NMAP xml文件系解析使用python-libnmap
pip install python-libnmap
参数解析使用 argparse
pip install argparse
导出Excel使用xlsxwriter模块
pip install xlsxwriter
json序列化成python 对象使用 simple-json模块
dumping 最快的是json内置模块
demsjon 性能不如simplejson
simplejson的loading数度比 dumping 快速
进度条的实现
#打印进度条,这个进度条打印思路很不错
def printProgress(cnt, tot, target='', previouslen=0):
percent = 100 * float(cnt) / float(tot)
if target and previouslen > len(target):
target = target + ' ' * (previouslen - len(target))
sys.stdout.write('[%-40s] %d%% %s\r' % ('='*int(float(percent)/100*40), percent, target))
sys.stdout.flush()
return ''
代码
# -*- coding: utf-8 -*-
"""
@author:随时静听
@file: SD2.py
@time: 2019/01/25
@email:d1314ziting@163.com
"""
try:
from libnmap.parser import NmapParser
import shodan
import os
import glob
import simplejson #用于loding
import json #用于 dumping
import argparse
from functools import wraps
import xlsxwriter
import sys
except :
exit(u'''
Python package dependency:(请检查包依赖)\n
pip install xlsxwriter\n
pip install simplejson\n
pip install python-libnmap\n
pip install argparse\n
''')
from collections import OrderedDict
# 脚本路径
BASE_DIR=os.path.dirname(os.path.abspath(__file__))
print BASE_DIR
# shodan访问API key
API_KEY=""
# 是否实时显示拉取的数据
LOG_ON=False
# 是否开启数据缓存
CACHE_ON=True
# 缓存数据存储位置配置
CACHE_DIR="./cache"
CACHE_FILES=[]
# 提取失败的任务记录
FAILED_FILE=os.path.join(CACHE_DIR+"Failed.lst")
FAILED_LST=[]
#
DATA_DIC={}
# Excel格式配置
EXCEL_TILTE=[u"序号","IP","NMAP_PORTS","Shodan_PORTS"]
# 列宽设置
COL_WIDTH=[7,20,30,35]
# 行高设置
ROW_HIGHT=[(0,17),("other",15)]#第一行和其他行高度
title_style={
'bold':True,#字体加粗
'align':'center',#水平位置设置:居中
'valign':'vcenter',#垂直位置设置,居中
'font_size':12,#'字体大小设置'
'font_name':'Courier New',
'border':1,#边框设置样式1
'border_color':'black',#边框颜色
'bg_color':'#009ad6',#背景颜色设置
}
body_style={
'align': 'left',
'valign': 'vcenter',
'font_size': 10,
'font_name':'Courier New',#字体设置
'border': 2,
'border_color': '#808080',
'font_name': 'Courier New',
}
def env_init():
'''
程序运行环境初始化:
1. 缓存路径检查,不存在就创建
2. 缓存文件见检查,如果存在将获取缓存文件名字,从现有文件中获取,加快获取数据
:return:
'''
if not os.path.exists(CACHE_DIR):
os.makedirs(CACHE_DIR)
CACHE_FILES.extend([os.path.join(CACHE_DIR,json_file) for json_file in glob.glob1(CACHE_DIR,"*.json")])
if CACHE_ON :#开启缓存加速
for filename in CACHE_FILES:
try:
with open(filename,'r') as fr:
data = simplejson.load(fr)
DATA_DIC.update(data)
except Exception as e:
print '[!] Error: loding data from file failed! '+filename
print '[!] Error: '+ e.message
# 解析nmap xml 文件
def parseNmapXml(filename = ""):
if not filename:
print "[!] Error: Nmap xml file is null !"
return None
# nmap xml 文件存在性校验
if not os.path.exists(filename):
print "[!] Error: Nmap xml file does not exist !"
