


前言
消息队列的主要有3大作用
进程通信(IPC):Interprocess Communication
程序解耦:程序由异步变为了异步,提升程序并发(规避IO等待时间)能力。
数据流量削峰:把消息暂时缓冲在消息队列里面。
NSQ传递的消息通常是无序的,当然你也可以保留下信息去check时间戳,因此NSQ更适合处理数据量大但是彼此间没有顺序关系的消息。
消息队列2种消息传递的模式:
1.点对点模式(queue)
消息生产者生成消息发送到queue中,然后消费者从queue中主动获取数据进行消费。
当1条消息被消费之后,这条消息就会从queue中消失,不存在重复消费。
golang中的channel就是这种模型。
2.发布和订阅者(topic)
生产者生成消息时把消息分类成不同Topic,消费者通过订阅(subcrible)这些Topic,把不同的消息获出来消费。
发布和订阅模式和点对点模式最大的区别:
引入 Publish---> Topic<--->Subcrible概念,Topic把消息分类了意味着生产端可以有多个不同的生成者生成不同的消息,消费端也可有多个不同的消费者订阅不同的Topic。
这种设计模式为生产和消费2端都提供了扩展/收缩的弹性空间 。
在发布和订阅这模式中,消费者端从消息队列获取数据的方式也有2种:
2.1.队列主动推送消息到消费端(供大于求)
2.2.消费者主动去队列拉取消息 (求大于供)
kafka概念
kafka是由Linkedln公司开发的用于处理公司内部海量日志传输问题的,由Scala和Java编写。2011年该公司把它贡献给Apche软件基金会,现已发展成Apche中的顶级开源项目,kafaka是1个分布式(一提到分布式就会想到集群)的基于发布/订阅模式的消息队列(message queue),主要应用于大数据实时处理场景。
kafka具有高吞吐、低延迟、容错率高的特点。
kafka架构

从宏观角度来看kafka就是1个非常粗大管子。在这个大管子的两端有2中角色生产者(producer)和消费者(consumer)。
Broker
Kafka的分布式就体现在kafka集群中可以灵活扩展Broker(kafka集群中的1个节点,服务器)方便我们对kafka集群进行弹性扩展。broker-id不在集群里不能重复。
Topic
对消息的分类,1个topic中的消息通常分布在多个Partition
Partition
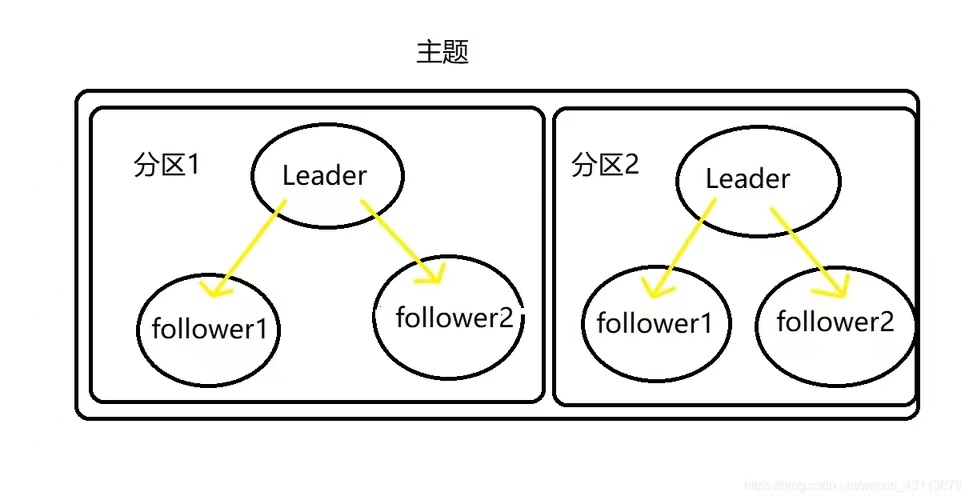
1个Topic中的消息会被取模路由到不同的Broker,分割存储为PPartition;
同1个Topic的消息数据,被分割成内容不同且数据是不重复的Partition;
同1个Partition会被N个Followers复制N份,分别存储到不同的Broker上;
Partition机制实现了Topic消息数据的容错备份、负载均衡及并行消费,Partition的表现形式就是1个个文件夹
在同1个Partition内消息是有序的,在Partition外消息是无序的。
Kafka中每生产1条消息,都会分配1个的index(offset偏移量),offset保证消息在消费时可以被顺序读取,而不是遍历随机读,
另外Kafka的DMA读写机制,也是kafka消费消息快的原因。
Follower
每个Partition都由1个Leader和多个Follower pation(副本分区)构成,Follower实现了Partition的数据备份;
当leader partition故障时kafak会选择1个follower partition成为leader partition,kafaka中主分区可以设置的最大的副本数量为10,leader和folloer partition不能在同一个服务器上,followers的数量也不能大于brokers(1个kafka集群中服务器)的数量。
Producer生产者
Producer写数据到kafka的工作流程
1.producer先从kafka集群中获取分区的leader信息
2.producer将消息发送给leader
3.leader将消息写入本地磁盘
4.follower从leader分区拉取消息数据
5.follower将消息写入本地磁盘,向leader partition发送ACK确定.
6.leader收到所有follower的ACK之后,向Producer发生ACK确定。
ps:ack应答机制保证了Producer数据写入的可靠性。
关于以上步骤细节:
producer选择Leader partition的原则?
在kafka中1个topic对应多个leader分区,producer在获取leader信息的时候是如何选择其中1个leader的呢?
1.根据producer指定leader分区来帮它存储数据。(Producer指定了partition)
2.如果producer没有指定特定的partition那么会根据producer设置的key,hash出1个值自动判断选择哪个leader partition.(Producer指定了Key)
3.如果既没有指定partition也没有指定key就采取轮询的方式写入到不同的partition(轮着来雨露均沾)
producer往kafka发送数据成功之后,ACK应答机制都也哪些?
producer在向kafka发布消息时,可以设置消息数据写入kafka成功之后是否需要ACK应答机制?有以下3个参数!
0:producer往集群中发布数据不需要等待kafka的ACK。(可靠性低,效率高!)
1:代表producer要求只需要leader进行ACK,follower从leader拉取数据的时候就别ACK了。(折中方案)
all:producer--->leader----->leader下面所有的follower数据接收成功后都需要 ACK应答。(可靠性高,效率低)
ps:如果producer往不存在的Topic中发送数据时,kafka会自动创建该Topic,partition和replication的数量默认配置都为1.
consumer group消费组
多个消费者组成1个组对同1个topc的消息进行消费(增加了kafka的消费能力)

