
LRU和LFU的区别和使用场景
以下的讨论实现都是奔着O(1)时间复杂度
LRU
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
LRU 总体上是这样的,最近使用的放在前边(最左边),最近没用的放到后边(最右边),
来了一个新的数,如果内存满了,把旧的数淘汰掉(最右边),
那位了方便移动数据,我们肯定不能考虑用数组,
呼之欲出,就是使用链表了,
解决方案:链表(处理新老关系)+ 哈希(查询在不在),
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:
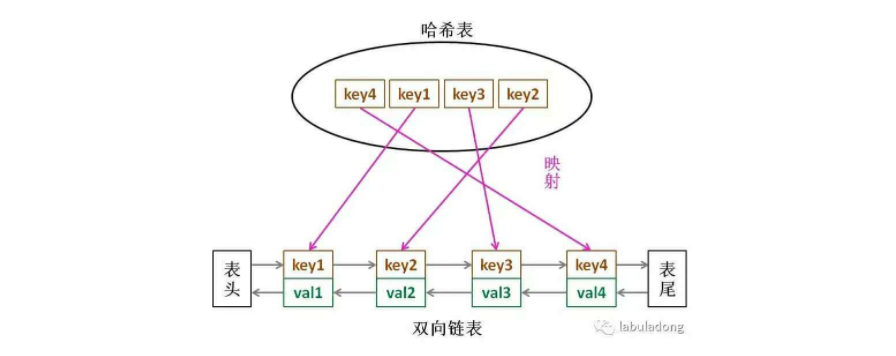
1、通常会用来做缓存的算法 当缓存被填满时,它应该删除最近最少使用的项目。
1.JDK自带的LinkHashMap实现


public class LRUCache{ int capacity; Map<Integer, Integer> map; public LRUCache(int capacity) { this.capacity = capacity; map = new LinkedHashMap<>(); } public int get(int key) { if (!map.containsKey(key)) { return -1; } // 先删除旧的位置,再放入新位置 Integer value = map.remove(key); map.put(key, value); return value; } public void put(int key, int value) { if (map.containsKey(key)) { map.remove(key); map.put(key, value); return; } map.put(key, value); // 超出capacity,删除最久没用的,利用迭代器删除第一个 if (map.size() > capacity) { map.remove(map.entrySet().iterator().next().getKey()); } } }
2.Map+双向联表实现
package com.mashibing.leetcode.link; import java.util.HashMap; import java.util.Map; public class LRUCache3HeadTail { private int capacity; private Map<Integer, ListNode> map; //key->node private ListNode head; // dummy head private ListNode tail; // dummy tail public LRUCache3HeadTail(int capacity) { this.capacity = capacity; map = new HashMap<>(); head = new ListNode(-1, -1); tail = new ListNode(-1, -1); head.next = tail; tail.pre = head; } public int get(int key) { if (!map.containsKey(key)) { return -1; } ListNode node = map.get(key); // 先删除该节点,再接到 头部 node.pre.next = node.next; node.next.pre = node.pre; moveToHead(node); return node.val; } public void put(int key, int value) { // 直接调用这边的get方法,如果存在,它会在get内部被移动到尾巴,不用再移动一遍,直接修改值即可 if (get(key) != -1) { map.get(key).val = value; return; } // 若不存在,new一个出来,如果超出容量,把尾去掉 ListNode node = new ListNode(key, value); map.put(key, node); moveToHead(node); if (map.size() > capacity) { map.remove(tail.pre.key); tail.pre = tail.pre.pre; tail.pre.next = tail; } } // 把节点移动到头部 private void moveToHead(ListNode node) { node.next = head.next; head.next = node; node.next.pre = node; node.pre = head; } // 定义双向链表节点 private class ListNode { int key; int val; ListNode pre; ListNode next; public ListNode(int key, int val) { this.key = key; this.val = val; pre = null; next = null; } } }
2、也可以作为负载均衡的算法
每次使用了每个节点的时候,就将该节点放置在最后面(做缓存时 放在前面),这样就保证每次使用的节点都是最近最久没有使用过的节点。
JDK自带的LinkHashMap实现
