
这周我学习了教材第九章,另外还在虚拟机下载了vscode、openeuler系统
1. 在终端键入tree 可以显示ubuntu系统中各个文件存放的位置与从属关系
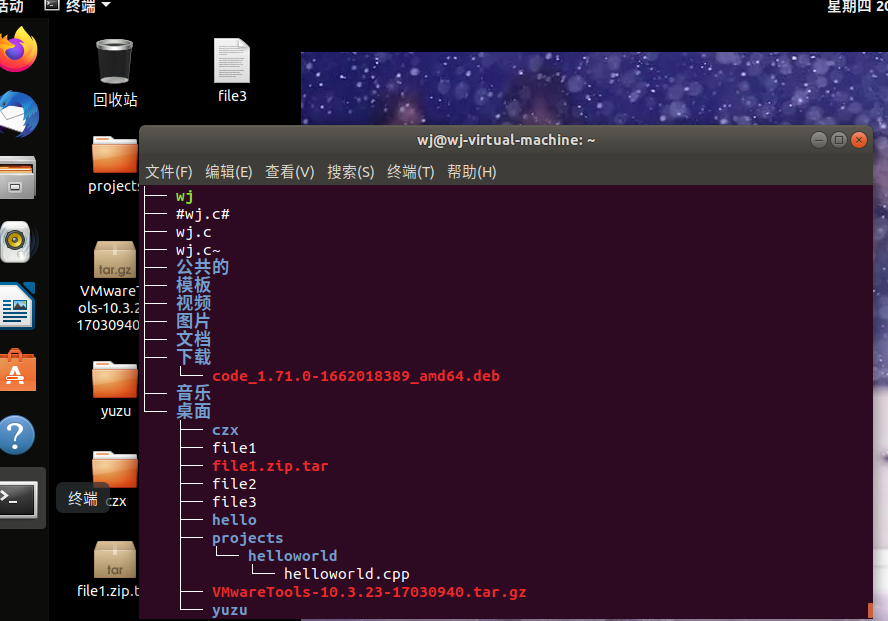
之前创建了一个project文件夹,里边又创建了一个helloworld子文件夹,子文件夹里包含了一个helloworld.c程
序,用“tree”命令可以较为清楚地看到几个文件间的从属关系
2. 打开vscode,在终端输入emacs使用emacs进行程序的
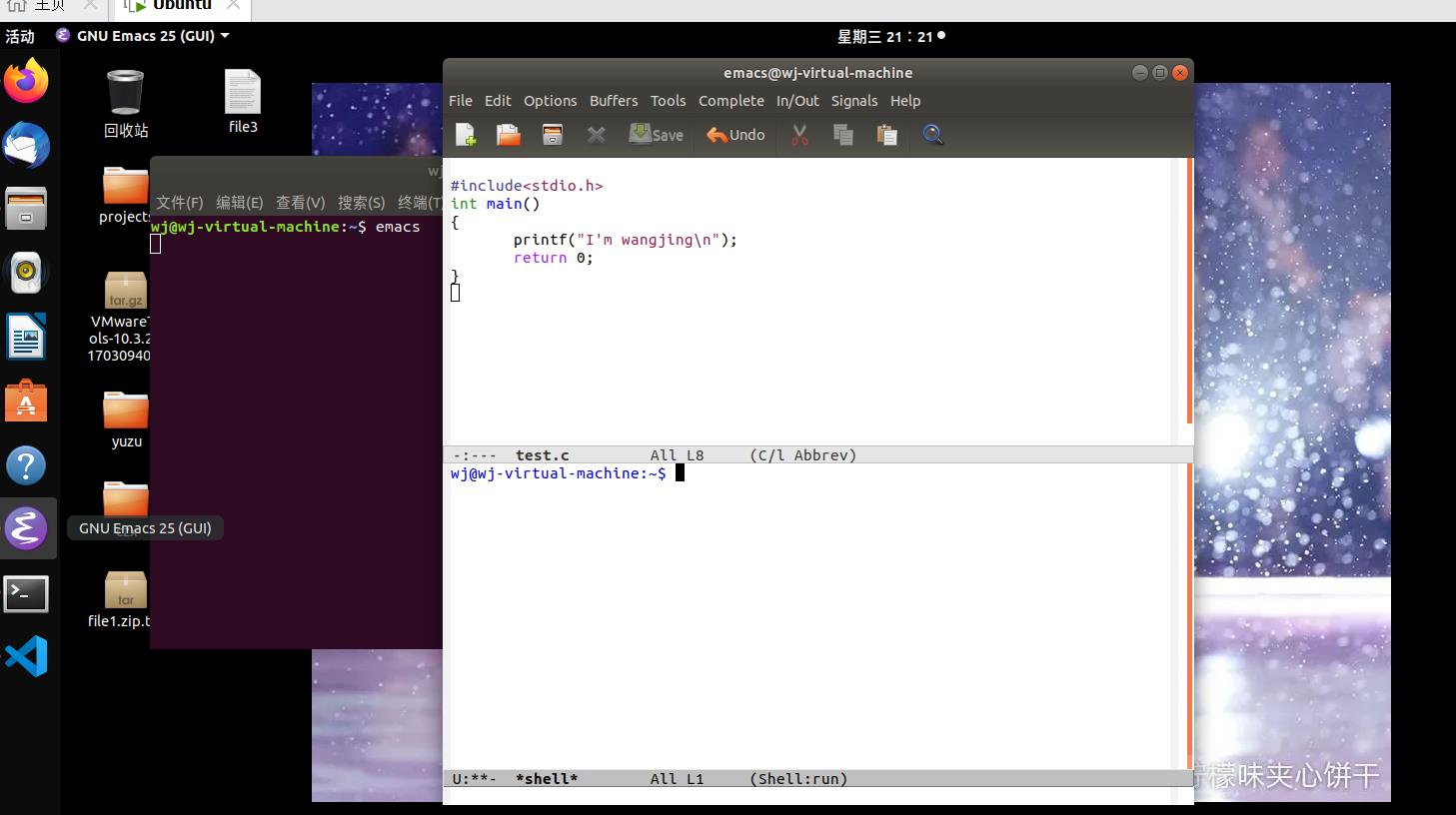
使用“ gcc -Wall -o hello hello.c对hello.c文件进行编译
再输入./hello即可运行
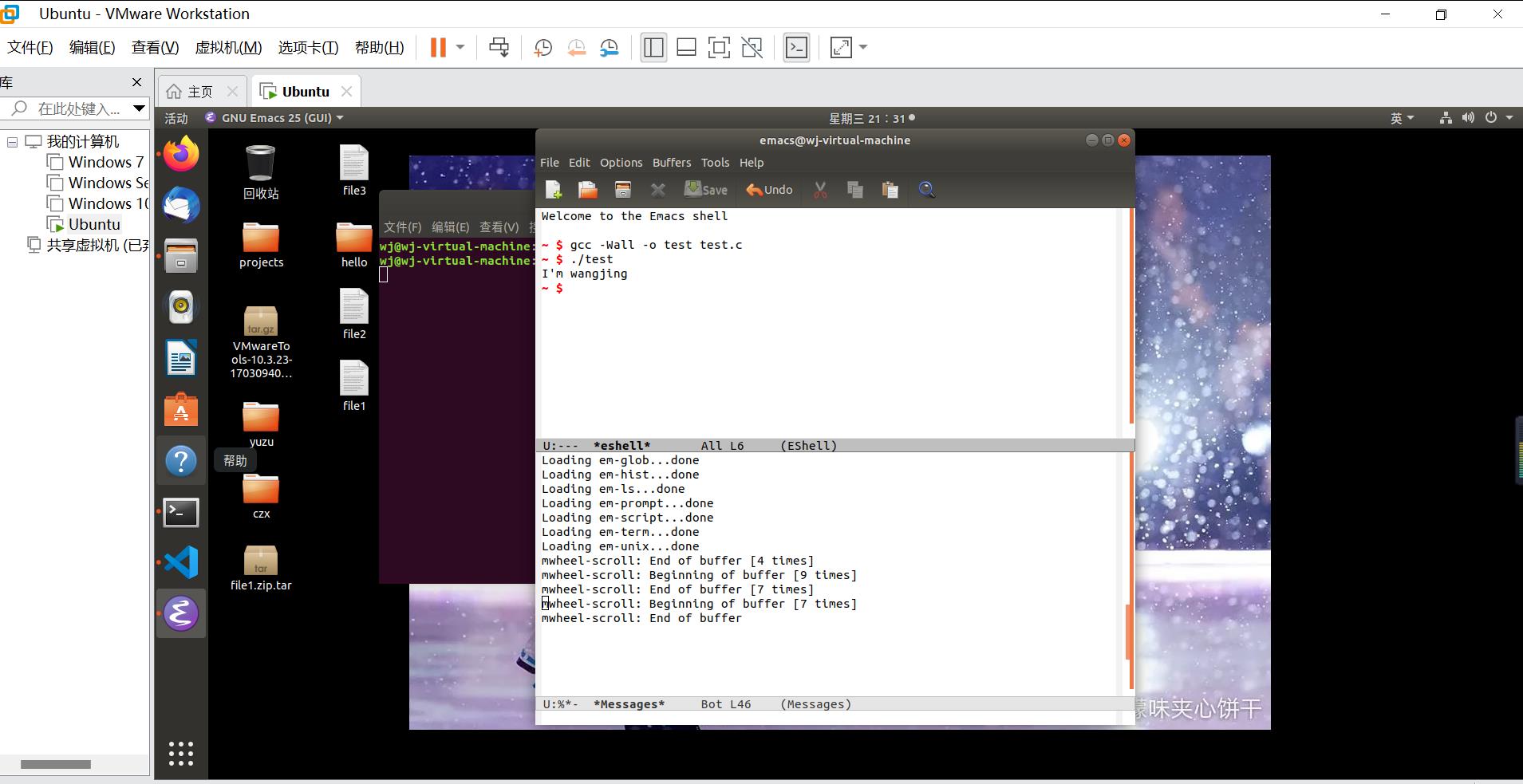
根据课本第九章相关作业要求,编写代码,实现统计文件中单词的数目:
文件内容如下:
统计出该文件一共有7个单词
编写代码,实现文件的写入和读出到数组内后输出到屏幕
代码如下:
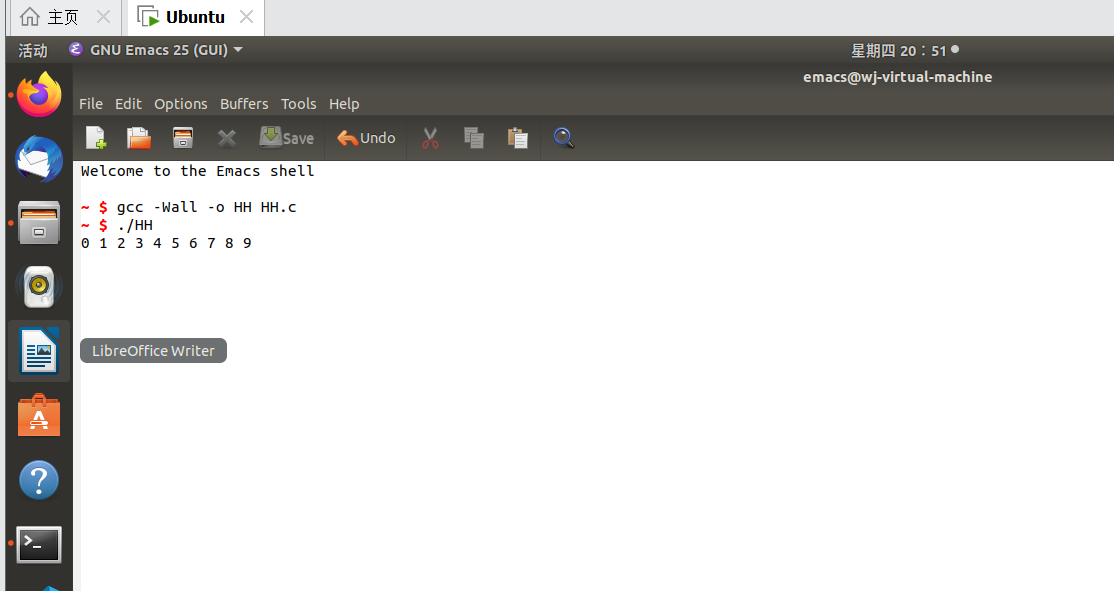
可以发现输出了“1 2 3 4 5 6 7 8 9”
我们再查看a.txt中的内容,发现已经改变为“1 2 3 4 5 6 7 8 9”

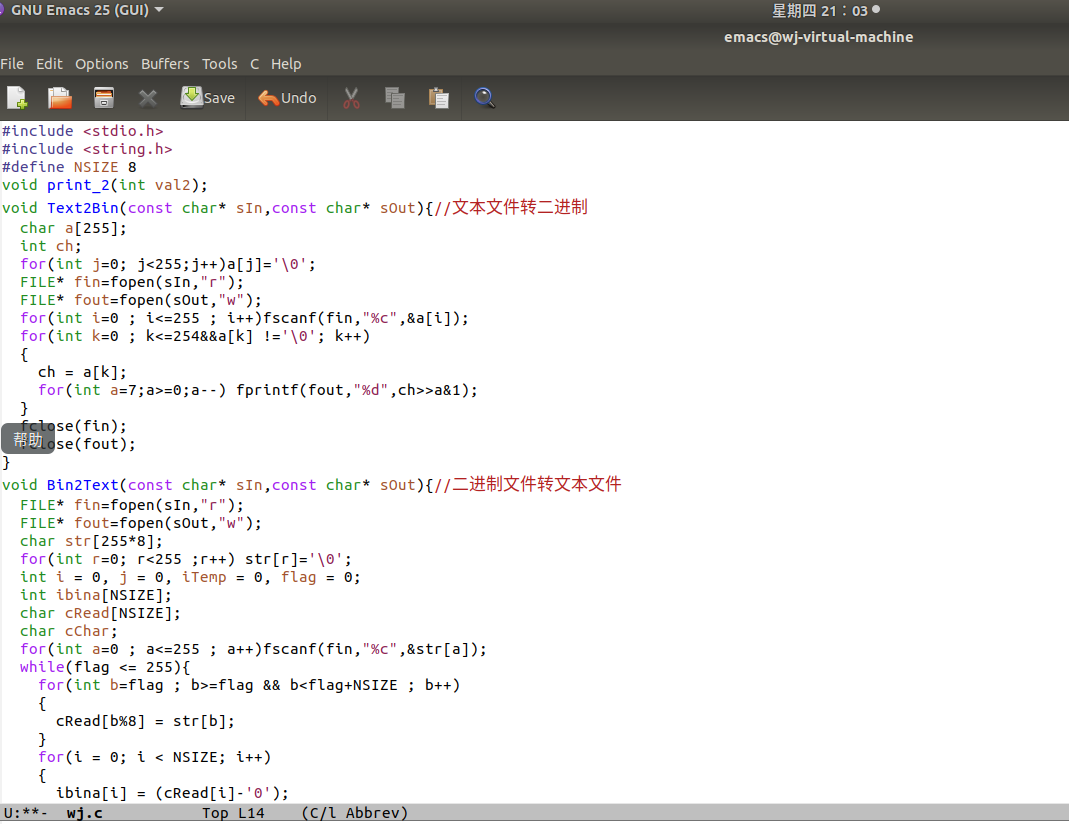
编写代码,实现文本文件向二进制文件的转换:
代码如下:
转化结果:
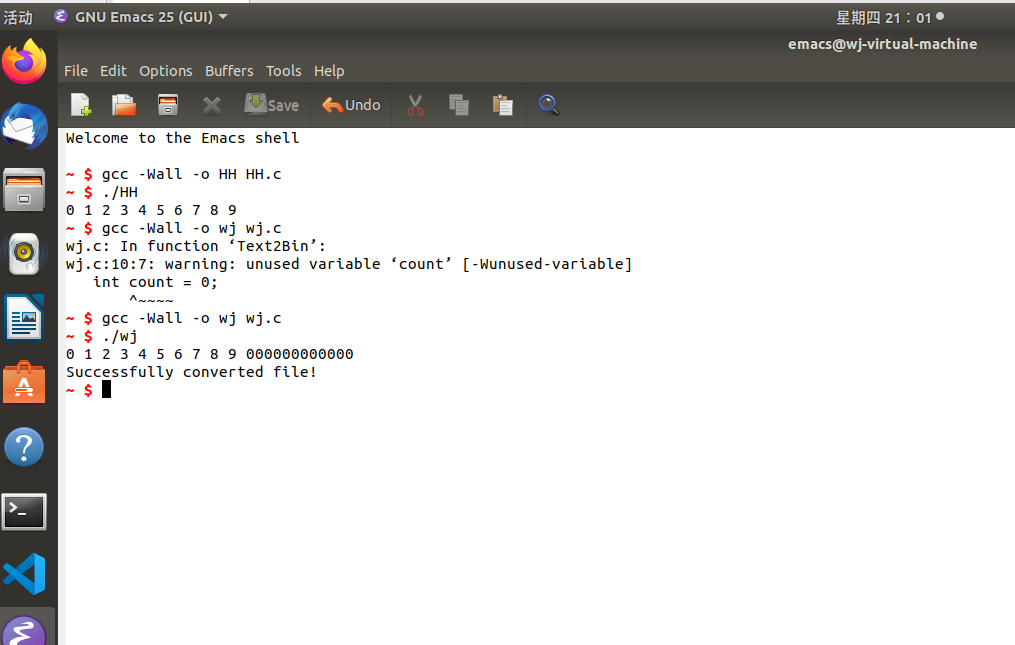
