
多任务处理
定义:在计算机技术中,多任务处理指的是同时执行几个独立的任务。
在单处理器(单CPU)系统中,一次只能执行一个任务。多任务处理是通过在不同任务之间多路复用CPU的执行时间来实现的,即将CPU执行操作从一个任务切换到另一个任务。如果切换速度足够快,就会给人一种同时执行所有任务的错觉。这种逻辑并行性成为“并发”。
进程的概念
定义:进程是对映像的执行。
操作系统是一个多任务处理系统。在操作系统中,任务也称为进程。我们把执行映像定义为包含执行代码、数据和堆栈的存储区。
操作系统内核将一系列执行视为使用系统资源的单一实体。系统资源包括内存空间、I/O设备以及最重要的CPU时间。
在操作系统内核中,每个进程用一个独特的数据结构表示,叫做进程控制块(PCB)或任务控制块(TCB)。我们直接称之为PROC结构体。
其结构如下:
typedef struct proc{
struct proc *next;
int *ksp;
int pid;
int ppid;
int status;
int priority;
int kstack[1024];
} PROC;
·next是指向下一个PROC结构体的指针,用于在各种动态数据结构(如链表和队列)中维护PROC结构体。
·ksp字段是保存的堆栈指针,当某进程放弃使用CPU时,它会执行上下文保存在堆栈中,并将堆栈指针保存在PROC.ksp中,以便以后恢复。
·pid是识别一个进程的ID编号.
·ppid是父进程ID编号。
·status是进程的当前状态。
·priority是进程调度优先级。
·kstack是进程执行时的堆栈。
操作系统内核通常会在其数据区中定义有限数量的PROC结构体,表示为:PROC proc[NPROC];
在一个单CPU系统中,一次只能执行一个进程。操作系统内核通常会使用正在运行的或当前的全局变量PROC指针,指向当前正在执行的PROC。在有多个CPU的多处理器操作系统中,可能不同CPU上实时、并行执行多个进程。因此,在一个多处理器系统中正在运行的[NCPU]可能是一个指针数组。
多任务处理系统
type.h文件
type.h文件定义了系统常数和表示进程的简单PROC结构体。
/*********** type.h file ************/
#define NPROC 9 // number of PROCs
#define SSIZE 1024 // gtack size = 4KB
// PROC status
#define FREE 0
#define READY 1
#define SLEEP 2
#define ZOMBIE 3
typedef struct proc{
struct proc *next; // next proc pointer
int *ksp; // saved stack pointer
int pid; // pid = 0 to NPROC-1
int ppid; // parent pid
int status; // PROC status
int priority; // scheduling priority
int kstack[SSIE] // process stack
}PROC;
在扩展MT系统时,应该向PROC结构体中添加更多的字段。
ts.s文件
ts.s在32位的GCC汇编代码中可实现进程上下文切换,后面小节中将会讲到。
#------------- ts.s file file -----------------
.globl running, scheduler, tswitch
tswitch:
SAVE: pushl %eax
pushl %ebx
pushl %ecx
pushl %edx
pushl %ebp
pushl %esi
pushl %edi
pushfl
movl running, %ebx # ebx -> PROC
movl %esp, 4(%ebx) # PORC.save_sp = esp
FIND: call scheduler
RESUME:movl running, %ebx # ebx -> PROC
movl 4(%ebx), %esp #esp = PROC.saved_sp
popf1
popl %edi
popl %esi
popl %ebp
popl %edx
popl %ecx
popl %ebx
popl %eax
ret
# stack contents = |retpc|eax|ebx|ecx|edx|ebp|esi|edi|eflag|
# -1 -2 -3 -4 -5 -6 -7 -8 -9
queue.c文件
queue.c文件可实现队列和链表操作函数。enqueue()函数按优先级将PROC输入队列中。在优先级队列中,具有相同优先级的进程按先进先出(FIFO)的顺序排序。dequeue()函数可返回从队列或链表中删除的第一个元素。printList()函数可打印链表元素。
t.c文件
t.c文件定义MT系统数据结构、系统初始化代码和进程管理函数。
多任务处理系统代码介绍
编写一个MT系统
在ubuntu环境下,首先用 sudo apt-get install gcc-multilib 安装必要的包
创建一个文件夹,写入t.c ts.s queue.c type.h文件,最后用 gcc -m32 ts.s t.c -o MTwj编译运行
此处ts.s tc.s等源代码来源于gitee,链接为https://gitee.com/DKY2019/xxaqxt/tree/master/第三章 MTsys 实践
用ls查看 发现确实编译成功——多出了MTwj

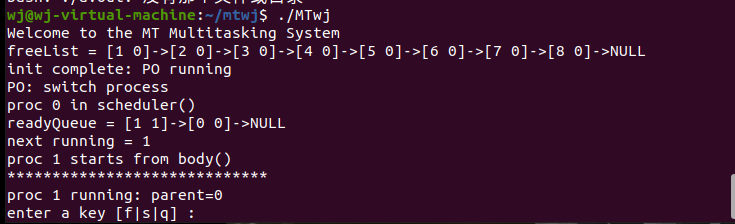
输入./MTwj开始运行MTwj,如图所示:
1.init()
当MT系统启动时,main()函数调用init()以初始化系统。init()初始化PROC结构体,并将它们输入freeList中;将readyQueue初始化为空,然后使用proc[0]创建P0,作为初始运行进程。P0的优先级最低,所有其他任务的优先级都是1,因此它们轮流从readyQueue运行。P0调用kfork()创建优先级为1的子进程P1,并将其输入就绪队列中,然后P0调用tswitch(),将会切换任务来运行P1。
2.tswitch()
tswitch()函数实现上下文切换。
3.kfork()函数
kfork()函数创建一个子任务并将其输入readyQueue中。每个新创建的任务都从同一个body()函数开始执行。由于新任务从未执行过,所以我们可以假设它的堆栈为空,而且当它调用tswitch()时,所有CPU寄存器内容都是0.
