
一、【SEED Labs 2.0】MD5 Collision Attack Lab
实验原理
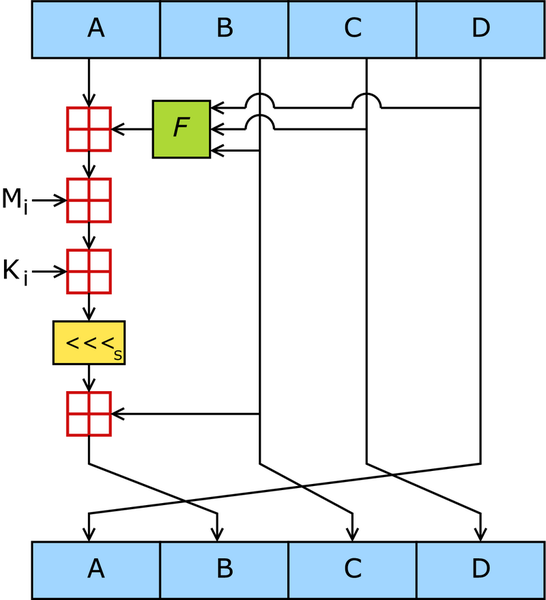
- 四个函数每个作用 16 轮,得到最后的结果。
Task 1: 使用相同的MD5哈希值生成两个不同的文件
1.首先创建 prefix.txt
touch prefix.txt
vim prefix.txt
- 例如,我们修改内容为
hail hydra
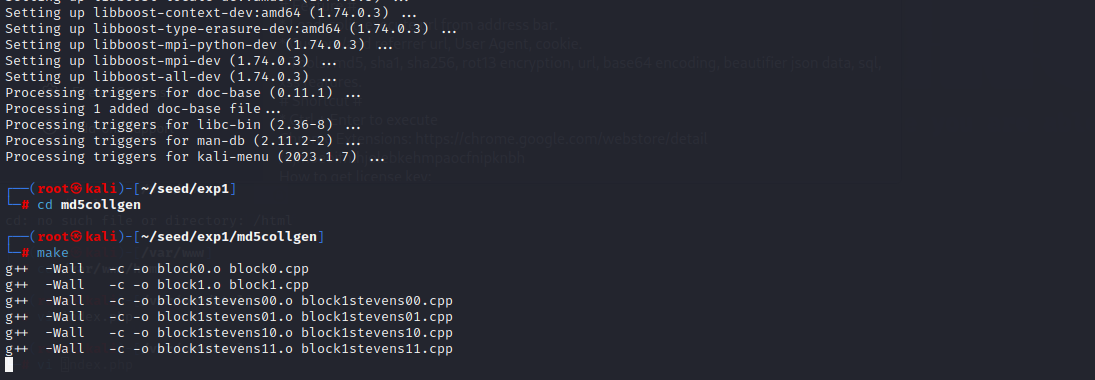
2.下载md5collgen
- To compile, we need C++ compiler and boost.
sudo apt install build-essential
sudo apt install libboost-all-dev
# only install boost libs that are needed
sudo apt install libboost-filesystem-dev libboost-timer-dev libboost-program-options-dev
- Clone this repo.
git clone https://github.com/zhijieshi/md5collgen.git - Then in the project directory, run make.
cd md5collgen
make
3.生成文件并验证
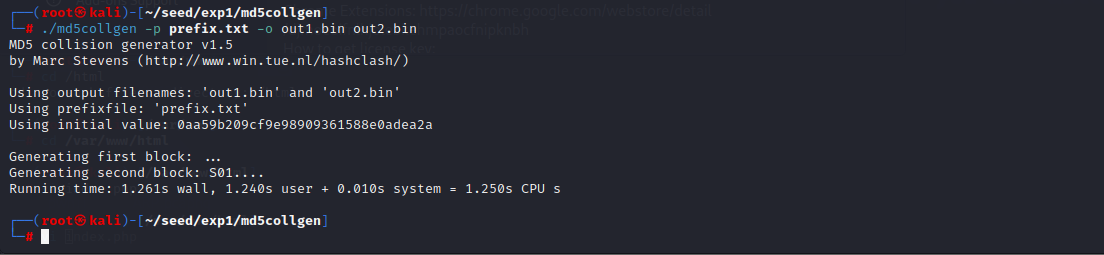
- 在md5collgen目录下生成两个 md5 相同的文件:
执行./md5collgen -p prefix.txt -o out1.bin out2.bin
![]()
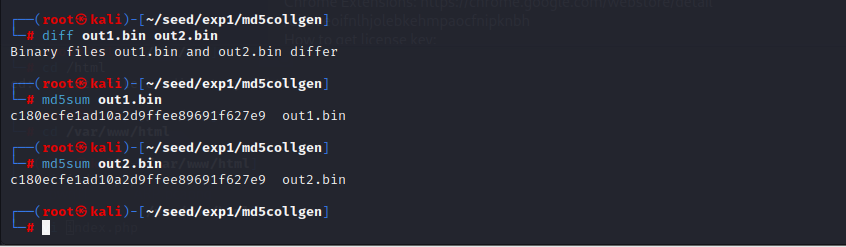
- 验证我们的文件是否相同、md5是否相同
diff out1.bin out2.bin
md5sum out1.bin
md5sum out2.bin
-
得到如下结果
![]()
-
我们用命令
sudo apt-get install bless在kali虚拟机下载bless十六进制文件查看器 -
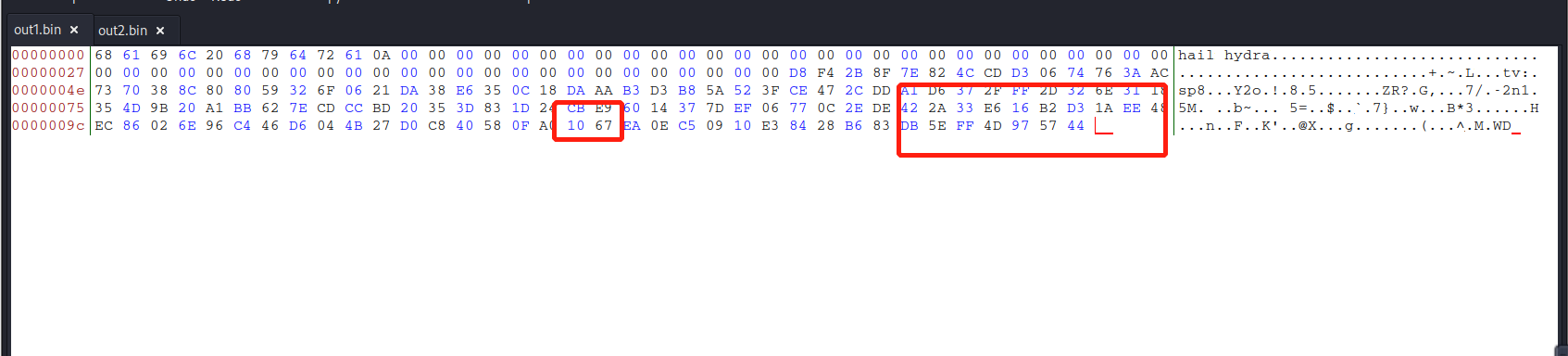
