from namenode 从NameNode节点,获取文件块信息 TraceScope scope = getPathTraceScope("newDFSInputStream", src); try { return new DFSInputStream(this, src, verifyChecksum); } finally { scope.close(); } }
(四)通过DFSInputStream实例,通过NameNode获取文件块和DataNode节点信息
4.构造DFSInputStream实例,初始化了几个重要的变量,调用了重要方法
DFSInputStream(DFSClient dfsClient, String src, boolean verifyChecksum ) throws IOException, UnresolvedLinkException { this.dfsClient = dfsClient; 通过该实例对象,我们可以访问到NameNode实例,从而调用RPC从远程NameNode节点中获取需要的文件块信息和DataNode节点信息 this.verifyChecksum = verifyChecksum; this.src = src; synchronized (infoLock) { this.cachingStrategy = dfsClient.getDefaultReadCachingStrategy(); } openInfo(); 在该方法内部,会调用其他方法获取文件块信息和DataNode节点信息!!! }
5.通过openinfo()方法,从NameNode节点中获取信息
void openInfo() throws IOException, UnresolvedLinkException { synchronized(infoLock) { lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength(); ...... } }
6.fetchLocatedBlocksAndGetLastBlockLength方法获取文件块位置和最后一块文件长度(返回该长度)
因为其他文件快都是默认大小,只有最后一个文件块大小是不固定的
private long fetchLocatedBlocksAndGetLastBlockLength() throws IOException { final LocatedBlocks newInfo = dfsClient.getLocatedBlocks(src, 0); locatedBlocks = newInfo; long lastBlockBeingWrittenLength = 0; if (!locatedBlocks.isLastBlockComplete()) { final LocatedBlock last = locatedBlocks.getLastLocatedBlock(); if (last != null) { if (last.getLocations().length == 0) { if (last.getBlockSize() == 0) { // if the length is zero, then no data has been written to // datanode. So no need to wait for the locations. return 0; } return -1; } final long len = readBlockLength(last); last.getBlock().setNumBytes(len); lastBlockBeingWrittenLength = len; } } fileEncryptionInfo = locatedBlocks.getFileEncryptionInfo(); return lastBlockBeingWrittenLength; }
其中文件块位置信息LocatedBlocks newInfo:
我们的文件大小应该是在140M左右,可以分成两块
LocatedBlocks{ fileLength=153530841 文件总大小 underConstruction=false blocks=[ 文件块信息数组 LocatedBlock{ 第一个文件块信息 BP-1976226360-192.168.58.100-1581578493797: 文件块所在目录同名,其中IP指定了下面文件块所属的集群IP blk_1073741825_1001; 文件块名 getBlockSize()=134217728; 该文件块大小,默认128M corrupt=false; offset=0; locs=[ DatanodeInfoWithStorage[ DataNode节点信息 192.168.58.100:50010, 