4.body()
body()中的所有(自动)局部变量都供进程专用,因为它们都是在每个进程堆栈中分配的。在body()中执行时,进程提示输入char=[f|a|q]命令,其中:
- f:kfork一个新的子进程来执行body()
- s:切换进程
- q:终止进程,并将进程以freeList中的FREE函数形式返回
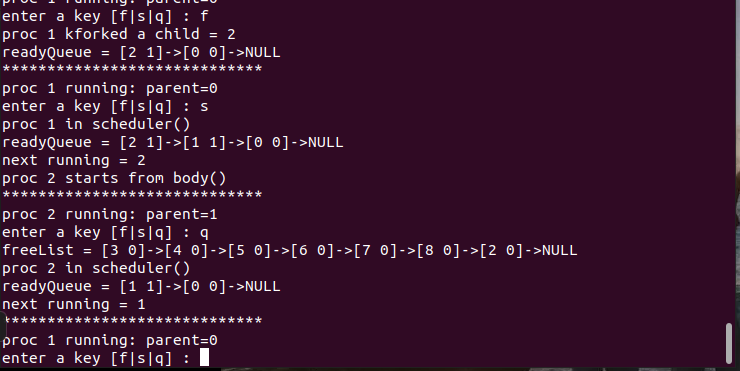
5.空闲任务P0
P0的特殊之处在于它在所有任务中具有最低的优先级。在系统初始化之后,P0创建P1并切换到运行P1。当且仅当没有可运行任务时,P0会再次运行。在这种情况下,P0会一直循环。当readyQueue变为非空时,它将切换到另一任务。在基本MT系统中,如果所有其他进程都已终止,则P0将会再次运行。若要结束MT系统,可按下"Ctrl+C"来终止Linux进程。

进程同步
定义:一个操作系统包含许多并发进程,这些进程可以彼此交互。进程同步是指控制和协调进程交互以确保正确执行所需的各项规则和机制。最简单的进程同步工具是休眠和唤醒。
睡眠模式
当某进程需要某些当前没有的东西时,例如申请独占一个存储区域、等待用户通过标准输入来输入字符等,它就会在某个事件值上进入休眠状态,该事件值表示休眠的原因。我们可以在PROC结构体中添加一个event字段,并实现ksleep(int event)函数,使进程进入休眠状态。由于休眠进程不在readyQueue中,所以它在被另一个进程唤醒之前不可运行,因此,在让自己进入休眠状态以后,进程调用tswitch()来放弃使用CPU。
唤醒操作
多个进程可能会休眠来等待同一个事件。当某个等待时间发生时,另一个执行实体会调用kwakeup(event),唤醒正处于休眠状态等待该事件值得所有程序。如果没有任何程序休眠等待该程序,Kwakeup()就不工作。
进程终止
操作系统以两种方式终止:
- 正常终止:进程调用exit(value),发出 exit(value)系统调用来执行在操作系统内核中的 kexit(value),这就是我们本节要讨论的情况。
- 异常终止:进程因某个信号而异常终止。信号和信号处理将在后面第6章讨论。在这两种情况下,当进程终止时,最终都会在操作系统内核中调用kexit()。
进程家族树
当某个进程死亡时,它将其所有的孤儿子进程,不论死亡还是活跃,都送到P1中,即成为P1的子进程。所以,如果还有其他进程存在,P1就不应该消失。大多数大型操作系统内核通过维护进程家族树来跟踪进程关系。
进程家族树通过PROC结构中的一对子进程和兄弟进程指针以二叉树的形式实现:
PROC *child,*sibling,*parent;

左侧中进程树可以实现为右侧所示的二叉树,其中每个垂直链接都是child指针,每个水平链接都是sibling指针。
等待子进程终止
在任何时候,进程都可以调用内核函数
pid = kwait(int *status)
在kwait算法中,如果没有子进程,则进程会返回-1,表示错误。
否则,他将搜索僵尸子进程。如果他找到僵尸子进程,就会收集僵尸子进程的pid和退出代码。相应的,当进程终止时,他必须发出:
kwakeup(running->parent)来唤醒父进程,让父进程将这个空壳埋葬(释放)到freeList并返回僵尸子进程的pid。
如果某个进程有多个子进程,那么它可能需要多次调用kwait()来处理所有死亡的进程。
或者某进程可以自己先终止,那么它就不需要等待任何死亡进程了。
当某进程死亡时,他所有的子进程都成了P1的子进程。
P1扮演的角色:
- 它是除P0之外所有进程的祖先。所有登录进程都是P1的子进程。
- 它就像是孤儿院的院长,所有孤儿都会被送到这儿,并叫它爸爸。
