
前言
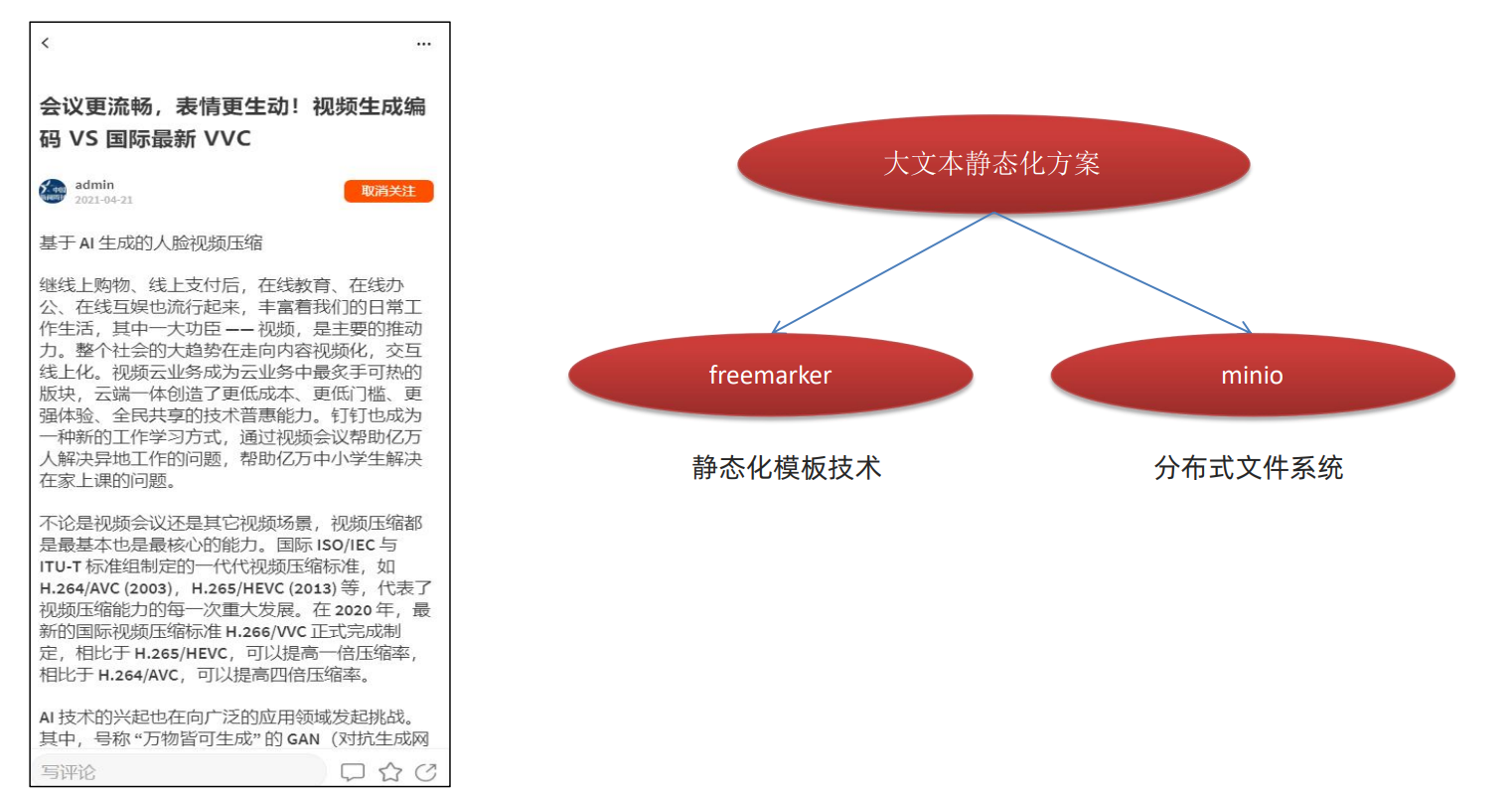
一、大文本静态化方案
一个新闻资讯网站,用户查询新闻/文章详情的频率会很高,所有我们可以使用大文本静态化方案减少数据库查询;
借助Freemarker模板引擎把文章详情中的大文本内容,提前渲染成HTML文件存储到对象存储服务-Minio中;
当用户查看新闻/文章详情时,直接使用URL从Minio-对象存储中get文章内容;
此举可以减少数据库查询,提升文章内容查询效率;
1.freemarker
模板渲染引擎,
1.1.模板


<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Hello World!</title> </head> <body> <b>普通文本 String 展示:</b><br><br> Hello ${name} <br> <hr> <b>对象Student中的数据展示:</b><br/> 姓名:${stu.name}<br/> 年龄:${stu.age} <hr> <#--1.集合遍历--> <#--2.if..else分支判断--> <#list studentList as student> <#if (student.age < 20) || (student.name="Martin")> <p style="color: aquamarine"> ${student.name}<---->${student.age}<br/></p> <#else> <p style="color: aqua">${student.name}<---->${student.age+6}</p> </#if> </#list> <#--3.判空、size方法、集合遍历--> <#if studentList??> <p>列表的总长度:${studentList?size} </p> <#list studentList as student> <#if (student.age < 20) || (student.name="Martin")> <p style="color: aquamarine"> ${student.name}<---->${student.age}<br/></p> <#else> <p style="color: aqua">${student.name}<---->${student.age+6}</p> </#if> </#list> </#if> <#--4.日期函数--> <#--5.内建函数 --> ${today?date} <br/> ${today?time} <br/> ${today?datetime} <br/> ${today?string("yyyy年MM月")} </body> </html>
1.2.单元测试
package com.heima.freemarker.demo; import freemarker.template.Configuration; import freemarker.template.Template; import freemarker.template.TemplateException; import org.junit.jupiter.api.Test; import org.junit.runner.RunWith; import org.springframework.test.context.junit4.SpringRunner; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import java.io.FileWriter; import java.io.IOException; import java.util.*; //单元测试和SpringBoot入口程序保证在同1个包下 @SpringBootTest(classes = FreemarkerDemoApplication.class) //@RunWith(SpringRunner.class) public class freemarkerTest { @Autowired private Configuration configuration; @Test public void test() throws IOException, TemplateException { //1.将生成的HTML文件放到当前目录 //2.导入configration依赖 //3.指定模板 Template template = configuration.getTemplate("01-basic.ftl"); //4.分配数据 Map context = getDate(); //5.生成文件 FileWriter fw = new FileWriter("test.html"); template.process(context, fw); } private Map getDate() { //map1 Map<String, Object> context = new HashMap<>(); context.put("name","张根"); Map<String, Object> stuMap1 = new HashMap<>(); stuMap1.put("name", "Martin"); stuMap1.put("age", 19); context.put("stu", stuMap1); //map2 Map<String, Object> stuMap2 = new HashMap<>(); stuMap2.put("name", "Tom"); stuMap2.put("age", 20); List<Map<String, Object>> studentList = new ArrayList<>(); studentList.add(stuMap1); studentList.add(stuMap2); context.put("studentList", studentList); // 新增日期字段 context.put("today", new Date()); return context; } }
2.分库分表
数据库优化方案
2.1.水平分表
水平分表就是指以行为单位对数据进行拆分,一般意义上的分库分表指的就是水平分表
分表之后,所有表的结构都是一样的。
2.2.垂直分表
表的记录并不多,但是字段却很长,表占用空间很大,检索表的时候需要执行大量的IO,严重降低了性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
垂直分表就是把一张表按列分为多张表,多张表通过主键进行关联,从而组成完整的数据。
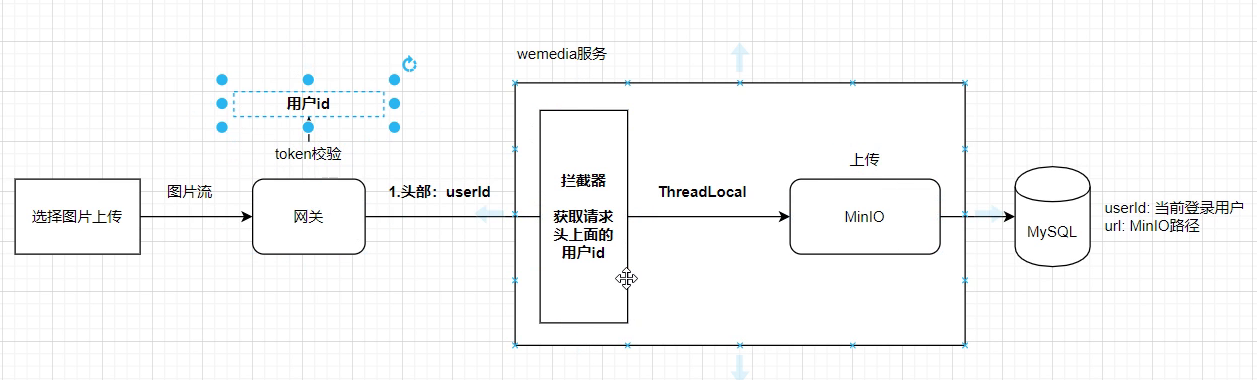
二、图片上传
SpringMVC拦截器只能返回true和false;
SpringMVC拦截器向SpringMVC处理器传递用户信息,借助ThreadLocal做中间介质;
三、新闻发布功能
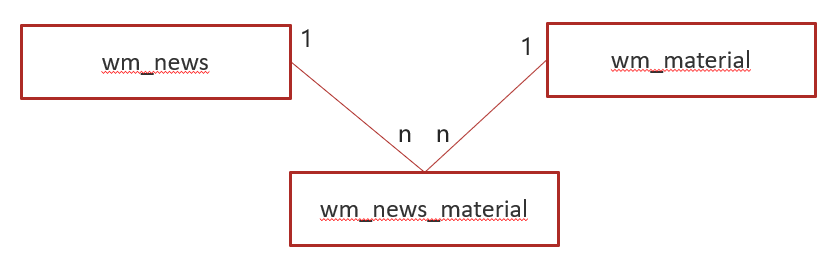
1.数据库表关系
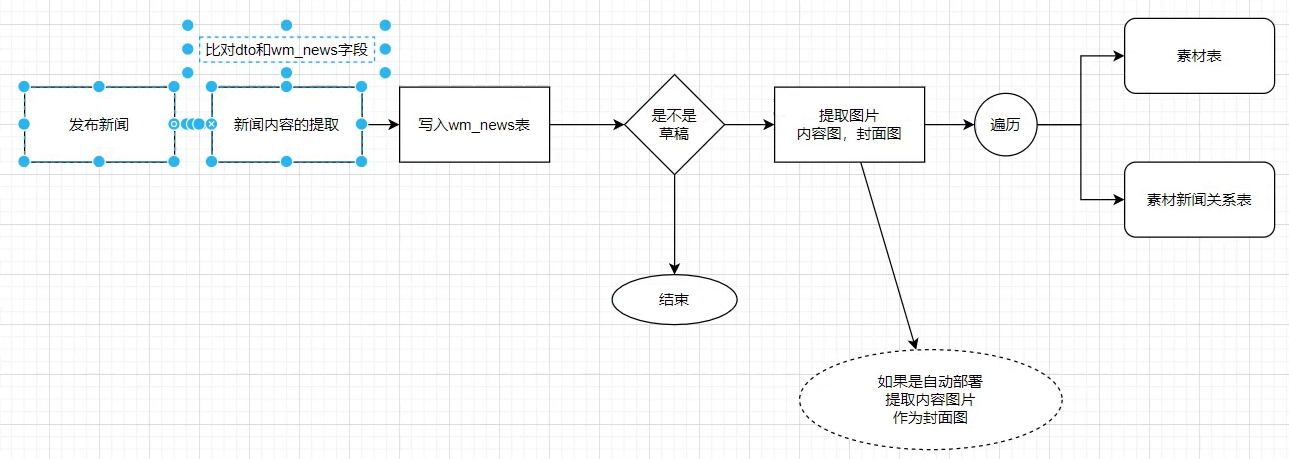
2.执行流程
四、新闻内容审核
Day03完成的新闻发布功能没有对新闻内容进行含敏感信息审核;
