# 深圳杯D题爬取电视收视率排行榜
深圳杯D题爬取电视收视率排行榜
站点分析
http://www.tvtv.hk/archives/category/tv
每天的排行版通过静态页面发布,先获取每天的排行榜链接,再进一步从链接里面获取数据
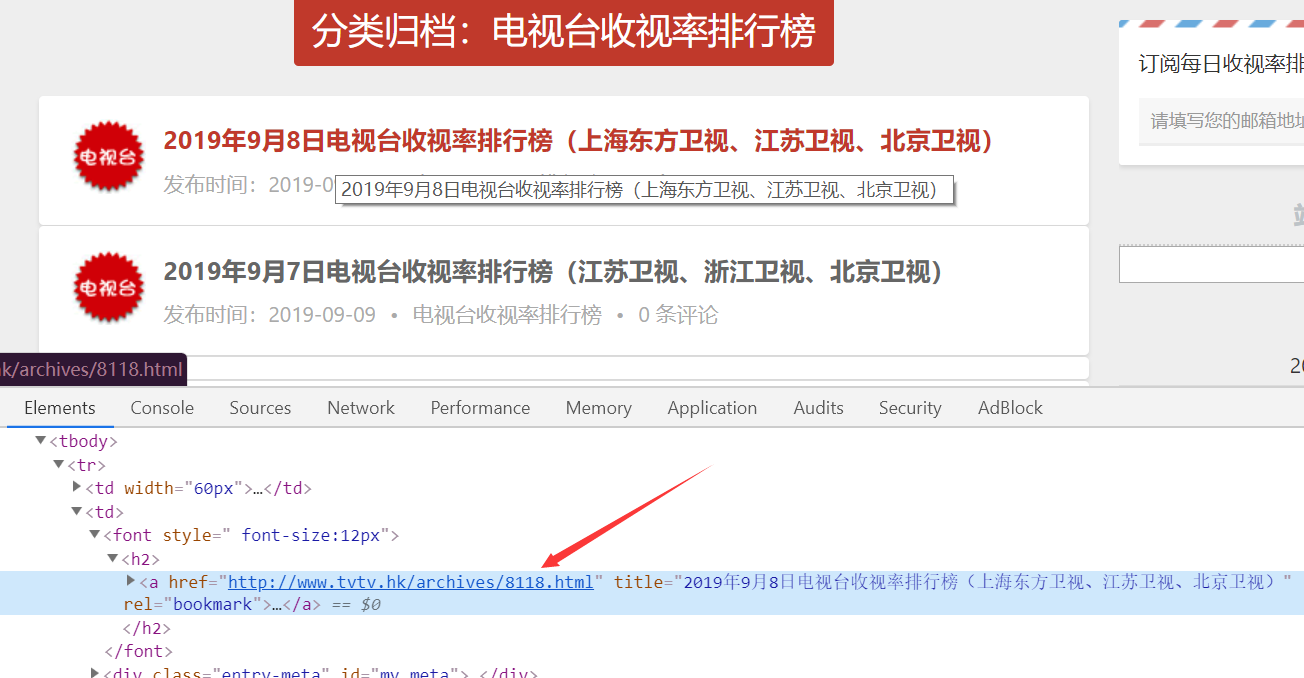
每天前10的信息发布在p标签内,存储的时候空格拆分一下
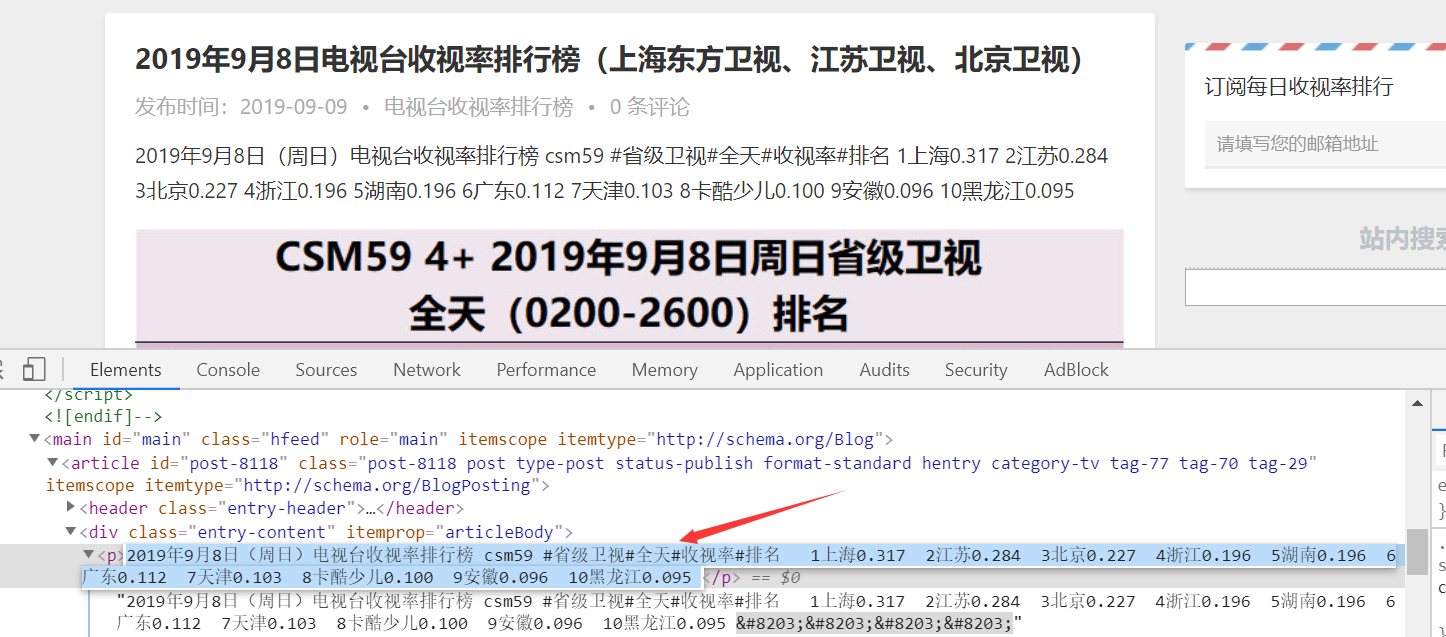
代码实现
获取每一页的静态链接
url = 'http://www.tvtv.hk/archives/category/tv/page/'
# 获取每一个网页的静态页面
for i in range(1, 100):
href = {}
print('正在爬取第' + str(i) + '页')
print(url + str(i))
doc = pq(url + str(i))
