
前言
收集大量的日志信息之后,把这些日志存放在哪里?才能对其日志内容进行搜素呢?MySQL?

1.MySQL海量数据下全文检索效率低
如果MySQL里存储了1000W条这样的数据,每条记录的details字段有128个字。
用户想要查询details字段包含“ajax”这个关键词的记录。
select * from tb_log where log_details like "%ajax%";
使用like模糊查询且左边有通配符,会导致索引失效;
每次执行这条SQL语句,都需要逐一查询logtable中每条记录,最头痛的是找到这条记录之后,每次还要对这条记录中details字段里的文本内容进行全文扫描。
判断这个当前记录中的details字段是的内容否包含 “ajax”?有可能会查询 10000w*128次.
所以想要支持搜素details字段的Text内容的情况下,把海量的日志信息存在MySQL中是不太合理的。
2.MySQL无法实现分词查询功能
如果用户不明确搜索目的,虽然在电商平台上搜索了1个关键词 ‘平板电视’,但也想看看平板电脑、液晶电视等商品;
select * from tb_good where good_name like "%平板电视%";
以上SQL语句只能查询到商品名称包含“平板电视“4个字连在一起的平板电视商品;
无法按照自然语言习对关键词进行分词处理,导致用户无法获得丰富的查询结果,例如:把商品名称包含“电视“和“平板”的商品也查询出来;
ES不是银弹只做搜索功能,否则搭建ES维护起来也复杂;
一、Elasticsearch简介
Elasticsearch是一个开源的高扩展的分布式全文检索引擎;
Elasticsearch是一个基于Lucene的分布式、高性能、可伸缩的搜素和分析系统,它对外提供了RESTful web API。
-
Mysql数据操作具备事务性,而ElasticSearch没有
-
MySQL支持外键,而ElasticSearch不支持
-
1.倒排索引
ElasticSearch之所以支持全文检索,1大核心原因是ES在存储数据的时候可以对数据进行分词并构建倒排索引,这是一种典型的空间换时间思想;
倒排索引是1种用于全文搜索的数据结构
倒排索引不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
倒排索引将文档中的每1个单词映射到包含该单词的所有文档的列表中
倒排索引在文本搜索和信息检索中广泛应用,如搜索引擎、网站搜索、文本分类等场景中。

2.全文检索
全文检索:把用户输入的关键词也进行分词,利用倒排索引,快速锁定关键词出现在那些文档。
说白了就是根据value查询key(根据文档中内容关键字,找到该该关键字所在的文档的)而非根据key查询value。
3.Lucene
Lucene是apache软件基金会4 jakarta项目组的一个java子项目,是一个开放源代码的全文检索引擎JAR包。帮助我我们实现了以上的需求。
lucene实现倒排索引之后,那么海量的数据如何分布式存储?如何高可用?集群节点之间如何管理?这是Elasticsearch实现的功能。
常说的ELK是Elasticsearch(全文搜素)+Logstash(内容收集)+Kibana(内容展示)三大开源框架首字母大写简称。
4.分片
分片是Elasticsearch中数据存储的基本单位。
Elasticsearch是1个分布式搜索引擎,它允许将1个索引分解成多个部分,每个部分都存储在不同的节点上。
这种分布式的存储方式使得Elasticsearch能够处理大量的数据,同时保持高效的查询性能。
1个分片默认可以存储最大约20亿个文档
索引的分片完成分配后,由于索引的路由机制,将不能重新修改分片数量。
5.分片副本
副本是对分片的复制,用于提供高可用性和故障恢复能力。
每个主分片都可以有1个或多个副本分片。
如果主分片所在的节点发生故障,副本分片可以用于提供服务,从而确保数据的高可靠性。
副本还允许查询请求在多个节点上并行处理,从而提高查询性能。
默认情况下,Elasticsearch为每个索引创建5个主分片,并为每个主分片创建1个副本分片。
6.分片和分片副本总结
分片和副本在Elasticsearch中扮演着不同的角色:
- 分片负责数据的分布存储
- 副本则负责数据的复制以提供高可用性和查询性能
用户可以根据自己的需求调整分片和副本的数量,以优化存储和查询性能。
7.ES底层写入流程

二、Elasticsearch安装
注意ES的版本要和客户端的依赖包版本保存一致;
docker pull elasticsearch:7.10.1