原来a1.txt中的文本文件转化成二进制文件后存于a2.txt中
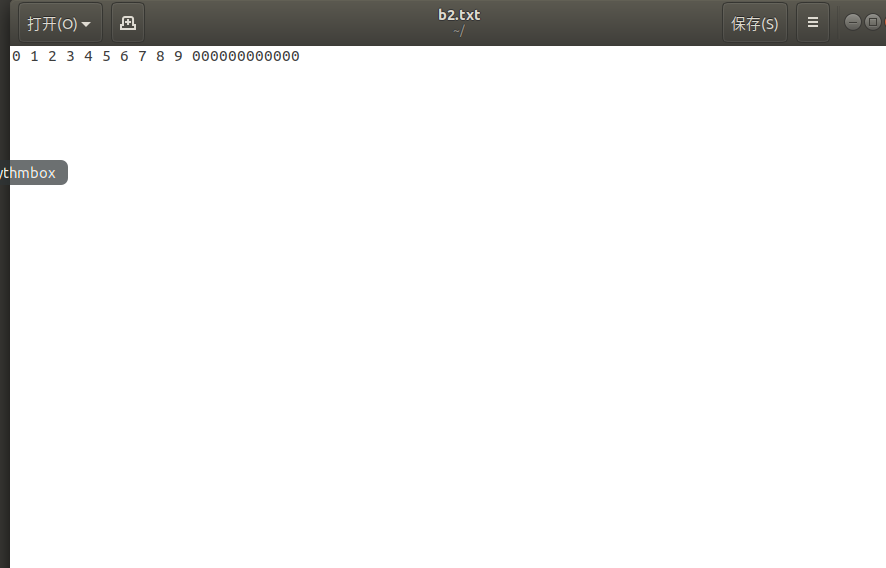
a2.txt中的转化结果为一串0、1数字:
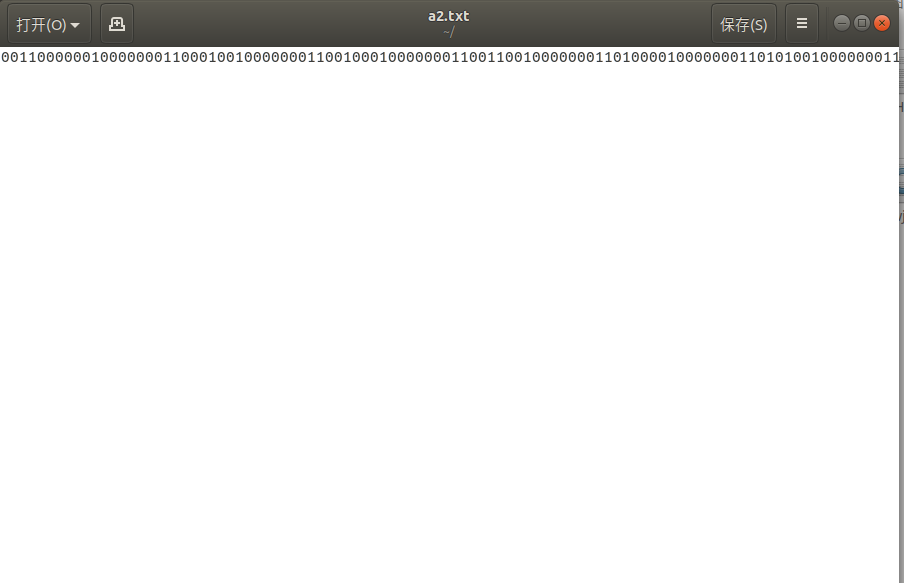
a2.txt中的二进制文本经过转化后,内容存于b2.txt中:
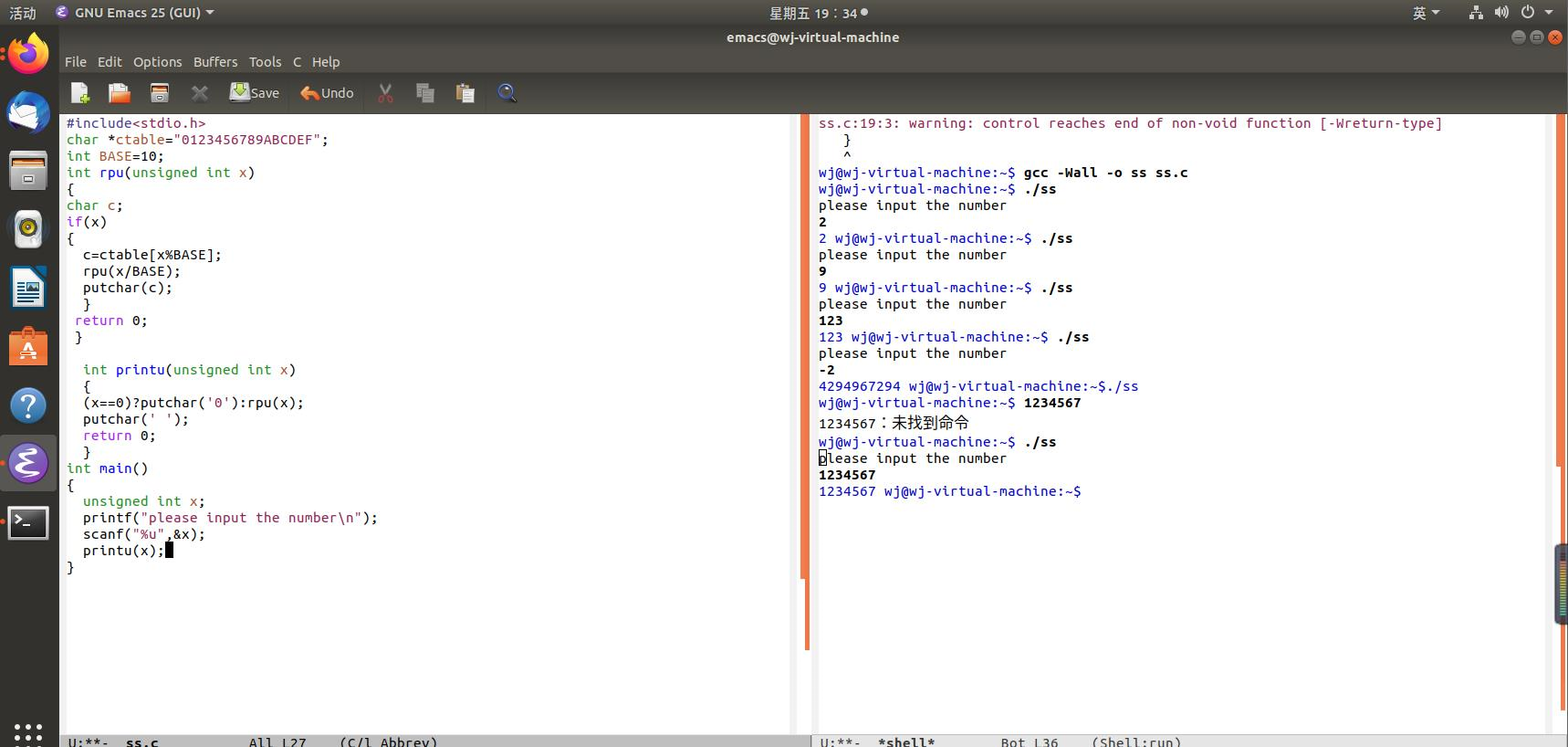
编写代码,实现十进制无符号整数的打印(以字符的形式输出)
书本上的代码如下:
char *ctable="0123456789ABCDEF";
int BASE=10;
int rpu(unsigned int x)
{
char c;
if(x){
c=ctable[x%BASE];
rpu(x/BASE);
putchar(c);
}
}
int printu(unsigned int x)
{
(x==0)?putchar('0'):rpu(x);
putchar(' ');
}
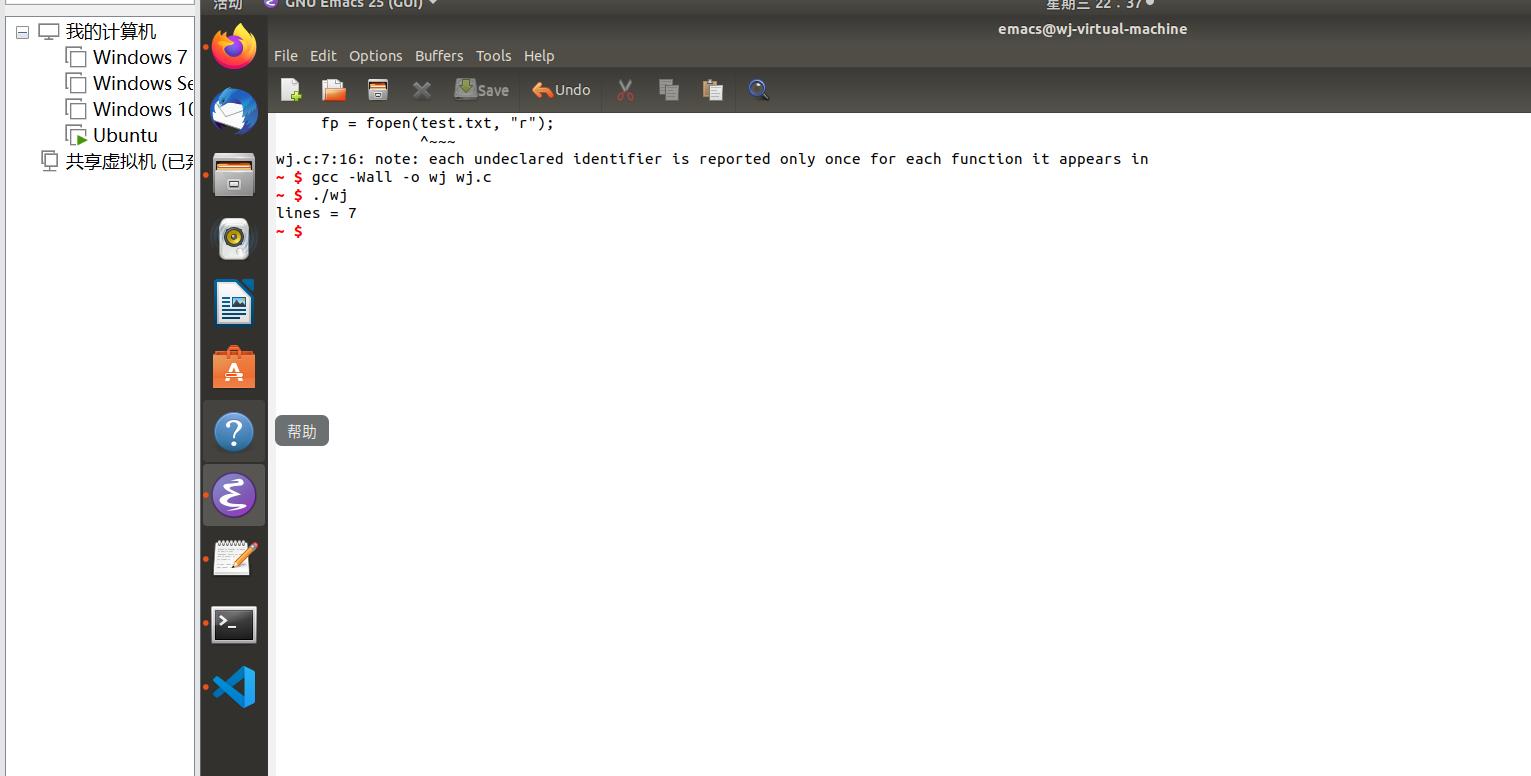
将其直接输入在emacs中还存在很多问题
经过查找后发现,其实这个问题是由于编译软件使用的不同导致的,平时我用的是dev c++和codeblocks,其实一般
不用写return ,emacs中就由于这个报错,我加上返回值后发现可以正常编译了
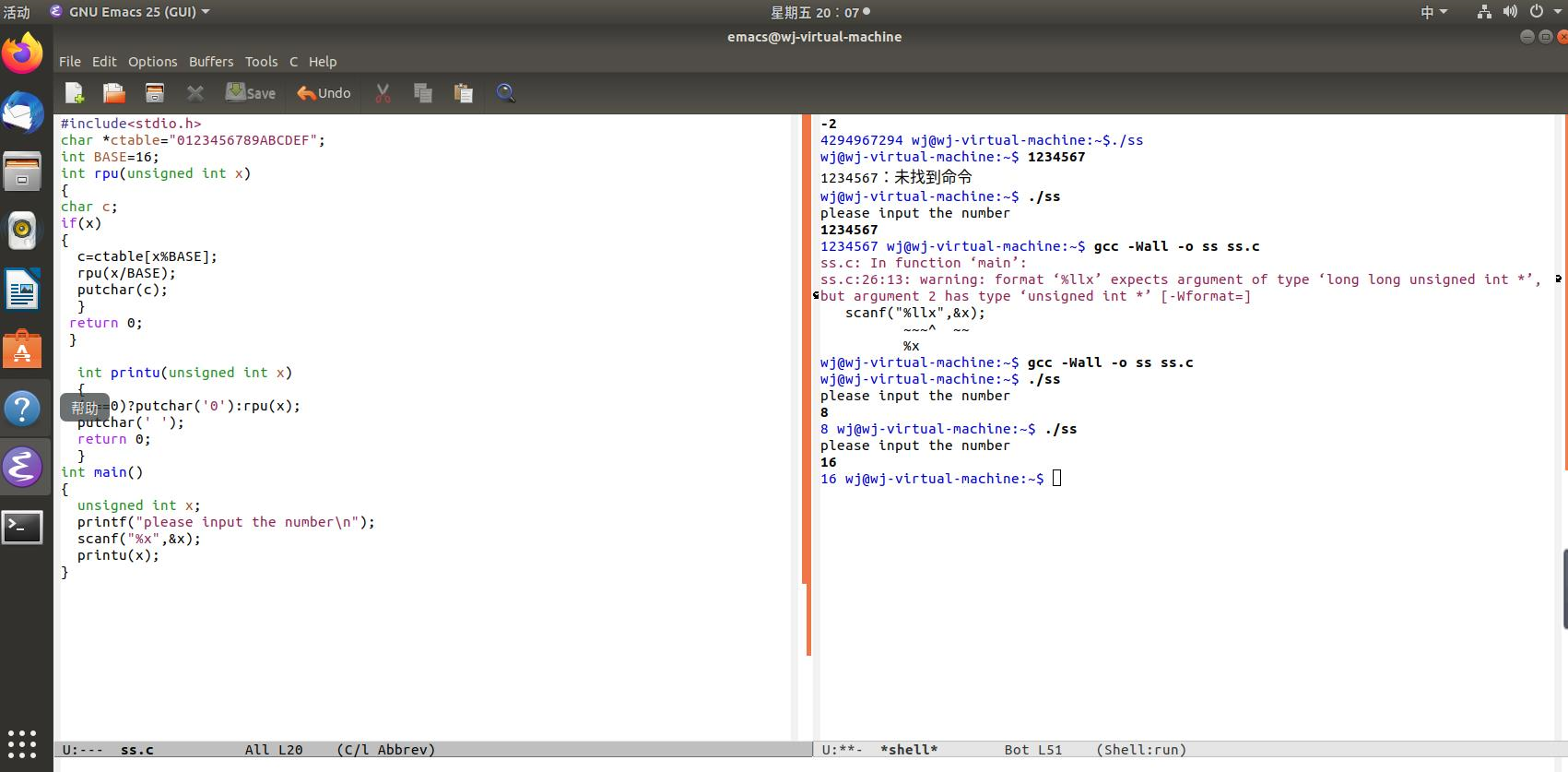
编写代码,实现十六进制无符号整数的打印:
编写代码,实现二进制向十进制数字的转换