在同1个consumer group中1个consumer可消费多个分区,但是1个分区只能被consumerGroup中1个consumer消费,保证消息不被同1个消费者重复消费;
也就是说只要N个consumer在同1 consumer group中,它们消费的数据永远是不一致的。这也是kafka的partition和NSQ的channel之间的本质区别!
安装kafka
1.下载二进制包
二进制包下载之后,根据操作系统 执行kafka和zookeeper的启动脚本即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | [root@zhanggen bin]# lsconnect-distributed.sh kafka-producer-perf-test.shconnect-mirror-maker.sh kafka-reassign-partitions.shconnect-standalone.sh kafka-replica-verification.shkafka-acls.sh kafka-run-class.shkafka-broker-api-versions.sh kafka-server-start.shkafka-configs.sh kafka-server-stop.shkafka-console-consumer.sh kafka-streams-application-reset.shkafka-console-producer.sh kafka-topics.shkafka-consumer-groups.sh kafka-verifiable-consumer.shkafka-consumer-perf-test.sh kafka-verifiable-producer.shkafka-delegation-tokens.sh trogdor.shkafka-delete-records.sh windowskafka-dump-log.sh zookeeper-security-migration.shkafka-leader-election.sh zookeeper-server-start.shkafka-log-dirs.sh zookeeper-server-stop.shkafka-mirror-maker.sh zookeeper-shell.shkafka-preferred-replica-election.sh[root@zhanggen bin]# |
2.启动zookeeper
zookeeprt是kafka集群中注册、自动发现服务,类似于NSQ中的Lookupd。kafka的二进制包包含了zookeeper无需单独下载
zookeeper配置kafka集群信息