- 它是太平间管理员,不停地寻找僵尸进程,埋葬它们死亡的空壳。
Unix/Linux中的进程
进程来源
当操作系统启动时,操作系统内核的启动代码会强行创建一个PID=0的初始进程,即通过分配PROC结构体进行创建,初始化PROC内容,并让运行指向proc[0]。然后,系统执行P0,初始化系统硬件和内核数据结构。然后挂载一个根文件系统,使得系统可以使用文件。然后P0复刻出一个子进程P1,并把进程切换为用户模式运行P1。
INIT和守护进程
P1通常被成为INIT进程。P1开始复刻出许多子程序。P1的大部分子进程都是用来提供系统服务的,在后台运行,不与任何用户交互,成为守护进程。
登录进程
除了守护进程外,P1还复刻出了许多LOGIN进程,每个终端一个,用于用户登录。
每个LOGIN进程打开三个与自己终端相关联的文件流。这三个文件流是用于标准输入的stdin、用于标准输出的stdout和用于标准错误消息的stderr。
每个文件流都是指向进程堆区的FILE结构体指针,每个结构体记录一个文件描述符(数字)。stdin的是0,stdout是1,stderr是2。
每个LOGIN进程向stdout显示一个login:
等待用户登录。用户账户保存在/etc/passwd和/etc/shadow文件中。每个用户账户在表单的/etc/passwd文件中都有一行对应的记录:
name:x:gid:uid:description:home:program
- name是用户登陆名
- x是登录检查密码
- gid是用户组ID
- uid是用户ID
- home是用户主目录
- program是用户登录后执行的初始程序
其他用户信息保存在/etc/shadow文件中。当用户尝试使用登录名和密码登录时,Linux将检查/etc/passwd文件和/etc/shadow文件(有点像PIN码这里感觉,不知道是不是),以验证用户的身份。
sh进程
当用户成功登陆时,LOGIN进程会获取用户的gid和uid,从而成为用户的进程。它将目录更改为用户的主目录并执行列出的程序。
用户进程执行sh,故用户进程通常成为sh进程。cd、退出、注销等由sh自己执行。对于每个(可执行)文件的命令,sh会复刻一个子进程,并等待子进程终止。子进程将其执行映像更改为命令文件并执行命令程序。子进程在终止时会唤醒父进程sh。除简单的命令外,sh还支持I/O重定向和通过管道连接的多个命令。
进程的执行模式
在Unix/Linux中,进程以两种不同的模式执行,即内核模式(Kmode)和用户模式(Umode)。

Umode进程只能通过一下三种方式进入Kmode:
(1)中断:外部设备发送给CPU信号,请求CPU服务。当在Umode下执行时,CPU中断是启用的。在发生中断时,CPU进入Kmode处理中断。
(2)陷阱:陷阱是错误条件,例如无效地址、非法指令、除以0等。CPU进入Kmode来处理错误。
(3)系统调用(syscall):是一种允许Umode进程进入Kmode以执行内核函数的机制。当某进程执行完内核函数后,它将期望结果和一个返回值返回Umode,该值通常为0(成功),-1(错误)。
进程管理的系统调用
int syscall(int a,int b,int c,int d);
a表示系统调用号,b,c,d表示对应核函数的参数。
fork()
Usage:int pid=fork();
fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,并返回子进程的pid,如果失败返回0。也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
下图为调用了一次fork之后的示意图:
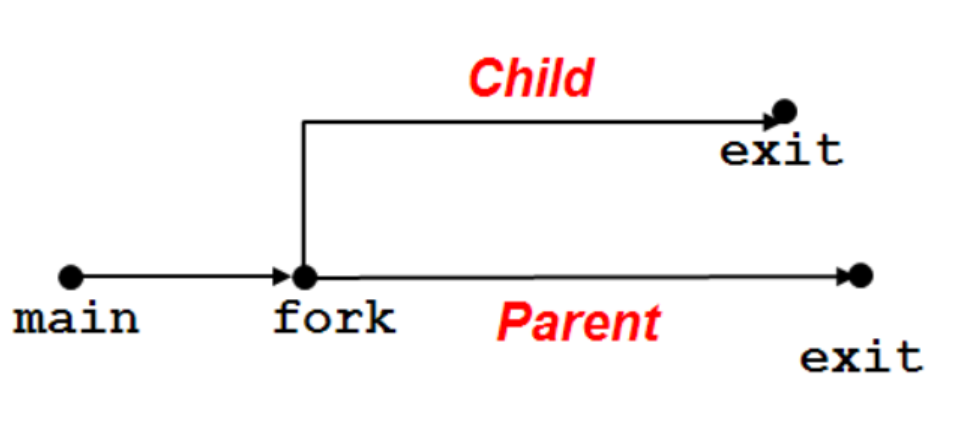