打开bless,我们分别查看 out1.bin 和 out2.bin
- out1.bin:
![]()
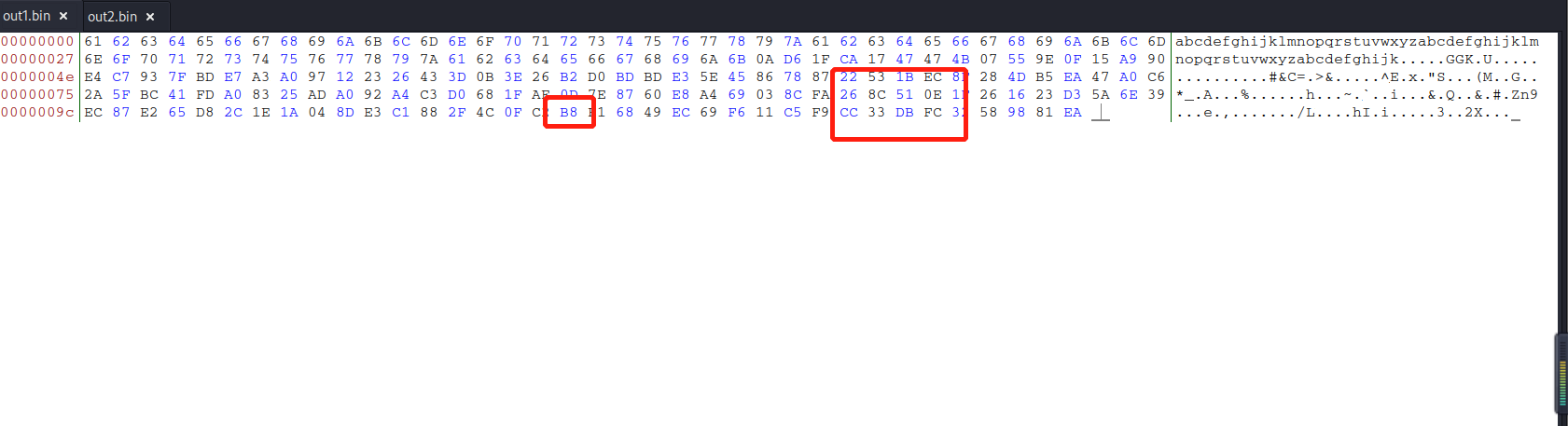
- out2.bin:
![]()
- out1.bin:
-
我们可以看到前64个(十六进制的40)已填充零。 这是因为MD5处理大小64字节的块。
-
经观察可得两文件的前缀相同,文件内容有少量不同。通过分析md5collgen的原理可以明白形成这一现象原因——就是当输入文件不是64字节的倍数时先补0到64字节的倍数,再添加两个128字节的数据分别生成两个MD5值相同的输出文件。
-
从prefix.txt中取前缀,若前缀不是64的倍数,则用零填充。md5collgen为两个输出文件生成128字节的内容,这两个输出文件就是在这128字节中存在部分差异。
-
将 prefix.txt 内容改为
abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijk。这里一共 63 个字母,加上文件结束符0A正好 64 Byte。 -
再次用
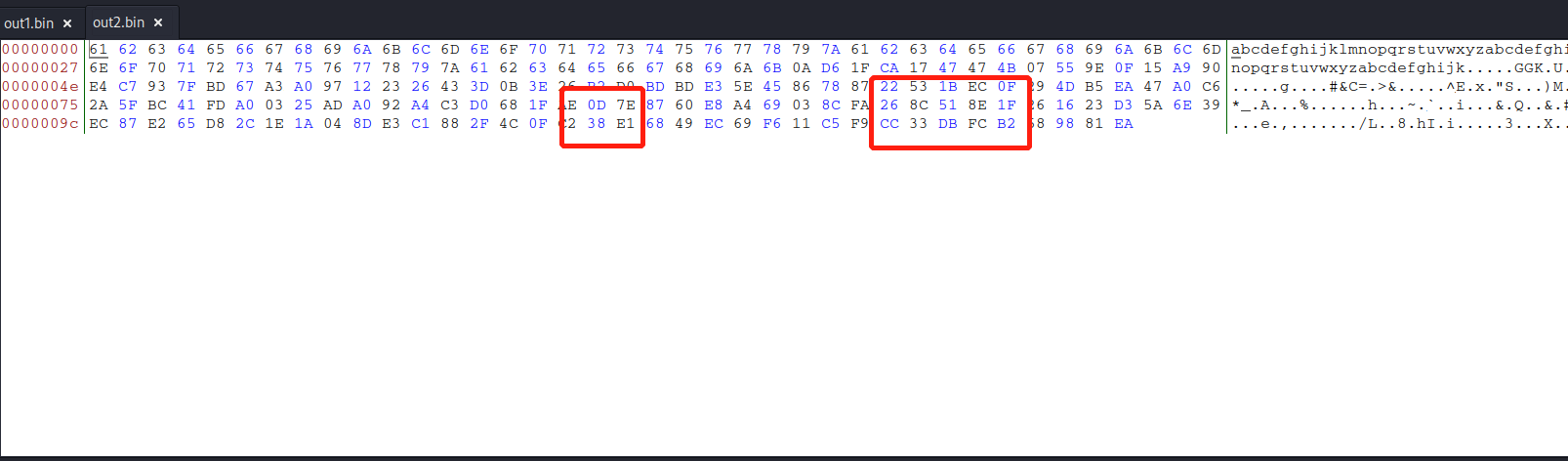
./md5collgen -p prefix.txt -o out1.bin out2.bin- out1.bin:
![]()
- out2.bin:
![]()
- out1.bin:
-
可以看到没有补零了。
-
我们可以发现在上一次情况下,字节仅在个别位置处不同。在多次试验之后,发现这些差异的地方不是固定的。

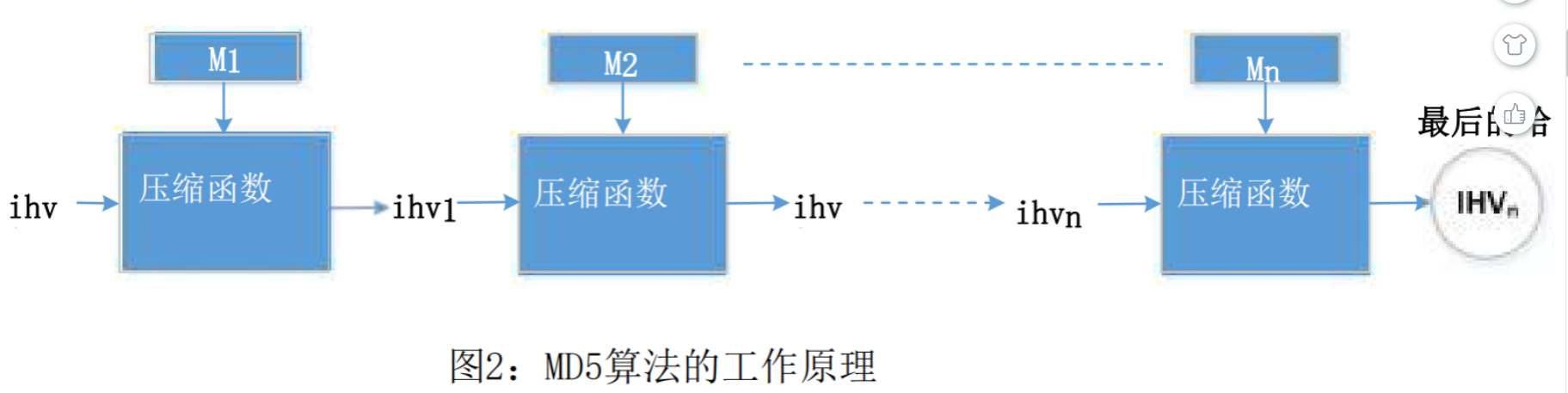
TASK2:了解MD5的属性
-
MD5是一个相当复杂的算法,但从非常高的层面,它不是那么复杂。如图所示,MD5将输入数据划分为64个字节的块,然后在这些块上迭代计算散列。MD5算法的核心是一个压缩函数,它接受两个输入,一个64字节的数据块和前一次迭代的结果。压缩函数产生一个128位的IHV,它代表“中级哈希值”(Intermediate Hash Value);然后将此输出输入到下一个迭代中。如果当前的迭代是最后一个迭代,则IHV将是最终的哈希值。第一次迭代的IHV输入(IHV0)是一个固定的值。
![]()
-
基于 MD5 算法的工作原理,我们可以推导出一个属性:
- 给定两个输入M,N如果MD5(M) = MD5(N),那么对于任何输入T,MD5(M || T) = MD5(N || T)。因此,将特定的suffix添加到具有相同MD5散列的任何两个不同消息中,通过连接原始消息和suffix消息,得到两个新的更长消息,这两个消息也具有相同的MD5散列。
- 也就是说,如果输入m和n具有相同的哈希,则将相同的suffix添加到它们将导致两个具有相同哈希值的输出。此属性不仅适用于MD5哈希算法,还适用于许多其他哈希算法。
-
我们对刚刚的两个 md5 相同的文件分别加上一个后缀,然后查看它们的 md5
echo hello >> out1.bin
echo hello >> out2.bin
md5sum out1.bin out2.bin
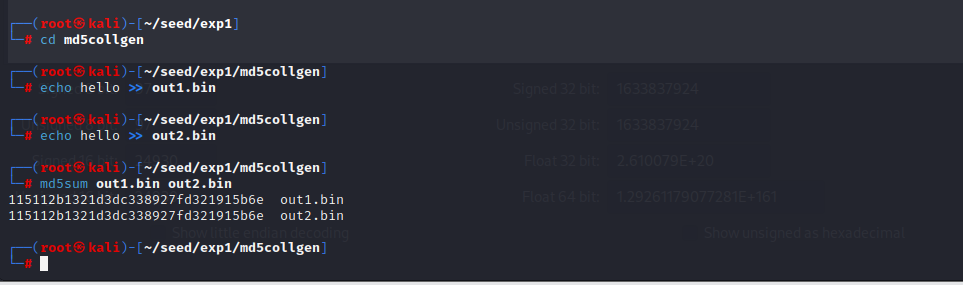
- 可以看到,md5 相同的文件加上相同后缀后,md5 依然相同。
Task 3:生成两个具有相同MD5哈希值的可执行文件
- 在这个任务中,您将得到以下C程序。您的工作是创建该程序的两个不同版本,以便它们的xyz数组的内容不同,但可执行文件的哈希值是相同的。
#include <stdio.h>
unsigned char xyz[200] = {
/* The actual contents of this array are up to you */
};
int main()
{
int i;
for (i=0; i<200; i++){
printf("%x", xyz[i]);
}
printf("\n");
}
- 您可以选择在源代码级别工作,即生成上述C程序的两个版本,编译后,它们对应的可执行文件具有相同的MD5哈希值。然而,直接在二进制级别上工作可能更容易。你可以在xyz数组中放入一些随机值,将上面的代码编译为二进制。然后可以使用十六进制编辑器工具直接在二进制文件中修改xyz数组的内容。
- 找到数组的内容存储在二进制文件中的位置并不容易。然而,如果我们用一些固定的值填充数组,我们可以很容易地在二进制文件中找到它们。例如,下面的代码用0x41填充数组,这是字母A的ASCII值。在二进制中找到200个A并不困难。
unsigned char xyz[200] = {
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
... (omitted) ...
