Programming Languages PartB Week1学习笔记——Racket纯函数式编程语言
@
- Overview of Part B
- Racket 介绍与安装
- Introduction to Racket
- Racket Definitions, Functions, Conditionals
- Racket Lists
- Syntax and Parentheses
- Parentheses Matter! (Debugging Practice)
- Dynamic Typing
- Cond
- Local Bindings
- Toplevel Bindings
- **Mutation with set!
- The Truth About Cons
- mcons For Mutable Pairs
- Delayed Evaluation and Thunks
- Avoiding Unnecessary Computations
- **Delay and Force
- Using Streams
- Defining Streams
- **Memoization
- Macros: The Key Points
- Option 后面还有一些关于Macro的选学内容
Overview of Part B
回顾Part A的ML内容

简单介绍Part B的内容, 主要是Racket的使用


Racket 介绍与安装
下面是来自百度百科的介绍:
Racket源自著名的专家型语言PLT Scheme,同时又是Lisp语言的一个分支。它适用于从脚本Script到应用程序开发的任务执行工具,包括图形用户界面,Web服务器等。支持编译器的虚拟机,创建独立的可执行程序的工具,Racket Web服务器,具有丰富而全面的功能库,适用于初学者和专家编程
Scheme最早由美国麻省理工学院MIT的Guy Lewis Steele Jr.在1970年代发展而来,后由Felleison发起PLT Scheme项目,其主要目的还是作为函数式编程的启蒙和教学语言,因此Racket很适合作为一个学习语言来学习,并于2010年6月将PLT Scheme更名为Racket,同时将DrScheme更名为DrRacket
Lisp语言的介绍:
Lisp语言的历史很久,几乎与史上第一个高级语言Fortran一样长。1957年计算机科学家首先发明了针对数字计算的Fortran语言,后来针对符号计算,由MIT的John McCarthy于1958年开发了Lisp (List processing)语言。
基于λ演算所创造,它适用于符号处理、自动推理、硬件描述和超大规模集成电路设计等。特点是,使用表结构来表达非数值计算问题,实现技术简单。采用抽象数据列表与递归作符号演算来衍生人工智能,LISP语言已成为最有影响,使用十分广泛的人工智能语言。(题外话:上个世纪的人工智能想法)
所以这里的Racket与原来的Scheme类似(实际上就是改名了),是Lisp的一种分支,是一种学习型(也有用在实际项目中)的函数式编程语言,对比上一部分的ML语言而言,该语言会更纯粹(函数式),编程思路也将与传统的指令式编程不同。
从Racket官网下载https://racket-lang.org/并安装官方提供的DrRacket IDE。DrRacket还可以写一些其他语言,但我们在课程中用来写Racket。
Racket官方教程https://docs.racket-lang.org/guide/index.html
Introduction to Racket
课程Racket简介


DrRacket的使用,Run按钮可以打开命令行REPL,同时 Ctrl+E 也能打开或关闭REPL,格式化代码:Ctrl+I

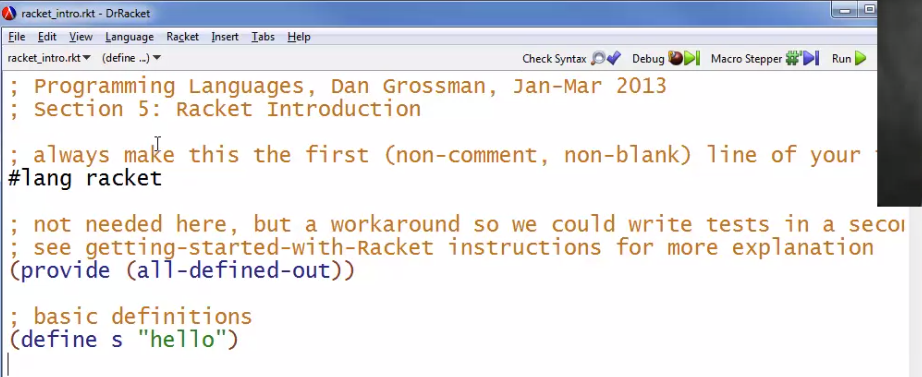
常见的一些Racket文件开头代码,Racket使用分号 “ ; ” 作为注释的符号
; 这一句代码用于标记文件使用的语言,告诉DrRacket文件使用的语言是Racket
#lang racket
; 这一句代码,让文件中的顶级定义(top-level externally)在外部可见。由于Racket每个文件都是自己独立的module,其中的定义内容默认是包含在module内部的private的内容。想要在外部文件中直接调用就需要这行语句。当然,在同一个文件的REPL中调用时,不需要这句话。
(provide (all-defined-out))
; 在test等其他文件中使用下面的语句,引入某个文件,相当于import了其他模块
(require "foo.rkt")
; 基本的定义语句
(define s "hello")
Racket Definitions, Functions, Conditionals
Racket语法大幅度区别于以往的命令式语言,首先是变量和函数定义(val or fun binding )