以下面的代码为例:
int main(){
printf("it's the main process step 1!!\n\n");
fork();//创建一个新的进程
printf("step2 after fork() !!\n\n");
int i;
scanf("%d",&i);//防止程序退出
return 0;
}
运行结果如下:

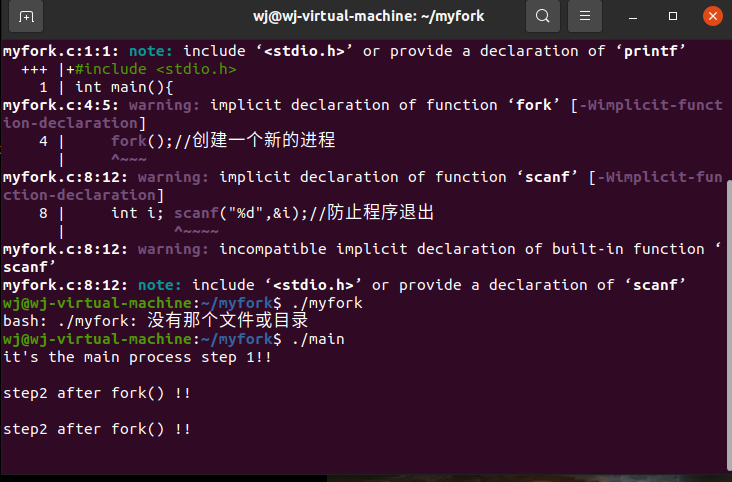
我们来分析一下以上的代码:程序在fork()函数之前只有一条主进程,所以只打印一次step 1;而执行fork()函数之后,程序分为了两个进程,一个是原来的主进程,另一个是fork()的新进程,他们都会执行fork()函数之后的代码,所以step 2打印了两次。所以有两次的step2 after fork() !!输出。
我们再使用课本给出的代码,加强理解:
#include<stdio.h>
int main()
{
int pid;
printf("this is %d my parent=%d\n",getpid(),getppid());
① pid=fork();
if(pid){
② printf("this is process %d child pid=%d\n",getpid(),pid);
}
else
{
③ printf("this is process %d parent=%d\n",getpid(),getppid());
}
}
编译结果如下:
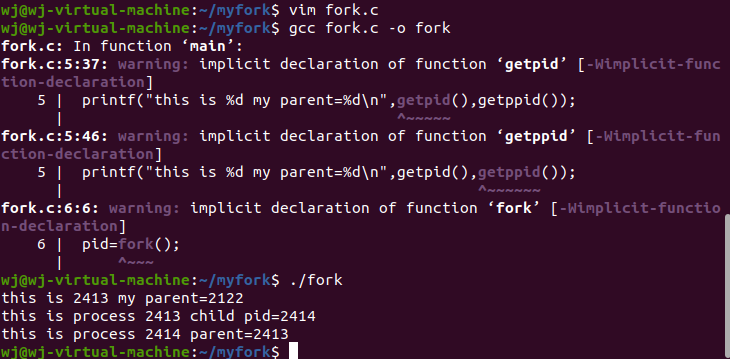
该程序由sh的子进程运行。在代码中,getpid()和getppid()是系统调用。getpid()返回调用进程的PID,getppid()返回父进程的PID。
- 第①行复刻一个子进程;
- 第②行打印正在执行进程的PID和新复刻子进程的PID;
- 第③行打印子进程的PID,应与第②行中子、父进程的PID相同。
进程执行顺序
在fork()完成后,子进程与父进程和系统中所有其他进程竞争CPU运行时间。接下来运行哪个程序取决于它们的调度优先级(呈动态变化)。
#include<stdio.h>
int main()
{
int pid=fork();
if(pid)
{
printf("parent %d child=%d\n",getpid(),pid);
①//sleep(1);
printf("parent %d exit\n",getpid());
}
else
{
printf("child %d start my parent=%d\n",getpid(),getppid());
②//sleep(2);
printf("child %d exit my parent=%d\n",getpid(),getppid());
}
}
(1)取消第一行注释,让父进程休眠1秒钟,可发现子进程先行运行完成。
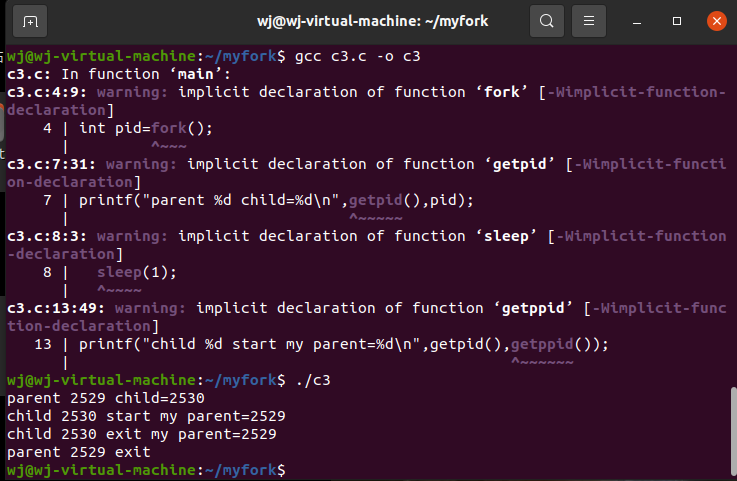
(2)取消第二行注释,但不取消第一行注释,让子进程休眠2秒钟。
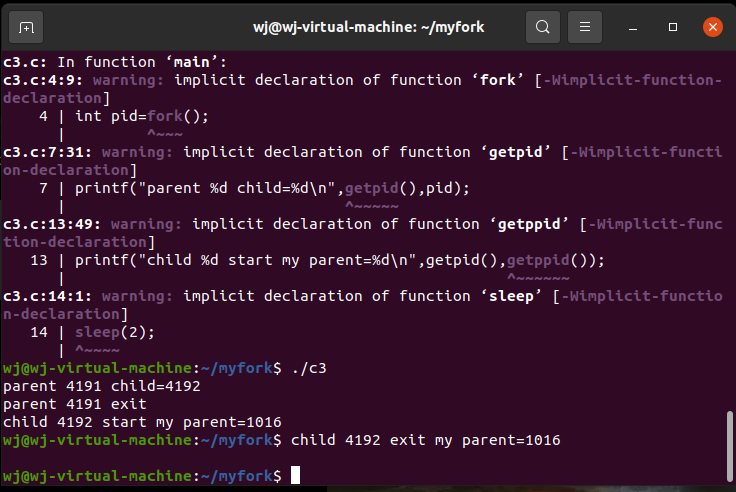
(3)取消第一行和第二行的注释,结果和第二行一样。

除了sleep(seconds)可以让调用进程延迟几秒外,Unix和Linux还提供以下系统调用方式,可能会影响系统的执行顺序。
nice(int nic):nice将进程优先级值增大一个指定值,这会降低进程调度的优先级。优先级值越大,证明进程优先级越低。sched_yield(void):使调度进程放弃使用CPU,允许优先级更高的其他进程先运行。
进程终止