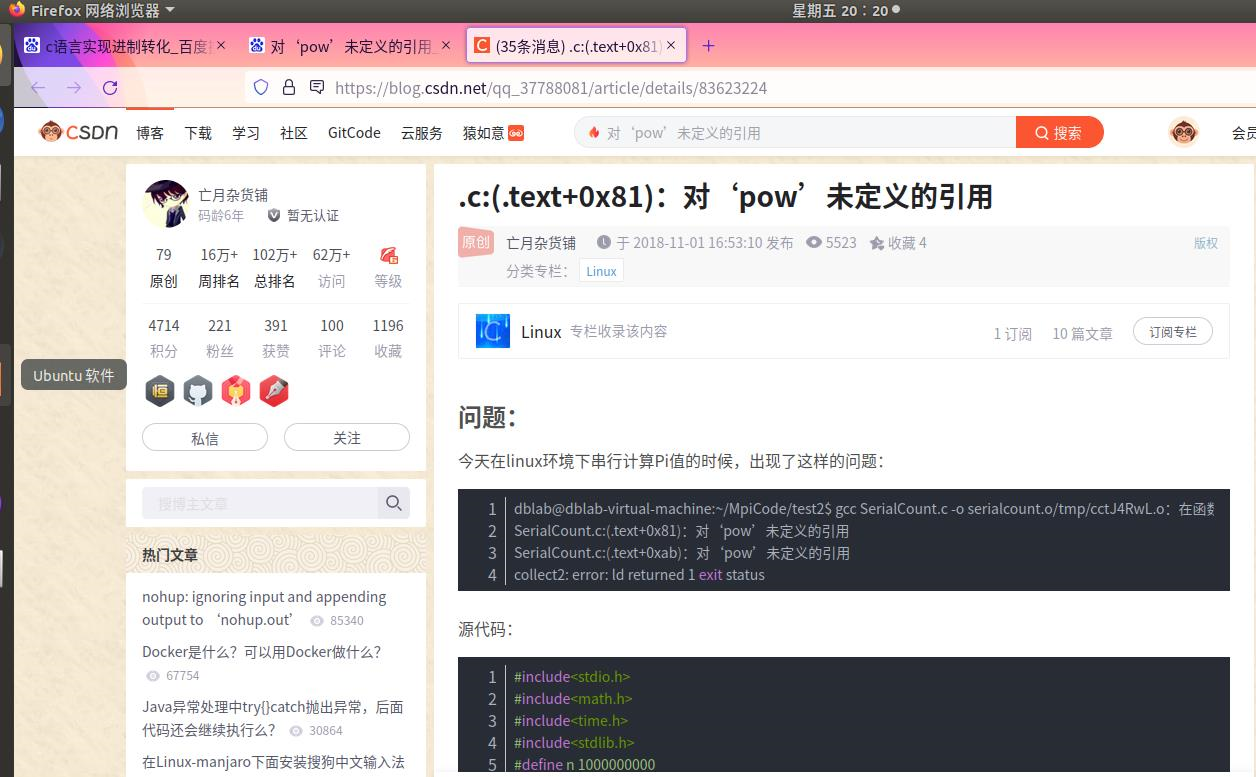
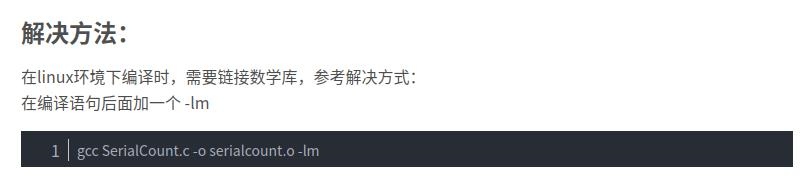
我在刚开始编写代码时,明明已经加了头文件“include<math.h>”,但是后来还是出现报错,说我的pow没有定义,我上网查找原因,原来是因为没有这个库,网上的解决办法是在后缀加一个-lm,我尝试后发现成功编译。
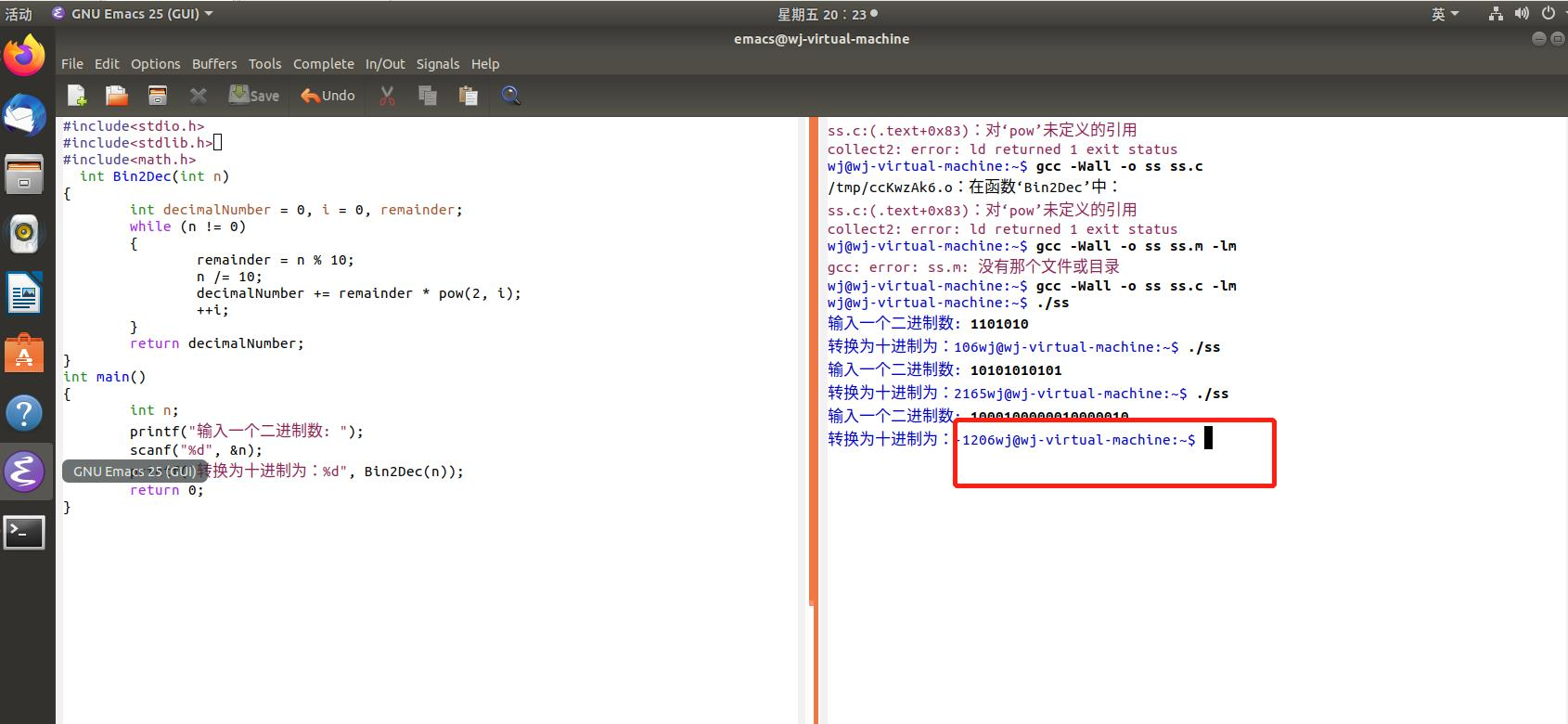
后来发现这个代码还有待改进,比如会出现溢出的情况,超过了整型的最大表示范围。
3.在虚拟机中下载openeuler系统,问题的解决过程及相关的配置完成过程
我参考以下链接下载了openeuler系统
https://blog.csdn.net/hhs_1996/article/details/123030055
这里一定要注意选择第一个选项,云班课也有同学进行了提醒,光标默认的是第二项,我们移动光标的方法是按住键盘
的“上”、“下”键,就可以进行相关的移动了
在输入完后,系统会自动进行安装,一定要预留好足够的空间给虚拟机,否则还需要重新来过,比较麻烦。
设置好root密码后,我们静静等待其进入下图界面:
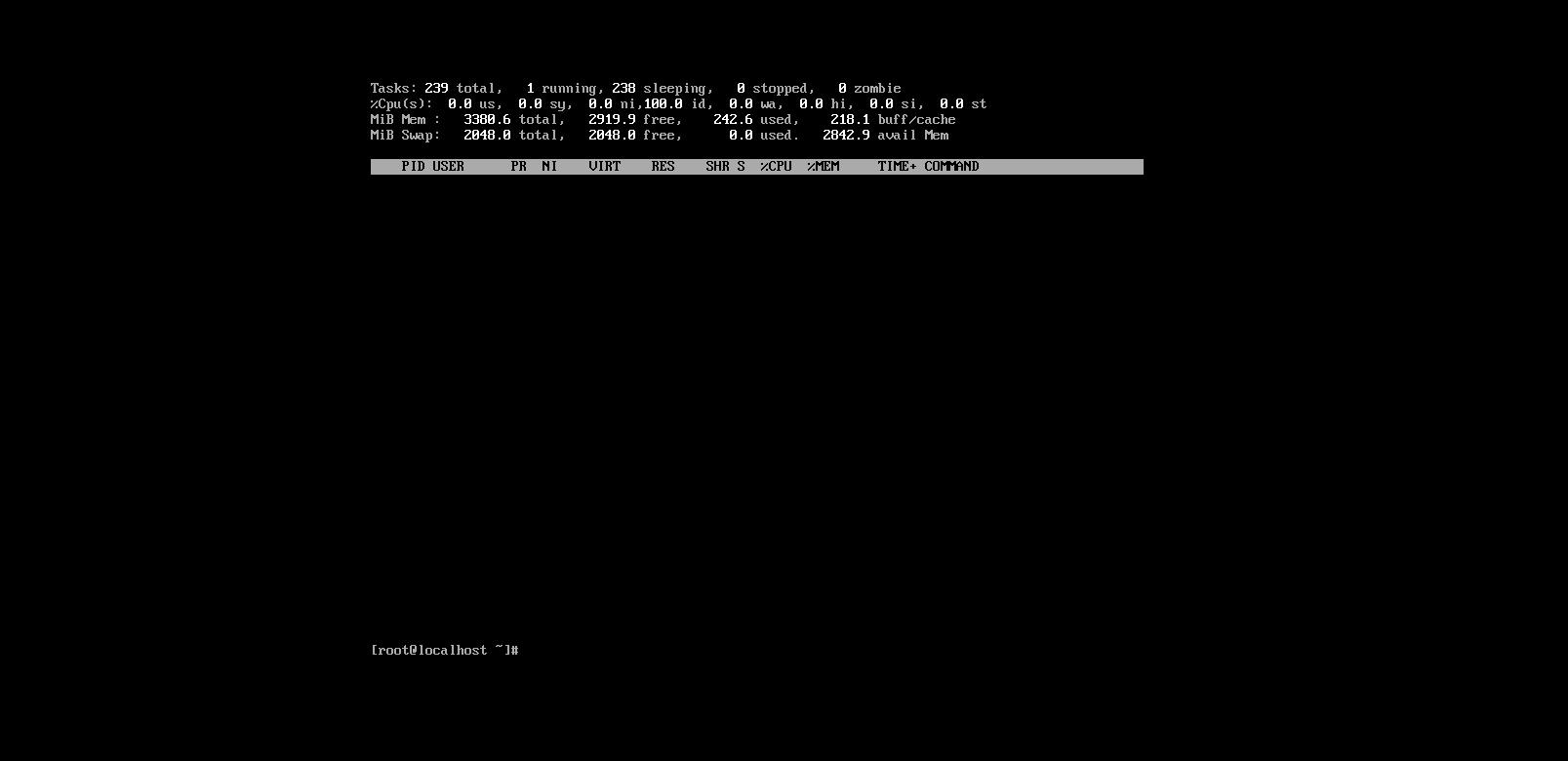
用top命令可以查看系统进程
但是我发现我找不到如何退出这个显示界面,上网搜查解决办法后,发现输入:ctrl+c即可
在开启虚拟机后,我发现虚拟机无法联网,后来查找原因发现是没有配置好网络的缘故。
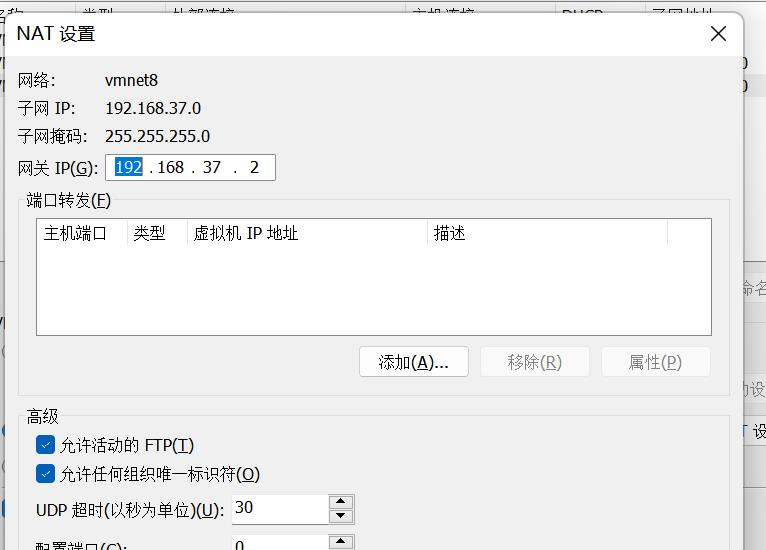