mkdir -p /mydata/elasticsearch/{config,data,plugins}
echo "http.host: 0.0.0.0" > /mydata/elasticsearch/config/elasticsearch.yml
chmod -R 775 /mydata/elasticsearch/
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms256m -Xmx1024m" \ -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d elasticsearch:7.10.1

docker pull kibana:7.10.1
[root@itcast ~]# mkdir -p /mydata/kibana/config [root@itcast ~]# cd /mydata/kibana/config [root@itcast config]# touch kibana.yml [root@itcast config]#
## ** THIS IS AN AUTO-GENERATED FILE ** ## Default Kibana configuration for docker target ##根据自己实际IP修改elasticsearch地址 server.name: kibana server.host: "0" elasticsearch.hosts: [ "http://192.168.56.18:9200" ] xpack.monitoring.ui.container.elasticsearch.enabled: true #开启中文配置 i18n.locale: "zh-CN"
docker run -d \ > --name=kibana \ > --restart=always \ > -p 5601:5601 \ > -v /mydata/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \ > kibana:7.10.1

3.安装DockerPortainer
Docker容器在修改完配置之后很容易出现故障导致启动失败;
此时就需要1个图形化的管理工具,对容器进行可视化操作,也方便查看日志,快速定位问题所在;
3.1.下载portainer镜像
docker pull portainer/portainer
3.2.启动portainer容器
portainer也是1个容器但是这个容器是用来管理其他容器的;
docker pull portainer/portainer 2.2 启动portainer #创建文件存储文件 docker volume create portainer_data #创建并启动容器 --restart=always 开机自动启动` docker run -d -p 9000:9000 --name=portainer --restart=always
-v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer
3.3.管理容器
最后确保以下3个容器都已经正常运行;

三、Elasticsearch使用
ES在使用时,会涉及到5个核心概念:
- 索引(Index)
- 映射(Mapping)
- 域(Field)
- 文档(Document)
- 倒排索引
在老版本ElasticSearch中还有1个概念Type,用于进行数据分类,但是在ES7开始已经将Type移除;
| Mysql | |
|---|---|
| 索引(Index) | 表(Table) |
| 映射(Mapping) | 表结构 |
| 域(Field) | 字段列(Column) |
| 文档(Document) |
1.
#先创建索引
PUT student
#再补充索引中的映射
PUT student/_mapping
{
"properties":{
"username":{
"type":"text"
},
"age":{"type":"integer"},
"birthday":{"type":"date","format":"yyyy-MM-dd" }
}
}
添加索引并指定映射
PUT student
{
"mappings":{
"properties":{
"username":{"type":"text"},
"age":{"type":"integer"},
"birthday":{"type":"date","format":"yyyy-MM-dd" }
}
}
}
1.2.