使用括号()来限定一个表达式的范围,使用define关键词来定义变量名及赋值等,lambda表达式用来描述并定义一个函数关系(注意lambda的参数需要带括号)。调用函数使用(函数名 变量表达式1 变量表达式2)的方式,包括加减乘除等算术运算、相等大小判断等比较运算,例如(* e1 e2)。题外话:这种调用方式其实有点类似之前ML课程中,使用datatype定义的实数运算的调用结构(比如 Mul(Add(Const 5, Const 1), Const 2) )
定义函数时(如果不用lambda),无参函数仍然需要括号括起来 ,(define (fun) (...fun-body...))
Racket提供了运算符函数的重载,可以对多个变量使用。同时lambda关键词并不是必须的,可以将函数名和参数作为一个整体(包含在一个括号内)。

Racket的条件判断,只需要if关键词,后面三个参数分别跟上条件、true的结果、false的结果
函数定义仍然能递归定义

注意pow1函数中的参数用的是 x y,实际上相当于给了两个参数(类似ML的tupled参数传递方式)。
但这些参数也确实可以是currying的,例如下面的例子。lambda其实就是定义了匿名函数,并具有闭包的特性。

同样的,函数能作为参数传递,且currying的函数能够实现partial application来生成函数。

需要注意的是,与ML相同,不同的定义方式需要用不同的方式来调用,pow1调用可以直接写多个参数,但pow2调用必须按参数的currying顺序逐层调用(必须有括号)

Racket的最基本的语法如下,其中e0是主要关键词,可以是define,lambda,provide,if或者函数名等。剩下的都是相应的表达式、变量名、其他关键词或子语句等。题外话:从这里可以看到Racket的语法一致性非常强,都是同样的一种语法结构的不同表达形式(至少到目前课程为止)。
(e0,e1,e2,...,en)
Racket Lists
与ML的List类似,各种语法如下,需要注意的是list可以容纳不同类型的值(Racket在运行前不会Type-check)。

list的语法与ML是基本类似的,语法对照如下:
| 语法 | Racket | ML |
|---|---|---|
| 空列表 | null 或 '() | [] |
| 连接一个元素与一个列表 | cons | :: |
| 取列表第一个元素 | car | hd |
| 取列表除第一个元素外的子列表 | cdr | tl |
| 判断列表是否为空 | null? (不止对list判断) | null |
| 根据元素生成列表 | (list e1 e2 ... en) | [e1,e2,...,en] |
; 例子1,sum all the numbers in a list
(define (sum xs)
if (null? xs)
0
(+ (car xs) (sum (cdr xs)))
; 例子2 append
(define (my-append xs ys)
if (null? xs)
ys
(cons (car xs) (my-append (cdr xs) ys))
; 例子3 map
(define (my-map f xs)
(if (null? xs)
null
(cons (f (car xs))
(my-map f (cdr xs)))))
Syntax and Parentheses
极度简化的语法!非常优雅(虽然用起来确实让我不太习惯,感觉有点反人类)

Racket的语法由term构成,一个term可能是
atom,special form 或者 a sequence of terms in parens
这里实际上就是一种递归的思想了(term也可能包含其他term序列,而atom和special form是递归出口)

为什么这样的语法很棒?

通过括号化,能够将程序代码转换为一颗程序树结构(结构更清晰)。同时由于这样的结构,多个运算符不会在同一个位置出现(括号已经表明了运算顺序),所以就不需要讨论运算符优先级的问题(这在C语言之类的命令式编程中是必须讨论的)。
Racket的语法组织形式其实与HTML类似(括号类比HTML的标签,大部分标签是需要闭合的,而且组成了树形结构(DOM))。所以其实也类似于XML或者JSON的组织形式。
我们不应该因为他的语法与其他语言有较大区别而主观上拒绝它,就好比优秀的历史学家不会因为不喜欢某个国家的人们的口音而拒绝去研究它。(研究不同于C语言体系的编程语言语法是一件挺有意思的事情,实话实说,能够体会到更多样的语言设计方式。不过在实际项目中写起来还是比较别扭,不太符合人类的逻辑直觉)

Parentheses Matter! (Debugging Practice)
圆括号很重要,如果括号中是表达式,表示call这个function(无参)

例子1:不能随便使用圆括号,由于是动态类型语言,运行到(1)时才会报错(不会提前type-check)