自媒体端发布新闻之后,通过阿里云的审核功能,对新闻的文字、图片内容进行自动审核;
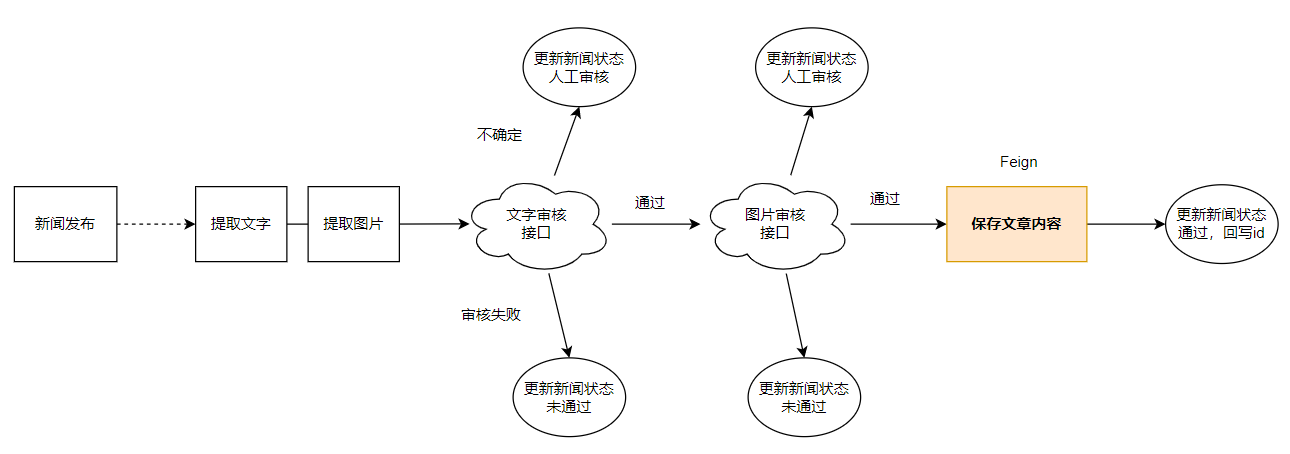
新闻的文字、图片内容审核通过之后,通过Feign向文章微服务发起远程调用,把新闻保存为文章;
远程调用之后文章微服务返回ArticleId,自媒体微服务获取ArticleId和wm_news的article_id自动进行新闻和文章的绑定;
五、自建议敏感词库
使用阿里云做新闻内容的审核,无法审核行业内一些专有敏感词;
需要自己维护1个敏感词库,再使用阿里云内容审核之前,先去自己的敏感词库匹配敏感词;
1.DFA算法
DFA全称 Deterministic Finite Automaton 即确定有穷自动机:从一个状态通过一系列的事件转换到另一个状态,即 state -> event -> state。
1.1.敏感词库初始化
DAF算法在初始化的时候,会把敏感词库中的所有敏感词,例如病毒、病毒你妹、冰棒、冰箱空调、冰墩墩、冰墩子拆成以下树状结构存储;
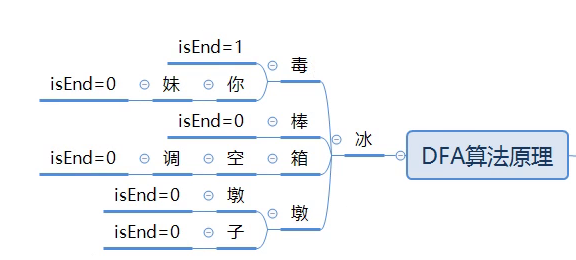
如果链路的结尾是isEnd=1代表是敏感词,isEnd=0代表非敏感词;
1.2.关键词和敏感词匹配
把客户输入的关键词也拆分成1个个的字,和敏感词库中存在的每一条链路进行比对,直到链路的边界结束;
1.命中敏感词情况
如果客户端输入病毒哈哈哈哈你妹啊,会把这句话拆成1个个的字;
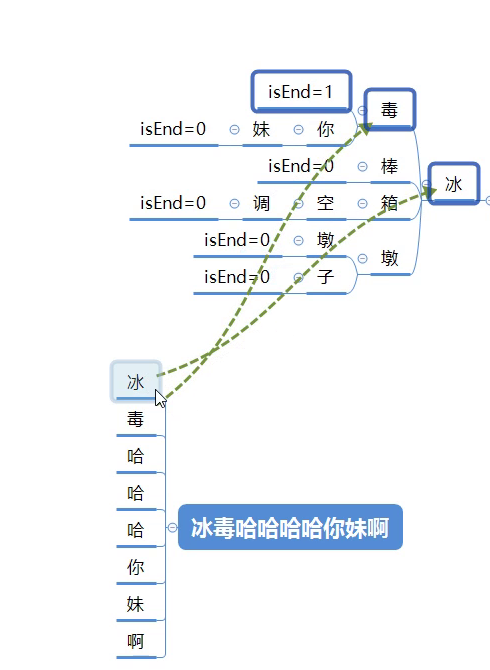
拿冰字和敏感词库中的冰字对比匹配成功;
判断是否是结尾?不是结尾
拿毒字和敏感词库中的毒字对比匹配成功 ;
判断是结尾isEnd=0病毒就是敏感词;
2.未命中敏感词情况
如果客户端输入病哈毒哈哈哈你妹啊,会把这句话拆成1个个的字;
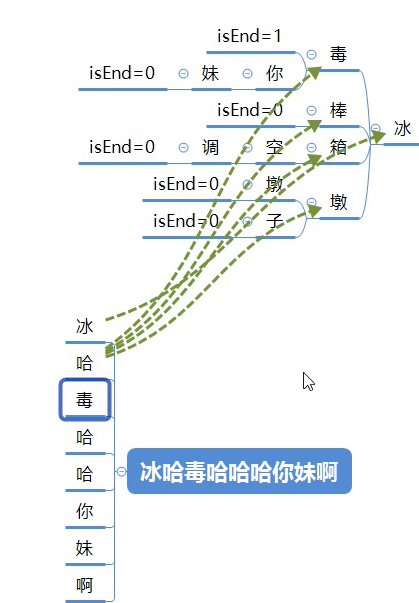
拿关键词中冰字和敏感词库中的冰字对比匹配成功;
判断是否是结尾?不是结尾
拿哈字和敏感词库中的毒字对比匹配失败;
拿哈字和敏感词库中的棒字对比匹配失败;
拿哈字和敏感词库中的箱字对比匹配失败;
拿哈字和敏感词库中的蹲字对比匹配失败;
---------------------------------------------------------
3.DFA算法实现
package com.heima.utils; import java.util.*; public class SensitiveWordUtil { public static Map<String, Object> dictionaryMap = new HashMap<>(); /** * 生成关键词字典库 * @param words * @return */ public static void initMap(Collection<String> words) { if (words == null) { System.out.println("敏感词列表不能为空"); return ; } // map初始长度words.size(),整个字典库的入口字数(小于words.size(),因为不同的词可能会有相同的首字) Map<String, Object> map = new HashMap<>(words.size()); // 遍历过程中当前层次的数据 Map<String, Object> curMap = null; Iterator<String> iterator = words.iterator(); while (iterator.hasNext()) { String word = iterator.next(); curMap = map; int len = word.length(); for (int i =0; i < len; i++) { // 遍历每个词的字 String key = String.valueOf(word.charAt(i)); // 当前字在当前层是否存在, 不存在则新建, 当前层数据指向下一个节点, 继续判断是否存在数据 Map<String, Object> wordMap = (Map<String, Object>) curMap.get(key); if (wordMap == null) { // 每个节点存在两个数据: 下一个节点和isEnd(是否结束标志) wordMap = new HashMap<>(2); wordMap.put("isEnd", "0"); curMap.put(key, wordMap); } curMap = wordMap; // 如果当前字是词的最后一个字,则将isEnd标志置1 if (i == len -1) { curMap.put("isEnd", "1"); } } } dictionaryMap = map; } /** * 搜索文本中某个文字是否匹配关键词 * @param text * @param beginIndex * @return */ private static int checkWord(String text, int beginIndex) { if (dictionaryMap == null) { throw new RuntimeException("字典不能为空"); } boolean isEnd = false; int wordLength = 0; Map<String, Object> curMap = dictionaryMap; int len = text.length(); // 从文本的第beginIndex开始匹配 for (int i = beginIndex; i < len; i++) { String key = String.valueOf(text.charAt(i)); // 获取当前key的下一个节点 curMap = (Map<String, Object>) curMap.get(key); if (curMap == null) { break; } else { wordLength ++; if ("1".equals(curMap.get("isEnd"))) { isEnd = true; } } } if (!isEnd) { wordLength = 0; } return wordLength; } /** * 获取匹配的关键词和命中次数 * @param text * @return */ public static Map<String, Integer> matchWords(String text) { Map<String, Integer> wordMap = new HashMap<>(); int len = text.length(); for (int i = 0; i < len; i++) { int wordLength = checkWord(text, i); if (wordLength > 0) { String word = text.substring(i, i + wordLength); // 添加关键词匹配次数 if (wordMap.containsKey(word)) { wordMap.put(word, wordMap.get(word) + 1); } else { wordMap.put(word, 1); } i += wordLength - 1; } } return wordMap; } public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("是是"); list.add("法是功"); list.add("冰毒"); initMap(list); String content="我是一个好人,并不会卖冰毒,我真的不卖冰毒"; Map<String, Integer> map = matchWords(content); System.out.println(map); } }
