
Kafka介绍
消息队列(MQ)简介
Kafka是一个消息队列
消息队列的作用:
异步 解耦 削峰
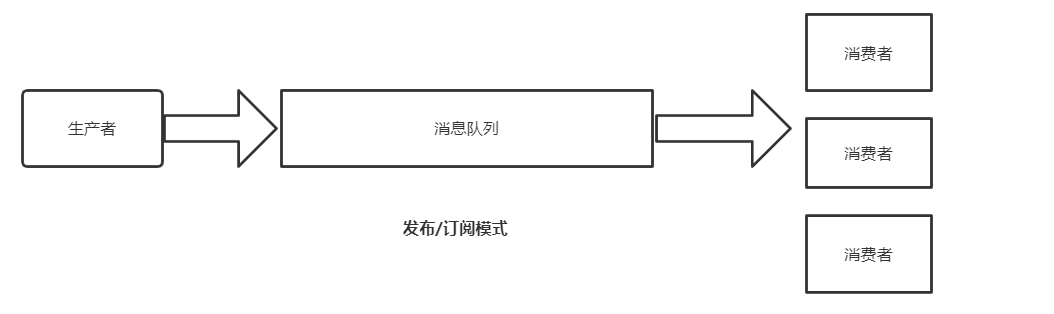
消息队列的两种模式:
1.点对点(消费者主动拉取数据,拉取完成消息清除)
2.发布订阅模式(一对多,消费者接收数据之后 不会清除消息)由队列主动给消费者推消息,速度由消息队列决定,消费者的处理能力不确定。
Kafka采用的是 发布订阅模式中的消费者主动拉取模式(需要维护一个消费者和队列之间的长轮询)
Kafka架构模型
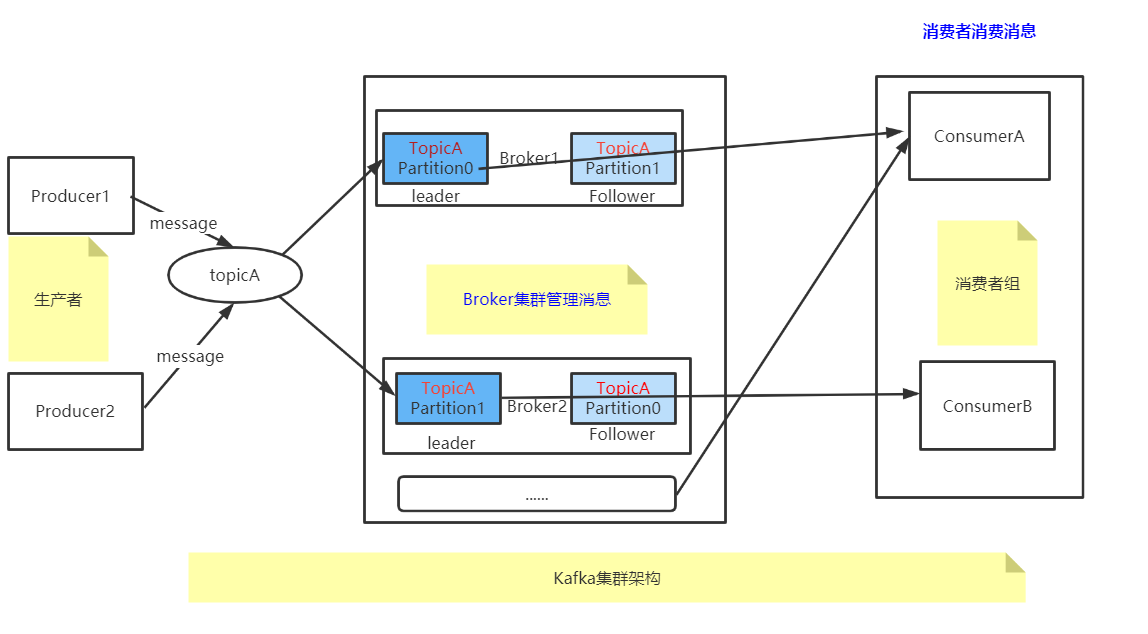
架构概念解释
1、Topic:
不同的TopicA TopicB 给数据分类,一个Topic可以理解为一个队列
2、Partition:
topic是逻辑的概念,partition是物理的概念,对用户来说是透明的。
producer只需要关心消息发往哪个topic,而consumer只关心自己订阅哪个topic,并不关心每条消息存于整个集群的哪个broker。
为了性能考虑,
TopicA一个主题多个分区,提高kafka负载能力。kafka消息队列不能保证全局有序性,只能保证区内有序。
3、Leader Follower:
一个分区Leader Follower 是主备高可用
4、Group:
分组的意义
假设一个topic有10个分区,如果没有消费者组,只有一个消费者对这10个分区消费,他的压力肯定大。
如果有了消费者组,组内的成员就可以分担这10个分区的压力,提高消费性能。
mq一共有两种基本消费模式:
1、load balancing(负载均衡):共享订阅、提高性能
2、fan-out(扇出):各自订阅、互不影响
那么有趣的地方来了,group内是load balancing,group间是fan-out
Kafka数据可靠性保证
怎么保证消息可靠呢?