例子2:如果稍加修改,没有递归,仍然是只有运行 (1)时才会报错(n=0时)
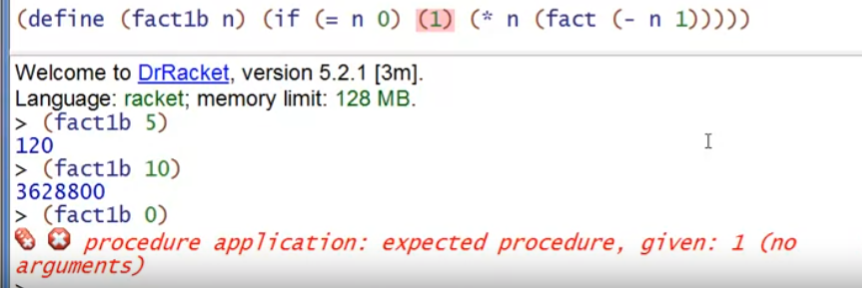
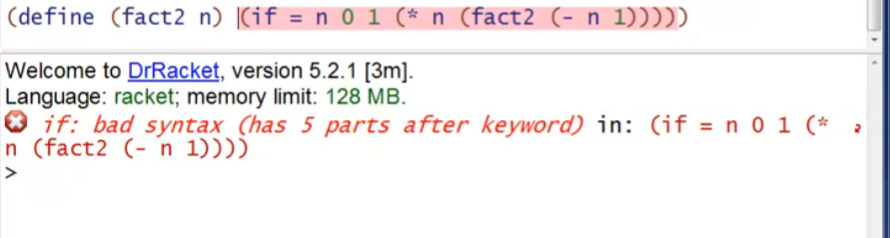
例子3:不能遗漏任何圆括号,否则无法识别语法
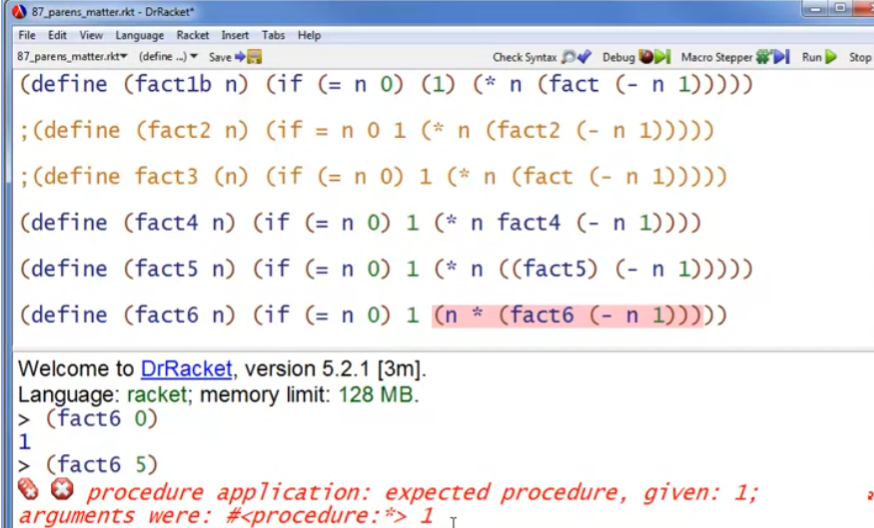
例子4:函数名和参数是一个整体term,不能遗漏括号,否则会被认为是val binding

例子5:

例子6:

例子7:
Dynamic Typing
Racket由于是动态类型,对 list的类型限制也没有那么严格,允许同时包含数字和嵌套列表或其他类型。但在使用list时要注意list中每个元素的类型情况

例子1:对嵌套数字列表的情况

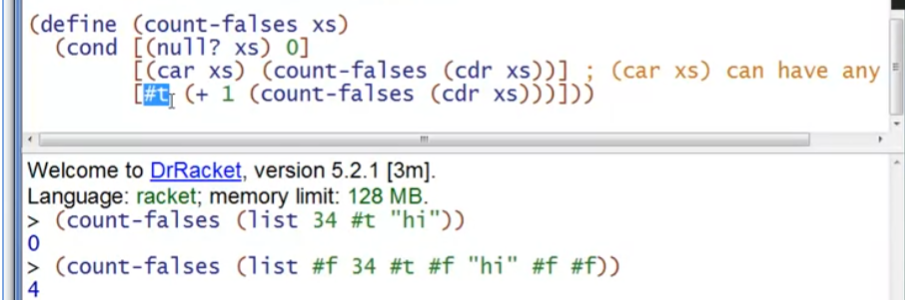
例子2:对列表中含有多种类型的元素(#f表示false),在函数调用时要判断每个元素的情况,否则操作对应不上就会报错(例如对字符串进行+运算)


Cond
用cond代替if then else

类似C语言的case,最后需要一个保底条件eNa为真(#t),否则Racket会返回一个void object,这样不太好。
例1:

例2:(题外话:语法太反人类,老师都写错了两个地方,笑死)

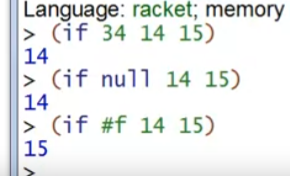
值得注意的是,在Racket中,不论是if还是cond ,在条件中都不要求一定是bool类型,它会认为所有非 #f 的值是true。(有点类似于C++中0认为是假,其他int值为真的意思,只是Racket要求更宽泛,甚至不一定是数字)

Local Bindings
Racket的local binding仍然可以使用let关键字

提供了多种方式来定义local binding,选择最适用于某个场景的方式。如果都可以适用,那就用let关键词。

(1)首先是let关键词。其语法是
(let ([x1 e1]
[x2 e2]
...
[xn en]) body)
必须要注意的一点是,let表达式中定义的local bindings(x1,x2...xn)是同时定义的(同时赋值evaluate),因此他们表达式中的值(e1,e2...en的evaluattion)都来自于let表达式以前,而不会因为let中的local binding语句顺序而变化(局部变量不会影响let表达式之前的同名变量的值)。例如下面的例子中,
let ([x (+ x 3)] [y (+ x 2)]) 中的 (+ x 3) 和 (+ x 2)的x 值全都来自于函数 silly-double的参数,而不会因为局部变量x而变化(即使从直观上看,y的定义在局部x之后,y的表达式中的x也来自函数的参数,而不是局部x)。这与ML等其他语言大不相同。
也就是说,可以理解为([x (+ x 3)] [y (+ x 2)])是一个整体,而不是具有顺序的多个命令语句,所以他们的赋值都依赖于let表达式之前的bindings(也就是函数参数的那个x)。当然,在body中就有局部作用域的覆盖效果了,(+ x y -5)中的x和y就只是局部变量了,跟函数参数的那个x无关了。
利用这种性质,可以很容易地实现变量交换顺序 ,(let ([x y] [y x])直接将外部的x,y 值交换赋值给局部的y,x。

