数据库整理
创建数据库
创建数据库需要指定字符集,不然容易在插入数据时发生错误。
create database 数据库名 default charset utf8 collate utf8_general_ci;
创建表
创建表很容易创建,但是值得注意的是,创建表时,有时候同样需要指定字符集以及引擎。除此之外还有约束条件。
create table 表名( 属性1 数据类型 not null primary key auto_increment comment '属性描述', # 非空、主键、自增。 属性2 数据类型 default 1 comment '属性描述', # 默认值constraint `外键名称` foreign key (属性) references 参照表(属性), )engine = InnoDB default charset =utf8;
插入数据
插入数据有两种方式,但我们一般选择有列名的。
Insert into 表名(列1,……列n) values (值1,……值n); Insert into 表名 values(值1,……值n);
复制数据也算是插入数据的一种,语法如下,但要注意的是表2必须事先存在,而且查询出的字段数目、数据类型、字段顺序要与插入列保持一致。
Insert into 表2 列名 select 列名 from 表1;
更新数据
更新数据的前提是要遵守约束。
update 表名 set 列1 = 新值1,列2 = 新值2 where expr
删除数据
删除数据用 delete from 表名 where expr。
删除数据表 用 drop table;
查询数据(单表查询)
查询分为单表查询和多表查询。
1. 简单查询,比如查询某一列(行)或者多行(列)。
2. 去重:distinct关键字指示数据库只返回不同的值。
3. where 条件 查询,例如,查询姓名为张三的学生信息;select * from student where sname=‘张三’;
3.1 where 常用的比较运算符;=、>、>=、<、<=、<>等。
3.2 between……and 代表的意思是两者之间且包括两者。
3.3 in、not in 判断某个字段的值是否在指定的集合中。
3.4 like 选择类似的值,例如:姓刘的:like '刘%'。 如果说是姓名为两个字,且姓为张 : like '张_'。
3.5 is nul:判断为空 not null : 判断不为空
3.6 逻辑运算: and or not
4. group by 分组查询
4.1 分组函数作用于一组数据,并对一组数据返回一个值。
4.2 avg函数返回满足where条件的一列的平均值。聚合函数之一
4.3 count(列名)返回某一列,行的总数。聚合函数之一
4.4 Max/Min函数返回满足where条件的一列的最大/最小值。聚合函数之一
4.5 sum函数返回满足where条件的行的和。聚合函数之一
SELECT 聚合函数和group by后存在的字段 FROM .. WHERE …. GROUP BY 字段1[,字段2,字段3]; 举个例子:查询学号范围在1001~1010之间的这10位学生的总成绩, select sum(degree),sno from score where sno between 1001 and 1010 group by sno;
5. having 筛选
having 和 where 的区别:
1. having与where类似,可筛选数据,where 后的表达式怎么写,having就怎么写
2. having 针对查询结果中的列发挥作用,筛选数据。where针对表中的列发挥作用,查询数据
3. gruop by 是在where条件后执行的。having是在group by 后执行的。
4. having 后可以使用聚合函数,where不可以。
6. order by 排序
order by 指定排序的列,排序的列即可以是表中的列名,也可以是select 语句后指定的列名。
order by 默认是asc即升序。降序为desc
order by子句应该位于select 语句的结尾。order by后面可以跟多个排序条件。
7. limit 限制结果条数
Limit [offset , N] 从offset开始,限制结果取N条。经常用于分页。
其中的3~7被合称为select的5种子句。
查询语句的编写顺序:SELECT … FROM … WHERE … GROUP BY … HAVING … ORDER BY …
查询语句的执行顺序:WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
常用函数
1. 时间日期相关函数:
| current_Date() | 当前日期 |
| current_Time() | 当前时间 |
| datediff(date1,date2) | 两个日期差多少天 |
| timediff(date1,date2) | 两个时间差多少时多少分多少秒 |
| now() | 当前时间 |
| Year()、Month()、Date() | 获取年、获取月。获取日 |
2. 字符串相关函数:

3. 数学相关函数

4. 流程控制函数

举个简单的例子:例如:SELECT scoid,socre,IF(socre>=60,'及格','不及格') AS 等级 from score;
5. 其他函数
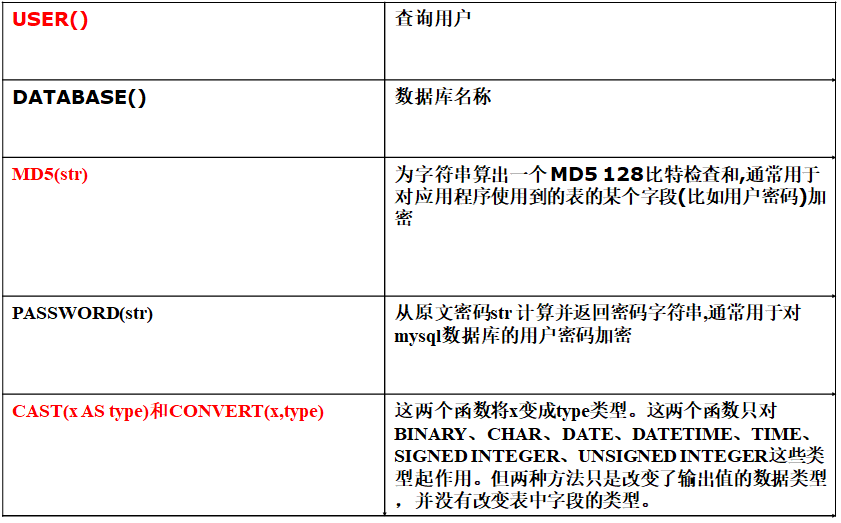
举几个例子:
# 获取当前用户 select user() as s1; #加密函数 select md5(name) from student; #改变字段数据类型的函数 select cast('123' as unsigned int)+1 select convert('123',unsigned int) +1
多表查询
1. 交叉连接:交叉连接会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积。
交叉连接的三种语法:
select * from table1 cross join table2 where 条件; select * from table1 join table2 where 条件; select * from table1,table2 where 条件;
2. 等值连接:where条件后是‘=’则为等值连接;
3. 内连接:合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表不匹配的行。
语法:SELECT <列名> FROM 表1 INNER JOIN 表2 ON 表1.列名 条件运算符 表2.列名 [WHERE 条件] [ORDER BY 排序列]
举个例子:查询小王所考科目的平均成绩,显示成绩,平均成绩
select name,avg(score) from score inner join student on score.stuid = student.stuid where name = '小王'
3. 外连接:外连接分为左外连接和右外连接。
3.1外连接和普通连接的区别:普通连接操作只输出满足连接条件的元组。外连接操作以指定表为连接主体,将主体表中不满足连接条件的元组一并输出。
3.2 左外连接:左外连接使用LEFT JOIN连接两表,连接时左表为主表,左表中的每条记录必定出现在结果集中,而在右表中没有对应的记录,将以NULL值进行填充。
SELECT * FROM TABLE_A LEFT JOIN TABLE_B ON 连接条件 [WHERE 条件]
举个例子:查询所有学生课程的考试成绩,查询结果保留学生ID、姓名、性别、课程ID、成绩
select student.sno,name,sex,sno,scorre from student left join score on student .sno = score.sno;
3.3 右外连接 :右外连接与左外连接相似,不同的是右表为主表,右表中的每条记录必定出现在结果集中,而在左表中没有对应的记录,将以NULL值进行填充。
语法:SELECT * FROM TABLE_A RIGHT JOIN TABLE_B ON 连接条件 [WHERE 条件]
4. 内外连接的区别:

子查询
子查询就是在原有的查询语句中, 嵌入新的查询,来得到我们想要的结果集。 也叫嵌套查询。
子查询分为:比较子查询,IN/NOT IN子查询,EXISTS/NOT EXISTS子查询
IN/NOT IN 与 EXISTS/NOT EXISTS的区别:
IN/NOT IN先执行子查询,子查询返回的是一个集合,然后再将子查询的结果作为外层查询的条件进行过滤。
EXISTS/NOT EXISTS先执行外层查询,再将外层查询的每一条记录作为条件进行子查询,子查询返回的只是返回一个TRUE或FALSE,因此一般情况 下子查询中直接使用SELECT 1提高效率。
视图
什么是视图:视图是一张虚拟表,视图中不存放数据,数据存放在视图所引用的原始表中。
如何创建:create view 视图名 as select 语句
如何查看视图:select * from 视图名
如何删除视图:drop view 视图名
查看视图表结构:desc 视图名
查看视图:show create view 视图名
修改视图:alter view 视图名 as select 语句
注意点:当表发生改变,视图也会发生改变。同样的当视图发生数据的增删改,那么同样也会影响到表。
视图的优点:定制数据、聚焦数据。简化数据操作,原表中的数据有一定的安全性,合并分离的数据,创建分区视图。
索引:
索引是以表列为基础建立的数据库对象,它保存着表中排序的索引列,并且记录了索引列在数据表中的物理存储位置,实现了表中数据的逻辑排序
使用索引,加快了查询速度。但降低了曾、删、改的速度,增大了表的文件大小。
索引的类型有以下六种:

普通索引仅仅加快了查询的速度,主键索引:加上主键的列的值不能重复。
唯一索引:加上唯一索引的列的值不能重复,它和主键索引的区别是:主键必须唯一,但索引不一定是主键,一张表中只能有一个主键,但是可以有一个或多个唯一索引。
索引的创建:
# 建表时直接声明索引
create table tableName ( 列1 列类型 列属性, .... 列N 列类型 列属性, primary key(列名), index (列名), unique(列名), fulltext(列名) )engine xxxxx charset xxxx
# 通过修改表建立索引:
alter table 表名 add index (列名); alter table 表名 add unique (列名); alter table 表名 add primary key(列名); alter table 表名 add fulltext (列名);
索引的删除:
删除主键索引:alter table 表名 drop primary key
删除其他索引:alter table 表名 drop index 索引名
索引的查看:show index from tableName

 浙公网安备 33010602011771号
浙公网安备 33010602011771号