执行程序映像的进程可能以两种方式终止:
(1)正常终止。每个C程序的main函数都是由C启用代码crt0.o调用的,如果程序执行成功,main()最终会返回到crt0.o,调用库函数exit(0)来终止进程。首先,exit(value)函数会执行一些清理工作,随后,其发出一个系统调用,使进入操作系统内核的进程终止。退出0通常表示正常终止。当内核中的某个进程终止时,它会将_exit(value)系统调用中的值记录为进程PROC结构体中的退出状态。并通知其父进程并使该进程成为僵尸进程。pid=wait(int *status);父进程可通过系统调用找到僵尸子进程,获得其pid和退出状态。它还会清空僵尸子进程PROC结构体,使该结构可被另一个进程重用。
(2)异常终止。在执行某程序时,进程可能会遇到错误,如非法指令、越权、除零等。这些错误会被CPU识别为异常。当出现异常时,它会进入操作系统内核,内核的异常处理程序将陷阱错误类型转化为一个幻数,称为信号,将信号传递给进程,使进程终止,此时僵尸进程的退出状态是信号编号。除了陷阱错误,信号也可能来自硬件或其他进程。eg:按下“Ctrl+C”组合键会产生一个硬件中断信号。
或者,用户可以使用命令:
kill -s signal_number pid通过向pid识别的目标发送信号。对于大多数信号数值,进程的默认操作是终止。
在这两种情况下,当进程终止时,最终都会在操作系统内核中调用kexit()函数。唯一的区别是Unix/Linux内核将擦除终止进程的用户模式映像。
在Linux中,每个PROC都有一个2字节的退出代码(exitCode)字段,用于记录进程退出状态。如果进程正常终止,exitCode的高字节位是_exit(exitValue)系统调用中的exitValue。低字节位是导致异常终止的信号数值。因为一个进程只能死亡一次,所以只有一个字节有意义。
等待子进程终止
在任何时候,一个进程都可以使用
int pid=wait(int *status);
系统调用,等待僵尸子进程。如果成功,则wait()会返回僵尸子进程的PID,而且status包含僵尸子进程的exitCode。此外,wait()还会释放僵尸子进程,以供重新使用。
在linux中输入以下代码:
#include<stdio.h>
#include<stdlib.h>
int main()
{
int pid,status;
pid=fork();
if(pid)
{
printf("parent %d waits for child %d to die\n",getpid(),pid);
pid=wait(&status);
printf("dead child =%d,status=0x%04x\n",pid,status);
}
else{
printf("child %d dies by exit(VALUE)\n",getpid());
exit(100);
}
}
运行结果如下图所示:
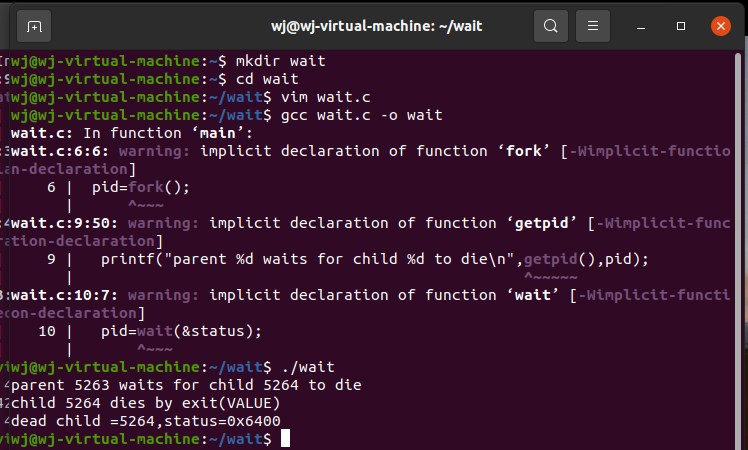
Linux中的subreaper进程
在linux中编译运行以下代码:
#include <stdio.h>
#include <unistd.h>
#include <wait.h>
#include <sys/prctl.h>
int main()
{
int pid,r,status;
printf("mark process %d as a subreaper\n",getpid());
r = prctl(PR_SET_CHILD_SUBREAPER);
pid = fork();
if(pid)
{
printf("subreaper %d child = %d\n", getpid(), pid);