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
}
-
指导方针:从数组内部,我们可以找到两个位置,从那里我们可以将可执行文件分为三部分:前缀、128字节的区域和后缀。前缀的长度需要是64字节的倍数。图3演示了文件是如何划分的。
![]()
-
我们可以在前缀上运行md5collgen来生成两个具有相同M**D5散列值的输出文件。让我们使用P和Q来分别表示这两个输出的第二部分(每个有128字节)作为前缀后面的部分。因此,我们有以下:
MD5 (prefix || P) = MD5 (prefix || Q) -
根据MD5的属性,我们知道,如果在上述两个输出中添加相同的后缀,生成的数据也将具有相同的散列值。基本上,以下是适用于任何后缀的:
MD5 (prefix || P || suffix) = MD5 (prefix || Q || suffix) -
因此,我们只需要使用P和Q来替换128字节的数组(在两个分界点之间),就可以创建两个具有相同哈希值的二进制程序。它们的结果是不同的,因为它们各自打印出具有不同内容的自己的数组。
-
可以使用bless来查看二进制可执行文件并找到数组的位置。为了划分二进制文件,我们可以使用一些工具来从特定位置划分文件。head和tail指令是非常有用的工具。你可以看说明书学习如何使用它们。下面我们举三个例子:

$ head -c 3200 a.out > prefix
$ tail -c 100 a.out > suffix
$ tail -c +3300 a.out > suffix
-
上面的第一个命令保存a的前3200字节到prefix文件。第二个命令保存a的最后100个字节到suffix文件。第三个命令将数据从第3300个字节到文件结束保存到suffix文件。通过这两个命令,我们可以从任何位置将一个二进制文件分割成若干块。
-
如果我们需要将一些碎片粘在一起,我们可以使用cat命令。
-
源代码如下:
#include <stdio.h>
unsigned char xyz[200] = {