4.调用
//调用自建敏感词库进行内容审核 private Boolean dfaCheck(String sentence){ if(StringUtils.isBlank(sentence)){ return true; } //1.使用DFA算法进行自建敏感词处理 //2.调用敏感词Mapper,查询所有敏感词 LambdaQueryWrapper<WmSensitive> wrapper = new LambdaQueryWrapper<>(); wrapper.select(WmSensitive::getSensitives); List<WmSensitive> wmSensitives = wmSensitiveMapper.selectList(wrapper); if(CollectionUtils.isEmpty(wmSensitives)){ return true; } List<String> words = wmSensitives.stream().filter(Objects::nonNull).map(WmSensitive::getSensitives).collect(Collectors.toList()); if(CollectionUtils.isEmpty(words)){ return true; } //3.DFA初始化 SensitiveWordUtil.initMap(words); //4.DFA敏感词对比 Map<String, Integer> result = SensitiveWordUtil.matchWords(sentence); //5.判断结果 return CollectionUtils.isEmpty(result); } //分析阿里云返回的扫描结果 private Boolean analyseScanResult(Map scanMap, Long articleId, Integer newsId) { //判断审核结果是否为空 if (CollectionUtils.isEmpty(scanMap)) { log.warn("审核结果为空"); return true; } String suggestion = (String) scanMap.get("suggestion"); if ("pass".equals(suggestion)) { return true; } else if ("block".equals(suggestion)) { //审核未通过----更新wmNews表的status字段,但是不更新wmNes表的articleId字段 updateWmNews(2, "未通过", articleId, newsId); return false; } else if ("review".equals(suggestion)) { //审核未通过----更新wmNews表的status字段,但是不更新wmNes表的articleId字段 updateWmNews(3, "转人工审核", articleId, newsId); } return true; }
六、图片文字审核
文章中包含的图片要识别文字,过滤掉图片文字的敏感词;

1.OCR
| 说明 | |
|---|---|
| 百度OCR | 收费 |
| Tesseract-OCR | Google维护的开源OCR引擎,支持Java,Python等语言调用 |
| Tess4J |
利用OCR技术提取图片中的文字内容,进行DFA和阿里云文字内容审核;
2.引入OCR依赖
<!--ocr依赖--> <dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>4.1.1</version> </dependency>
3.工具类
package com.heima.utils; import net.sourceforge.tess4j.ITesseract; import net.sourceforge.tess4j.Tesseract; import net.sourceforge.tess4j.TesseractException; import java.awt.image.BufferedImage; public class OcrUtil { private final static String DATA_PATH = "D:\\workspace\\cp386\\project\\lead-news\\leadnews-base\\"; private final static String LANGUAGE = "chi_sim"; public static String doOcr(BufferedImage image) throws TesseractException { //创建Tesseract对象 ITesseract tesseract = new Tesseract(); //设置字体库路径 tesseract.setDatapath(DATA_PATH); //中文识别 tesseract.setLanguage(LANGUAGE); //执行ocr识别 String result = tesseract.doOCR(image); //替换回车和tal键 使结果为一行 result = result.replaceAll("[\\r\\n]", "-").replaceAll(" ", ""); return result; } }
4.添加中文字体库
导入中文字体库, 把资料中的 chi_sim.traineddata 文件拷贝到项目根目录下
5.调用工具类
//调用ORC进行图片中包含文字的检测 private String orcCheck(List<byte[]> images) throws IOException, TesseractException { //判空 if (CollectionUtils.isEmpty(images)) { return ""; } StringBuilder stringBuilder = new StringBuilder(); //接收图片并遍历 for (byte[] image : images) { //调用ORC工具类,提取图片中的内容 ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(image); BufferedImage read = ImageIO.read(byteArrayInputStream); String textFromImage = OcrUtil.doOcr(read); //将文字内容组成1个字符串 stringBuilder.append(textFromImage); } //返回提取到的文字 return stringBuilder.toString(); }

1.