while (1)
{
pid = wait(&status);
if (pid > 0)
printf("subreaper %d waited a ZOMBIE=%d\n",getpid(), pid);
else
break;
}
}
else
{
printf("child %d parent = %d\n", getpid(), (pid_t)getppid());
pid = fork();
if (pid)
{
printf("child=%d start: grandchild=%d\n", getpid(),pid);
printf("child=%d EXIT: grandchild=%d\n",getpid(),pid);
}
else
{
printf("grandchild=%d start:myparent=%d\n",getpid(),getppid());
printf("grandchild=%d EXIT:myparent=%d\n", getpid(),getppid());
}
}
}
运行结果如下图所示:

exec()更改进程执行映像
进程可以使用exec()将其Umode映像更改为不同的(可执行)文件。
int execve(const char *filename,char *const argv[],char *const envp[]);
在execve系统调用中,第一个参数文件名与当前工作目录(CWD)或绝对路径名有关。参数argv[]是一个以NULL结尾的字符串数组指针,每个指针指向一个命令行参数字符串。按照惯例,argv[0]是程序名,其他argv[]项是程序的命令行参数。
例如: a.out one two three
其布局为: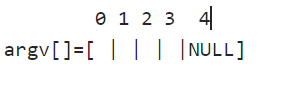
环境变量
环境变量是当前sh定义的变量,由子sh或进程继承。当sh启动时,环境变量便在登录配置文件和.bashrc脚本文件中设置。它们定义了后续程序的执行环境。各环境变量定义为:关键字=字符串
在sh会话中,用户可使用env或printenv命令查看环境变量,如图:

SHELL:指定将解释任何用户命令的sh
TERM:指定运行sh时要模拟的终端类型
USER:当前登录用户
PATH:系统在查找命令时将检查的目录列表
HOME:用户的主目录。在Linux中,所有用户主目录都在/home中
HOME=/home/newhome
exec函数族
#include <unistd.h>
int execl(const char *pathname, const char *arg0, ... /* (char *)0 */ );
int execv(const char *pathname, char *const argv[]);
int execle(const char *pathname, const char *arg0, .../* (char *)0, char *const envp[] */ );
int execve(const char *pathename, char *const argv[], char *const envp[]);
int execlp(const char *filename, const char *arg0, ... /* (char *)0 */ );
int execvp(const char *filename, char *const argv[]);
int fexecve(int fd, char *const argv[], char *const envp[]);