这里我们应该选择桥接模式,使用net8网络,用管理员权限打开。
在设置好网络模式后,尝试用ping baidu网站,发现可以正常Ping 通,说明网络恢复了正常状态。
3. 在ubuntu系统中下载vscode,并完成vscode相关插件的下载及C/C++运行环境的配置
这里我参考了这位博主写的CSDN,十分详细,分享给大家:
可以参考这篇博客https://blog.csdn.net/weixin_43786336/article/details/122543876
不过最后我出现了includepath的配置问题,我检查了很多遍也觉得没有什么大问题,不知道哪里出了原因。
4、最后总结一下这一周学习的库函数相关内容:
一、库函数基础概念
1.** 库函数:**库函数(Library function)是把函数放到库里,供别人使用的一种方式。方法是把一些常用到的函数
编完放到一个文件里,供不同的人进行调用。调用的时候把它所在的文件名用#include<>加到里面就可以了。一般是
放到lib文件里的。不受平台限制。
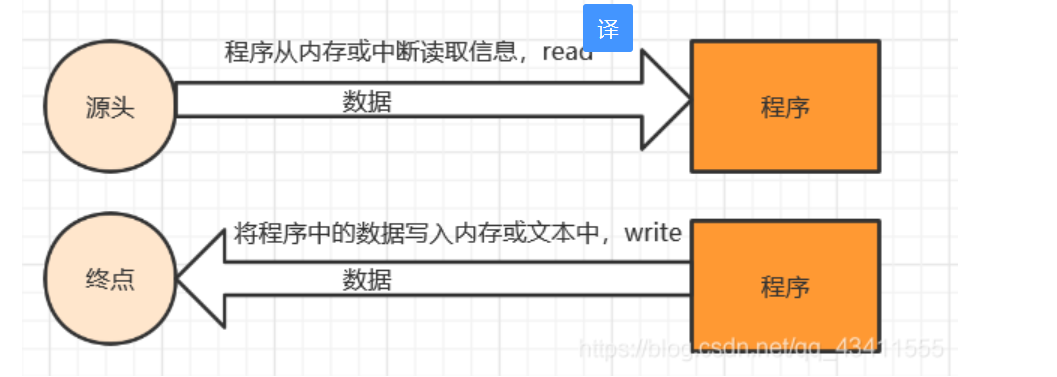
- 流:对于标准的C函数库,文件操作都是围绕着流来进行的,流是一个抽象的概念,当程序需要读取数据的时候,开
启一个通向数据源的流,数据源可以是文件,内存,网络连接等;当程序需要写入数据时,开启一个通向目的地的流,
如下图:
- 缓冲区: 库函数对文件处理时设置缓冲区,即在程序执行时,会提供额外的内存,来暂时存放文件中的数据,避免
多次和内核交互。注意,在实际编程中,这个缓冲区是隐式的,并不会被编程人员显示获取。