(2)其次是let*表达式,语法与let相同,但特性不同
(题外话:可能是设计语法的人自己也觉得let的特性反人类了?笑死)。
事实上,let*就与ML等其他语言的let相同了,局部变量不是同时evaluate的,顺序在前的局部变量会影响后面的local binding。例如:

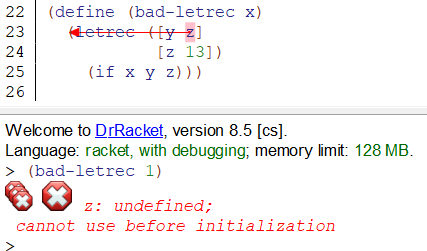
(3)然后是letrec 表达式,语法仍然与let相同
letrec允许local binding中使用所有的bindings(在函数中,即使是在使用时还没binding,但即将在letrec表达式中定义的变量。但从未在let之前或let中定义和初始化过的binding,(在v6.1以下的版本中)会将该变量值赋为#<undefined>,(在v6.1以上的版本中)会抛出异常 )。注意这个特性是和let不同的,let的local binding必须使用let之前的binding,而letrec使用所有的binding。这样的特性在互递归中很有用。

示例:当使用 [x (+ x 2)] 时会报错,这里其实是程序混乱了,解释器不知道后面这个x是指向哪个位置(local binding的x还是函数的参数x),结果就以为是local binding,认为这个值还没定义。
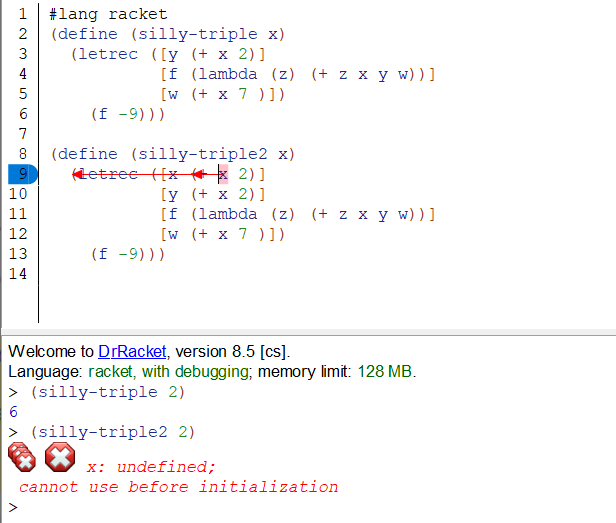
利用DrRacket提供的binding查看,可以说明这个现象。可见在letrec中,local的优先级是比较高的,有local的时候优先绑定到local变量(如果此时local的变量没有初始化就会报错),否则去找let表达式之前的bindings(绑定到更高一级的变量)


这一点也可以说明,letrec的binding规则是顺序化的,类似let*而不是let。如果为local 的x赋值一个初值,那么局部作用域的x会覆盖掉函数参数的x。
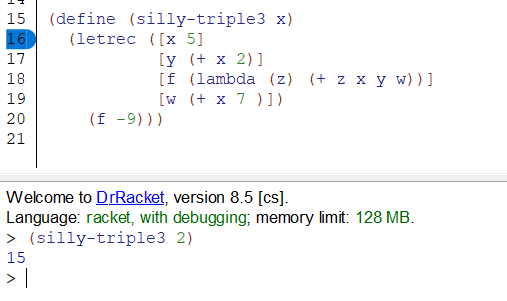

互递归示例,判断奇数偶数(mod2)。另外,很重要的是,不能在函数之外使用later bindings(仍然是因为顺序的问题,而函数似乎没有变量binding那么在乎顺序?)

(4)Local define
在特定位置,例如函数体的开头部分,可以直接使用define定义local bindings,并且特性与letrec类似,可以使用所有位置的bindings(包括互递归)。该方法定义bindings更符合Racket style(也没那么反人类)。

Toplevel Bindings
Top-level binding与local binding类似,只不过是在文件层面定义的。值得注意都是,later binding只能在函数体重定义,并且在later binding定义之前,该函数都不能被调用。
另外一点不同是,Racket在同一个module中不能重复定义一个相同的(名称)变量两次,意味着在同一个module中没有shadowing的概念(变量本身不能直接被改变(unmutable),其指向地址的变量也不能改变(no shadowing))。

例子:


不过,在不同的module之间可以shadowing

**Mutation with set!
虽然同一个module中不能通过相同名称来shadowing变量,也不能用define直接改变某个变量的值,但Racket确实提供了改变变量值的方法(赋值符号),那就是 set! 关键词
以begin关键词开头,是一个sequence,返回最后一个表达式(en)的值,当表达式有副作用时比较有用。sequence相当于C语言的逗号表达式。