GET person
1.3.查询多个索引
PUT person1
GET person,person1
1.4. 查询所有索引信息
GET _all
DELETE person1
2.别名机制
由于倒排索引的缘故,在ES中无法删除字段,也无法修改字段类型;
所有我们一般对外暴露index(索引)的别名,而不是真正的索引名称;

如果在创建索引的时候或者在映射中新增字段,指定了错误的映射,有2种解决方案;
2.1.索引没有投入使用
如果索引中没有导入数据,删除索引再重新指定映射;
2.2.索引已经投入使用
- 新创建1个正确的索引
- 把之前错误索引中数据导入到新建正确索引中
- 使用别名指向新的正确索引;
#模拟错误:新增了1个student1索引
PUT student1
PUT student1/_mapping
{
"properties":{
"birtday":{"type":"text"}
}
}
#创建别名student--》student1
POST _aliases
{
"actions": [
{
"add": {
"index": "student1",
"alias": "student"
}
}
]
}
#发现指定错了映射,birtday字段应该为date类型
GET student1
#开始修改,新增1个索引指定正确的映射student2,设置birtday字段为date类型
PUT student2
PUT student2/_mapping
{
"properties":{
"birthday":{"type":"date","format":"yyyy-MM-dd" }
}
}
#删除之前指定的别名 student--》student1
POST _aliases
{
"actions": [
{
"remove": {
"index": "student1",
"alias": "student"
}
}
]
}
#创建新的别名student--》student2
POST _aliases
{
"actions": [
{
"add": {
"index": "student2",
"alias": "student"
}
}
]
}
#查看新增的索引student2确定索引也是正确的
GET student2
#删除student1
DELETE student1;
使用Java程序把之前的数据填充到student2索引中
3.1.字符串
-
text:会进行分词,如华为手机,会分成:华为,手机。 被分出来的每一个词,称为term(词条)
-
keyword:不会进行分词,如华为手机,只有一个词条,即华为手机。
3.2.数值
-
long:带符号64位整数
-
integer:带符号32位整数
-
short:带符号16位整数
-
byte:带符号8位整数
-
double:双精度64位浮点数
-
float:单精度32位浮点数
-
half_float:半精度16位浮点数
3.3.布尔:
-
boolean
3.4.二进制:
-
binary
3.5.日期:
-
date
3.6.范围类型:
-
integer_range
-
float_range
-
long_range
-
double_range
-
date_range
3.7.数组
POST person/_doc/1
{
"name":"张三",
"age":18,
"address":"北京"
}
POST person/_doc
{
"name":"李四",
"age":20,
"address":"北京"
}
GET person/_doc/1
GET person/_search
查询条件
GET logstash-2022.12.12/_search { "_source": { "includes":["@timestamp","message","stream"] }, "sort": [ { "@timestamp": { "order": "desc" } } ], "from": 1, "size": 3 }
4.3.修改文档
PUT person/_doc/1
{
"name": "张三丰",
"age": 180,
"address": "武当山"
}
DELETE person/_doc/1
四、SpringBoot操作ElasticSearch
使用restHighLevelClient操作ES的流程如下:
1.构建查询请求




<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency> <!--引入es的坐标--> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.10.1</version> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-client</artifactId> <version>7.10.1</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>7.10.1</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <scope>test</scope> </dependency> </dependencies>
1.2.application.yml
elasticsearch:
host: 192.168.56.18
port: 9200
1.3.创建启动类EsApplication
package com.zhanggen.es.demo; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class EsApplication { public static void main(String[] args) { SpringApplication.run(EsApplication.class,args); } }
1.4.创建es配置类
package com.zhanggen.es.demo.config; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestClientBuilder; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration @ConfigurationProperties(prefix="elasticsearch") public class ElasticSearchConfig { private String host; private int port; public String getHost() { return host; } public void setHost(String host) { this.host = host; } public int getPort() { return port; } public void setPort(int port) { this.port = port; } @Bean public RestHighLevelClient restHighLevelClient(){ RestClientBuilder builder = RestClient.builder(new HttpHost(host, port, "http")); builder.setRequestConfigCallback(requestConfigBuilder ->{ requestConfigBuilder.setConnectionRequestTimeout(500000); requestConfigBuilder.setSocketTimeout(500000); requestConfigBuilder.setConnectTimeout(500000); return requestConfigBuilder; }); return new RestHighLevelClient(builder); } }