那么当我们使用标准I/O函数,即在#include<stdio.h>中的C库函数时,系统会自动设置缓冲区:
- 通过数据流来读写文件,那么当对文件进行读取时,不会直接操作作为源头的物理空间(如磁盘),而是打开数据流,
将源头上的文件信息拷贝到缓冲区中,然后程序再从缓冲区中读取所需数据。

- 当写入文件时,也并不会马上就写入终点物理空间(如磁盘等),而是先写入缓冲区,只有在缓冲区满或者关闭文件
时,才会将缓冲区的数据写入终点,如下图:
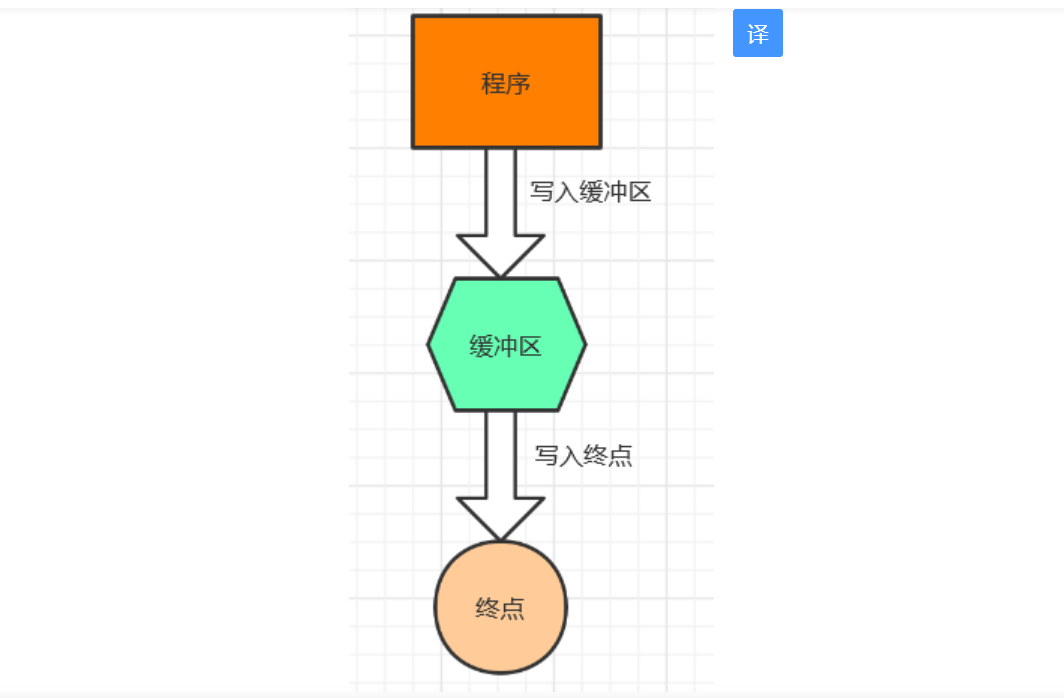
4. 文件指针: 用库函数的方式访问文件,用FILE类型表示一个打开的文件,这个类型中包含管理文件流的信息,我
们将指向该类型的指针FILE*称为文件指针。借用该指针可以对它指向的文件进行操作。
5. 文件类型: 文本类型和二进制,b就表示二进制文件。
二、基础文件操作函数
那下面我们介绍基础的文件操作:
(一)fopen
fopen()表示打开一个文件,这是文件操作的第一步。函数原型如下:
FILE fopen(const char path,const char* mode)**
参数说明:
const char path:*表示打开文件路径和文件名,如果在同一目录下,那么只写文件名即可,不在同一目录下需要写
绝对路径加文件名。
const char mode:*表示打开文件的方式,可以取值如下:
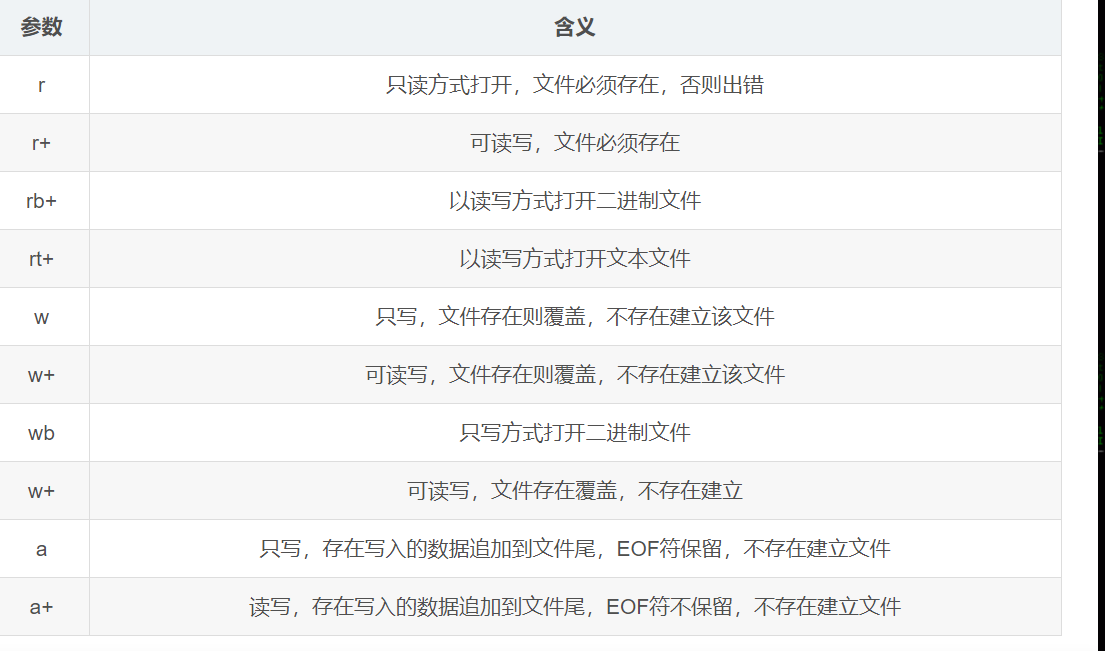
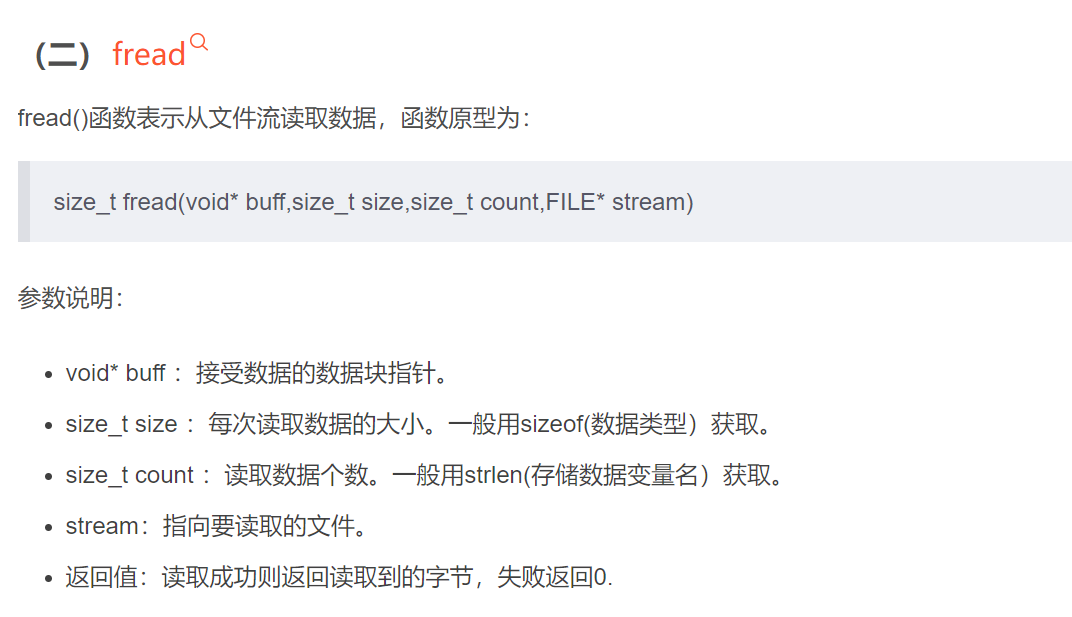