例子:
需要注意的地方是,闭包的环境是在函数定义时决定的(环境中有哪些变量等),函数体的值在调用时才会计算(但仍然是lexical scope(static scope)(b还是定义时的变量b,只是在调用之前变量b对应的值被改变了),例如下面例子中的(f 4)的值,b已经在当前动态环境中变为5了,所以计算出来z为9)。ML中不存在这样的问题是因为unmutable。
另外,一旦表达式计算出一个值,那他就和计算值的过程无关了(值如果已经存储下来了的话,例如c的值不会再随着b变化而变化了)

这其实和C/C++是一样的,相当于是说函数的lexical scope绑定了变量是谁,但变量的值是需要调用时才知道的(这个值与新定义的局部同名变量无关),例如下面的C++例子:
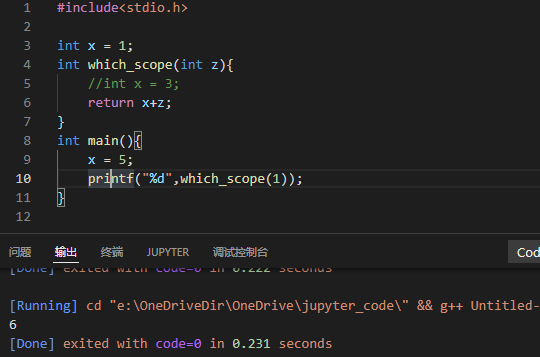
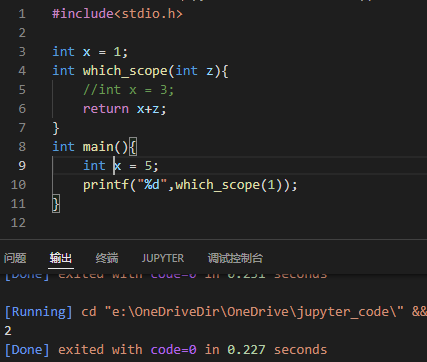
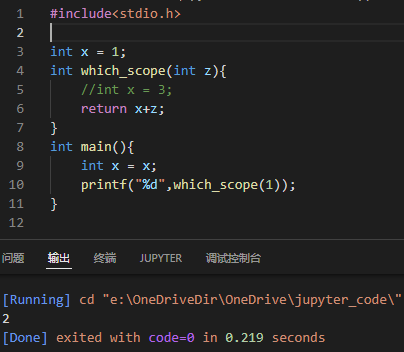
通用准则:如果某个你不想改变的内容可能发生改变,那就给它声明一个local copy
就类似上面C++例子中的局部 int x,如果一定要使用同样的名称表示(不想改变的内容可能发生改变),那就定义一个相等值的局部变量。
比如:
当然,这里指的是为函数定义一个local 的lexical scope,例如:现在的函数f 中,b就是局部的,而不是top-level(全局)的,如果后面全局b被修改了,也不会影响f中的b值

当然,由于运算符是全局预定义的,也存在被修改的可能性,所以也可以定义一个local copy

如果函数中使用了其他函数,那么所有函数中任何被使用到的可修改的东西,都需要声明成local copy
当然,这样过于复杂了,在Racket中也没有必要这么做。Racket的module机制在一定程度上杜绝了肆意的修改。
但是使用copy来避免mutaion的思想是比较重要的,在其他语言中也一样适用。

The Truth About Cons

cons不仅可以制造list,也可以制造pair(在这里叫做cell),取决于最后cons的一个元素是null(或某个列表),还是一个普通的元素。例如:
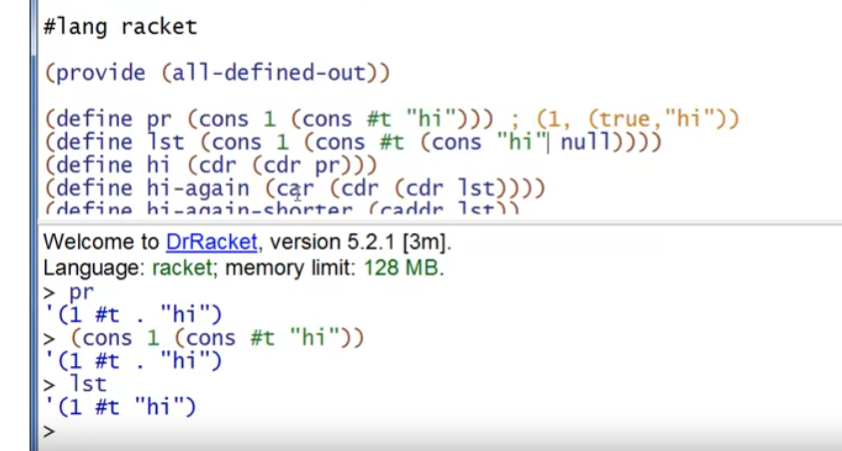
同理,car和cdr可以对cell使用,相当于ML的#1,#2。另外,由于历史原因,Racket还提供了(car (cdr (cdr xx)))的简化表达方式,(caddr xx)。
使用list? 和 pair? 可以分别判断是否为list或cell



mcons For Mutable Pairs
cons生成的内容内部是不可修改的

不可修改指的不是变量本身,而是指变量指向的内容的值(某个元素或子cons),也就是cons生成的结构的内容,例如,使用set! 能够改变变量x中存储的值,此时已经计算值的y不会受影响(类似于更改了x指针指向的位置,但y仍然指向原来的位置,所以内容没变)。但现在如果想要让y跟着x的变化而变化(类似于C中修改指针指向的内容中的值,或者说是java中修改引用指向的内容中的值),也就是说要直接修改x存储的列表中某个元素的值,那就不能再使用cons


