

C#3.0新增特性
文章出处:http://www.cnblogs.com/allenlooplee/archive/2008/06/01/1211520.html
缘起
每次有新技术发布时,我们总能感受到两种截然不同的情绪:一种是恐惧和抵抗,伴随着这种情绪的还有诸如"C# 2.0用的挺好的,为什么要在C# 3.0搞到那么复杂?"或者"我还在使用C# 1.0呢?"等言辞;另一种则是兴奋和拥抱,伴随着这种情绪的还有诸如"原来这个问题在C# 3.0里可以这么简单!"等言辞。
最近我在公司内部做一个LINQ的系列讲座,在我为其中C# 3.0新特性这一讲准备演示文稿时,突然萌生了写下这篇文章的念头。语言的特性乃至其本身并没有对错之分,是否接受在很大程度上是一个感性问题,即你是否喜欢这样的做事方式,我并没有打算说服任何人接受C# 3.0和LINQ,写这篇文章也只是想和大家分享一下我自己的感受。
有一次我观看一个关于Expression Blend的培训视频,里面说了一句让我印象非常深刻的话:
I know how it works because I know why it works.
细细品味这句话,你会感受到它所要传达的信息:理解为何需要这个功能可以帮助你更好地理解如何使用这个功能,而这也正是我要在这篇文章里采用的表达方式。
你是如何创建属性的?
如果你长期使用C#,相信你不会对属性这个东西感到陌生。一般地,属性是对私有字段的一个简单包装,就像这样:
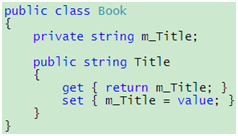
代码 1
使用属性而不是直接公开私有字段的一个好处就是在属性的获取访问器或设置访问器里加入额外的逻辑并不会为客户端代码带来麻烦,例如你想在设置标题的时候做一些额外的检查。但如果你只是简单地包装一下,像上面的代码那样,就会发现你其实多写了不少可以省略的代码。既然Title属性和m_Title私有字段对应,获取访问器就肯定是返回m_Title的值,而设置访问器也肯定是把值设到m_Title。再者,如果你只通过Title属性来访问这个数据,那么m_Title私有字段就会变得无足轻重,这样的话,为什么不交给编译器代劳呢?这个时候,C# 3.0的自动属性就可以派上用场了:
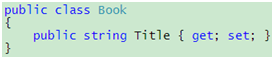
代码 2
编译器会为你创建一个私有字段,并让获取访问器和设置访问器指向这个私有字段。当然,如果有需要,例如要在获取访问器或设置访问器里加入额外的逻辑时,你随时可以对获取访问器和设置访问器进行展开。
你是如何初始化对象的?
现在,假设我们有这样一个类:

代码 3
你会怎样初始化它?一种做法是用Book的默认构造函数创建对象实例,然后分别为每个属性赋值:

代码 4
另一种做法是使用C# 3.0对象初始化器:

代码 5
乍看一下,C# 3.0的做法似乎没有让人感到任何优越感,现在,请你仔细观察一下,这两份代码分别包含多少个";"?代码4有5个";",意味着它用了5个语句进行初始化;而代码5只有1个";",意味着它只用了1个语句进行初始化。从词法的角度来看,如果此刻我只能接受一个表达式,那么代码4的做法就帮不上忙了。一个变通的方法是为Book类提供带参的构造函数,但这种方法也有弊端,用户可能只想在初始化时为部分属性提供数据,而我们又无法确切预知用户会提供哪些属性的组合,于是,我们可能要为用户提供足够多的构造函数重载,嗯,有点无聊,也有点多余。另一个变通的方法是提供接受最多参数的构造函数,如果用户为某个参数传递null,那么就忽略与之对应的属性,这个方法比较接近代码5的做法,不同的是,如果你的属性很多,而用户关心的只是很少一部分,就可能不得不输入很多null了。
现在,假设你要实例化一组Book对象,并把它们储存在一个集合里,你会怎么做?下面是通常的做法:
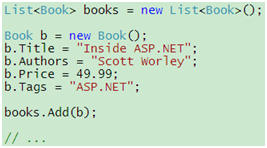
代码 6
如果结合使用C# 3.0的对象初始化器和集合初始化器,你就可以把代码简化为:

代码 7
集合里的每个元素通过","分割,结合对象初始化器使用,整个集合的结构显得比较明晰。字典的初始化也可以同样简单:

代码 8
说到这里,我相信你也能感觉到,C#似乎正在表达式化,以前需要很多条语句才能做到的事情,现在却可以用单个表达式描述出来,而这种理念也渗透在整个C# 3.0的氛围里。
你是如何把运算逻辑外包出去的?
假设我现在得到了一组Book的实例对象,你要对它们进行排序,那么你如何告诉它你要按价格来排序呢?