exec系列函数共有7个函数可供使用,这些函数的区别在于:指示新程序的位置是使用路径还是文件名,如果是使用文件名,则在系统的PATH环境变量所描述的路径中搜索该程序;在使用参数时使用参数列表的方式还是使用argv[]数组的方式。
filename必须是一个二进制的可执行文件,或者是一个脚本以#!格式开头的解释器参数参数。如果是后者,这个解释器必须是一个可执行的有效的路径名,但是不是脚本本身,它将调用解释器作为文件名
execl()函数
execl()函数用来执行参数path字符串所指向的程序,第二个及以后的参数代表执行文件时传递的参数列表,最后一个参数必须是空指针以标志参数列表为空。
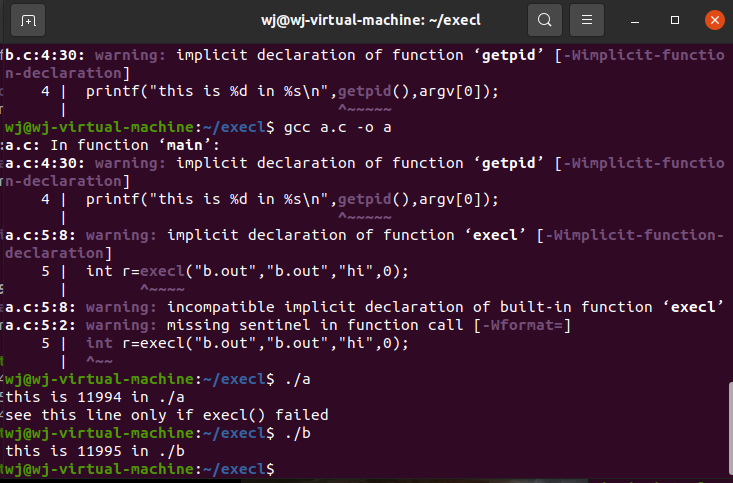
运行课本所给程序:
b.c:
#include<stdio.h>
int main(int argc,char *argv[])
{
printf("this is %d in %s\n",getpid(),argv[0]);
}
a.c:
#include<stdio.h>
int main(int argc,char *argv[])
{
printf("this is %d in %s\n",getpid(),argv[0]);
int r=execl("b.out","b.out","hi",0);
printf("see this line only if execl() failed\n");
}
运行结果如下:
execv()函数
execve()函数函数用来执行参数path字符串所指向的程序,第二个为数组指针维护的程序参数列表,该数组的最后一个成员必须是空指针。
编写以下代码:
execve.c
#include<stdio.h>
#include<unistd.h>
int main(int arg, char **args)
{
char *argv[]={"ls","-al","/home/wj", NULL};
char *envp[]={0,NULL}; //传递给执行文件新的环境变量数组
execve("/bin/ls",argv,envp);
}
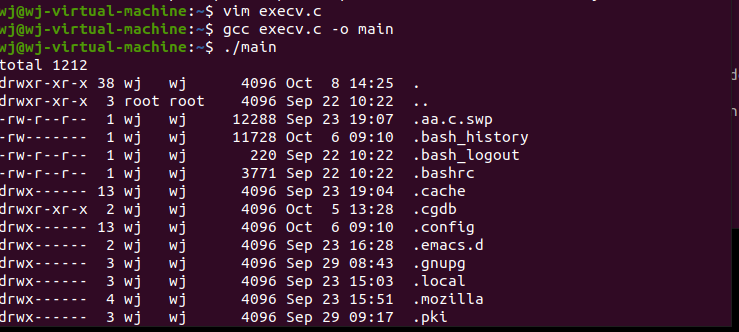
I/O重定向
文件流和文件描述符
sh进程有三个用于终端I/O的文件流:stdin、stdout、stderr。每个流都是指向可执行映像堆区中FILE结构体中的一个指针。
通过open函数打开一个文件,可以得到一个存储该文件所有属性的结构体(类似于标准io的FILE),但是又不完全像标准io,系统io的open会将这个结构体的指针存放到一个数组(文件描述符表)中,然后返回这个指针在数组中的下标,而是一个int值(不像fopen返回一个FILE*),即fd。之后就通过操作这个fd来操作文件。每个文件流对应Linux内核中的一个打开文件。每个打开文件都用一个文件描述符(数字)表示。stdin、stdout、stderr的文件描述符分别为0、1、2。
scanf("%s",&item);
它会从stdin文件输入一个(字符串)项,指向FILE结构体。如果FILE结构体的fbuf[]为空,它会向Linux内核发出read系统调用,从文件描述符0中读取数据,映射到终端或者伪终端的键盘上。
open/close
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int close(int fd);
参数flags必须包含下面三个中的一个: O_RDONLY, O_WRONLY, O_RDWR。另外,0或多个文件创建选项和文件状态选项可以以按位或(|)的形式加入到flags中,常用的有以下几个:
- O_CREAT 文件不存在时会创建