(set! (car x) 45) 并不能修改x存储的内容(list)中的值

使用mcons,其语法与cons类似,其生成的内容需要mcar和mcdr来使用(其值中会明显标明mcons)

使用set-mcar! 和 set-mcdr! 来修改mcons中的某个元素。
需要注意的是,length能够用来计算cons生成的list有多少个元素,但不能用在cons生成的cell上。并且,即使mcons生成的是list,也不能使用length


Delayed Evaluation and Thunks
延迟计算与形式转换

函数调用时,函数参数表达式先计算参数的value 再call函数,会被贪婪地计算。而条件分支不会被贪婪的计算,会先根据条件的结果(true or false),决定哪一个分支会被计算。
在下面的例子中,说明了函数调用的计算过程(先计算函数的所有参数,导致函数陷入死循环)
factorial-normal中 if属于条件判断,会先计算条件(= x 0),再决定哪个分支被计算,因此x=0时是递归的出口
然而,factorial-bad函数使用了my-if-bad,虽然看起来像是unnecessary wrapping,但事实上更严重,因为函数调用前,所有的参数都会计算,导致factorial-bad会一直被调用,一直递归下去(死循环)。
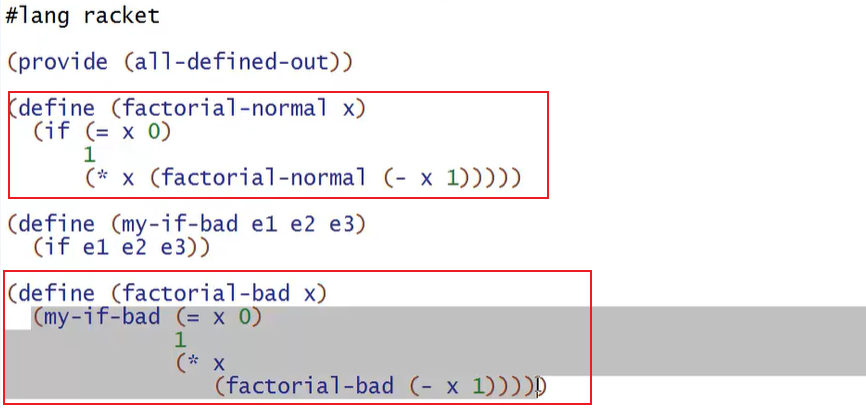
如果想要实现类似的if包装函数,需要将参数设计为零参数(zero-argument)函数(相当于高等函数使用一等函数做参数),然后使用零参数调用(e),这是一种delay evaluation的方式。这种方法的实质就是利用了,函数定义时不会计算值(要记得函数定义本身就是一个值),只有在调用时才计算返回值,所以将函数调用delay到了if 表达式真正调用的位置。

delay evaluation就是将表达式放到一个函数中来计算(得益于闭包)。如果要将一个函数a的调用返回值(及其一些操作的表达式)作为另一个函数b的参数传递进去,那就将函数a(及其一些操作的表达式)包装成零参数函数再作为函数b的参数传递进去,然后再函数b中调用零参函数。
这种零参函数的使用,被称为对表达式进行形式变换(thunk)


Avoiding Unnecessary Computations
如果不是必须要thunk(例如上一节例子中对递归函数的delay evaluation),那么在函数中调用一两次的情况是比较好的应用,但如果函数中多个位置(例如多个独立的if分支中)都使用到了同一个零参函数(重复调用非常多次),同时,这个零参函数的调用还非常缓慢(函数调用的时间代价高昂),那就是一种不好的使用情况,此时应该将他作为值来传递而不是传递thunk

例子:


当x为0时运行很快,因为没有计算y-thunk,但x越来越大时,y-thunk重复计算的次数越来越多,会导致程序运行速度变得非常慢。
这种时候除了不使用thunk,而直接传递函数调用值之外,通常也可以使用let定义局部变量获取这个函数调用值,然后再thunk这个局部变量。这样thunk局部变量可以避免改变函数原有的结构。

Racket为我们提供了实现这种lazy evaluation的预定义结构,叫做promise,但我们下一节会定义一个自己的。

**Delay and Force

实现这种lazy evaluzation可以使用delay and force的形式,并通过promise来判断。
这一节的结构设计非常巧妙和高级!
注意下面的例子中用到了 set-mcar! set-mcdr! ,和begin关键词生成的sequence,因为修改mcons的pair是一种副作用,所以用sequence是合理的。

my-delay中存储的实际上是函数是否调用的信息,#f时th是没调用的函数,#t时是调用的值(被my-force返回)。一旦一个promise被调用,他们的值就是(#t v) ,v就是th的调用值,这样就被记录下来了,实现了lazy evaluation。
如何使用:

例子:相当于对真正的thunk两层包装(当然,前提是真正的thunk函数的调用值必须是固定的)
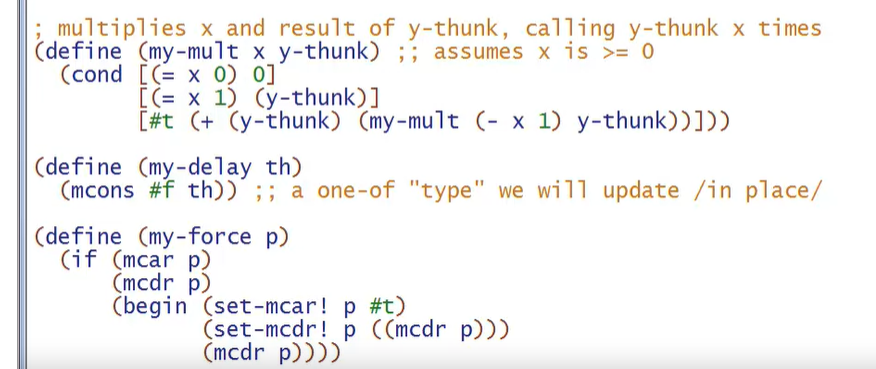

例子中的三种方式比较:

Using Streams
stream流,是一个无穷的sequence,在计算机领域很常见


例子:这里的stream是由procedure (powers-of-two)开始,每一个节点都是一个cell,第一个元素存值,第二个元素存下一个thunk(下一个procedure)
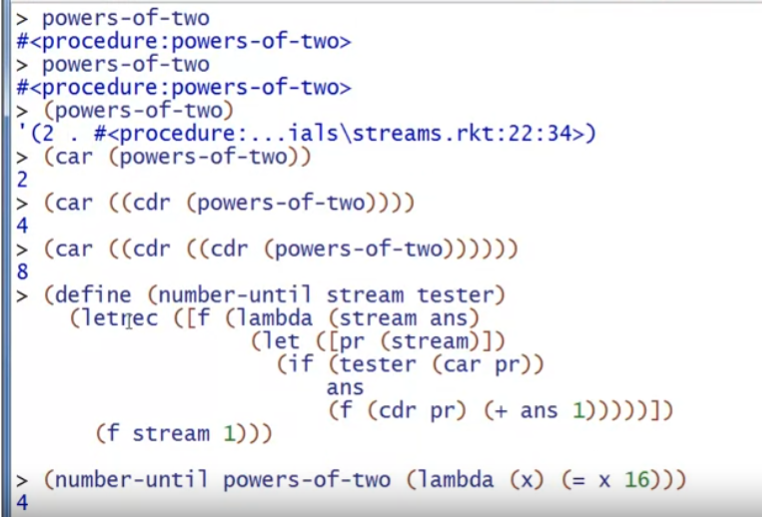

Defining Streams
一定要记住stream的标准格式:

定义stream的关键在于调用时返回一个结果和一个thunk,返回的thunk通常用递归实现(因为没有调用,只是传递递归函数,没有递归出口不会有任何问题),这样由于thunk由调用者调用,没有出口却不会出现死循环,而且正好是无穷的。
例子1:
例子2和3:注意local binding的使用,将f声明一个local copy,防止f后续被修改导致函数nats的效果变化,然后这里的lambda表达式写错了
另外注意 nats (lambda ())的写法,nats没有参数,所以nats本身就是后面的lambda定义的函数,如果是 (nats x) (lambda ()),那就必须调用(nats x)才能得到后面的lambda定义的函数(有点类似于patial application)。


例2和例3在语法上类似,因此可以使用类似ML的高等函数来简化整个代码

同时,需要注意的是,Racket(或ML、Java这些语言)拥有 eager semantic,函数调用时会计算所有能计算的值(函数参数、函数体中没delay的值)。
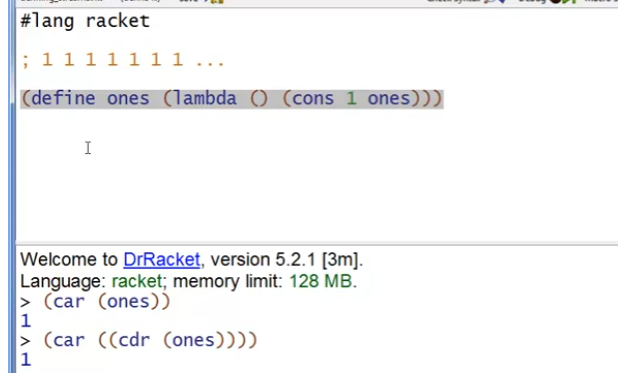
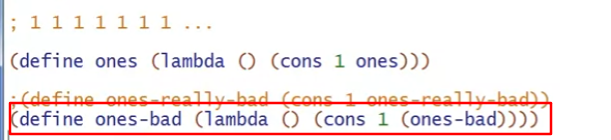
变量定义的时候也是这样,例如下面的例子,ones-really-bad就是一个循环定义的变量,所以会出现未定义的错误

而如果是一个无参函数,这样就变成了循环调用,陷入死循环
**Memoization
除thunk之外的另一种用来避免重复计算的常用方法

这种方法与promise类似,但可以携带参数,并拥有多个存储的结果
以斐波那契数列为例:
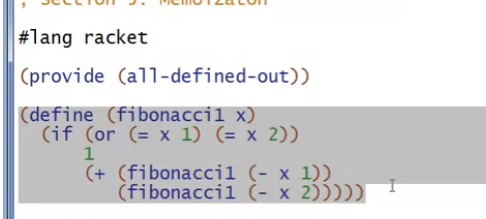
第一个是最常见的反向递归,多次递归,效率低下。
第二个是正向的递归(y增加到x停止),每次保存上一次的结果给下一次调用。