回答:ack kafka选择全部同步完成才ack
但在副本多的情况下,如果有一个副本发生故障了怎么办?
acks参数配置(写入到副本要求严格程度)
0:producer不等待broker的ack。可能数据丢失
1:producer等待broker的ack,lead落盘成功后直接ack。可能数据丢失
-1:producer等待broker的ack,partition的leader和follower(ISR中的follower)全部落盘成功后才ack。可能重复发送
lead落盘之后,已经发送同步,但是没来得及发送ack。此时消息已经同步到follower,但是生产者会再次发送消息,导致消息重复投递。
此时需要做幂等性。kafka会通过消息的seq+Partition+Pid(producer的ID)生成一个唯一的key,持久化做幂等性。
ISR: in-sync-replica set 意为和Leader保持同步的follower集合。当ISR中的Follower完成数据的同步之后,leader就会给follower发送ack。
ISR淘汰策略:在同步时间和差距数量的权衡中高版本中只取决于时间,也就是把延迟时间最短的一些Follower 加到ISR队列中,如果主从数量不一致,取ISR中最小的那个作为集群的offset。
如果不使用ISR 有一个副本坏了,就没法ack了。
kafka如何保证消息的顺序性
Kafka 中发送1条消息的时候,可以指定(topic, partition, key) 3个参数。partiton 和 key 是可选的。
如果你指定了 partition,那就是所有消息发往同1个 partition,就是有序的。
并且在消费端,Kafka 保证,1个 partition 只能被1个 consumer 消费。
或者你指定 key(比如 order id),具有同1个 key 的所有消息,会发往同1个 partition。也是有序的。
在或者 你的topic只设置一个分区,这样topic下的所有消息都会发送到一个partion里面,从而有序
kafka分区策略
如果在发消息的时候指定了分区,则消息投递到指定的分区
如果没有指定分区,但是消息的key不为空,则基于key的哈希值来选择一个分区
如果既没有指定分区,且消息的key也是空,则用轮询的方式选择一个分区
kafka零拷贝 消费者 offset维护
Kafka消息挤压
一开始因为消费者故障挤压了几百万条数据。现在消费者好了 可以正常消费了,现在留下了一个问题
如果快速的将挤压的几百万条消息处理掉?
比如一个消费者1s消费1000条,一秒三个消费者是3000条,一分钟18w条,一千万数据需要一小时
这时候可以将消费者逻辑代码改一下,不处理后序的落库逻辑,而是把消息打到一个新建的临时的topic上面,这个topic可以扩容十倍(个分区)
其实 没必要这么麻烦,一开始topic分区多设置一点就好了。
由于业务高峰,或者由于节点故障,消息不能被消费,导致消息量剧增,消息积压。如何快速的将波峰抹平。
如果是正常的业务消息积压,不去处理,到峰值过后波峰自然会被抹平,有时几小时,有时候可能一天还不能处理完。要想不影响新的业务消息,就需要另想他法了。
-这里建议临时扩充consumer的数量,提高consumer的消费能力。另一方面,可以申请临时的topic 通过临时程序将积压的消息转移到临时topic,提高更多的consumer数量。
zookeeper在kafka中的作用
1.Broker注册
Broker是分布式部署,并且相互之间相互独立,但是需要一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了zookeeper。
在Zookeeper上有一个专门用来进行Broker服务器列表记录的节点 /broker/ids,每个Broker在启动时,都会到Zookeeper上注册。
即到/broker/ids下创建属于自己的节点,如 /broker/ids/[0...
kafka使用了全局唯一的数字来指代每个Broker服务器,不同的Broker必须使用不同的Broker ID进行注册。
创建完节点后,每个Broker就会将自己的IP地址和端口信息记录到该节点中去。
其中Broker创建的节点是临时节点,一旦Broker宕机,则对应的临时节点也会被自动删除
2. Topic注册
在Kafka中,同一个Topic消息会被分成多个分区,并将其分布在多个Broker上。
这些分区信息及与Broker的对应关系也都是由Zookeeper在维护,由专门的节点记录 如 /Broker/topics
Kafka中每个Topic都会以/brokers/topics[topic]的形式被记录,如/brokers/topics/login和/brokers/topics/search等
Logstash消费Kafka性能调优
平时开发过程中,开发把消息打到Kafka上,剩下就不用管了。运维通过Logstash把消息存储到es
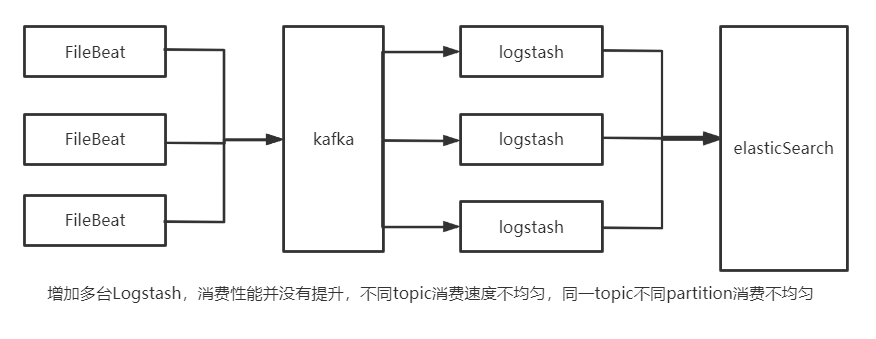
产生原因:
topic的partition的数量少
所有logstash的配置文件都相同,使用同一个group消费所有的topic
解决办法:
提高topic分区数量
对logstash进行分组,数据量较大的topic设置单独的一组logstash和消费组
每组logstash中总的消费线程数量和总的partition数量保持一致
logstash类似消费者,提高消费者分组的同时要考虑生产者的分区一并提高。