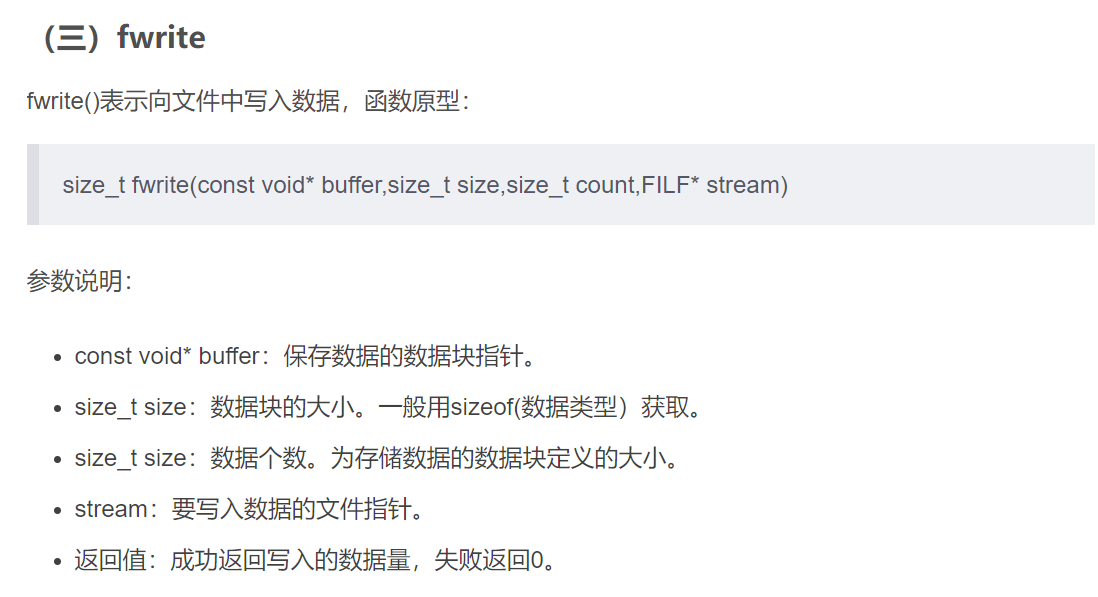

** 字符模式I/O(重点)**
函数原型:
```
int fgetc(File *fp);
int unget(int c ; FILE *fp);
int fputc(int c , FILE *fp);
这三个函数均是按字符读取文件内容,可以实现对文件的按字符读写(其中fgetc实现按字符读操作,而ungetc和
fputc则是按字符写入操作)
**行模式I/O**
**函数原型:**
```
char *fgets(char *buf , int size_z , FILE *fp);
int fputs(char *buf , FILE *fp);
fgets()函数从指定的流 fp 读取一行,并把它存储在 buf 所指向的字符串内。当读取 (size_z-1) 个字符时,或
者读取到换行符时,或者到达文件末尾时,它会停止。
参数解析:
* buf -- 这是指向一个字符数组的指针,该数组存储了要读取的字符串。
* size_z -- 这是要读取的最大字符数(包括最后的空字符)。通常是使用以 str 传递的数组长度。
* fp -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要从中读取字符的流。
fputs()函数则是将 buf 指向的字符串按行输入到 FILE 指针指向的对象文件中去,其参数与fgets()函数类似,可
以以它作为参考。
格式化输入*
scanf() 和 fscanf(),格式化的输入;
函数原型:
```
scanf(char *FMT , &items);