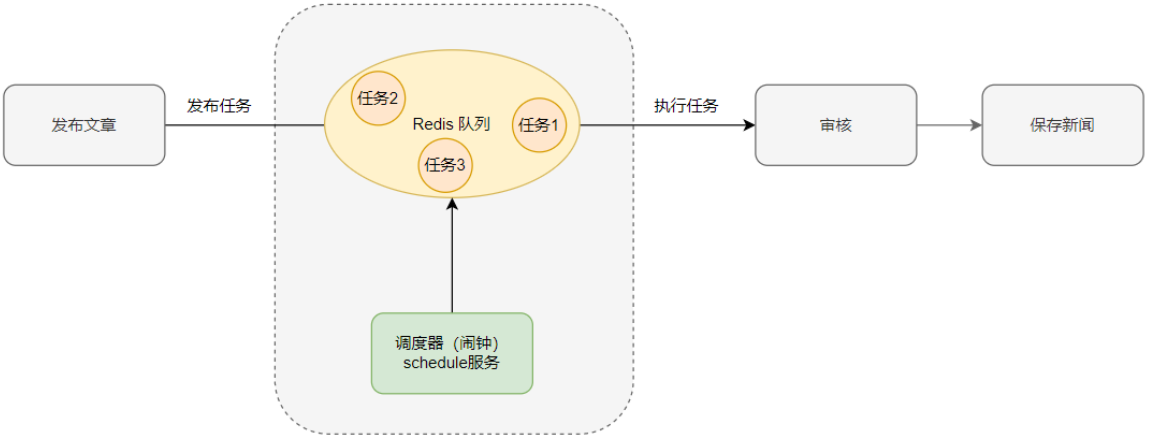
场景一:订单下单之后30分钟后,如果用户没有付钱,则系统自动取消订单;如果期间下单成功,任务取消
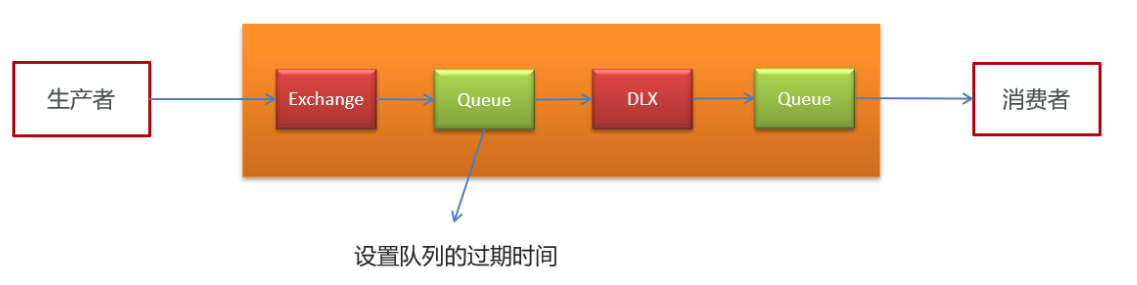
3.1.RabbitMQ实现延迟任务
-
TTL:Time To Live (消息存活时间)
-

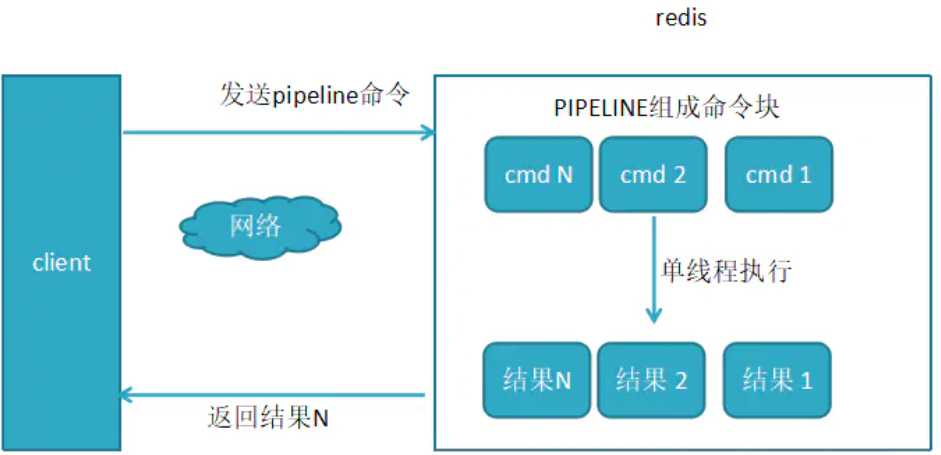
4.Redis管道技术
管道(pipeline)可以一次性发送多条命令并在执行完后一次性将结果返回;
Pipeline通过减少客户端与Redis的通信次数来实现降低往返延时时间;
Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性;
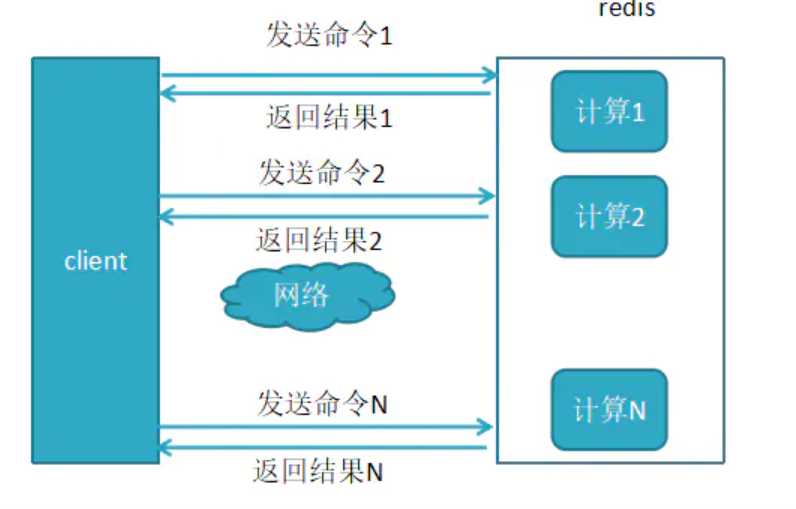
Pipline管道技术比逐条执行要快,特别是客户端与服务端的网络延迟越大,体能越明显;
代码
package com.heima.common.chache; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cache.annotation.CachingConfigurerSupport; import org.springframework.dao.DataAccessException; import org.springframework.data.redis.connection.DataType; import org.springframework.data.redis.connection.RedisConnection; import org.springframework.data.redis.connection.StringRedisConnection; import org.springframework.data.redis.core.Cursor; import org.springframework.data.redis.core.RedisCallback; import org.springframework.data.redis.core.ScanOptions; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.data.redis.core.ZSetOperations.TypedTuple; import org.springframework.lang.Nullable; import org.springframework.stereotype.Component; import java.io.IOException; import java.util.*; import java.util.concurrent.TimeUnit; @Component public class CacheService extends CachingConfigurerSupport { @Autowired private StringRedisTemplate stringRedisTemplate; public StringRedisTemplate getstringRedisTemplate() { return this.stringRedisTemplate; } /** -------------------key相关操作--------------------- */ /** * 删除key * * @param key */ public void delete(String key) { stringRedisTemplate.delete(key); } /** * 批量删除key * * @param keys */ public void delete(Collection<String> keys) { stringRedisTemplate.delete(keys); } /** * 序列化key * * @param key * @return */ public byte[] dump(String key) { return stringRedisTemplate.dump(key); } /** * 是否存在key * * @param key * @return */ public Boolean exists(String key) { return stringRedisTemplate.hasKey(key); } /** * 设置过期时间 * * @param key * @param timeout * @param unit * @return */ public Boolean expire(String key, long timeout, TimeUnit unit) { return stringRedisTemplate.expire(key, timeout, unit); } /** * 设置过期时间 * * @param key * @param date * @return */ public Boolean expireAt(String key, Date date) { return stringRedisTemplate.expireAt(key, date); } /** * 查找匹配的key * * @param pattern * @return */ public Set<String> keys(String pattern) { return stringRedisTemplate.keys(pattern); } /** * 将当前数据库的 key 移动到给定的数据库 db 当中 * * @param key * @param dbIndex * @return */ public Boolean move(String key, int dbIndex) { return stringRedisTemplate.move(key, dbIndex); } /** * 移除 key 的过期时间,key 将持久保持 * * @param key * @return */ public Boolean persist(String key) { return stringRedisTemplate.persist(key); } /** * 返回 key 的剩余的过期时间 * * @param key * @param unit * @return */ public Long getExpire(String key, TimeUnit unit) { return stringRedisTemplate.getExpire(key, unit); } /** * 返回 key 的剩余的过期时间 * * @param key * @return */ public Long getExpire(String key) { return stringRedisTemplate.getExpire(key); } /** * 从当前数据库中随机返回一个 key * * @return */ public String randomKey() { return stringRedisTemplate.randomKey(); } /** * 修改 key 的名称 * * @param oldKey * @param newKey */ public void rename(String oldKey, String newKey) { stringRedisTemplate.rename(oldKey, newKey); } /** * 仅当 newkey 不存在时,将 oldKey 改名为 newkey * * @param oldKey * @param newKey * @return */ public Boolean renameIfAbsent(String oldKey, String newKey) { return stringRedisTemplate.renameIfAbsent(oldKey, newKey); } /** * 返回 key 所储存的值的类型 * * @param key * @return */ public DataType type(String key) { return stringRedisTemplate.type(key); } /** -------------------string相关操作--------------------- */ /** * 设置指定 key 的值 * * @param key * @param value */ public void set(String key, String value) { stringRedisTemplate.opsForValue().set(key, value); } /** * 获取指定 key 的值 * * @param key * @return */ public String get(String key) { return stringRedisTemplate.opsForValue().get(key); } /** * 返回 key 中字符串值的子字符 * * @param key * @param start * @param end * @return */ public String getRange(String key, long start, long end) { return stringRedisTemplate.opsForValue().get(key, start, end); } /** * 将给定 key 的值设为 value ,并返回 key 的旧值(old value) * * @param key * @param value * @return */ public String getAndSet(String key, String value) { return stringRedisTemplate.opsForValue().getAndSet(key, value); } /** * 对 key 所储存的字符串值,获取指定偏移量上的位(bit) * * @param key * @param offset * @return */ public Boolean getBit(String key, long offset) { return stringRedisTemplate.opsForValue().getBit(key, offset); } /** * 批量获取 * * @param keys * @return */ public List<String> multiGet(Collection<String> keys) { return stringRedisTemplate.opsForValue().multiGet(keys); } /** * 设置ASCII码, 字符串'a'的ASCII码是97, 转为二进制是'01100001', 此方法是将二进制第offset位值变为value * * @param key * @param * @param value 值,true为1, false为0 * @return */ public boolean setBit(String key, long offset, boolean value) { return stringRedisTemplate.opsForValue().setBit(key, offset, value); } /** * 将值 value 关联到 key ,并将 key 的过期时间设为 timeout * * @param key * @param value * @param timeout 过期时间 * @param unit 时间单位, 天:TimeUnit.DAYS 小时:TimeUnit.HOURS 分钟:TimeUnit.MINUTES * 秒:TimeUnit.SECONDS 毫秒:TimeUnit.MILLISECONDS */ public void setEx(String key, String value, long timeout, TimeUnit unit) { stringRedisTemplate.opsForValue().set(key, value, timeout, unit); } /** * 只有在 key 不存在时设置 key 的值 * * @param key * @param value * @return 之前已经存在返回false, 不存在返回true */ public boolean setIfAbsent(String key, String value) { return stringRedisTemplate.opsForValue().setIfAbsent(key, value); } /** * 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始 * * @param key * @param value * @param offset 从指定位置开始覆写 */ public void setRange(String key, String value, long offset) { stringRedisTemplate.opsForValue().set(key, value, offset); } /** * 获取字符串的长度 * * @param key * @return */ public Long size(String key) { return stringRedisTemplate.opsForValue().size(key); } /** * 批量添加 * * @param maps */ public void multiSet(Map<String, String> maps) { stringRedisTemplate.opsForValue().multiSet(maps); } /** * 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 * * @param maps * @return 之前已经存在返回false, 不存在返回true */ public boolean multiSetIfAbsent(Map<String, String> maps) { return stringRedisTemplate.opsForValue().multiSetIfAbsent(maps); } /** * 