
【mysql】索引优化记录
基础知识
Innodb存储引擎
- 支持行锁
- 支持事务;
Myisam存储引擎
- 只支持表锁;
- 不支持事务;
常见索引列表
- 独立的列
- 前缀索引(索引选择性)
- 多列索引(并不是多个单列索引,索引顺序很重要)
- 聚簇索引(保存了完整的数据记录,数据文件本身就是索引文件)
- 覆盖索引(一个索引包含或覆盖所有查询的字段值,对于Innodb来说,可以避免对主键索引的二次查询)
- 使用索引扫描做排序
- 冗余索引和重复索引
索引对CRUD的影响
- 一般来说,增加索引是为了提升查询速度,索引越多,查询速度应该越快(当索引太多时,由于选择判断的原因,查询不一定会变快);
- 增加索引,create/delete/update等操作都会相应的变慢,尤其是新增索引导致内存瓶颈的时候尤甚;
mysql存储引擎、索引、服务器
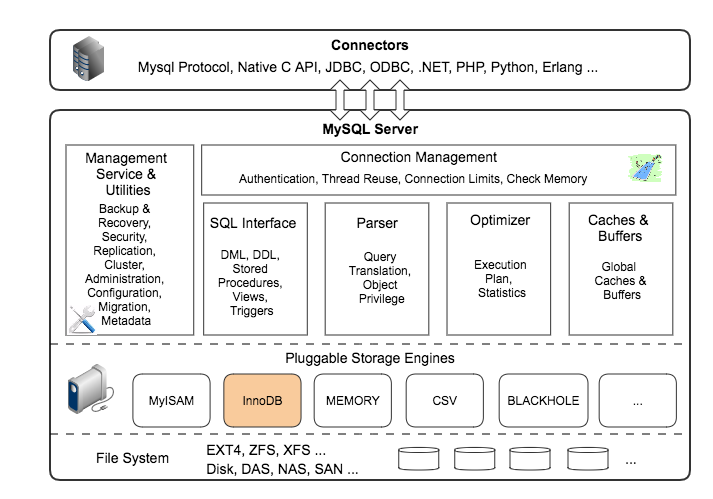
- 索引是在存储引擎层面实现;
示例:actor_id建立了索引(Innodb)
select actor_id from table where actor_id<5 and actor<>1;
----output-----
actor_id
2
3
4
执行过程:
存储引擎层面:使用索引范围扫描(actor_id<5),返回给服务器{1,2,3,4}这几条记录;- 服务器层面:过滤存储引擎返回的记录,actor_id<>1,过滤掉actor_id=1的记录;
- 最终返回{2,3,4}记录;
从上面的执行过程可以看到:
- 存储引擎过滤-->服务器过滤-->返回给客户端;
- 如果存储引擎层面能够过滤掉足够多的无需记录,性能会有很大提升: 这部分主要是
索引发挥的作用; - 存储引擎返回的{1,2,3,4}条记录,都会加上锁(Innodb支持行锁),虽然{1}不是所需的:索引能够减少锁的个数,有效的提升并发性;
- 服务端过滤掉{1},会通知存储引擎,此时存储引擎可以将{1}的行锁解除,不必等到事务提交;
关于Innodb、索引、锁
很少有人知道的细节:
Innodb在二级索引上使用共享(读)锁,但访问主键索引需要排他(写)锁。(不太理解这样做的好处)
这消除了使用覆盖索引的可能性,并且使得select for update比lock in share mode或非锁定查询要慢很多;(没搞明白为什么**)
索引优化示例
在where中使用IN来匹配最左前缀
比如QQ使用性别、年龄、地区等来筛选用户,大部分时候,都会将性别、年龄、地区作为过滤条件;
而性别只有m/f 两种分类,选择性很差,但是搜索频率相当高 ,此时我们可以对性别进行索引,排在最左列,如:
alter table xxx add key(sex,region,age);
如果某次查询,没有将sex作为查询条件,该如何使用上面的索引呢?
技巧:使用IN
select * from table where sex in ('m','f') and region ='xxxx' and age > 12;
上面使用IN来过滤,并不会过滤掉任何行,但是可以让mysql使用最左前缀进行优化;
mysql会将上述的查询优化为:
select * from table where sex = 'm' and region ='xxxx' and age > 12;
and
select * from table where sex = 'f' and region ='xxxx' and age > 12;
使用IN进行优化的适用条件
只有当该列的值比较少时,使用IN来进行最左前缀匹配优化才是可行的,如果IN的列表特别长,性能可能会适得其反;
示例:
select * from table where sex in ('m','f') and region in ('beiJing', 'shanghai','suzhou') and age > 12;
优化器会将上述查询转换为:2*3=6中组合,没增加一个IN,组合数都会成指数级增长;
将需要做范围查询的列放到索引的最后面
如果需要对性别、地区、年龄做索引,索引顺序应当如何?