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
};
int main()
{
int i;
for (i=0; i<200; i++){
printf("%x", xyz[i]);
}
printf("\n");
}
-
编译成二进制文件
![]()
-
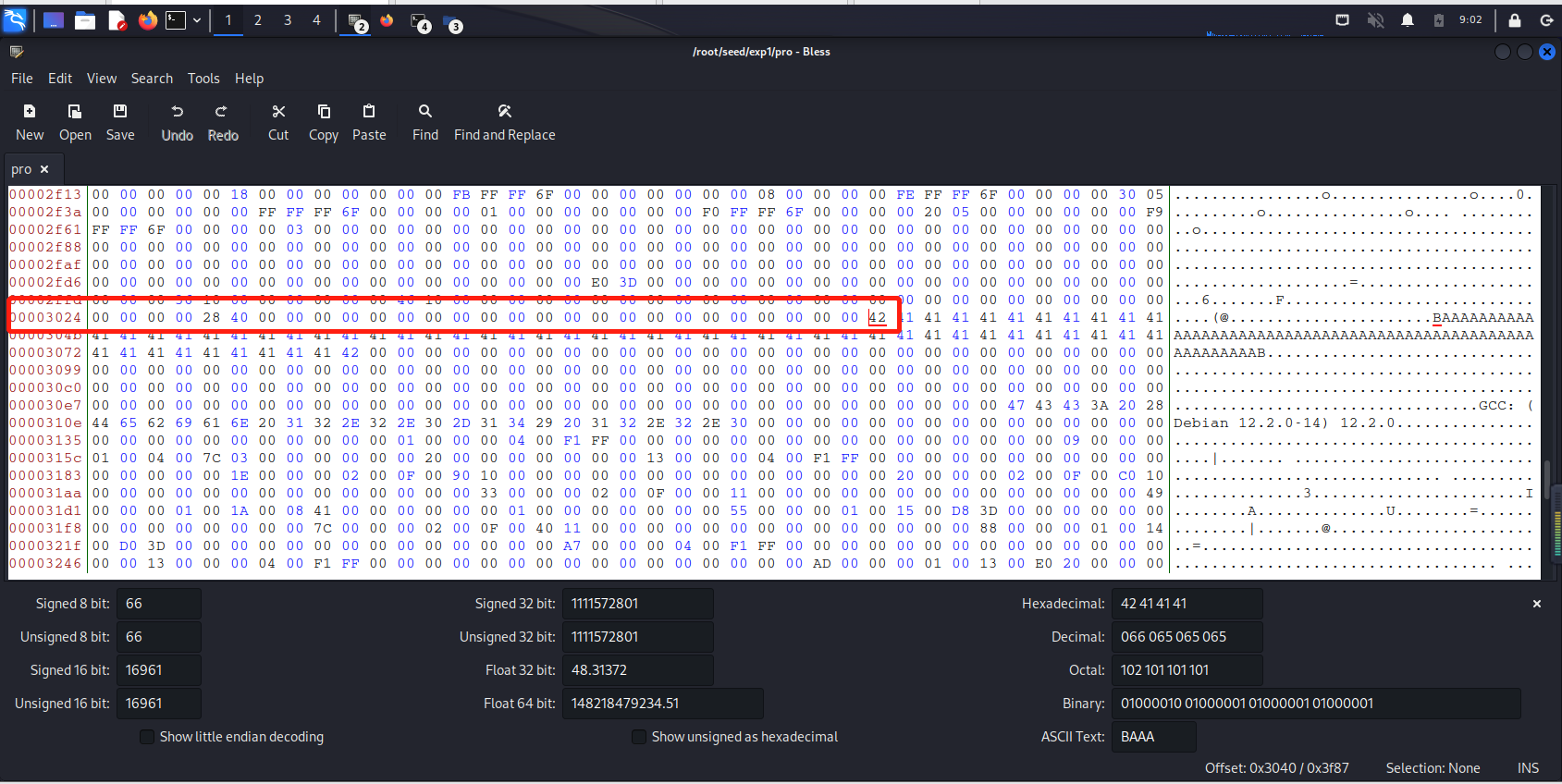
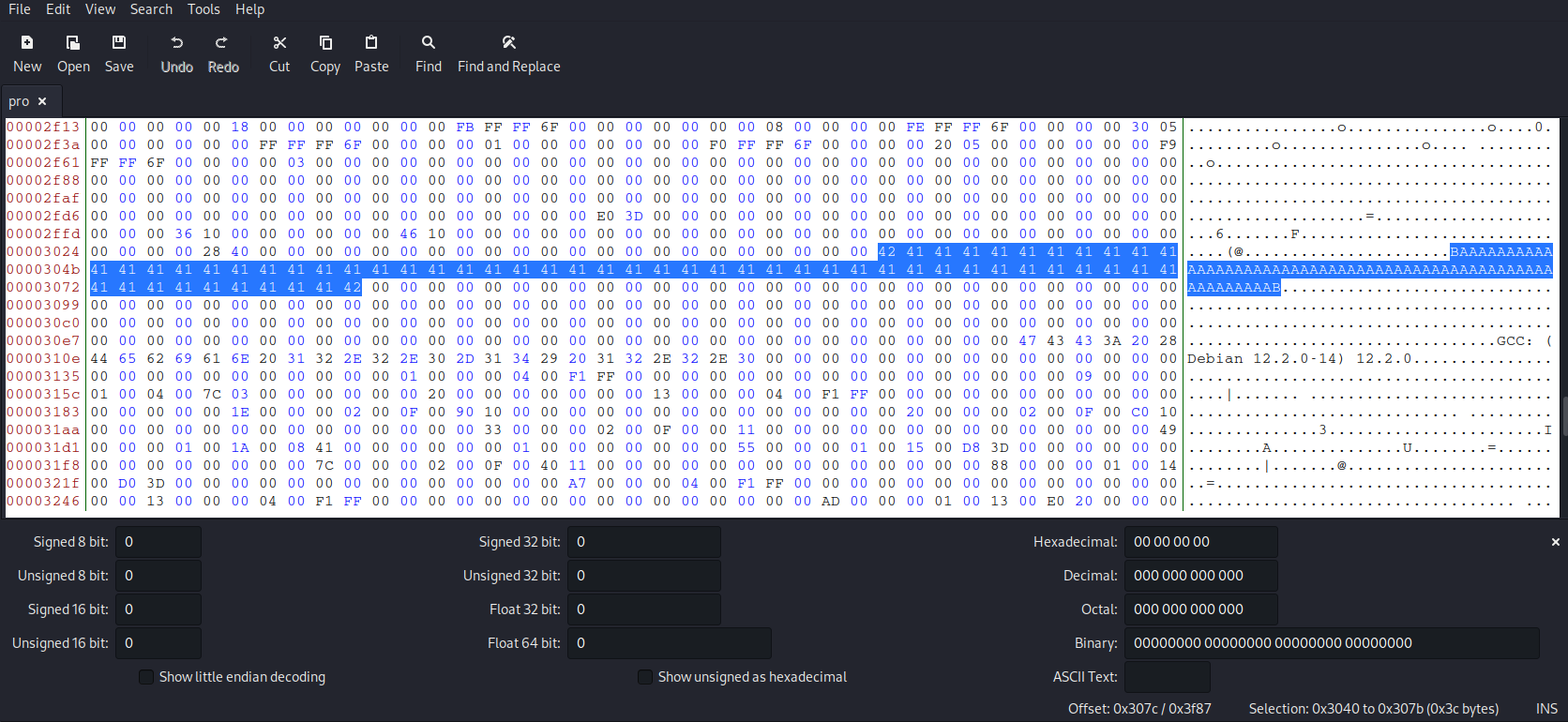
在二进制文件task3中找到xyz数组的位置:
![]()
![]()
-
因为12352(3040h)刚好为64的倍数,所以我们把其和之前的截取放在prefix中。
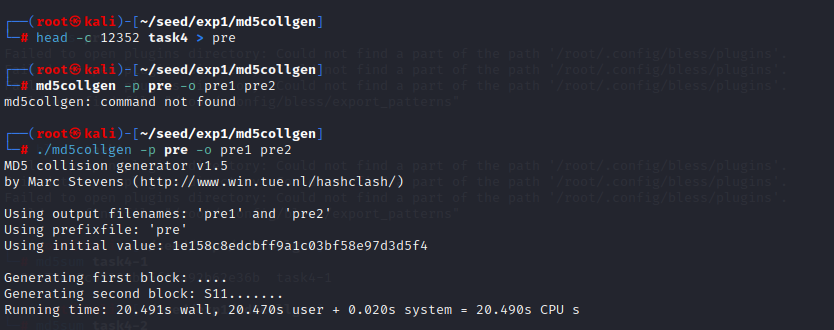
head -c 12352 pro > prefix -
计算得到在 12352(3040h) 到 12411(307bh) 范围内,12352刚好为64的倍数,因此我们把12352后面的截取出来:
tail -c +12353 pro > suffix -
然后对 prefix 生成 md5 相同的两个文件
md5collgen -p prefix -o prefix1 prefix2 -
这时候prefix1和prefix2,就是由前缀prefix文件加上两个不同的128字节数据生成的具有相同md5值的文件:
MD5 (prefix || P) = MD5 (prefix1) = MD5 (prefix2) = MD5 (prefix || Q) -
把刚刚的尾巴接到这两个文件后面

cat suffix >> prefix1
cat suffix >> prefix2
- 赋予执行权限
chmod +x prefix1
chmod +x prefix2
- 运行,可以发现两者的输出结果是不一样的
![]()

./prefix1 > prefix1.out
./prefix2 > prefix2.out
diff -q prefix1.out prefix2.out