1.5.创建测试类ESTest
package com.zhanggen.es.demo; import org.elasticsearch.client.RestHighLevelClient; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; @SpringBootTest @RunWith(SpringRunner.class) public class ESTest { @Autowired private RestHighLevelClient restHighLevelClient; }
2.操作索引
对ES中索引的增、删、查操作
package com.itheima.es.demo; import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest; import org.elasticsearch.action.support.master.AcknowledgedResponse; import org.elasticsearch.client.IndicesClient; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.client.indices.CreateIndexRequest; import org.elasticsearch.client.indices.CreateIndexResponse; import org.elasticsearch.client.indices.GetIndexRequest; import org.elasticsearch.client.indices.GetIndexResponse; import org.elasticsearch.cluster.metadata.MappingMetadata; import org.elasticsearch.common.xcontent.XContentType; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import java.io.IOException; import java.util.Map; @SpringBootTest @RunWith(SpringRunner.class) public class ESTest { //注入操作ElasticSearch的客户端 @Autowired private RestHighLevelClient restHighLevelClient; //测试创建索引 @Test public void createIndexTest() throws IOException { IndicesClient indicesClient = restHighLevelClient.indices(); //设置索引名称 CreateIndexRequest createIndexRequest=new CreateIndexRequest("student"); //定义索引的映射(结构) String mappingInfo = "{\n" + " \"properties\":{\n" + " \"name\":{\n" + " \"type\":\"keyword\"\n" + " },\n" + " \"age\":{\n" + " \"type\":\"integer\"\n" + " },\n" + " \"address\":{\n" + " \"type\":\"text\"\n" + " }\n" + " }\n" + "}"; createIndexRequest.mapping(mappingInfo, XContentType.JSON); CreateIndexResponse response = indicesClient.create(createIndexRequest, RequestOptions.DEFAULT); System.out.println(response.isAcknowledged()); } //测试查询索引 @Test public void findIndexTest() throws IOException { IndicesClient indicesClient = restHighLevelClient.indices(); GetIndexRequest getIndexRequest = new GetIndexRequest("student"); GetIndexResponse response = indicesClient.get(getIndexRequest, RequestOptions.DEFAULT); Map<String, MappingMetadata> mappings = response.getMappings(); for (String key : mappings.keySet()) { System.out.println(key+"==="+mappings.get(key).getSourceAsMap()); } } //删除索引 @Test public void delIndex() throws IOException { IndicesClient indicesClient = restHighLevelClient.indices(); DeleteIndexRequest delIndexRequest = new DeleteIndexRequest("student"); AcknowledgedResponse response = indicesClient.delete(delIndexRequest, RequestOptions.DEFAULT); System.out.println(response.isAcknowledged()); } }
3.操作文档
package com.itheima.es.demo; import com.alibaba.fastjson.JSON; import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest; import org.elasticsearch.action.delete.DeleteRequest; import org.elasticsearch.action.delete.DeleteResponse; import org.elasticsearch.action.get.GetRequest; import org.elasticsearch.action.get.GetResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.support.master.AcknowledgedResponse; import org.elasticsearch.client.IndicesClient; import org.elasticsearch.client.Request; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.client.indices.CreateIndexRequest; import org.elasticsearch.client.indices.CreateIndexResponse; import org.elasticsearch.client.indices.GetIndexRequest; import