根据选择性越高,就应该放在索引的最前列原则,年龄和地区可能肯定被放在性别前面;
但是根据查询频率来看,每次基本上都会使用性别查询,根据上一条的优化原则(在where中使用IN来匹配最左前缀),性别放在第一列反而更合适;
查询年龄时,基本都是 age>xxx and age<xxx,当然可以使用IN进行优化,但是age的范围太广,IN优化反而达不到好的效果;
为了能够匹配更多的最左前缀列,将范围查询的列放到索引的最后面放在最后反而更合适,因为Mysql无法使用【范围列】后面的索引列;
alter table xxx add key("sex","region","age");
避免多个范围条件
因为Mysql无法使用【范围列】后面的索引列;
所以当出现多个范围条件时,最多只能使用其中的1列进行索引,无法同时使用索引;
冗余索引与重复索引
示例(以Innodb的B+Tree索引为例)
有索引(A,B) ==>(A)为冗余索引,因为索引(A)只是索引(A,B)的前缀索引;
有索引(A,B) ==>(A,B,Id)是冗余索引,其中ID为主键,因为Innodb中,二级索引本身就包含主键;
有索引(A,B) ==>(B,A)不是冗余索引
有索引(A,B) ==>(B)不是冗余索引
有B-Tree索引(A,B) ==>Hash索引(A,B)不是冗余索引 (索引类型不同)
一般来讲,应当消除冗余索引。
比如最初有如下查询:假设有索引(state_id)
select count(*) from table where state_id = 'xxx'; //`覆盖索引`
后来增加新的查询
select state_id, city, address from table where state_id = 'xxx'; //变为`非覆盖索引`
为了提高第二条语句的查询效率,应该扩展(state_id)索引
alter table xxx drop key state_id,
add key state_id_2(state_id, city, address);
如此修改后,查询1和查询2都可以使用新的索引:state_id_2(state_id, city, address);
有时冗余索引能提升查询速度(以空间换取查询时间)
还是以上述查询为例,索引由 state_id(state_id)变为state_id_2(state_id, city, address),势必导致索引变大,占用的空间更多;
相同内存下,索引载入内存的数量减少,同时索引的遍历变慢,如果数据量很大,将导致查询1变慢,尤其是使用了前缀压缩索引时更为明显;
如果此时允许冗余索引,将会是查询1和查询2都变快,当然,势必导致占用的存储空间更大,也会影响update/create/delete的性能;
使用索引扫描做排序
Innodb的B+TREE是按照列的顺序进行排列的,因此可以使用索引扫描做排序;
使用索引扫描做排序的条件
- 索引的列顺序与order by的列顺序完全相同(最左前缀原则使然);
- 所有列的排序方向都一致,要么都正序,要么都反序(因为多列索引的排序顺序是一致的):如果隔列排序顺序不同,可以考虑新增字段,存放对应列的反转串;
索引扫描读取数据 vs 全表扫描读取数据 (性能比较)
- 索引扫描排序时,如果需要进行主键的二次索引,通常都是随机IO;
- 全表扫描,通常都是顺序IO;
因此按索引顺序读取完整记录(涉及到主键的二次索引查询)的速度通常比顺序的全表扫描慢;
结论
使用索引扫描排序时,尽量能使用覆盖索引,并且排序的数据条数尽量小,避免造成大量的随机IO;
索引排序最重要的用法(order by + limit)
上面讲到了,索引排序如果涉及到主键的二次查询,通常都是随机IO,如果数据量很大,这势必严重影响性能;
如果在查询语句中有limit做限制,通常数据量都很小,即使是随机IO,对性能的影响也可以忽略不计;
因此,索引排序最重要的用法是使用order by与 limit的结合使用;
特殊情况:可以是索引排序不满足最左前缀原则
在where字句中,对索引的前导列使用了常量值时,可以不满足最左前缀原则;
示例:
KEY `poolId_domainID_idx` (`pool_id`,`domain_id`) //索引
查询:前导列pool_id使用常量
MySQL [test]> explain select * from pool_configs where pool_id = 'xxx' order by domain_id ;
+----+-------------+--------------+------+-----------------------------------+---------------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------------+------+-----------------------------------+---------------------+---------+-------+------+-------------+
| 1 | SIMPLE | pool_configs | ref | pool_id_index,poolId_domainID_idx | poolId_domainID_idx | 96 | const | 1 | Using where |
+----+-------------+--------------+------+-----------------------------------+---------------------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql在进行优化时,会将上述查询优化为:order by pool_id, domain_id(优化后其实是满足最左前缀原则的)
MySQL [test]> explain select * from pool_configs where pool_id = 'xxx' order by pool_id, domain_id ;
+----+-------------+--------------+------+-----------------------------------+---------------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------------+------+-----------------------------------+---------------------+---------+-------+------+-------------+