增加(自增长), 负数则为自减 * * @param key * @param * @return */ public Long incrBy(String key, long increment) { return stringRedisTemplate.opsForValue().increment(key, increment); } /** * @param key * @param * @return */ public Double incrByFloat(String key, double increment) { return stringRedisTemplate.opsForValue().increment(key, increment); } /** * 追加到末尾 * * @param key * @param value * @return */ public Integer append(String key, String value) { return stringRedisTemplate.opsForValue().append(key, value); } /** -------------------hash相关操作------------------------- */ /** * 获取存储在哈希表中指定字段的值 * * @param key * @param field * @return */ public Object hGet(String key, String field) { return stringRedisTemplate.opsForHash().get(key, field); } /** * 获取所有给定字段的值 * * @param key * @return */ public Map<Object, Object> hGetAll(String key) { return stringRedisTemplate.opsForHash().entries(key); } /** * 获取所有给定字段的值 * * @param key * @param fields * @return */ public List<Object> hMultiGet(String key, Collection<Object> fields) { return stringRedisTemplate.opsForHash().multiGet(key, fields); } public void hPut(String key, String hashKey, String value) { stringRedisTemplate.opsForHash().put(key, hashKey, value); } public void hPutAll(String key, Map<String, String> maps) { stringRedisTemplate.opsForHash().putAll(key, maps); } /** * 仅当hashKey不存在时才设置 * * @param key * @param hashKey * @param value * @return */ public Boolean hPutIfAbsent(String key, String hashKey, String value) { return stringRedisTemplate.opsForHash().putIfAbsent(key, hashKey, value); } /** * 删除一个或多个哈希表字段 * * @param key * @param fields * @return */ public Long hDelete(String key, Object... fields) { return stringRedisTemplate.opsForHash().delete(key, fields); } /** * 查看哈希表 key 中,指定的字段是否存在 * * @param key * @param field * @return */ public boolean hExists(String key, String field) { return stringRedisTemplate.opsForHash().hasKey(key, field); } /** * 为哈希表 key 中的指定字段的整数值加上增量 increment * * @param key * @param field * @param increment * @return */ public Long hIncrBy(String key, Object field, long increment) { return stringRedisTemplate.opsForHash().increment(key, field, increment); } /** * 为哈希表 key 中的指定字段的整数值加上增量 increment * * @param key * @param field * @param delta * @return */ public Double hIncrByFloat(String key, Object field, double delta) { return stringRedisTemplate.opsForHash().increment(key, field, delta); } /** * 获取所有哈希表中的字段 * * @param key * @return */ public Set<Object> hKeys(String key) { return stringRedisTemplate.opsForHash().keys(key); } /** * 获取哈希表中字段的数量 * * @param key * @return */ public Long hSize(String key) { return stringRedisTemplate.opsForHash().size(key); } /** * 获取哈希表中所有值 * * @param key * @return */ public List<Object> hValues(String key) { return stringRedisTemplate.opsForHash().values(key); } /** * 迭代哈希表中的键值对 * * @param key * @param options * @return */ public Cursor<Map.Entry<Object, Object>> hScan(String key, ScanOptions options) { return stringRedisTemplate.opsForHash().scan(key, options); } /** ------------------------list相关操作---------------------------- */ /** * 通过索引获取列表中的元素 * * @param key * @param index * @return */ public String lIndex(String key, long index) { return stringRedisTemplate.opsForList().index(key, index); } /** * 获取列表指定范围内的元素 * * @param key * @param start 开始位置, 0是开始位置 * @param end 结束位置, -1返回所有 * @return */ public List<String> lRange(String key, long start, long end) { return stringRedisTemplate.opsForList().range(key, start, end); } /** * 存储在list头部 * * @param key * @param value * @return */ public Long lLeftPush(String key, String value) { return stringRedisTemplate.opsForList().leftPush(key, value); } /** * @param key * @param value * @return */ public Long lLeftPushAll(String key, String... value) { return stringRedisTemplate.opsForList().leftPushAll(key, value); } /** * @param key * @param value * @return */ public Long lLeftPushAll(String key, Collection<String> value) { return stringRedisTemplate.opsForList().leftPushAll(key, value); } /** * 当list存在的时候才加入 * * @param key * @param value * @return */ public Long lLeftPushIfPresent(String key, String value) { return stringRedisTemplate.opsForList().leftPushIfPresent(key, value); } /** * 如果pivot存在,再pivot前面添加 * * @param key * @param pivot * @param value * @return */ public Long lLeftPush(String key, String pivot, String value) { return stringRedisTemplate.opsForList().leftPush(key, pivot, value); } /** * @param key * @param value * @return */ public Long lRightPush(String key, String value) { return stringRedisTemplate.opsForList().rightPush(key, value); } /** * @param key * @param value * @return */ public Long lRightPushAll(String key, String... value) { return stringRedisTemplate.opsForList().rightPushAll(key, value); } /** * @param key * @param value * @return */ public Long lRightPushAll(String key, Collection<String> value) { return stringRedisTemplate.opsForList().rightPushAll(key, value); } /** * 为已存在的列表添加值 * * @param key * @param value * @return */ public Long lRightPushIfPresent(String key, String value) { return stringRedisTemplate.opsForList().rightPushIfPresent(key, value); } /** * 在pivot元素的右边添加值 * * @param key * @param pivot * @param value * @return */ public Long lRightPush(String key, String pivot, String value) { return stringRedisTemplate.opsForList().rightPush(key, pivot, value); } /** * 通过索引设置列表元素的值 * * @param key * @param index 位置 * @param value */ public void lSet(String key, long index, String value) { stringRedisTemplate.opsForList().set(key, index, value); } /** * 移出并获取列表的第一个元素 * * @param key * @return 删除的元素 */ public String lLeftPop(String key) { return stringRedisTemplate.opsForList().leftPop(key); } /** * 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 * * @param key * @param timeout 等待时间 * @param unit 时间单位 * @return */ public String lBLeftPop(String key, long timeout, TimeUnit unit) { return stringRedisTemplate.opsForList().leftPop(key, timeout, unit); } /** * 移除并获取列表最后一个元素 * * @param key * @return 删除的元素 */ public String lRightPop(String key) { return stringRedisTemplate.opsForList().rightPop(key); } /** * 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 * * @param key * @param timeout 等待时间 * @param unit 时间单位 * @return */ public String lBRightPop(String key, long timeout, TimeUnit unit) { return stringRedisTemplate.opsForList().rightPop(key, timeout, unit); } /** * 