通过该IP:端口,可以访问到该文件块所属的DataNode节点下的文件数据 DS-1787954b-d2e5-435b-bf8a-2e72e677dcf3, DISK ] ] }, LocatedBlock{ 第二个文件块信息 BP-1976226360-192.168.58.100-1581578493797: blk_1073741826_1002; getBlockSize()=19313113; corrupt=false; offset=134217728; locs=[ DatanodeInfoWithStorage[ 192.168.58.100:50010, DS-1787954b-d2e5-435b-bf8a-2e72e677dcf3,
DISK ] ] } ] lastLocatedBlock=LocatedBlock{ 最后一个文件块信息,需要我们为此在单独列出,同上面的第二块 BP-1976226360-192.168.58.100-1581578493797: blk_1073741826_1002; getBlockSize()=19313113; corrupt=false; offset=134217728; locs=[ DatanodeInfoWithStorage[ 192.168.58.100:50010, DS-1787954b-d2e5-435b-bf8a-2e72e677dcf3,DISK ] ] } isLastBlockComplete=true }
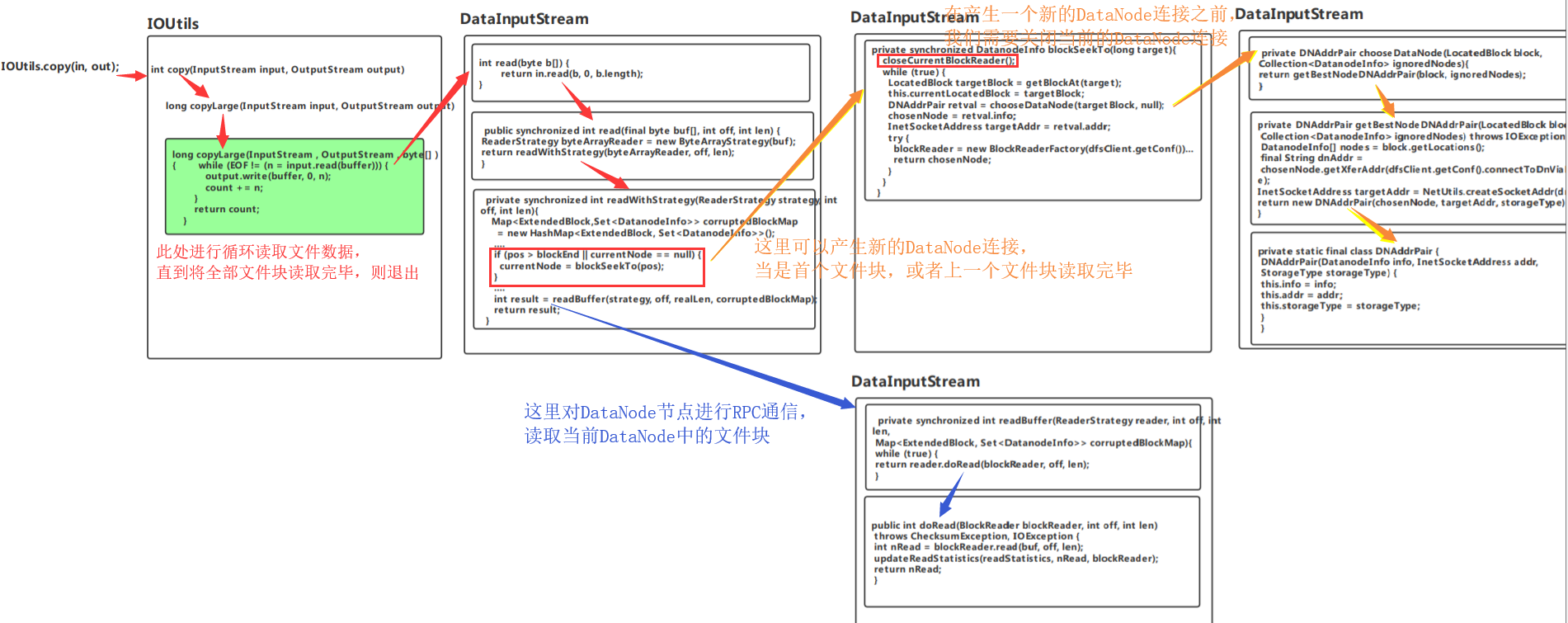
(五)获取文件块信息程序流程

六:解析文件系统,同DataNode节点通信,获取文件数据
FSDataInputStream in = fs.open(f); //打开hdfs输入流 FileOutputStream out = new FileOutputStream("E:\\jdk.tar.gz"); //打开文件输出流,输入文件路径 IOUtils.copy(in, out);
(一)从IOUtil模块拷贝数据到输出流
1.从输入流拷贝数据到输出流
public static int copy(InputStream input, OutputStream output){ long count = copyLarge(input, output); }
public static long copyLarge(InputStream input, OutputStream output) { return copyLarge(input, output, new byte[DEFAULT_BUFFER_SIZE]); }
public static long copyLarge(InputStream input, OutputStream output, byte[] buffer){ long count = 0; int n = 0; while (EOF != (n = input.read(buffer))) { //一直循环直到该文件块被全部读取 output.write(buffer, 0, n); count += n; } return count; }
n = input.read(buffer)从HDFS系统中DataNode节点读取数据,output.write(buffer, 0, n);输出到本地文件系统
(二)在DataInputStream模块中调用read方法,一方面获取DataNode信息和连接,一方面通过blockReader进行数据读取
2.从DFSInputStream实例中读取指定字节的数据
public final int read(byte b[]) throws IOException { return in.read(b, 0, b.length); }
3.使用字节读取策略,读取数据到buffer中
public synchronized int read(final byte buf[], int off, int len) { ReaderStrategy byteArrayReader = new ByteArrayStrategy(buf); return readWithStrategy(byteArrayReader, off, len); }
其中buf数组大小4096
4.使用readWithStrategy获取DataNodeInfo并读取数据(重点)
private synchronized int readWithStrategy(ReaderStrategy strategy, int off, int len){ Map<ExtendedBlock,Set<DatanodeInfo>> corruptedBlockMap = new HashMap<ExtendedBlock, Set<DatanodeInfo>>(); ....