| 1 | SIMPLE | pool_configs | ref | pool_id_index,poolId_domainID_idx | poolId_domainID_idx | 96 | const | 1 | Using where |
+----+-------------+--------------+------+-----------------------------------+---------------------+---------+-------+------+-------------+
1 row in set (0.00 sec)
覆盖索引
对于Innodb存储引擎,主键使用聚簇索引(包含所有的记录),而二级索引包含主键值,因此正常查询时,一般都会进行主键索引的二次查询(二级索引先找到主键值,然后在根据主键值找到对应的记录);
如果二级索引中包含了要查询的所有数据列,则无需在根据主键值查询完整的记录,减少一次索引查询,可以大大提升查询性能。
示例:
二级索引:poolId_domainID_idx (pool_id,domain_id)包含了两列
| pool_configs | CREATE TABLE `pool_configs` (
`id` char(32) NOT NULL,
`pool_id` char(32) NOT NULL,
`region_name` varchar(50) DEFAULT NULL,
`domain_id` char(32) DEFAULT NULL,
`value` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `pool_id_index` (`pool_id`),
KEY `poolId_domainID_idx` (`pool_id`,`domain_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
查询pool_id与domain_id将使用覆盖索引;
如下所示:Extra的内容为Using index,即表示使用覆盖索引;
MySQL [test]> explain select pool_id , domain_id from pool_configs ;
+----+-------------+--------------+-------+---------------+---------------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------------+-------+---------------+---------------------+---------+------+------+-------------+
| 1 | SIMPLE | pool_configs | index | NULL | poolId_domainID_idx | 193 | NULL | 71 | Using index |
+----+-------------+--------------+-------+---------------+---------------------+---------+------+------+-------------+
对比不是使用覆盖索引的查询;
下面的语句查询所有列,而并没有任何索引能覆盖所有列,因此无法使用覆盖索引
MySQL [test]> explain select * from pool_configs ;
+----+-------------+--------------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | pool_configs | ALL | NULL | NULL | NULL | NULL | 71 | NULL |
+----+-------------+--------------+------+---------------+------+---------+------+------+-------+
优化技巧
查询时尽量不要使用*返回所有列,因此可能导致无法使用覆盖索引
在大多数存储引擎中,覆盖索引只能覆盖那些只访问索引中部分列的查询。
因此查询时,如果只需要个别的列(如:只需要 id, pool_id, domain_id),则不要使用*返回所有列;
因为Innodb的二级索引中包含主键值,所以Innodb查询包含主键列不会对覆盖索引造成影响;
使用延时关联技术优化查询,使用覆盖索引
该技巧较高,目前自己还无法掌握,并且优化后的查询性能与数据分布密切相关;
充分利用Innodb二级索引包含主键值的特性,优化查询,达到覆盖索引查询效果
上面的示例中,索引poolId_domainID_idx只包含poolId和domainId,并不包含主键值id,根据Innodb二级索引包含主键值的特性,
如下查询也会使用覆盖索引:
MySQL [test]> explain select id , pool_id , domain_id from pool_configs ;
+----+-------------+--------------+-------+---------------+---------------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------------+-------+---------------+---------------------+---------+------+------+-------------+
| 1 | SIMPLE | pool_configs | index | NULL | poolId_domainID_idx | 193 | NULL | 71 | Using index |
+----+-------------+--------------+-------+---------------+---------------------+---------+------+------+-------------+
1 row in set (0.00 sec)
Innodb聚簇索引--主键选择
在Innodb中表中按主键顺序插入行