- O_TRUNC 文件存在且用只写或读写打开,则将文件截断为0长度
- O_EXCL 如果文件存在则报错,用来测试文件存不存在。一般常和O_CREAT一起用,不存在就创建
- O_APPEND 写入时在文件尾追加
- O_NONBLOCK 以非阻塞的方式打开,如果需要等待就不排队,过后再打开。阻塞地打开就是排队等待直到打开为止
如果用标准io的fopen里的打开方式来比拟的话:
- r -> O_RDONLY
- r+ -> O_RDWR
- w -> O_WRONLY | O_CREAT | O_TRUNC
- w+ -> O_RDWR | O_CREAT | O_TRUNC
- a -> O_APPEND | O_CREAT
- a+ -> O_RDWR | O_APPEND | O_CREAT
read/write
ssize_t read(int fd, void *buf, size_t count);
从fd中读count个内容放入buf中
ssize_t write(int fd, const void *buf, size_t count);
从buf中取出count个内容写入fd。注意这里的buf是const的,因为这里的buf是取内容的,我们不能更改它,而read要更改buf
ead成功会返回读到的字节数,读到文件尾就返回0,如果失败就返回-1,并且设置errno
write成功会返回成功写入的字节个数,如果返回0表示什么都没写进去,返回-1表示出错。
dup/dup2
int dup(int oldfd);
int dup2(int oldfd, int newfd);
//dup2会先关掉newfd的文件,然后复制oldfd的指针到newfd处
像下图这样,dup会拷贝数组中oldfd的指针,然后放到数组可用范围中下标最小的且没用过的位置,然后返回这个新的文件描述符。成功后两个fd都会指向同一个文件表现,如果失败返回-1。
完成上述任何一项操作之后,文件描述符0将被替换或复制到打开文件中,以便每个scanf()调用都将从打开的文件中获取输入。
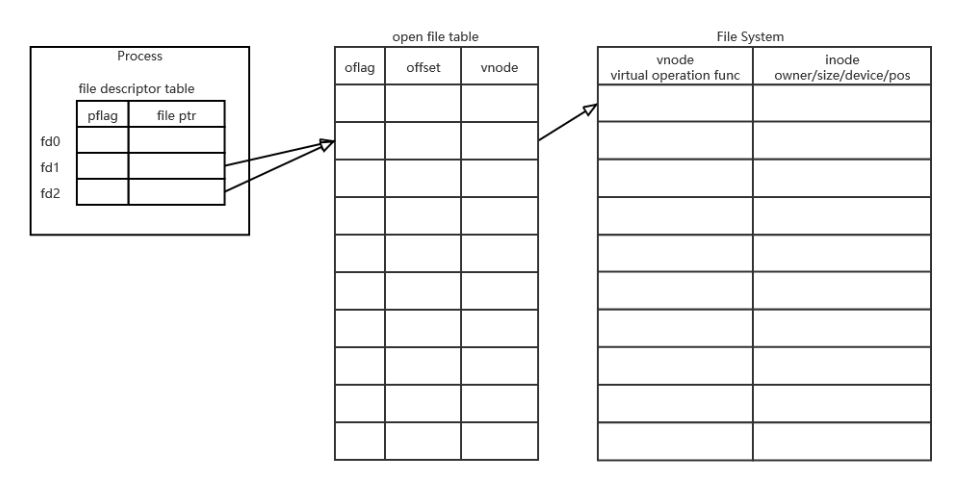
参考博客:https://blog.csdn.net/weixin_43318827/article/details/121065230
管道
管道是是Linux由Unix那里继承过来的进程间的通信机制,它是Unix早期的一个重要通信机制。其思想是,在内存中创建一个共享文件,从而使通信双方利用这个共享文件来传递信息。由于这种方式具有单向传递数据的特点,所以这个作为传递消息的共享文件就叫做“管道”。管道时用于进程交换数据的单向进程件通信通道。管道有一个读取端和一个写入端。
管道命令处理
cmd1 | cmd2
sh将通过一个进程运行cmd1,并通过另一个进程运行cmd2,他们通过一个管道连接在一起,因此cmd1的输出变为cmd2的输入.
命令管道
命令管道又叫FIFO
(1)在sh中,通过mknod命令创建一个命令管道:
(2)或在c语言中发出mknod()系统调用
(3)进程可像访问普通文件一样发个文命名管道。一般用mknod创建管道,为什么不用touch呢?因为touch 只能创建普通文件,像管道、字符设备、块设备等特殊文件就要用 mknod 了
使用命令:mknod pipe1 p创建管道,用ls -l进行查看
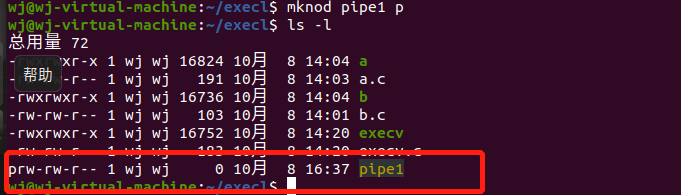
ls -l pipe1

实现myshell
运行结果如下:
可以模拟sh对于命令的执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号