
深入浅出java的Map
HashMap的组成
首先了解数组和链表两个数据结构
1.数组 寻址容易,插入和删除元素困难
数组由于是紧凑连续存储,可以随机访问,通过索引快速找到对应元素,而且相对节约存储空间。
但正因为连续存储,内存空间必须一次性分配够,所以说数组如果要扩容,需要重新分配一块更大的空间,再把数据全部复制过去,时间复杂度 O(N);
而且你如果想在数组中间进行插入和删除,每次必须搬移后面的所有数据以保持连续,时间复杂度 O(N)。
2.链表 寻址困难,插入和删除元素容易
链表因为元素不连续,而是靠指针指向下一个元素的位置,所以不存在数组的扩容问题;如果知道某一元素的前驱和后驱,操作指针即可删除该元素或者插入新元素,时间复杂度O(1)。
但是正因为存储空间不连续,你无法根据一个索引算出对应元素的地址,所以不能随机访问;而且由于每个元素必须存储指向前后元素位置的指针,会消耗相对更多的储存空间。
另外值得惊醒的一句话是:
数据结构的存储方式只有两种:数组(顺序存储)和链表(链式存储)
Hash表的实现就是结合了数组和链表:https://blog.csdn.net/hadues/article/details/105384914
如下图:左边是一个数组,每个数组指向一个链表
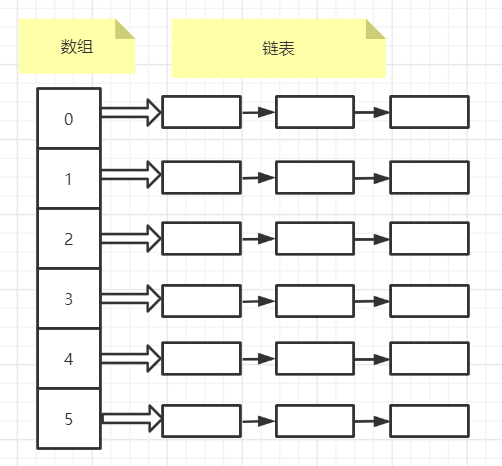
键值对插入Map的过程
首先map的key拿到之后,通过Hash函数计算出它的hashCode, 结合数组长度进行无符号右移(>>>)、按位异或、按位与(&)计算出索引,得到数组的Position,继而找到数组Position所指向的链表。
如果两个key的HashCode相同,我们会比较equals方法
- 如果equals相同:则将后添加的value覆盖之前的value
- 如果equals不同:则产生了Hash冲突,会划出一个节点存储数据,链接到链表后面
JDK1.8以后,如果数组长度大于64,并且链表长度大于8,则链表会进化成红黑树
HashMap集合的成员变量
1.集合的初始化容量(必须是2的n次幂)
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
计算hashCode在数组中的哪个位置,实际上就是取余,hash&(length-1)计算机中直接求余运算不如位移运算。
参考:高效取余运算 https://www.cnblogs.com/gne-hwz/p/10060260.html
如果数组长度不是2的n次幂,计算出的索引特别容易相同,及其容易发生hash碰撞
数组长度为9的时候 3&(9-1)=0 2&(9-1)=0 发生了hash碰撞
数组长度为8的时候 3&(8-1)=3 2&(8-1)=2 没发生哈希碰撞
2.默认的负载因子,默认是0.75
/** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
Map扩容的时,并不是把集合存满在扩容,集合数量达到加载因子*数组长度(默认16*0.75=12),才会扩容
负载因子是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。
3.当链表长度超过8时,会转变成红黑树
/** * The bin count threshold for using a tree rather than list for a * bin. Bins are converted to trees when adding an element to a * bin with at least this many nodes. The value must be greater * than 2 and should be at least 8 to mesh with assumptions in * tree removal about conversion back to plain bins upon * shrinkage. */ static final int TREEIFY_THRESHOLD = 8;
红黑树的查询效率虽然比链表高,但是占用空间是链表的两倍,之所以临界值是8 是根据数学的泊松分布概率 链表长度超过8的概率非常小
这是时间和空间的一个取舍
HashMap扩容机制
JDK1.7扩容时,会伴随一次重新的hash分配,并且会遍历Hash表中的所有元素,是非常耗时的。
JDK1.8扩容时,因为每次扩容都是翻倍,与原来计算的(n-1)&hash的结果相比,只是多了一个bit位,
所以节点要么就在原来的位置(e.hash&oldCap结果是0),要么就被分配到 原位置+旧容量 这个位置(e.hash&oldCap结果不等于0)
https://blog.csdn.net/zlp1992/article/details/104376309
JDK1.7 链表采用头插的方式 扩容时,在多线程的情况下可能出现循环链表(同一位置上新元素总会被放在链表的头部位置)
JDK1.8 链表采用的是尾插(不在倒序处理)
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了
ConCurrentHashMap
JDK7:ConcurrentHashMap采用了分段锁的,把容器默认分成16段,put值的时候 只是锁定16断中的一个部分,就是把锁给细化了
JDK8:采用的CAS自旋
JDK1.7 对于ConCurrentHashMap的size统计,当经过了两次计算(3次对比)之后,发现每次统计时Hash都有结构性的变化
这时它就会气急败坏的把所有Segment都加上锁;而当自己统计完成后,才会把锁释放掉,再允许其他线程修改哈希中的个数
JDK1.8 对于ConCurrentHashMap的size统计,JDK1.8借助了baseCount和counterCells两个属性,并配合多次CAS的方法,避免的锁的使用
/** * Base counter value, used mainly when there is no contention, * but also as a fallback during table initialization * races. Updated via CAS. */ private transient volatile long baseCount;/** * Table of counter cells. When non-null, size is a power of 2. */ private transient volatile CounterCell[] counterCells;
过程
1.当并发量较小的时,优先使用CAS的方式直接更新baseCount
2.当更新baseCount冲突,则会认为进入到比较激烈的竞争状态,通过启用counterCells减少竞争,通过CAS的方式把总数更新情况记录在counterCells对应的位置上
3.如果更新counterCells上的某个位置出现了多次失败,则会通过扩容counterCells的方式减少冲突
4.当counterCells在扩容期间,会尝试更新baseCount的值
对于元素总数的统计,逻辑就非常简单了,只需要让baseCount加上各counterCells内的数据,就可以得出哈希内的总数,整个过程完全不需要借助锁。
疑问:HashMap有线程安全的ConcurrentHashMap 但是TreeMap为什么没有ConcurrentTreeMap
因为CAS操作用在红黑树实现起来太复杂
所以用ConcurrentSkipListMap用CAS实现排序(跳表代替Tree)
跳表:在链表的基础上一层一层的加一些个关键元素的链表,加了个索引。跳表的查找效率比链表本身要高,同时它的CAS实现难度比TreeMap容易很多