fscanf(FILE *fp , char *FMT , &items);
scanf()从标准输入 stdin 读取格式化输入;fscanf()从流 fp 读取格式化输入;
参数解析:
二者功能类似,参数可互相参考
fp -- 指向 FILE 对象的指针, FILE 对象标识了 fp 流;
FMT -- 表示C字符串,包含了以下各项中的一个或多个:空格字符、非空格字符 和 format 说明符。
**可以实现整型与字符串类型转换的两个函数:**
itoa()(integer to alphanumeric,整型数转字符串)和 atoi()(alphanumeric to integer,字符串转整型
数)
**1、itoa()**
它可以实现整型数向字符串的类型转变;
**2、atoi()**
它可以实现把字符串转换成整型数的操作;
函数原型如下:
char* itoa(int value ,char *string ,int radix);
int atoi(const char *nptr);
其参数如下:
```
itoa():
value: 要转换的整数;
string: 转换后的字符串;
radix: 转换进制数,如2,8,10,16 进制等;
atio():
nptr:要转换的字符串。
** 文件流缓冲**
每一个文件流都有一个FILE结构体,它包含了一个内部的缓冲区。想要对文件流进行读写就需要对该缓冲区进行遍历。所以才会有文件的流缓冲。主要有以下三种方式。
无缓冲:标准I/O不对字符进行缓冲处理,即对所有的从非缓冲流中写入或者读取的字符将马上被单独传送到文件中去或者从文件中传输出来。如stder函数;