org.elasticsearch.client.indices.GetIndexResponse; import org.elasticsearch.cluster.metadata.MappingMetadata; import org.elasticsearch.common.xcontent.XContentType; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import java.io.IOException; import java.util.HashMap; import java.util.Map; @SpringBootTest @RunWith(SpringRunner.class) public class ESTestDocument { //注入操作ElasticSearch的客户端 @Autowired private RestHighLevelClient restHighLevelClient; //测试在student索引中创建1个文档 @Test public void addDoc() throws IOException { IndexRequest indexRequest = new IndexRequest("student").id("1"); indexRequest.source("{\n" + " \"name\":\"张根\",\n" + " \"age\":18,\n" + " \"address\":\"河北\"\n" + "}", XContentType.JSON); IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT); System.out.println(response.status()); } //测试在student索引中创建1个文档2 @Test public void addDoc1() throws IOException { IndexRequest indexRequest = new IndexRequest("student").id("1"); //本质上就是在请求体包含1个json数据 HashMap<String, Object> map = new HashMap<>(); map.put("name","张根"); map.put("age",18); map.put("address","河北"); indexRequest.source(JSON.toJSONString(map),XContentType.JSON); IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT); System.out.println(response.status()); } //测试查询文档 @Test public void findDocTest() throws IOException { GetRequest getRequest = new GetRequest("student","1"); GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT); String str = response.getSourceAsString(); Map<String, Object> map = response.getSourceAsMap(); System.out.println(map); } //测试删除文档 @Test public void delDocTest() throws IOException { DeleteRequest deleteRequest = new DeleteRequest("student", "1"); DeleteResponse response = restHighLevelClient.delete(deleteRequest,RequestOptions.DEFAULT); System.out.println(response.status()); } }
4.从MySQL中批量导入数据到ES
package com.zhanggen.es.service.impl; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.serializer.SerializerFeature; import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper; import com.baomidou.mybatisplus.extension.plugins.pagination.Page; import com.itheima.es.entity.HotelEntity; import com.itheima.es.mapper.HotelMapper; import com.itheima.es.service.HotelService; import org.apache.lucene.search.TotalHits; import org.elasticsearch.action.bulk.BulkRequest; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentType; import org.elasticsearch.index.query.QueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import java.io.IOException; import java.util.*; @Service public class HotelServiceImpl implements HotelService { @Autowired private HotelMapper hotelMapper; @Autowired private RestHighLevelClient restHighLevelClient; //批量导入 @Override public int addDocToES() { int esTotal = 0; Long currentPage = 1L; Page<HotelEntity> page = new Page<>(currentPage, 200); LambdaQueryWrapper<HotelEntity> queryWrapper = new LambdaQueryWrapper<>(); Integer integer = hotelMapper.selectCount(queryWrapper); Page<HotelEntity> hotelEntityPage = hotelMapper.selectPage(page, queryWrapper); //先算出数据库中一共有多少页 long totalpage = hotelEntityPage.getPages(); for (currentPage = 1L; currentPage <= totalpage; currentPage++) { //批量导入 queryWrapper = new LambdaQueryWrapper<>(); hotelEntityPage = hotelMapper.selectPage(page.setCurrent(currentPage), queryWrapper); //ES批量导入的API:请求集合 BulkRequest bulkRequest = new BulkRequest(); for (HotelEntity hotelEntity : hotelEntityPage.getRecords()) { String data = JSON.toJSONStringWithDateFormat(hotelEntity, "yyyy-MM-dd", SerializerFeature.WriteDateUseDateFormat); IndexRequest indexRequest = new IndexRequest("hotel").source(data, XContentType.JSON); bulkRequest.add(indexRequest); } try { BulkResponse response = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); } catch (IOException e) { e.printStackTrace(); } esTotal += hotelEntityPage.getRecords().size(); } return esTotal; } //查询全部 @Override public Map<String, Object> matchAllQuery() { //1.