代码 9
在C# 1.0里,我们需要特意为它提供一个独立的方法:

代码 10
然后向Sort()方法传入所需委托的实例:

代码 11
这在C# 2.0里可以进一步简化为:

代码 12
如果使用C# 2.0的匿名方法,我们可以省去很多不必要的代码:

代码 13
此外,使用匿名方法,Sort()方法和你希望它用来比较两个Book实例对象的逻辑可以放在同一个地方;而使用独立的命名方法,包含这个逻辑的方法可能会由于整理代码而被挪到别的地方。这样,当你看到代码12时,为了了解它内部的实现,就不得不花一些精力去寻找Compare()方法了。当然,你可以争辩说,我们可以制定一个编码规范,使得Compare()方法必须紧贴在Sort()方法的下方。是的,你可以,但如果这个逻辑并不需要重用,那么使用匿名方法还是具有明显的优势的。如果这个逻辑需要重用,那么匿名方法就无能为力了。
现在,让我们来考察一下代码13,有没有发现匿名方法的表达方式还不够简练?我们知道,books集合里面只有Book的实例对象,所以Sort()方法传给我们两个参数的类型必定是Book,而Sort()方法期待的结果正是x.Price.CompareTo(y.Price)这个表达式的运算结果,至于delegate和return这样的字眼可以说在这里完全是多余的,那么为什么我们不直接这样表达呢:

代码 14
这就是C# 3.0引入的Lambda表达式语法。我见过一些人,他们通常强调尽可能简单,但若事情突然变得比他们预期的还要简单很多,他们就开始感到不适,甚至拒绝接受这种简单,其实即使事物的发展方向和你的前进方向相一致,但如果发展速度大大超越了你,仍然有可能引发你内心对失控的恐惧。我希望Lambda表达式语法不会让你感到太大的不适,当然我更希望你会喜欢上它。
Lambda表达式的理解其实可以很简单,就是"=>"左边的参数参与右边的表达式运算,而运算结果将会返回,这有点像化合反应,即两种或两种以上的物质(左边的参数)生成一种新物质(右边的表达式的运算结果),不同的是,Lambda可以不接收任何参数,也可以不返回任何结果。
"=>"右边除了可以放表达式之外,还可以放语句,像这样:

代码 15
我们把它称为Lambda语句(Lambda Statement),或许你已经发现,它和匿名方法相比只是不需要写delegate关键字和参数类型。
你是如何为对象扩展与之相关的功能的?
我一直在想,为什么String类没有提供一个Reverse()方法,把字符串翻转呢?我猜可能是因为这种操作没有什么现实意思,除非你要做一个文字游戏。实现Reverse()方法并不难,下面是其中一种做法:

代码 16
使用方法也非常简单:

代码 17
你甚至可以把Reverse()方法放到某个静态类里,例如Utils,这样,代码17就可以变成:

代码 18
在C# 3.0之前,你最多只能走到这里,而到了C# 3.0,你还可以使用扩展方法对它做进一步调整,使代码18变成:

代码 19
怎么样,看上去就像Reverse()方法是属于String的,而你所需要做的仅仅是在Reverse()方法的target参数前面加上"this"关键字:
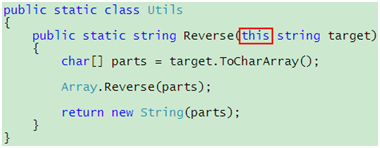
代码 20
我们知道,计算机的底层世界并不知道什么是面向对象,而我们在对象里定义的实例方法都包含一个隐藏参数,这个参数就是指向当前对象实例的指针,C# 3.0的扩展方法在形式上模仿了这种做法,但由于扩展方法本质上并不属于与之相关的类,所以你无法在扩展方法里访问类内部的私有成员。
就上面的讨论来说,你可能认为,和代码18相比,代码19并没有太大的优势,那么为什么需要扩展方法呢?假设我们手头上有一堆书,我想找到最便宜的LINQ的书,使用标准查询运算符的话可以这样写:

代码 21
我们知道,Where()、OrderBy()和First()等都是扩展方法,如果C# 3.0不支持扩展方法,那么代码21就不得不写成这样了:
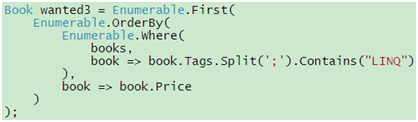
代码 22
代码21的可读性明显比代码22的高,也显得更自然,而此时我们只是使用了3个标准查询运算符,你可以想象一下,在没有扩展方法的支持下要表达更复杂的查询会是怎样一番情景?
你是如何表达你想要的东西的?
现在,假设我想找到最便宜的LINQ的书,使用C# 2.0的语法,我可能需要这样:

代码 23
虽然我已经使用了Array.IndexOf()方法、List<T>.Sort()方法和匿名函数来简化代码,但仍然无法掩盖一个事实,那就是我在讲述如何获取我想要的东西,而这也正是命令式编程(Imperative Programming)的核心思想。
如果使用C# 3.0的语法,情况将会大不一样:
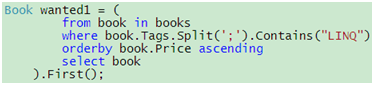
代码 24
在这里,你表达了你想要的东西,而不是获取这些东西的具体步骤,这是声明式编程(Declarative Programming)的核心思想,这样做的好处是明显的,你的需求可以被重新解析并执行,必要时还可以对底层的实现进行优化,但由于你并不关心和牵扯到具体的实现上,所以那些优化并不会导致你修改代码。
命令式编程就像过程管理,你深入执行的细节,继而对整个过程的执行实施控制;而声明式编程则像目标管理(MBO),你制定目标,并把任务分配下去执行。代码23给人的感觉就是整个执行过程都非常的清楚,你可以对任何一个步骤进行修改或者调优;而代码24给人的感觉就是你除了说出你想要什么,你什么也不能做,这对于那些过程管理拥戴者来说可能是不可接受的,他们感到对事物失去了控制,无法建立安全感,因而产生了焦虑。曾经有人向我抱怨:如果你使用了LINQ,你就只能迫使自己相信它的实现是很好的。想想看,如果你的公司把饭堂业务承包给一个餐饮公司,你的公司可以插手别人如何招聘厨师、如何采购食物、如何烧菜烧饭吗?选择LINQ意味着你愿意把执行细节交给别人去处理,从而脱离这些细节,如果你根本无法放下对这些细节的控制,那么LINQ可能并不适合你。
很难说这两种编程方式孰优孰劣,因为在某些场合下,善于过程管理的管理者确实更能让事态朝正确的方向发展;而在另一些场合下,目标管理为实现者提供足够的自由度,更能激励他们积极地进行思考。管理界对于过程管理和目标管理孰优孰劣之争论似乎从来没有停过,更何况编程界对于命令式编程和声明式编程孰优孰劣之争论,我个人倒是更倾向于把这看成是找出更适合你自己的风格,而不是盲目听信别人的说法。语言到底是发挥积极作用还是消极作用在很大程度上是取决于使用者的,我们应该使用语言有利的一面来协助我们的工作,而不是使用其有害的一面来伤害自己和别人。
回到代码24,它把满足条件的书的所有信息都返回给我,如果我只需要书名和作者名字呢?我们知道,在面向对象的世界里,信息储存在对象里,于是我们不得不走到一个尴尬的境地,那就是我们要为此创建一个临时类:
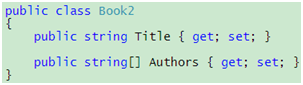
代码 25
噩梦正式开始了,如果我需要书名和价格呢?如果我需要书名、作者和价格呢?……(读者可以自行补全这个列表)这个时候就轮到C# 3.0的匿名类型和隐式类型化变量出场了:

代码 26
因为匿名类型是由编译器自动生成的,而在你写代码的时候它还没有名字,所以你无法用这个类型来声明这个变量,此时"var"关键字就派上用场了。这个是"var"关键字的最初目的,但得益于类型推断系统,我们还可以使用"var"关键字声明任何本地变量,只要我们在声明的同时给予它初始化,否则编译器无法进行推断。曾经有人问我:如果我想返回代码26里的wanted7怎么办?我们知道,方法的返回值需要明确给出类型,而在我们写下代码26时,编译器还没有给查询表达式里的匿名类型取名。如果你真的要把它返回,你只能把方法的返回值类型定为IEnumerable<object>,因为我们只能确定匿名类型是object的后代,但这样一来,客户端代码的日子就不太好过了,因为除了通过反射来访问你的对象,它别无他选。如果你真的要把它返回,那就意味着你和客户端代码有共享这个对象的需求,此时恰当的做法应该是使用命名类型。另外,代码26里构建匿名类型时的"book.Title"是"Title = book.Title"的简写,当你省略"Title ="时,编译器会假定你希望匿名类型的这个属性的名字和Book.Title的一样。
匿名类型还有一个有趣的地方,它曾经是可变的(mutable),后来却变成不可变的(immutable),Sree在《Immutable is, the new Anonymous Type》一文中给出了这个转变的解释。我们知道,在面向对象的世界里,对象封装并维护自身的状态,我们通过调用对象的方法所产生的副作用来影响对象的状态,而不可变则是函数式编程(Functional Programming)的核心特征,或许你已经感受到了,C# 3.0引入了大量函数式编程的东西,而函数式编程语言似乎也要风生水起,这究竟意味着什么呢?
前路在何方?
无论你是否承认,C# 3.0在表达上比它之前的版本要来的简单,但要获得这种简单,你必须先用很多东西武装自己的脑袋,这使我想起曾经在一本书里看到的一句话:
简单是由复杂来支撑的。
不同语言之间的相互渗透已经不再是什么新奇之事了,引入其它语言的功能有时候甚至可以看作是在战略上入侵对手的市场,这在某种程度上有点像金融业的混业经营。下一个版本的C#将会是怎样的呢?或许这个问题令你兴奋不已,你甚至希望现在就让C# Team看看你的创造力;或许这个问题令你痛心不已,你害怕自己无法适应下一波的变革,因为变革可能导致动荡,动荡可能带来失控,失控可能引发焦虑。不管怎样,该来的是无法回避的,或许现在先让我们看看Matthew Podwysocki的《What Is the Future of C# Anyways?》是否有一些启示……