tickTime=2000 dataDir=/home/myname/zookeeper clientPort=2181 initLimit=5 syncLimit=2 server.1=192.168.229.160:2888:3888 server.2=192.168.229.161:2888:3888 server.3=192.168.229.162:2888:3888
启动zookeeper
1 | ./bin/zookeeper-server-start.sh ./config/zookeeper.properties |
3.启动1个KafkaBroker
broker配置文件
listeners=PLAINTEXT://192.168.11.103:9092
启动
1 | ./bin/kafka-server-start.sh ./config/server.properties |
4.生产topic
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | package mainimport ( "fmt" "github.com/Shopify/sarama")func main() { config := sarama.NewConfig() config.Producer.RequiredAcks = sarama.WaitForAll //赋值为-1:这意味着producer在follower副本确认接收到数据后才算一次发送完成。 config.Producer.Partitioner = sarama.NewRandomPartitioner //写到随机分区中,默认设置8个分区 config.Producer.Return.Successes = true msg := &sarama.ProducerMessage{} msg.Topic = `CMDB_log` msg.Value = sarama.StringEncoder("this is a good test") client, err := sarama.NewSyncProducer([]string{"192.168.56.133:9092"}, config) if err != nil { fmt.Println("producer close err, ", err) return } fmt.Println("Kafka连接成功!") defer client.Close() pid, offset, err := client.SendMessage(msg) if err != nil { fmt.Println("send message failed, ", err) return } fmt.Printf("分区ID:%v, offset:%v \n", pid, offset)} |
5.验证topic对应partition
生产者生产的每1个Topic都会有对应的partition进行数据存储。
[root@zhanggen kafka-logs]# pwd
/tmp/kafka-logs
[root@zhanggen kafka-logs]# ls
cleaner-offset-checkpoint nginx_log-0 zhanggen_log-0
log-start-offset-checkpoint recovery-point-offset-checkpoint
meta.properties replication-offset-checkpoint
[root@zhanggen kafka-logs]# cd zhanggen_log-0/
[root@zhanggen zhanggen_log-0]# ls
00000000000000000000.index 00000000000000000000.timeindex
00000000000000000000.log leader-epoch-checkpoint
[root@zhanggen zhanggen_log-0]#
6.消费数据
[root@zhanggen kafka_2.12-2.5.0]# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.56.133:9092 --topic=zhanggen_log --from-beginning this is a good test this is a good test this is a good test How's it going?
7.开发go客户端消费数据
根据topic查询到所有分区,然后使用gorutine对每个分区进行消费。
package mainimport ( "fmt" "github.com/Shopify/sarama")func main() { config := sarama.NewConfig() consumer,err:=sarama.NewConsumer([]string{"192.168.56.133:9092"},config) if err!=nil{ fmt.Println("开启consumer 失败") return } //获取某个topic对应的存储分区列表 partitionList,err:=consumer.Partitions("ngix-log") if err!=nil{ fmt.Println("获取topic:tailconfig下对应分区失败!") return } fmt.Println(partitionList) for _,partition := range partitionList{ //从分区列表中获取每个分区,针对每个分区开启单独的go程进行消费, pc,err:=consumer.ConsumePartition("ngix-log",int32(partition),sarama.OffsetNewest) if err!=nil{ fmt.Println("从分区%s获取数据失败") return } defer pc.AsyncClose() //开启go程:异步从每个分区获取数据 go func(partitionConsumer sarama.PartitionConsumer){ for msg := range pc.Messages(){ fmt.Printf("分区:%d offset:%d key:%v value:%v\n",msg.Partition,msg.Offset,msg.Key,string(msg.Value)) } }(pc) } select { }} |
8.Golang sarama模块结合Linux taill命令实时上传日志到kafka
验证kafka是实时的数据流处理平台,这个很关键。
我的日志内容增加了kafaka的topic需要处理,如果减少了也需要处理。所以kafka很适合传输日志内容。
1 2 3 4 5 6 7 8 | D:\goproject\src\go相关模块\kafka\consumer>go run main.go[0]分区:0 offset:93 key:[] value:nice to meet you Tom.------------------------------------------------分区:0 offset:94 key:[] value:nice to meet you Jack分区:0 offset:95 key:[] value:how are you?分区:0 offset:96 key:[] value:it's ok,I lost my girl firend.分区:0 offset:97 key:[] value:.............-----------------------------------在文件里删除以上内容之后分区:0 offset:98 key:[] value: nice to meet you Marry. |
Kafka问题汇总
生产环境中Kafak遇到的问题汇总
所有消费者重复消费同1条消息
程序执行完之后,偏移量没有被正确的提交,导致所有消费者一直在消费同1条消息。
解决方法
幂等性处理
在消费者端实现幂等性处理是解决重复消费问题的有效方法。通过在消费端记录已经处理过的消息ID或者通过消息去重的方式,可以保证同一消息不会被重复处理。
提交消费偏移量
及时提交消费偏移量是避免重复消费的关键。可以通过设置适当的提交频率或者在消息处理完成后手动提交偏移量来确保消费偏移量的准确性。
使用Exactly-Once语义
Kafka提供了Exactly-Once语义来解决重复消费和消息丢失的问题,可以通过配置事务或者幂等性生产者来实现Exactly-Once语义。
参考


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
2017-05-17 前端基础之CSS的引入+HTML标签选择器+CSS操作属性