if(pos>blockEnd || currentNode == null){ currentNode = blockSeekTo(pos);
} .... int result = readBuffer(strategy, off, realLen, corruptedBlockMap); return result; }
补充重点:产生一个新的DataNode节点连接
if(pos>blockEnd || currentNode == null){ currentNode = blockSeekTo(pos); }
1.当currentNode为空(即是要读取第一个文件块),我们则产生一个DataNode连接
2.pos>blockEnd当我们读取完成一个文件块后pos会大于blockEnd,一般默认blockEnd为128M,即为134217727

注意:pos默认值为0,blockEnd默认值为-1。blockEnd在获取DataNode块信息时直接设置为blockEnd+该文件块的大小(默认除了最后一块外,全为128M),则值为128M-1,而pos则是每次加上读取的4096字节(处理最后一次读取字节可能不同),其他全是pos+=4096。所以当一个文件块读取完毕后pos大小应该是pos+128M=0+128M,当一个文件块读取完毕后,则满足pos>blockEnd,进入if语句,关闭当前DataNode连接,产生下一个DataNode连接
private long pos = 0;
private long blockEnd = -1;
(三)获取DataNode信息并进行RPC连接
5.打开到DataNode的DataInputStream,以便可以从DataNode读取它。我们从namenode获得块ID和启动时目的地的ID。
private synchronized DatanodeInfo blockSeekTo(long target){ closeCurrentBlockReader(); //每当进入当前方法时,都是上一个文件块已经读取完毕,这里要产生一个新的文件块。在产生一个新的文件块之前需要先关闭之前的文件块
//连接到所需模块的最佳DataNode(因为可能存在多个副本,我们选择最近的块),带有潜在的偏移 DatanodeInfo chosenNode = null; while (true) { LocatedBlock targetBlock = getBlockAt(target); //计算所需要的块 this.currentLocatedBlock = targetBlock; DNAddrPair retval = chooseDataNode(targetBlock, null); //由8中的封装类返回实例对象,包含DataNodeInfo实例对象,网络socket实例对象(同远程DataNode节点通信),存储类型!!! chosenNode = retval.info; InetSocketAddress targetAddr = retval.addr; StorageType storageType = retval.storageType; try { ExtendedBlock blk = targetBlock.getBlock(); blockReader = new BlockReaderFactory(dfsClient.getConf()). setInetSocketAddress(targetAddr). setRemotePeerFactory(dfsClient). setDatanodeInfo(chosenNode). setStorageType(storageType). setFileName(src). setBlock(blk). setBlockToken(accessToken). setStartOffset(offsetIntoBlock). setVerifyChecksum(verifyChecksum). setClientName(dfsClient.clientName). setLength(blk.getNumBytes() - offsetIntoBlock). setCachingStrategy(curCachingStrategy). setAllowShortCircuitLocalReads(!shortCircuitForbidden). setClientCacheContext(dfsClient.getClientContext()). setUserGroupInformation(dfsClient.ugi). setConfiguration(dfsClient.getConfiguration()). build(); return chosenNode; } } }
其中currentLocatedBlock = targetBlock(这里列出第一块数据):正是我们在NameNode中获取的第一个文件块信息
LocatedBlock{ BP-1976226360-192.168.58.100-1581578493797: blk_1073741825_1001; getBlockSize()=134217728; corrupt=false; offset=0; locs=[ DatanodeInfoWithStorage[ 192.168.58.100:50010, DS-1787954b-d2e5-435b-bf8a-2e72e677dcf3, DISK ] ] }
重点:生成了blockReader对象(是类的成员变量),用于HDFS文件块读取!!!
6.选择一个最好的文件块(例如所有副本中最近的)
private DNAddrPair chooseDataNode(LocatedBlock block, Collection<DatanodeInfo> ignoredNodes){ return getBestNodeDNAddrPair(block, ignoredNodes); }
7.选择获取数据流的最佳节点。
private DNAddrPair getBestNodeDNAddrPair(LocatedBlock block, Collection<DatanodeInfo> ignoredNodes) throws IOException { DatanodeInfo[] nodes = block.getLocations(); StorageType[] storageTypes = block.getStorageTypes(); DatanodeInfo chosenNode = null; StorageType storageType = null; if (nodes != null) { for (int i = 0; i < nodes.length; i++) { if (!deadNodes.containsKey(nodes[i]) && (ignoredNodes == null || !ignoredNodes.contains(nodes[i]))) { chosenNode = nodes[i]; break; } } } final String dnAddr = chosenNode.getXferAddr(dfsClient.getConf().connectToDnViaHostname); //获取远程DataNode节点的IP:Port字符串 InetSocketAddress targetAddr = NetUtils.createSocketAddr(dnAddr); //与远程DataNode主机建立socket链接 return new DNAddrPair(chosenNode, targetAddr, storageType); //返回一个封装对象,包含DataNodeInfo实例,socket实例等等 }
8.用于封装数据节点信息及其地址的实用程序类。其中包含DataNodeInfo实例对象
private static final class DNAddrPair { final DatanodeInfo info; final InetSocketAddress addr; final StorageType storageType; DNAddrPair(DatanodeInfo info, InetSocketAddress addr, StorageType storageType) { this.info = info; this.addr = addr; this.storageType = storageType; } }
(四)通过获取的DataNode连接,使用blockReader进行数据读取
9.通过blockReader解析数据读取
private synchronized int readBuffer(ReaderStrategy reader, int off, int len, Map<ExtendedBlock, Set<DatanodeInfo>> corruptedBlockMap){ while (true) { return reader.doRead(blockReader, off, len); }
10.通过blockReader直接读取数据到缓存中(真正的数据读取)
public int doRead(BlockReader blockReader, int off, int len) throws ChecksumException, IOException { int nRead = blockReader.read(buf, off, len); updateReadStatistics(readStatistics, nRead, blockReader); 更新信息 return nRead; 返回读取字节数 }
读取之前buf依旧为空:
读取之后buf被填充:

(五)DataNode连接和文件数据读取程序流程图