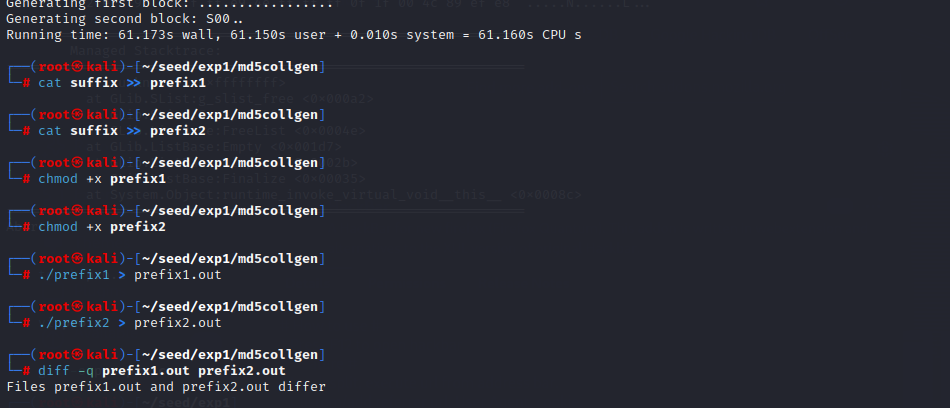
-
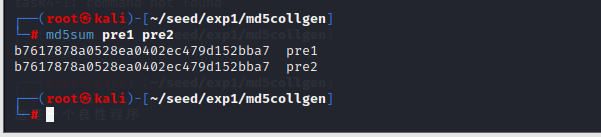
我们再来查看下prefix1,prefix2的哈希值,发现完全一致:
![]()
-
这就说明:MD5 (prefix || P || suffix) = MD5 (prefix1(原) || suffix)= MD5 (prefix) = MD5 (prefix2) = MD5 (prefix2(原)|| suffix) = MD5 (prefix || Q || suffix)
-
其实,现在的两个MD5的相同的可执行文件和原来的二进制可执行文件,只是中间的128字节数据不同而已

Task 4:使两个程序行为不同
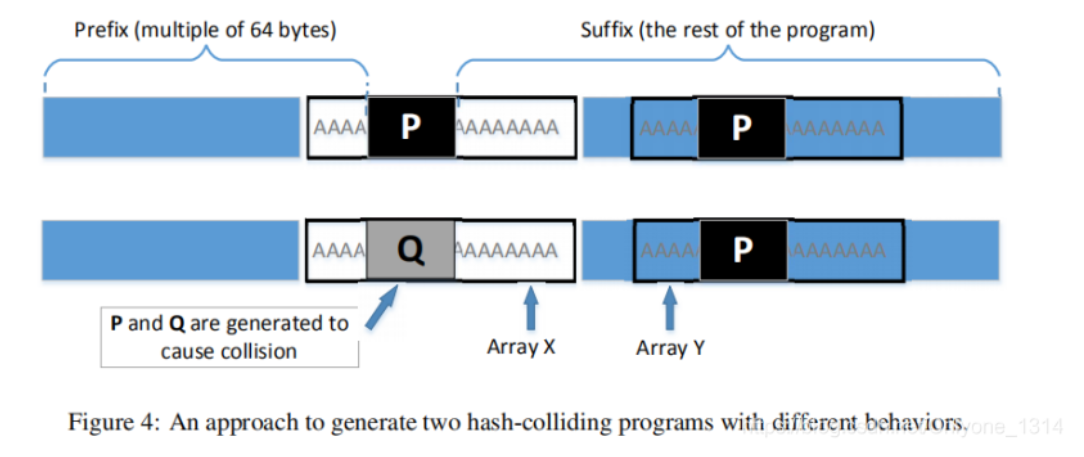
- 我们可以用一些值初始化数组X和Y,这些值可以帮助我们在可执行二进制文件中找到它们的位置。我们的工作是更改这两个数组的内容,这样就可以生成具有相同MD5散列的两个不同版本。在一个版本中,X和Y的内容是相同的,所以良性代码执行;在另一个版本中,X和Y的内容不同,所以恶意代码被执行。我们可以使用类似于上一个任务中使用的技术来实现这个目标。图4演示了程序的两个版本。
![]()
- 从图可知,只要P和Q相应地生成,这两个二进制文件具有相同的MD5哈希值。在第一个版本中,我们使数组X和Y的内容相同,而在第二个版本中,我们使它们的内容不同。因此,我们唯一需要更改的是这两个数组的内容,而不需要更改程序的逻辑。
- 在我们的方法中,我们创建两个数组X和Y。我们比较这两个数组的内容;如果他们都是一样的,执行的是良性代码;否则,将执行恶意代码。
- 伪代码如下:
Array X;
Array Y;
main()
{
if(X’s contents and Y’s contents are the same)
run benign code;
else
run malicious code;
return;
}