#解析nmap xml数据
try:
nmap_obj = NmapParser.parse_fromfile(filename)
except Exception as e:
# xml解析失败异常处理
print "[!] Error: {} XML file parsing failed ! "
return []
return nmap_obj.hosts
# 处理缓存数据
def cache_processing(func):
@wraps(func)
def inner(*args,**kwargs):
if len(args)==2:
#如果开启缓存
if CACHE_ON:
ret=DATA_DIC.get(args[0].id,None)
#如果从缓存文件中获取不到数据就直接请求加入缓存数据中
if not ret:
ret = func(*args, **kwargs)
if ret:
DATA_DIC.update({args[0].id:ret})#讲数据加入缓存字典
else:
ret=func(*args,**kwargs)
try:
if LOG_ON:
print "[-] INFO: " + args[0].id +" : " +json.dumps(ret,sort_keys=True, indent=2)
except Exception as e:
print "[!] Failed: " + args[0].id
return ret
else:
print "[!] Error: Too few function parameters! In function "+func.__name__
return None
return inner
@cache_processing
def load_data_from_shodan(host,shodan_api):
try:
data_dic=shodan_api.host(host.id,history=False)
return data_dic
except Exception as e:
pass
return None
def parserArgs():
global API_KEY,CACHE_ON,LOG_ON,CACHE_DIR
parser=argparse.ArgumentParser(
usage="python shellFilename -f nmap_xml -o outfile.xlsx ",
description=u'''
Python package dependency:\n
\tpip install xlsxwriter\n
\tpip install python-libnmap\n
\tpip install argparse\n
程序说明:\n
\t1. 默认不开启开启缓存 ,请使用 --make-cache开启缓存\n
\t2. 如果需要实时查看信息获取,请使用 -v 参数\n
\t3. 使用 --api-key shodan-key 来初始化 shodan api \n
''',epilog=".."*50)
parser.add_argument('-f',"--file",help="A File Output scan in normal using nmap",required=True)
parser.add_argument('-o',"--output",help="Report xlsx filename",required=True)
parser.add_argument('-v',"--verbosity",help=u"Print data in real time (默认关闭)",action="store_true")
parser.add_argument('-c',"--make-cache",help=u"Create cached data (默认关闭)",action="store_true")
parser.add_argument("--cache-path",help="Cache file path",default="./cache")
parser.add_argument("--api-key",help="A key for Shodan API")
args = parser.parse_args()
if args.api_key:
API_KEY=args.api_key
if args.cache_path:
CACHE_DIR=args.cache_path
CACHE_ON=args.make_cache
LOG_ON=args.verbosity
if args.output:
if os.path.exists(args.output):
print u"[!] Error: 文件已经存在 ! ("+args.output+")."
exit(u"[!] 程序退出")
return (args.file,args.output)
def ReportExcel(data_lst,outfile,title_style=title_style,body_style=body_style,title=EXCEL_TILTE,c_w=COL_WIDTH,r_h=ROW_HIGHT):
if not outfile:
exit("[!] Error in Function : ReportExcel.")
book=xlsxwriter.Workbook(outfile)
sheet=book.add_worksheet("Result")
title_style=book.add_format(title_style)
body_style=book.add_format(body_style)
# 设置 列宽
for c, w in enumerate(c_w):
# print c, w
sheet.set_column(c, c + 1, w)
# 设置 行高
exculde_r=[]
other_h=0
for r,h in r_h:
if r!="other":
sheet.set_row(r,h)
exculde_r.append(r)
if r=="other":
other_h=h
for i in list(set(range(1000))-set(exculde_r)):
sheet.set_row(i,other_h)
#写入标题
for i,data in enumerate(title):
sheet.write(0,i,data,title_style)
# 数据写入
index=1
for r,data in enumerate(data_lst): # host,nmap_ports_lst,shodan_ports_lst
sheet.write(r+1,0,index,body_style)
#写入 IP
sheet.write(r+1,1,data[0],body_style)
if not data[1]:
sheet.write(r+1,2,"/",body_style)
else:
sheet.write(r+1,2,",".join([ str(p[0]) for p in data[1] ]),body_style)
if not data[2]:
sheet.write(r+1,3,"/",body_style)
else:
sheet.write(r+1,3,",".join([ str(p) for p in data[2] ]),body_style)
index+=1
book.close()
def writeCache():
'''
缓存数据回写
:return:
'''
import datetime
import time
cache_filename=time.strftime("%Y%m%d_%H%M%S",time.localtime())+".json"
if CACHE_ON:
with open(os.path.join(CACHE_DIR,cache_filename),"w") as f:
try:
json.dump(DATA_DIC,f)
except:
print "WARNING: CACHE DATA WRITE FAILED!"
