# ACM奇淫技巧
ACM奇淫技巧
差分操作
-
描述:给定一个数组,每次可以对数组某一个区间加一或者减一,求最少操作多少次可以使数组全部元素一致,最终可能的序列有多少种。
-
题解:可以使用差分,先求一个差分数组,差分数组中正数总和位x,负数总和为y。由于只能加一或者减一操作(加m减m操作可以同样分析,暂时没有想出怎么解,只是感觉可以同样分析)。所有最少操作次数为min(x,y)(解释:每次操作选取一正数一负数,正数减1负数加1)+abs(x-y)(剩下全正或者全负的情况,只能和差分数组的第一项或者 最后一项匹配)。最终可能的序列有abs(x-y)+1(解释:取决于最后全正或者全负情况下的操作一共abs(x-y)步操作,对原数组第一项的操作可能有(0,1,2,abs(x-y)一共abs(x-y)+1中操作方式)
坐标旋转
- (x,y)绕原点逆时针旋转\(\beta\)角到(s,t)
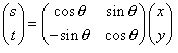
ACM 卡常优化
vsc代码块(头文件模板)
/*
* @Author: yexm
* @Date: $CURRENT_YEAR-$CURRENT_MONTH-$CURRENT_DATE
* @Time: $CURRENT_HOUR:$CURRENT_MINUTE:$CURRENT_SECOND
* @Location: ${TM_FILENAME} Line_$TM_LINE_NUMBER
*/
//加减代替取模优化,多数组结构体优化,puts()输出优化
#include <bits/stdc++.h>
using namespace std;
#define fre freopen("data.in","r",stdin);
#define frew freopen("my.out","w",stdout);
#define ms(a) memset((a),0,sizeof(a))
#define re(i,a,b) for(register int i=(a);(i)<(b);++(i))
#define ree(i,a,b) for(register int i=(a);(i)<=(b);++(i))
#define all(x) (x).begin(),(x).end()
#define pb push_back
#define lson l,m,i<<1
#define rson m+1,r,i<<1|1
#define reg register
typedef long long LL;
const int inf=(0x7f7f7f7f);
inline void sf(int& x){
x=0;int w=0; char ch=0;
while(!isdigit(ch)) {w|=ch=='-';ch=getchar();}
while(isdigit(ch)) x=(x<<3)+(x<<1)+(ch^48),ch=getchar();
x=(w?-x:x);
}
inline void pf(int x){
if(x<0) putchar('-'),x=-x;
if(x>9) pf(x/10);
putchar(x%10+'0');
}
const int maxn=1e5+5;
int main(){
return 0;
}
读入输出优化
//支持正负整数
inline void sf(int& x){
x=0;int w=0; char ch=0;
while(!isdigit(ch)) {w|=ch=='-';ch=getchar();}
while(isdigit(ch)) x=(x<<3)+(x<<1)+(ch^48),ch=getchar();
x=(w?-x:x);
}
inline void pf(int x){
if(x<0) putchar('-'),x=-x;
if(x>9) pf(x/10);
putchar(x%10+'0');
}
逗号表达式
- 逗号表达式比分号快很多很多
内联函数inline
- 内联函数的使用,一般函数比表达式慢很多。使用内联函数在编译的时候会直接在主程序中把函数内容展开,减少内存访问。不适合代码长和复杂的函数。
1 int max(int a, int b){.....}//原函数
2 inline int max(int a, int b){....}//直接加inline就好了。
寄存器变量register
- CPU寄存器变量的使用
频繁使用的变量,声明时加上该register关键字,运行时放到CPU寄存器中,速度快。但是CPU寄存器空间小,变量多的时候,一般还是丢到内存里面的。
for(register int i=0,a=1;i<=99999999;i++)
a++;
条件判断加减代替取模
//设模数为 mod
inline int inc(int x,int v,int mod){x+=v;return x>=mod?x-mod:x;}//代替取模+
inline int dec(int x,int v,int mod){x-=v;return x<0?x+mod:x;}//代替取模-
自增运算符优化
- 用++i代替i++,后置++需要保存临时变量以返回之前的值,在 STL 中非常慢。
使用结构体优化
- 如果要经常调用a[x],b[x],c[x]这样的数组,把它们写在同一个结构体里面会变快一些,比如f[x].a, f[x].b, f[x].c 指针比下标快,数组在用方括号时做了一次加法才能取地址!所以在那些计算量超大的数据结构中,你每次都多做了一次加法!!!在 64 位系统下是 long long 相加,效率可想而知。