- 构造 task.c 如下
#include <stdio.h>
#include <string.h>
unsigned char X[200] = {
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
};
unsigned char Y[200] = {
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41, 0x41,
};
int main()
{
//大于返回正数,小于返回负数
if (strcmp(X, Y)){
printf("这是一个恶性程序\n");
}
//相等则返回0
else {
printf("这是一个良性程序\n");
}
}
-
编译:
gcc -o task4 task.c
![]()
-
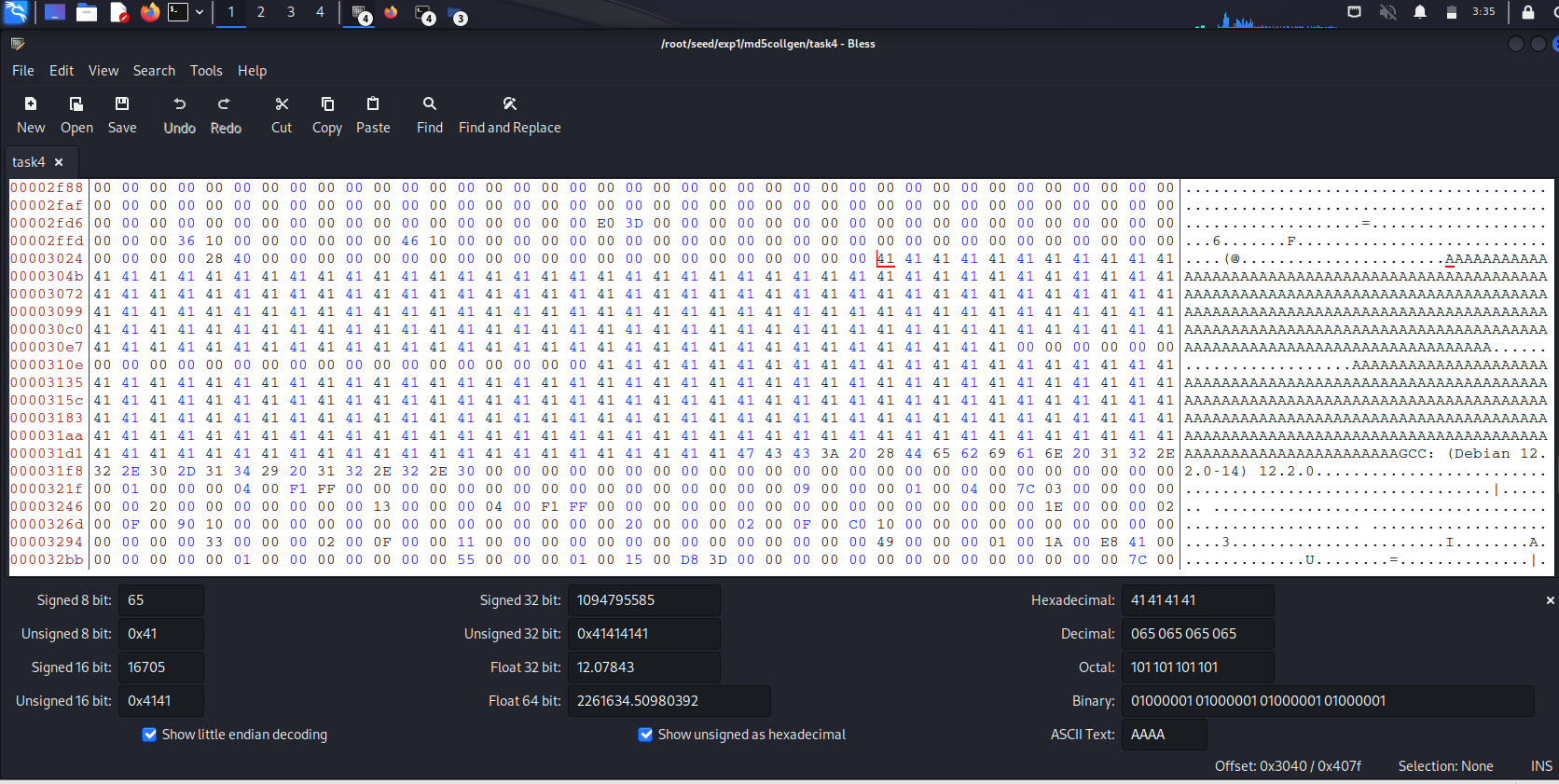
打开二进制可执行程序task4,找到两个数组位置
![]()
-
数组X的位置是从12352开始的,我们把前12352个字节的数组取出来作为prefix前缀文件:

head -c 12352 origin > pre
md5collgen -p pre -o pre1 pre2
-
发现两个文件的md5值是相同的
![]()
-
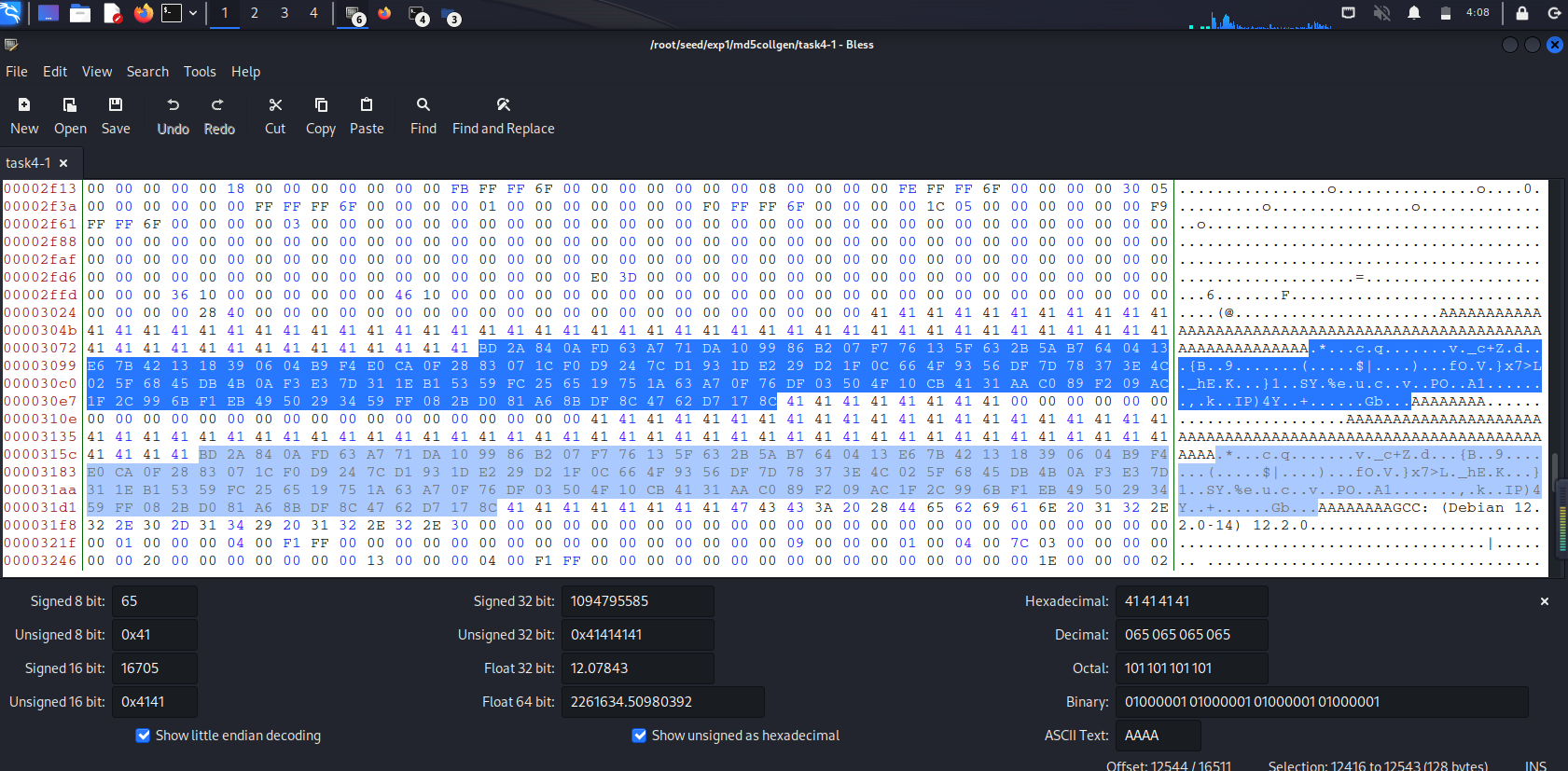
先把pre1的尾缀128字节的数据填入可执行程序task4的X和Y数组,此时X和Y数组相等,即可得到一个良性的程序task4-1:
BD 2A 84 0A FD 63 A7 71 DA 10 99 86 B2 07 F7 76 13 5F 63 2B 5A B7 64 04 13 E6 7B 42 13 18 39 06 04 B9 F4 E0 CA 0F 28 83 07 1C F0 D9 24 7C D1 93 1D E2 29 D2 1F 0C 66 4F 93 56 DF 7D 78 37 3E 4C 02 5F 68 45 DB 4B 0A F3 E3 7D 