#打印进度条,这个进度条打印思路很不错
def printProgress(cnt, tot, target='', previouslen=0):
percent = 100 * float(cnt) / float(tot)
if target and previouslen > len(target):
target = target + ' ' * (previouslen - len(target))
sys.stdout.write('[%-40s] %d%% %s\r' % ('='*int(float(percent)/100*40), percent, target))
sys.stdout.flush()
return ''
def runMain():
env_init()
#统计信息
num=0
# 获取解析的xml和导出的文件名
nmap_xml, outfile = parserArgs()
print "[-] INFO: Processing Nmap xml file: "+nmap_xml
print "[-] INFO: Set output Excel file name : "+outfile
# 获取xml 中的主机信息
host_lst = parseNmapXml(nmap_xml)
print "[-] INFO: Parser Nmap XML file completed! GET HOST NUM: "+ str(len(host_lst))
# 初始化shodan API
try:
api = shodan.Shodan(API_KEY)
except Exception as e:
print "[!] Error: Shodan API initialization failed! "
exit(u"[!] 程序异常退出:"+e.message)
# nmap_xml_lst=[]
# shodan_lst=[]
result_lst = []
if not host_lst :
exit("[!] Parse nmap xml file ("+nmap_xml+") 0 host!")
for i,host in enumerate(host_lst) :
host_dic = load_data_from_shodan(host,api)
# print DATA_DIC
if host_dic:
num+=1
nmap_ports = host.get_open_ports()
shodan_ports = host_dic.get('ports', [])
result_lst.append( (host.id, nmap_ports, shodan_ports) )
printProgress(i + 1, len(host_lst), host.id)
ReportExcel(result_lst,outfile)
writeCache()
print "[-] INFO: All has Finished processing ! Total:" + str(num)
print "[-] INFO: Excel File save path: " + outfile
if __name__ == '__main__':
# 测试
# ReportExcel([("192.168.1.1",[1,2,3],[]),["192.168.2.3",[77,8080,9001,8007],[999,3306,3389] ] ],"123.xlsx")
# print CACHE_ON
runMain()
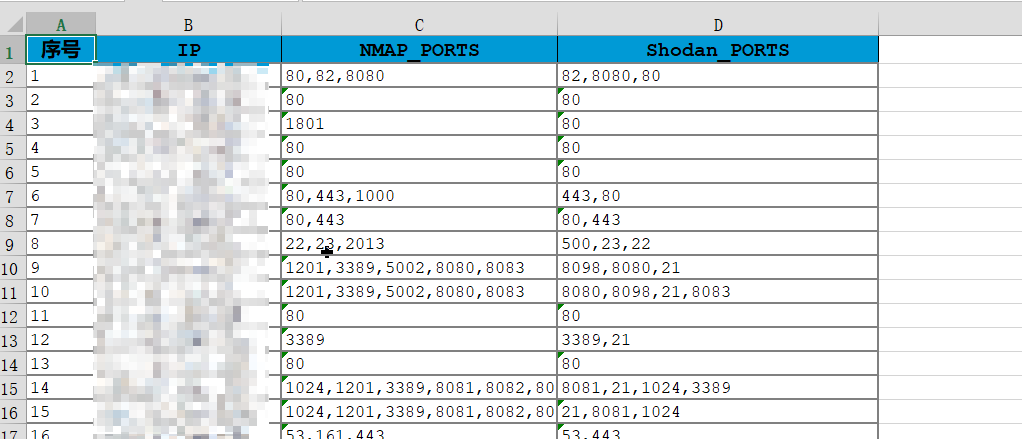
效果图
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号