行缓冲:当在输入和输出遇到换行符时,标准I/O执行I/O操作。如stdout函数;
全缓冲:在填满I/O缓冲区后再进行实际的I/O操作。一般的文件流缓冲方式。
在fopen()创建文件流之后,在对它进行任何操作之前,都可以发送以下函数来选择采用何种缓冲方式:
`int setvbuf(FILE *stream, char *buf, int mode, int size)`
**其中参数如下:**
stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了一个打开的流。
buf -- 这是分配给用户的缓冲。如果设置为 NULL,该函数会自动分配一个指定大小的缓冲。
mode -- 这指定了文件缓冲的模式;
size --这是缓冲的大小,以字节为单位。
模式必须为以下三者之一:
_IOFBF/(F=full)全缓冲:对于输出,数据在缓冲填满时被一次性写入。对于输入,缓冲会在请求输入且缓冲为空时被填充;
_IOLBF/(L=line)行缓冲:对于输出,数据在遇到换行符或者在缓冲填满时被写入,具体视情况而定。对于输入,缓冲会在请求输入且缓冲为空时被填充,直到遇到下一个换行符;
_IONBF 无缓冲:不使用缓冲。每个 I/O 操作都被即时写入。buffer 和 size 参数被忽略。
变参函数
参数数量可变的函数,比如printf()函数。其基本格式如下:
int func(int n , int m , ...);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号