public String doRoute(String serviceKey, TreeSet<String> addressSet) { // cache clear if (System.currentTimeMillis() > CACHE_VALID_TIME) { jobLRUMap.clear(); CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;//一天 } // init lru LinkedHashMap<String, String> lruItem = jobLRUMap.get(serviceKey); if (lruItem == null) { /** * LinkedHashMap * a、accessOrder:ture=访问顺序排序(get/put时排序)/ACCESS-LAST;false=插入顺序排期/FIFO; * b、removeEldestEntry:新增元素时将会调用,返回true时会删除最老元素;可封装LinkedHashMap并重写该方法,比如定义最大容量,超出是返回true即可实现固定长度的LRU算法; */ lruItem = new LinkedHashMap<String, String>(16, 0.75f, true){ @Override protected boolean removeEldestEntry(Map.Entry<String, String> eldest) { if(super.size() > 3){ return true; }else{ return false; } } }; jobLRUMap.putIfAbsent(serviceKey, lruItem); } // put for (String address: addressSet) { if (!lruItem.containsKey(address)) { lruItem.put(address, address); } } // load String eldestKey = lruItem.entrySet().iterator().next().getKey(); String eldestValue = lruItem.get(eldestKey);//LRU算法关键体现在这里,实现了固定长度的LRU算法 return eldestValue; }
LFU
LRU算法是预测最近被访问的数据将来最有可能被访问到。
LFU(Least Frequently Used)最不经常使用。算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
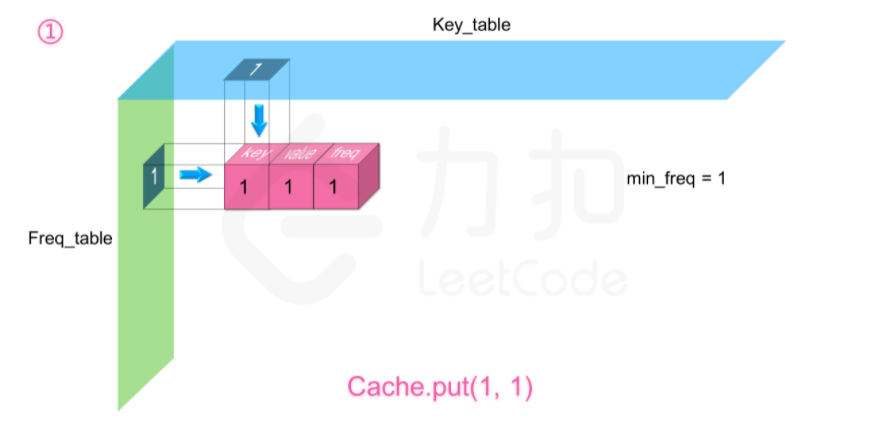
我们需要定义两个哈希表,第一个 freq_table 以频率 freq 为索引,每个索引存放一个双向链表,这个链表里存放所有使用频率为 freq 的缓存,
缓存里存放三个信息,分别为键 key,值 value,以及使用频率 freq。
第二个 key_table 以键值 key 为索引,每个索引存放对应缓存在 freq_table 中链表里的内存地址,这样我们就能利用两个哈希表来使得两个操作的时间复杂度均为 O(1)O(1)。
同时需要记录一个当前缓存最少使用的频率 minFreq,这是为了删除操作服务的。
这个数据结构长这样:
参考leetCode:https://leetcode-cn.com/problems/lfu-cache/solution/lfuhuan-cun-by-leetcode-solution/
1、LFU作为缓存算法
当缓存达到容量时,则应该在插入新的键值对之前,删除使用频次(后文用freq表示)最低的键值对。
如果freq最低的键值对有多个,则删除其中最旧的那个。
代码实现:
class LFUCache { int minfreq, capacity; Map<Integer, Node> key_table; Map<Integer, LinkedList<Node>> freq_table; public LFUCache(int capacity) { this.minfreq = 0; this.capacity = capacity; key_table = new HashMap<Integer, Node>();; freq_table = new HashMap<Integer, LinkedList<Node>>(); } public int get(int key) { if (capacity == 0) { return -1; } if (!key_table.containsKey(key)) { return -1; } Node node = key_table.get(key); int val = node.val, freq = node.freq; freq_table.get(freq).remove(node); // 如果当前链表为空,我们需要在哈希表中删除,且更新minFreq if (freq_table.get(freq).size() == 0) { freq_table.remove(freq); if (minfreq == freq) { minfreq += 1; } } // 插入到 freq + 1 中 LinkedList<Node> list = freq_table.getOrDefault(freq + 1, new LinkedList<Node>()); list.offerFirst(new Node(key, val, freq + 1)); freq_table.put(freq + 1, list); key_table.put(key, freq_table.get(freq + 1).peekFirst()); return val; } public void put(int key, int value) { if (capacity == 0) { return; } if (!key_table.containsKey(key)) { // 缓存已满,需要进行删除操作 if (key_table.size() == capacity) { // 通过 minFreq 拿到 freq_table[minFreq] 链表的末尾节点 Node node = freq_table.get(minfreq).peekLast(); key_table.remove(node.key); freq_table.get(minfreq).pollLast(); if (freq_table.get(minfreq).size() == 0) { freq_table.remove(minfreq); } } LinkedList<Node> list = freq_table.getOrDefault(1, new LinkedList<Node>()); list.offerFirst(new Node(key, value, 1)); freq_table.put(1, list); key_table.put(key, freq_table.get(1).peekFirst()); minfreq = 1; } else { // 与 get 操作基本一致,除了需要更新缓存的值 Node node = key_table.get(key); int freq = node.freq; freq_table.get(freq).remove(node); if (freq_table.get(freq).size() == 0) { freq_table.remove(freq); if (minfreq == freq) { minfreq += 1; } } LinkedList<Node> list = freq_table.getOrDefault(freq + 1, new LinkedList<Node>()); list.offerFirst(new Node(key, value, freq + 1)); freq_table.put(freq + 1, list); key_table.put(key, freq_table.get(freq + 1).peekFirst()); } } } class Node { int key, val, freq; Node(int key, int val, int freq) { this.key = key; this.val = val; this.freq = freq; } }
2、LFU作为负载均衡算法:保证每次使用都是最不经常使用的节点
代码实现(此代码时间复杂度不是O1)
package com.mashibing.leetcode.link; import java.util.HashMap; import java.util.Map; public class LRUCache3HeadTail { private int capacity; private Map<Integer, ListNode> map; //key->node private ListNode head; // dummy head private ListNode tail; // dummy tail public LRUCache3HeadTail(int capacity) { this.capacity = capacity; map = new HashMap<>(); head = new ListNode(-1, -1); tail = new ListNode(-1, -1); head.next = tail; tail.pre = head; } public int get(int key) { if (!map.containsKey(key)) { return -1; } ListNode node = map.get(key); // 先删除该节点,再接到 头部 node.pre.next = node.next; node.next.pre = node.pre; moveToHead(node); return node.val; } public void put(int key, int value) { // 直接调用这边的get方法,如果存在,它会在get内部被移动到尾巴,不用再移动一遍,直接修改值即可 if (get(key) != -1) { map.get(key).val = value; return; } // 若不存在,new一个出来,如果超出容量,把尾去掉 ListNode node = new ListNode(key, value); map.put(key, node); moveToHead(node); if (map.size() > capacity) { map.remove(tail.pre.key); tail.pre = tail.pre.pre; tail.pre.next = tail; } } // 把节点移动到头部 private void moveToHead(ListNode node) { node.next = head.next; head.next = node; node.next.pre = node; node.pre = head; } // 定义双向链表节点 private class ListNode { int key; int val; ListNode pre; ListNode next; public ListNode(int key, int val) { this.key = key; this.val = val; pre = null; next = null; } } }