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 * * @param sourceKey * @param destinationKey * @return */ public String lRightPopAndLeftPush(String sourceKey, String destinationKey) { return stringRedisTemplate.opsForList().rightPopAndLeftPush(sourceKey, destinationKey); } /** * 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 * * @param sourceKey * @param destinationKey * @param timeout * @param unit * @return */ public String lBRightPopAndLeftPush(String sourceKey, String destinationKey, long timeout, TimeUnit unit) { return stringRedisTemplate.opsForList().rightPopAndLeftPush(sourceKey, destinationKey, timeout, unit); } /** * 删除集合中值等于value得元素 * * @param key * @param index index=0, 删除所有值等于value的元素; index>0, 从头部开始删除第一个值等于value的元素; * index<0, 从尾部开始删除第一个值等于value的元素; * @param value * @return */ public Long lRemove(String key, long index, String value) { return stringRedisTemplate.opsForList().remove(key, index, value); } /** * 裁剪list * * @param key * @param start * @param end */ public void lTrim(String key, long start, long end) { stringRedisTemplate.opsForList().trim(key, start, end); } /** * 获取列表长度 * * @param key * @return */ public Long lLen(String key) { return stringRedisTemplate.opsForList().size(key); } /** --------------------set相关操作-------------------------- */ /** * set添加元素 * * @param key * @param values * @return */ public Long sAdd(String key, String... values) { return stringRedisTemplate.opsForSet().add(key, values); } /** * set移除元素 * * @param key * @param values * @return */ public Long sRemove(String key, Object... values) { return stringRedisTemplate.opsForSet().remove(key, values); } /** * 移除并返回集合的一个随机元素 * * @param key * @return */ public String sPop(String key) { return stringRedisTemplate.opsForSet().pop(key); } /** * 将元素value从一个集合移到另一个集合 * * @param key * @param value * @param destKey * @return */ public Boolean sMove(String key, String value, String destKey) { return stringRedisTemplate.opsForSet().move(key, value, destKey); } /** * 获取集合的大小 * * @param key * @return */ public Long sSize(String key) { return stringRedisTemplate.opsForSet().size(key); } /** * 判断集合是否包含value * * @param key * @param value * @return */ public Boolean sIsMember(String key, Object value) { return stringRedisTemplate.opsForSet().isMember(key, value); } /** * 获取两个集合的交集 * * @param key * @param otherKey * @return */ public Set<String> sIntersect(String key, String otherKey) { return stringRedisTemplate.opsForSet().intersect(key, otherKey); } /** * 获取key集合与多个集合的交集 * * @param key * @param otherKeys * @return */ public Set<String> sIntersect(String key, Collection<String> otherKeys) { return stringRedisTemplate.opsForSet().intersect(key, otherKeys); } /** * key集合与otherKey集合的交集存储到destKey集合中 * * @param key * @param otherKey * @param destKey * @return */ public Long sIntersectAndStore(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForSet().intersectAndStore(key, otherKey, destKey); } /** * key集合与多个集合的交集存储到destKey集合中 * * @param key * @param otherKeys * @param destKey * @return */ public Long sIntersectAndStore(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForSet().intersectAndStore(key, otherKeys, destKey); } /** * 获取两个集合的并集 * * @param key * @param otherKeys * @return */ public Set<String> sUnion(String key, String otherKeys) { return stringRedisTemplate.opsForSet().union(key, otherKeys); } /** * 获取key集合与多个集合的并集 * * @param key * @param otherKeys * @return */ public Set<String> sUnion(String key, Collection<String> otherKeys) { return stringRedisTemplate.opsForSet().union(key, otherKeys); } /** * key集合与otherKey集合的并集存储到destKey中 * * @param key * @param otherKey * @param destKey * @return */ public Long sUnionAndStore(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForSet().unionAndStore(key, otherKey, destKey); } /** * key集合与多个集合的并集存储到destKey中 * * @param key * @param otherKeys * @param destKey * @return */ public Long sUnionAndStore(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForSet().unionAndStore(key, otherKeys, destKey); } /** * 获取两个集合的差集 * * @param key * @param otherKey * @return */ public Set<String> sDifference(String key, String otherKey) { return stringRedisTemplate.opsForSet().difference(key, otherKey); } /** * 获取key集合与多个集合的差集 * * @param key * @param otherKeys * @return */ public Set<String> sDifference(String key, Collection<String> otherKeys) { return stringRedisTemplate.opsForSet().difference(key, otherKeys); } /** * key集合与otherKey集合的差集存储到destKey中 * * @param key * @param otherKey * @param destKey * @return */ public Long sDifference(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForSet().differenceAndStore(key, otherKey, destKey); } /** * key集合与多个集合的差集存储到destKey中 * * @param key * @param otherKeys * @param destKey * @return */ public Long sDifference(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForSet().differenceAndStore(key, otherKeys, destKey); } /** * 获取集合所有元素 * * @param key * @param * @param * @return */ public Set<String> setMembers(String key) { return stringRedisTemplate.opsForSet().members(key); } /** * 随机获取集合中的一个元素 * * @param key * @return */ public String sRandomMember(String key) { return stringRedisTemplate.opsForSet().randomMember(key); } /** * 随机获取集合中count个元素 * * @param key * @param count * @return */ public List<String> sRandomMembers(String key, long count) { return stringRedisTemplate.opsForSet().randomMembers(key, count); } /** * 随机获取集合中count个元素并且去除重复的 * * @param key * @param count * @return */ public Set<String> sDistinctRandomMembers(String key, long count) { return stringRedisTemplate.opsForSet().distinctRandomMembers(key, count); } /** * @param key * @param options * @return */ public Cursor<String> sScan(String key, ScanOptions options) { return stringRedisTemplate.opsForSet().scan(key, options); } /**------------------zSet相关操作--------------------------------*/ /** * 添加元素,有序集合是按照元素的score值由小到大排列 * * @param key * @param value * @param score * @return */ public Boolean zAdd(String key, String value, double score) { return stringRedisTemplate.opsForZSet().add(key, value, score); } /** * @param key * @param values * @return */ public Long zAdd(String key, Set<TypedTuple<String>> values) { return stringRedisTemplate.opsForZSet().add(key, values); } /** * @param key * @param values * @return */ public Long zRemove(String key, Object... values) { return stringRedisTemplate.opsForZSet().remove(key, values); } public Long