31 1E B1 53 59 FC 25 65 19 75 1A 63 A7 0F 76 DF 03 50 4F 10 CB 41 31 AA C0 89 F2 09 AC 1F 2C 99 6B F1 EB 49 50 29 34 59 FF 08 2B D0 81 A6 8B DF 8C 47 62 D7 17 8C
![]()
-
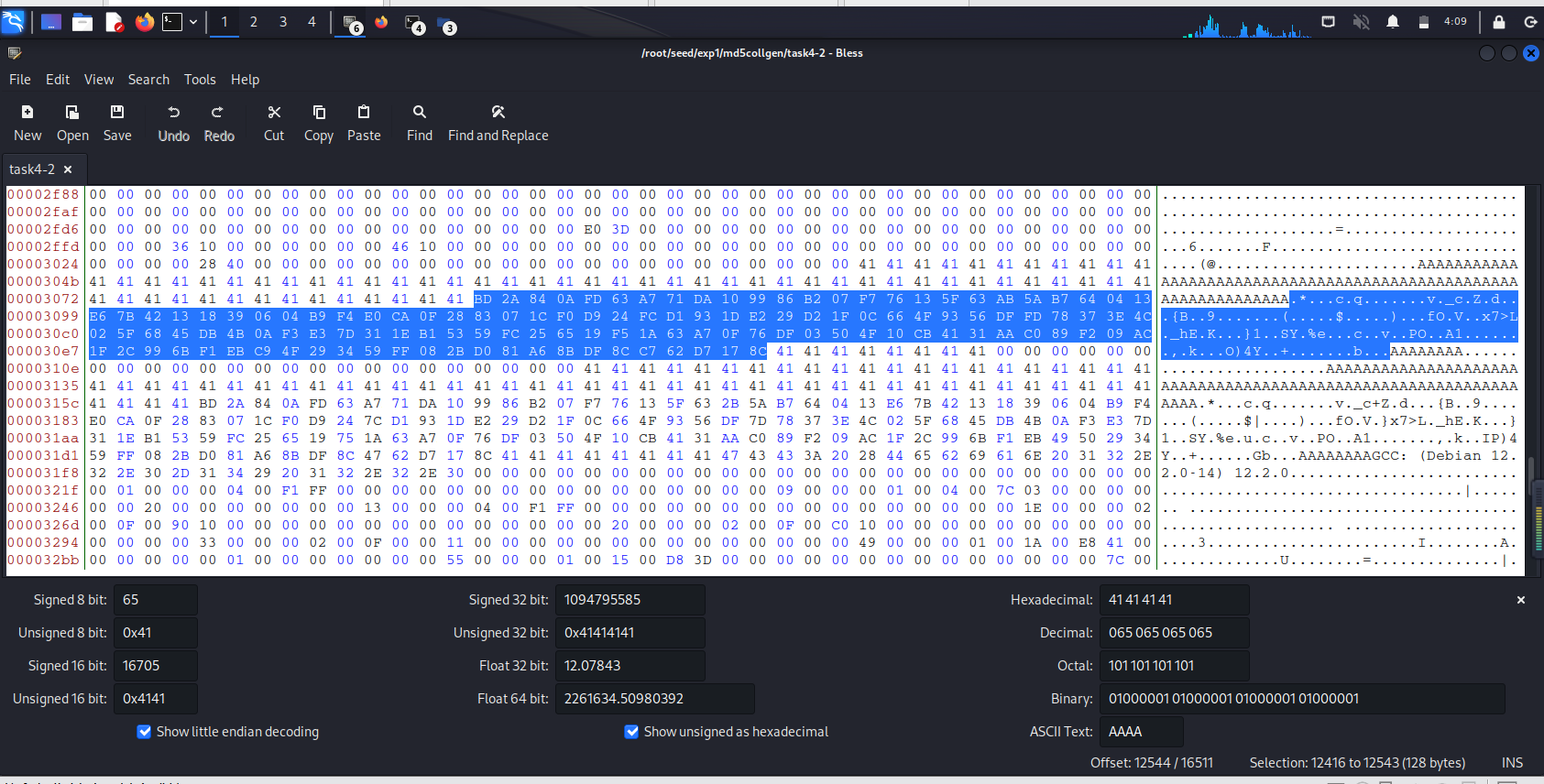
再把pre1的尾缀128字节的数据填入Y数组,pre2的尾缀128字节的数据填入X数组(不要把X和Y数组弄反了),此时X和Y数组不相等,即可得到一个良性的程序task4-2:
-
pre2的尾缀128字节如下:
BD 2A 84 0A FD 63 A7 71 DA 10 99 86 B2 07 F7 76 13 5F 63 AB 5A B7 64 04 13 E6 7B 42 13 18 39 06 04 B9 F4 E0 CA 0F 28 83 07 1C F0 D9 24 FC D1 93 1D E2 29 D2 1F 0C 66 4F 93 56 DF FD 78 37 3E 4C 02 5F 68 45 DB 4B 0A F3 E3 7D 31 1E B1 53 59 FC 25 65 19 F5 1A 63 A7 0F 76 DF 03 50 4F 10 CB 41 31 AA C0 89 F2 09 AC 1F 2C 99 6B F1 EB C9 4F 29 34 59 FF 08 2B D0 81 A6 8B DF 8C C7 62 D7 17 8C
![]()
-
其实良性程序task4-1和恶性程序task4-2只是X数组中间的128字节不同(是pre1和pre2的尾缀128字节),Y数组中间的128字节相同(都是pre1的尾缀128字节,也可以都换成pre2的尾缀128字节):
-
可以发现他们两个会运行出不同的结果:
![]()
-
任务完成~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号