sp = doc('.status-publish')
for s in sp.items():
ha = s.find('h2 a')
href[ha.attr('title')] = ha.attr('href')
with open('TV链接列表.csv', 'a') as f:
for key in href.keys():
if key.find('榜') > 0:
f.write(key + ',' + href[key] + '\n')
从每天的静态页面中获取前十的数据
# 从每一个静态页面中获取数据
out = open('TV收视率.csv', 'w', encoding='utf-8')
with open('TV链接列表.csv', 'r') as f:
for line in f:
print(line)
strs = line.split(',')
out.write(strs[0])
doc = pq(strs[1])
p = doc.find('p:nth-child(1)').text().strip()
ps = p.split(' ')
count = 0
for item in ps:
count = count + 1
if count <= 3:
continue
j = 0
while '0' <= item[j] <= '9':
j = j + 1
out.write(',' + item[j:])
out.write('\n')
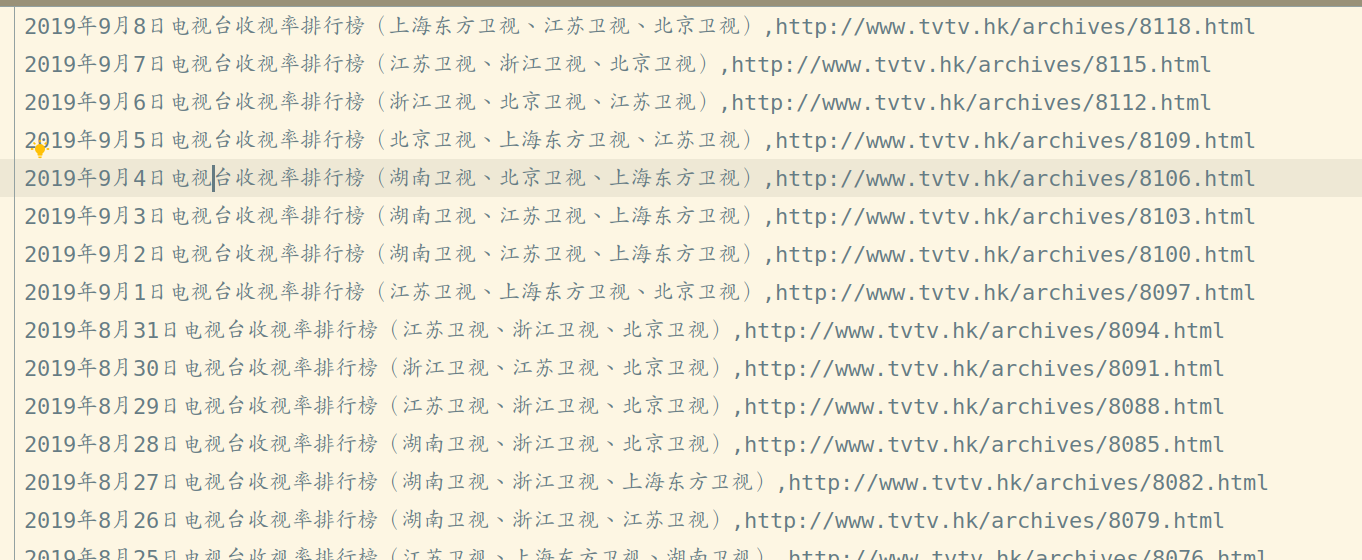
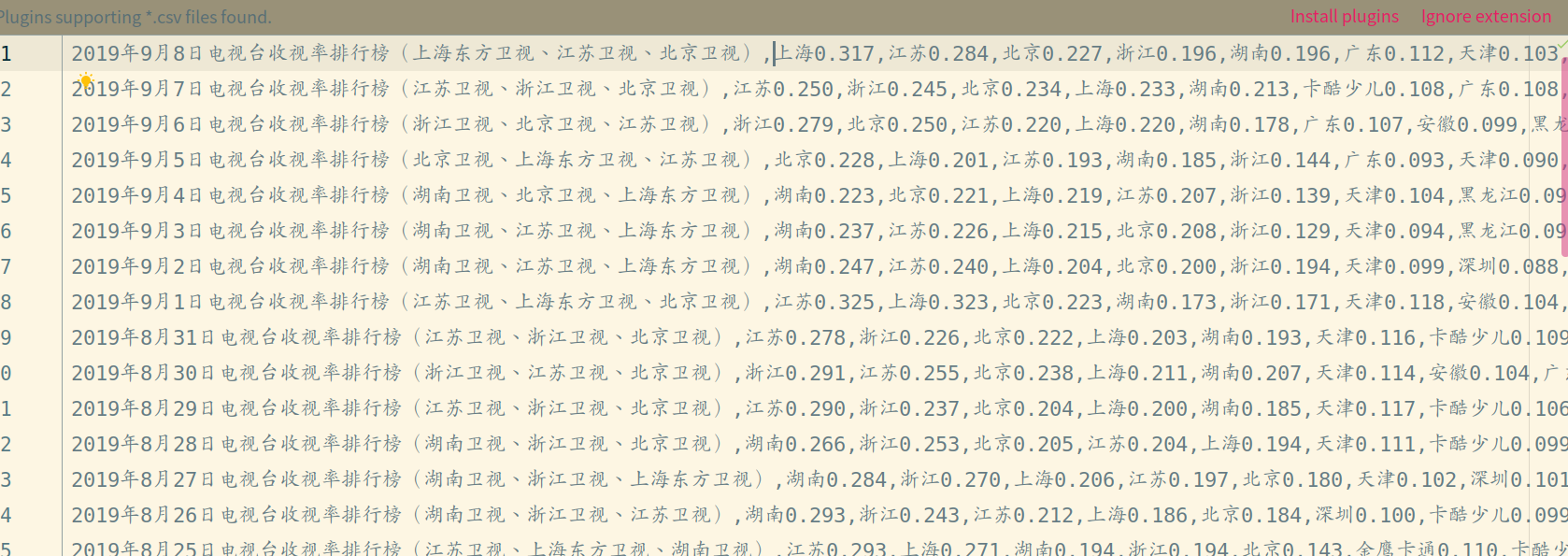
运行结果
完整代码获取:https://github.com/sstealer/WebSpider/tree/master。 感觉有帮助的话可以GitHub点个赞哦