zRemove(String key, Collection<String> values) { if (values != null && !values.isEmpty()) { Object[] objs = values.toArray(new Object[values.size()]); return stringRedisTemplate.opsForZSet().remove(key, objs); } return 0L; } /** * 增加元素的score值,并返回增加后的值 * * @param key * @param value * @param delta * @return */ public Double zIncrementScore(String key, String value, double delta) { return stringRedisTemplate.opsForZSet().incrementScore(key, value, delta); } /** * 返回元素在集合的排名,有序集合是按照元素的score值由小到大排列 * * @param key * @param value * @return 0表示第一位 */ public Long zRank(String key, Object value) { return stringRedisTemplate.opsForZSet().rank(key, value); } /** * 返回元素在集合的排名,按元素的score值由大到小排列 * * @param key * @param value * @return */ public Long zReverseRank(String key, Object value) { return stringRedisTemplate.opsForZSet().reverseRank(key, value); } /** * 获取集合的元素, 从小到大排序 * * @param key * @param start 开始位置 * @param end 结束位置, -1查询所有 * @return */ public Set<String> zRange(String key, long start, long end) { return stringRedisTemplate.opsForZSet().range(key, start, end); } /** * 获取zset集合的所有元素, 从小到大排序 */ public Set<String> zRangeAll(String key) { return zRange(key, 0, -1); } /** * 获取集合元素, 并且把score值也获取 * * @param key * @param start * @param end * @return */ public Set<TypedTuple<String>> zRangeWithScores(String key, long start, long end) { return stringRedisTemplate.opsForZSet().rangeWithScores(key, start, end); } /** * 根据Score值查询集合元素 * * @param key * @param min 最小值 * @param max 最大值 * @return */ public Set<String> zRangeByScore(String key, double min, double max) { return stringRedisTemplate.opsForZSet().rangeByScore(key, min, max); } /** * 根据Score值查询集合元素, 从小到大排序 * * @param key * @param min 最小值 * @param max 最大值 * @return */ public Set<TypedTuple<String>> zRangeByScoreWithScores(String key, double min, double max) { return stringRedisTemplate.opsForZSet().rangeByScoreWithScores(key, min, max); } /** * @param key * @param min * @param max * @param start * @param end * @return */ public Set<TypedTuple<String>> zRangeByScoreWithScores(String key, double min, double max, long start, long end) { return stringRedisTemplate.opsForZSet().rangeByScoreWithScores(key, min, max, start, end); } /** * 获取集合的元素, 从大到小排序 * * @param key * @param start * @param end * @return */ public Set<String> zReverseRange(String key, long start, long end) { return stringRedisTemplate.opsForZSet().reverseRange(key, start, end); } public Set<String> zReverseRangeByScore(String key, long min, long max) { return stringRedisTemplate.opsForZSet().reverseRangeByScore(key, min, max); } /** * 获取集合的元素, 从大到小排序, 并返回score值 * * @param key * @param start * @param end * @return */ public Set<TypedTuple<String>> zReverseRangeWithScores(String key, long start, long end) { return stringRedisTemplate.opsForZSet().reverseRangeWithScores(key, start, end); } /** * 根据Score值查询集合元素, 从大到小排序 * * @param key * @param min * @param max * @return */ public Set<String> zReverseRangeByScore(String key, double min, double max) { return stringRedisTemplate.opsForZSet().reverseRangeByScore(key, min, max); } /** * 根据Score值查询集合元素, 从大到小排序 * * @param key * @param min * @param max * @return */ public Set<TypedTuple<String>> zReverseRangeByScoreWithScores( String key, double min, double max) { return stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, min, max); } /** * @param key * @param min * @param max * @param start * @param end * @return */ public Set<String> zReverseRangeByScore(String key, double min, double max, long start, long end) { return stringRedisTemplate.opsForZSet().reverseRangeByScore(key, min, max, start, end); } /** * 根据score值获取集合元素数量 * * @param key * @param min * @param max * @return */ public Long zCount(String key, double min, double max) { return stringRedisTemplate.opsForZSet().count(key, min, max); } /** * 获取集合大小 * * @param key * @return */ public Long zSize(String key) { return stringRedisTemplate.opsForZSet().size(key); } /** * 获取集合大小 * * @param key * @return */ public Long zZCard(String key) { return stringRedisTemplate.opsForZSet().zCard(key); } /** * 获取集合中value元素的score值 * * @param key * @param value * @return */ public Double zScore(String key, Object value) { return stringRedisTemplate.opsForZSet().score(key, value); } /** * 移除指定索引位置的成员 * * @param key * @param start * @param end * @return */ public Long zRemoveRange(String key, long start, long end) { return stringRedisTemplate.opsForZSet().removeRange(key, start, end); } /** * 根据指定的score值的范围来移除成员 * * @param key * @param min * @param max * @return */ public Long zRemoveRangeByScore(String key, double min, double max) { return stringRedisTemplate.opsForZSet().removeRangeByScore(key, min, max); } /** * 获取key和otherKey的并集并存储在destKey中 * * @param key * @param otherKey * @param destKey * @return */ public Long zUnionAndStore(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForZSet().unionAndStore(key, otherKey, destKey); } /** * @param key * @param otherKeys * @param destKey * @return */ public Long zUnionAndStore(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForZSet() .unionAndStore(key, otherKeys, destKey); } /** * 交集 * * @param key * @param otherKey * @param destKey * @return */ public Long zIntersectAndStore(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForZSet().intersectAndStore(key, otherKey, destKey); } /** * 交集 * * @param key * @param otherKeys * @param destKey * @return */ public Long zIntersectAndStore(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForZSet().intersectAndStore(key, otherKeys, destKey); } /** * @param key * @param options * @return */ public Cursor<TypedTuple<String>> zScan(String key, ScanOptions options) { return stringRedisTemplate.opsForZSet().scan(key, options); } /** * 扫描主键,建议使用 * * @param patten * @return */ public Set<String> scan(String patten) { Set<String> keys = stringRedisTemplate.execute((RedisCallback<Set<String>>) connection -> { Set<String> result = new HashSet<>(); try (Cursor<byte[]> cursor = connection.scan(new ScanOptions.ScanOptionsBuilder() .match(patten).count(10000).build())) { while (cursor.hasNext()) { result.add(new String(cursor.next())); } } catch (IOException e) { e.printStackTrace(); } return result; }); return keys; } /** * 管道技术,提高性能 * * @param type * @param values * @return */ public List<Object> lRightPushPipeline(String type, Collection<String> values) { List<Object> results = stringRedisTemplate.executePipelined(new RedisCallback<Object>() { public Object doInRedis(RedisConnection connection) throws DataAccessException { StringRedisConnection stringRedisConn = (StringRedisConnection) connection; //集合转换数组 String[] strings = values.toArray(new String[values.size()]); //直接批量发送 stringRedisConn.rPush(type, strings); return null; } }); return results; } public List<Object> refreshWithPipeline(String future_key, String topic_key, Collection<String> values) { List<Object> objects = stringRedisTemplate.executePipelined(new RedisCallback<Object>() { @Nullable @Override public Object doInRedis(RedisConnection redisConnection) throws DataAccessException { StringRedisConnection stringRedisConnection = (StringRedisConnection) redisConnection; String[] strings = values.toArray(new String[values.size()]); stringRedisConnection.rPush(topic_key, strings); stringRedisConnection.zRem(future_key, strings); return null; } }); return objects; } //分布式锁 public String tryLock(String name, long expire) { name = name + "_lock"; String token = UUID.randomUUID().toString(); Boolean locked = stringRedisTemplate.opsForValue().setIfAbsent(name, token, expire, TimeUnit.MILLISECONDS); if (locked == null) { return null; } return locked ? token : null; } }
5.Spring定时器
Spring中的定时器可以帮助我们定时执行1些周期性任务;
5.1.程序入口
package com.zhanggen.schedule; import org.mybatis.spring.annotation.MapperScan; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.scheduling.annotation.EnableScheduling; @SpringBootApplication @MapperScan("com.zhanggen.schedule.mapper") //开启定时任务注解 @EnableScheduling public class ScheduleApplication { public static void main(String[] args) { SpringApplication.run(ScheduleApplication.class,args); } }
5.2.定时器
//使用PipLine管道技术从Resis的FUTURE队列定时刷新超时任务信息至TOPIC队列 @Override //秒、分钟、小时、天、月 //@Scheduled(cron ="5/15 * * * * ?"):从第5秒开始,每个15秒执行1次 @Scheduled(fixedRate = 1000 * 60 * 5) //间隔1秒执行1次 public void refresh() { log.warn("正在从FUTURE队列中转移超时任务到TOPIC队列中"); //加上分布式锁 String lockToken = cacheService.tryLock("reflsh_lock", 5000); if (StringUtils.isEmpty(lockToken)) { return; } //间隔5分钟,从未来队列中获取超时任务(超时时间大于当前时间) Set<String> timeOutTasks = cacheService.zRange("FUTURE", 0, System.currentTimeMillis()); if (CollectionUtils.isEmpty(timeOutTasks)) { log.warn("未来队列中没有可以转移的任务"); return; } cacheService.refreshWithPipeline("FUTURE", "TOPIC", timeOutTasks); }
6.ProtostuffUtil
基于protobuff改造的protostuff,它拥有良好性能的同时,又免去了生成描述文件的烦恼;
快速序列化和反序列化对象;
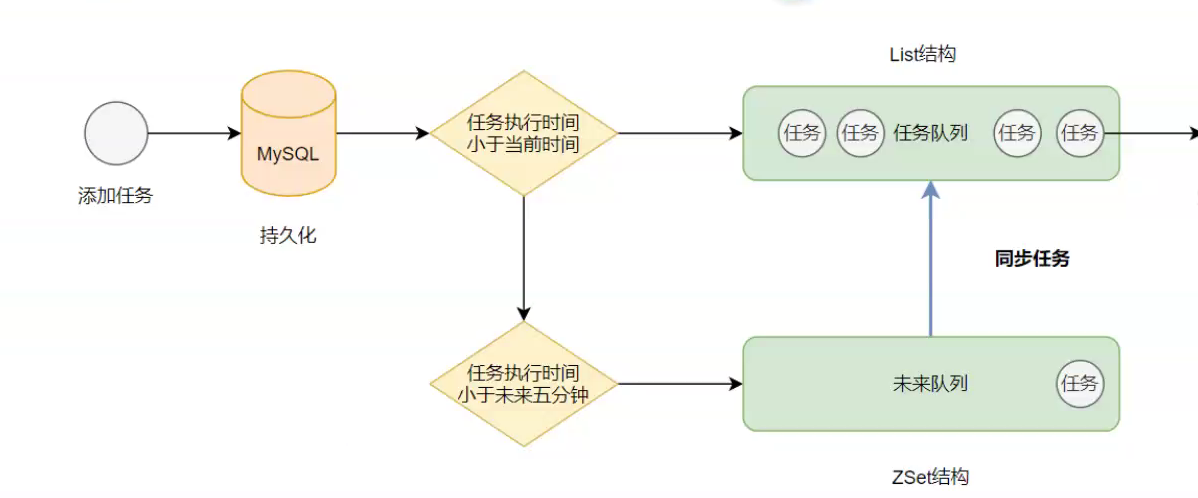
1.延迟任务队列加入之前逻辑
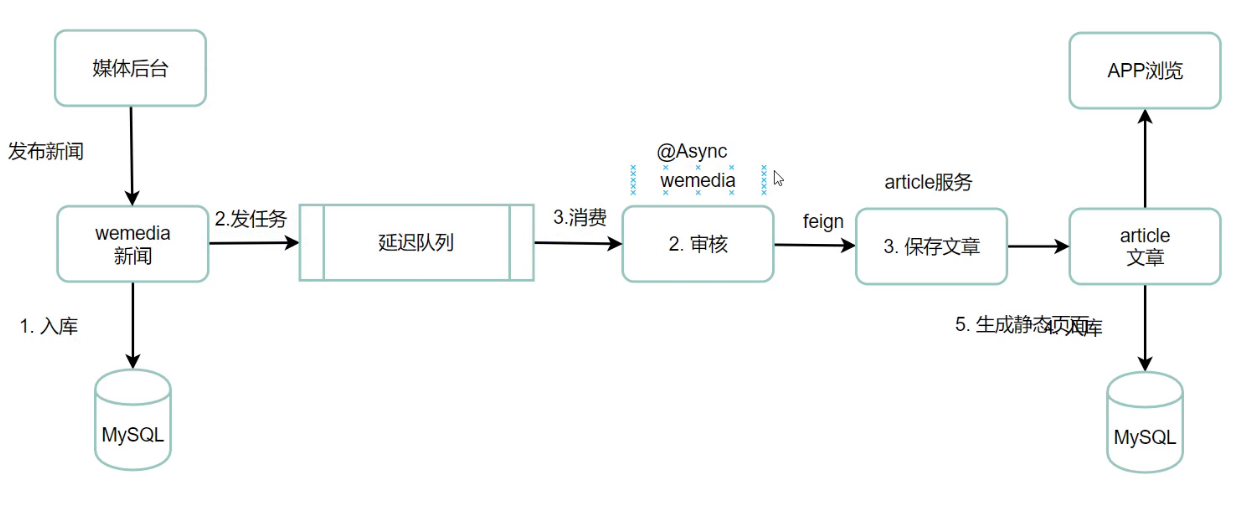
自媒体微服务用于发布新闻,
新闻发布之后通过feign调用AutoScan进行文章审核
AutoScan调用文章微服务的saveArticle接口进行文章的保存
saveArticle接口调用MinIoTemplate把文章内容上传到Minio服务器
2.延迟任务队列加入之后逻辑
新增schedul微服务
在自媒体微服务的新闻发布接口进行延迟任务添加
在自媒体微服务新增Scheduled定时任务消费者,定时从Redis中获取任务进行消费
Scheduled定时任务消费者,再调用AutoScan进行内容审核
---------------------------------------------------------------------------------------
AutoScan调用文章微服务的saveArticle接口进行文章的保存
saveArticle接口调用MinIoTemplate把文章内容上传到Minio服务器
//自媒体新闻发布接口 @Override @Transactional(rollbackFor = RuntimeException.class) public ResponseResult submit(WmNewsDto wmNewsDto) { /* wm_news(新闻表)和wm_material(素材表)两张表是多对多关系 通过wm_news_wm_material关系表相连 */ // 1. 从入参中,提取新闻表需要的内容,保存到wmNews对象 WmNews wmNews = wmNewsDto2WmNews(wmNewsDto); if (wmNews == null) { return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_REQUIRE); } // 2. 把wmNews对象写入新闻表 int insertResult = wmNewsMapper.insert(wmNews); if (insertResult < 1) { return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR); } // 3. 判断是不是草稿(是草稿->返回) Short status = wmNewsDto.getStatus(); if (status == 0) { return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS); } // 4. 提取新闻内容中所有图片素材的URL //遍历一条一条的添加wm_material(素材表)和wm_news_wm_material关系表 String content = wmNewsDto.getContent(); List<String> contentImages = getContentImages(content); // 5.从所有图片素材的URL中提取到封面图-- // 如果是自动布局,要到内容图中,去提取图片作为封面图 // 如果type=0,无图布局 // 如果type=1,单图布局 // 如果type=3,多图 // 如果type=-1,自动 List<String> images = wmNewsDto.getImages(); Short type = wmNewsDto.getType(); List<String> coverImages = getCoverImages(type, images, contentImages); // 6. 素材表和新闻表的关系表添加记录,wm_news_material关系表中type=0代表是内容图片 Boolean contentImageResult = addMaterial(wmNews.getId(), contentImages, 0); if (!contentImageResult) { throw new RuntimeException("内容图添加失败"); } // 7. 素材表和新闻表的关系表添加记录,wm_news_material关系表中type=1代表是封面图片 Boolean coverImageResult = addMaterial(wmNews.getId(), coverImages, 1); if (!coverImageResult) { throw new RuntimeException("封面图添加失败"); } //8.新闻发布成功之后,调用审核代码进行新闻内容审核,转换成文章 // try { // autoScanService.autoScanWmNews(wmNews.getId().longValue()); // } catch (Exception e) { // log.warn("----------新闻内容审核失败--------"); // e.printStackTrace(); // } //8.往延时队列中发送1个任务,标明这个任务的执行时间 Boolean isAddTask = addNewsToTask(wmNews.getId(), wmNews.getPublishTime().getTime()); if (!isAddTask) { throw new RuntimeException("自媒体微服务远程调用schedule微服务添加任务失败"); } return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS); } //发布新闻任务到Redis public Boolean addNewsToTask(Integer newsId, Long executeTime) { log.info("添加任务到延迟服务中----begin"); Task task = new Task(); task.setExecuteTime(executeTime); WmNews wmNews = new WmNews(); wmNews.setId(newsId); task.setParameters(ProtostuffUtil.serialize(wmNews)); ResponseResult responseResult = scheduleClien.addTask(task); if (responseResult != null && responseResult.getCode() == 200) { log.info("添加任务到延迟服务中成功----end"); return true; } log.info("添加任务到延迟服务中失败----end"); return false; }
从延迟队列中消费任务,再次调用autoScanWmNews进行内容审核;
//发布任务到Redis的接口在WmNessService,从Redis队列中获取任务进行消费,调用autoScanWmNews进行内容审核; @Scheduled(fixedRate = 1000) public void getTask() { ResponseResult pollResult = scheduleClient.poll(); //从Redis队列获取任务进行消费失败 if (pollResult == null || pollResult.getCode() != 200) { log.warn("从Redis队列获取任务进行消费失败"); return; } String data = (String) pollResult.getData(); if (StringUtils.isEmpty(data)) { log.warn("从Redis队列中没有可以消费的任务"); return; } Task task = JSON.parseObject(data, Task.class); if(task==null){ log.warn("消费任务时序列化失败"); } byte[] parameters = task.getParameters(); WmNews wmNews= ProtostuffUtil.deserialize(parameters,WmNews.class); if(wmNews==null){ log.warn("参数缺失"); return; } try { autoScanWmNews(wmNews.getId().longValue()); } catch (Exception e) { log.warn("Redis队列中获取Task调用autoScanWmNews进行新闻内容扫描失败"); e.printStackTrace(); } }
九、文章上/下架
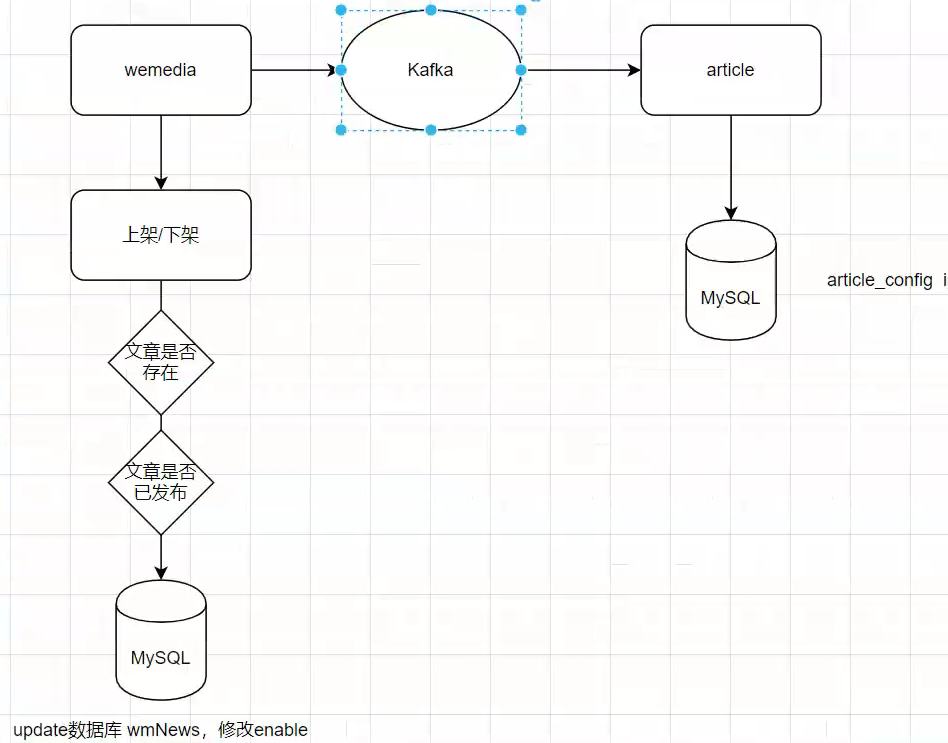
参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号