- 可以选择一个自增列(auto_increment)作为主键;
- 避免使用UUID作为主键(尤其是比较长的随机的):随机插入时,会导致大量的
页分裂和碎片;
何为页分裂
mysql在将数据记录写入磁盘之前,会先在内存中缓存多条记录,熟悉内存模型的应该知道内存分页,好像默认大小是16K;
当记录个数达到一定值后,总数据大小接近内存分页大小,此时才会将内存中的数据刷入到磁盘(磁盘也是分页的),充分利用内存缓存和分页机制;
上述过程中,这些记录都存储在同一页中;
当聚簇索引的主键为随机值时,因为Innodb会按照主键顺序存储,所以通常都会将新插入的记录,插入到已经刷入到磁盘的--分页中(此页可能已经满了),
如果是这样,将会导致磁盘数据重新读入内存,并导致页分裂(因为一页大小是固定的,插入新记录,肯定需要页分裂);
Innodb使用自增列作为主键--缺点
在高并发场景下,所有的插入同时进行,会导致主键的上界成为热点,高并发可能会导致间隙锁的激励竞争(不太理解为什么会导致间隙锁的竞争)。
另一个热点是auto_increment锁机制:这个很好理解;
解决方案
- 考虑重新设计表或应用;
- 更改配置:innodb_autoinc_lock_mode (这个没有研究过,具体细节不清楚);
总结
- 自增列作为主键,在高并发情况下,可能会有激烈的所竞争;
- 在非高并发情况下,使用自增的列作为主键,是比较好的选择;
多列索引-索引列顺序选择
将`选择性`最高的列放到索引最前列。(这个法则可能没有想象的重要,通常不如避免随机IO和排序重要)
选择性:是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值;
Index Selectivity = Cardinality / #T,具体可以参见:http://www.cnblogs.com/ssslinppp/p/8206093.html
说明
下面介绍的基于平均选择性(适用于绝大部分情况)和基于数据分布--选择性(适用于少部分特殊情况),并没有将排序、分组、范围查询考虑进去;
排序、分组、范围查询对性能造成的影响不能忽视。
示例:
select * from pool_configs where pool_id='7b8f0f5e2fbb4d9aa2d5fd55466dsij2' and domain_id = 'aed318549ff511e6b70cfa163eb66336';
如何决定索引的列顺序(pool_id, domain_id)还是(domain_id,pool_id);
基于平均选择性(适用于绝大部分情况)
查看索引选择性:
select count(distinct pool_id)/count(*) as poolIdSelect,
count(distinct domain_id)/count(*) as domainIdSelect,
count(*) from pool_configs;
+--------------+----------------+----------+
| poolIdSelect | domainIdSelect | count(*) |
+--------------+----------------+----------+
| 0.0676 | 0.0270 | 74 |
+--------------+----------------+----------+
从上面可以看出,poolId的选择性更好一些,创建索引时应该使用:(注:该种方式只是考虑到了平均选择性,并没有考虑到数据的分布情况)
alter table pool_configs add key('pool_id','domain_id');
基于数据分布--选择性(适用于少部分特殊情况)
在上面介绍了基于平均选择性(适用于绝大部分场景)的情况,现在考虑下面的一种特殊情况;
假设有一个表,包含字段 groupId和userId,大部分情况下,使用如下索引肯定是好的:
alter table xxx add key('groupId','userId');(大部分情况下,比较好)
alter table xxx add key('userId','groupId');(可能不是好选择)
但是,如果有个特殊的GroupId(可能是管理员组Id,假设值为:xxxx001),而几乎所有的记录都包含该GroupId(可能数据是从某处迁移过来,默认使用该GroupId),
select count(*), sum(groupId=xxxx001), sum(userId=xxx) from tablexxx \G;
-----output-----
count(*): 100W
sum(groupId=xxxx001): 99W
sum(userId=xxx):5w
则根据上面的平均选择性创建的索引可能几乎不起作用,这种特殊的数据分布,使用平均选择性可能会是情况变得更糟,甚至摧毁整个系统;
解决方案:
在应用层面解决,不允许查询groupId=xxx001的语句执行,特殊情况特殊对待;
索引合并
如下sql
select * from where busiId=001 or orgaId=004;
上面的sql使用or,mysql在进行查询时,可能会使用索引合并来进行优化;
可以通过explain来查看是否进行了索引合并(在Extra会出现Using union(xxx,xxx)字样);
索引合并
简单描述就是:
- 查询busiId=001的所有记录;
- 查询orgaId=004的所有记录;
- 根据
or或and决定对上述的结果进行或与运算;
索引合并,有时候能起到很好的优化效果,有时候并非如此;
出现索引合并,通常意味着,表上的索引设计的很糟糕;
比如:
- 有1w条数据;
- busiId=001查询出8000条数据;
- orgaId=004查询出7000条数据;
- 则进行union合并时,总共需要处理1.5w条数据,还不如直接进行全表扫描效率高;
索引合并通常会消耗更多的CPU和内存资源,可能还不如如下sql有效率;
select * from where busiId=001
union all
select * from where orgaId=004;
优化方式
最好的方式,还是考虑表结构和索引是否最优;
方式1:关闭索引合并功能,optimizer_switch;
方式2:使用ignore index提示,让优化器忽略掉某些索引;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号