构建查询 SearchRequest hotelSearch = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); QueryBuilder queryBuilder = QueryBuilders.matchAllQuery(); searchSourceBuilder.query(queryBuilder); hotelSearch.source(searchSourceBuilder); //返回的结果 Map<String, Object> map = new HashMap<>(); try { SearchResponse searchResponse = restHighLevelClient.search(hotelSearch, RequestOptions.DEFAULT); SearchHits searchResponseHits = searchResponse.getHits(); //总条目 long totalHits = searchResponseHits.getTotalHits().value; List<HotelEntity> list = new ArrayList<>(); SearchHit[] searchHits = searchResponseHits.getHits(); if (searchHits != null || searchHits.length > 0) { for (SearchHit searchHit : searchHits) { String sourceAsString = searchHit.getSourceAsString(); list.add(JSON.parseObject(sourceAsString, HotelEntity.class)); } } map.put("list", list); map.put("totalResultSize", totalHits); } catch (IOException e) { e.printStackTrace(); } return map; } //分页查询 @Override public Map<String, Object> pageQuery(int current, int size) { SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); QueryBuilder queryBuilder = QueryBuilders.matchAllQuery(); searchSourceBuilder.query(queryBuilder); //设置分页 searchSourceBuilder.from((current - 1) * size); searchSourceBuilder.size(size); searchRequest.source(searchSourceBuilder); Map<String, Object> resultMap = new HashMap<>(); try { SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); SearchHits hits = searchResponse.getHits(); long totalHits = hits.getTotalHits().value; SearchHit[] searchHits = hits.getHits(); List<HotelEntity> list = new ArrayList<>(); for (SearchHit searchHit : searchHits) { String sourceAsString = searchHit.getSourceAsString(); list.add(JSON.parseObject(sourceAsString, HotelEntity.class)); } resultMap.put("list", list); resultMap.put("totalResultSize", totalHits); resultMap.put("current", current); //设置总页数 resultMap.put("totalPage", (totalHits + size - 1) / size); } catch (IOException e) { e.printStackTrace(); } return resultMap; }
5.迁移失败
如果数据前移失败,多半是ES设置的映射有问题,可以从responses中打印出错信息;
package com.hmall.search.feign; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.serializer.SerializerFeature; import com.hmall.client.ItemClient; import com.hmall.common.dto.Item; import com.hmall.common.dto.PageDTO; import com.hmall.search.domain.ItemDoc; import org.elasticsearch.action.bulk.BulkItemResponse; import org.elasticsearch.action.bulk.BulkRequest; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentType; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.BeanUtils; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import java.io.IOException; @RunWith(SpringRunner.class) @SpringBootTest public class FeignTest { @Autowired private RestHighLevelClient restHighLevelClient; @Autowired private ItemClient itemClient; @Test public void testFindItem() { //1次插入多少条 Integer size = 1000; PageDTO<Item> itemPageDTO = itemClient.queryItemByPage(1, 0); Long total = itemPageDTO.getTotal(); Long totalPage = total % size == 0 ? total / size : total / size + 1; for (Long currentPage = 1L; currentPage <= totalPage; currentPage++) { System.out.println("第" + currentPage + "页"); itemPageDTO = itemClient.queryItemByPage(currentPage.intValue(), size); //批量导入 //ES批量导入的API:请求集合 BulkRequest bulkRequest = new BulkRequest(); for (Item item : itemPageDTO.getList()) { ItemDoc itemDoc = new ItemDoc(); BeanUtils.copyProperties(item, itemDoc); String data = JSON.toJSONStringWithDateFormat(itemDoc, "yyyy-MM-dd", SerializerFeature.WriteDateUseDateFormat); IndexRequest indexRequest = new IndexRequest("item").source(data, XContentType.JSON); bulkRequest.add(indexRequest); } try { BulkResponse bulkItemResponses = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); if (bulkItemResponses.hasFailures()) { BulkItemResponse[] itemResponse = bulkItemResponses.getItems(); for (BulkItemResponse response : itemResponse) { if (response.isFailed()) { System.out.println("=======" + response.getFailureMessage() + "============="); } } } } catch (IOException e) { e.printStackTrace(); } } System.out.println(itemPageDTO.getList()); } @Test public void testFindItem1() { } }
五、Go操作ElasticSearch
Go语言和Ptython都可以使用其第3方库https://github.com/olivere/elastic来连接并操作ES。
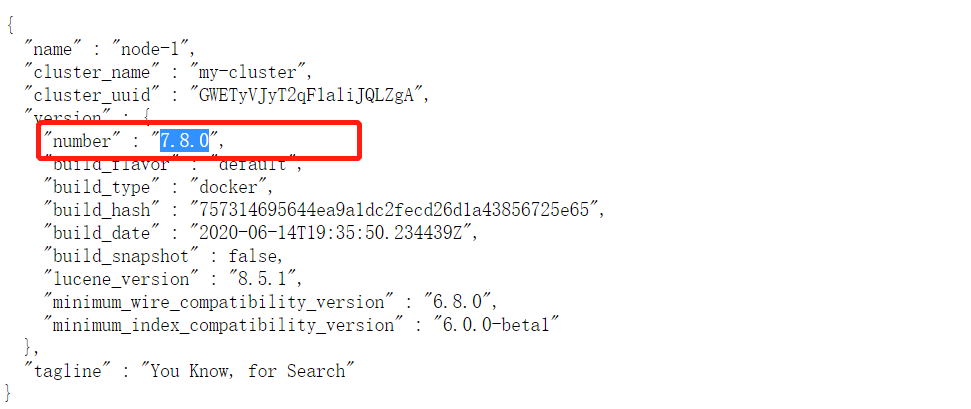
注意APICleint的版本与你的ES版本相一致
例如:我们这里使用的ES是7.8.0的版本,那么我们下载的client也要与之对应为github.com/olivere/elastic/v7。
1.引入依赖
使用go.mod来管理依赖下载指定版本的第三库:
module go相关模块/elasticsearch go 1.13 require github.com/olivere/elastic/v7 v7.0.4
2.代码
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// Elasticsearch demo
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Married bool `json:"married"`
}
func main() {
client, err := elastic.NewClient(elastic.SetURL("http://192.168.56.135:9200/"))
if err != nil {
// Handle error
panic(err)
}
fmt.Println("connect to es success")
p1 := Person{Name: "曹操", Age: 155, Married: true}
put1, err := client.Index().
Index("students").Type("go").
BodyJson(p1).
Do(context.Background())
if err != nil {
// Handle error
panic(err)
}
fmt.Printf("Indexed user %s to index %s, type %s\n", put1.Id, put1.Index, put1.Type)
}
Python
""" pip install elasticsearch==7.8.0 http://10.110.158.162:10072/ ES地址 http://10.110.158.162:10937/ Kibana地址 """ from elasticsearch import Elasticsearch clent = Elasticsearch(hosts="http://10.110.158.162:10072") query = { "_source": { "includes": ["@timestamp", "message", "stream"] }, "sort": [ { "@timestamp": { "order": "desc" } } ], "from": 1, "size": 3 } allDoc = clent.search(index="k8s-2022.12.26", body=query) for row in allDoc["hits"]["hits"]: print(row["_source"])
六、日志查询
#查询当前ES数据库中存在所有索引 GET _cat/indices #查询k8s-2022.12.26索引中定义的字段类型 GET k8s-2022.12.26/_mapping #根据ID查询1个文档 GET k8s-2022.12.26/_doc/Q3YKTYUBy4Ru3dTnzJs0 #查询k8s-2022.12.26索引中的300条日志 GET k8s-2022.12.26/_search { "query":{ "match": {"kubernetes.container_name":"nginx"} }, "sort": [ { "@timestamp": { "order": "desc" } } ], "from": 0, "size": 300 } #针对text字段match查询tag=linux-messages的日志 GET k8s-2022.12.26/_search { "query": { "match": {"tag":"linux-messages"} }, "sort": [ { "@timestamp": { "order": "desc" } } ], "from": 0, "size": 300 } #查询tag=linux-messages以及host_ip=10.110.158.162的日志,指定显示_source的部分字段 GET k8s-2022.12.26/_search { "_source": { "includes":["@timestamp","host_ip"] }, "query": { "bool":{ "must":[ {"match":{"tag":"linux-messages"}} ] }}, "from": 0, "size": 20 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号