第三种是记忆化,这种方式有点类似于构建一个永久的hashmap来存储各种参数下的函数值。注意这里的memo是持续存在的,因为定义在f的外部,所以只有在fibonacci3调用的时候被初始化一次,f调用时不会初始化(这里将fibonacci3赋为f实际上运用了闭包特性,memo是一种类似全局存在的变量,但又不暴露在全局中)
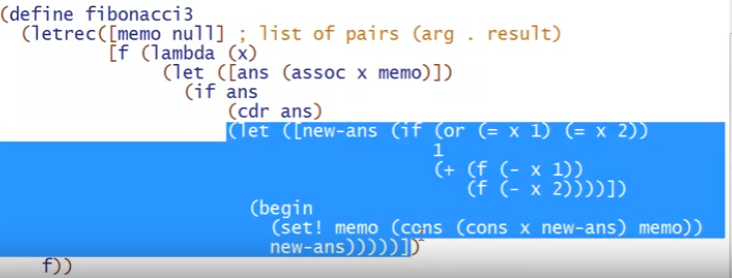
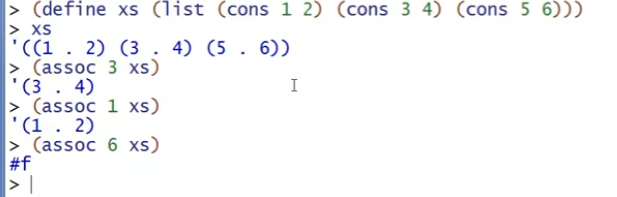
其中的assoc是库函数,用来判断某个值是否在pair的list中(判断cell的 car是否等于这个值),如果存在,返回存在的第一个(first)元素,否则返回#f
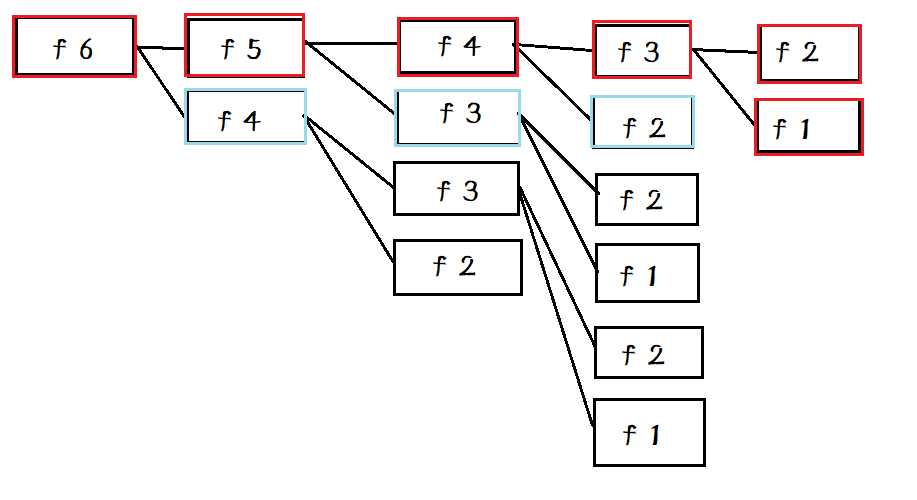
fibonacci3的实现方式中,虽然对于没有计算过的值仍然会调用两次递归,但由于已经计算的值不会再重复计算,就斩断了多余的递归(重复计算的过程)(原来的树形的函数调用栈直接变成了线性的),所以速度会很快。事实上就是f(- x 1)执行时会计算从1到x的所有值,存储下来
用图来表示就是:
以 f 6开始为例:理论上递归调用栈应该是一颗庞大的树,但由于记忆化,真正发生计算的只有红框的部分,而蓝框的部分是在获取已经计算的被存储的值,剩下的黑框部分根本不会发生(这部分的递归被斩断了)
Macros: The Key Points
macro宏命令

什么是macro

宏命令定义描述了如何添加新的语法,并将新语法转换到原始语言的不同语法上,可以用来实现语法糖(简化某些语法)
宏命令系统是一种用来提供定义宏命令的方法的语言(或某种大型语言的一部分)。
宏展开是指重写语法的过程,是宏指令的使用(根据源语法进行重写),宏展开发生在在程序运行之前(甚至在或在编译前被替换)。
(宏定义其实可以参考C/C++的宏,如果学过C的话其实很容易理解。先预定义一种模式,再在程序中运用这种模式(这些模式会在运行或编译前被展开成源语言的语法语句))。
Racket的宏命令使用

使用例子:


宏命令怎么定义的就需要怎么用,不能随便更改。
宏命令通常不被看好,因为容易被滥用。如果不确定macro是否适合,那就不要使用。


Option 后面还有一些关于Macro的选学内容
Optional: Tokenization, Parenthesization, and Scope
Optional: Racket Macros With define-syntax
Optional: Variables, Macros, and Hygiene
Optional: More Macro Examples
基本上是与Macro的概念剖析、定义语法和实现示例相关。虽然Racket的Macro是一种非常强大且有效的特性(感觉和C的宏类似),但由于没有怎么用到,以及时间问题,就先跳过这部分了。如果实际中需要用到Racket的Macro,再回过头来看看这一部分,然后翻翻文档就好了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号