消息队列
Q1. 为什么使用消息队列?
A1: 我们公司有个什么业务场景,这个业务场景有个什么技术挑战,如果不用 MQ 可能会很麻烦,但是你现在用了 MQ 之后带给了你很多的好处。一般的使用场景有:解耦、异步、削峰。
- 解耦:生产者发布消息,谁需要谁订阅。如果是直接同步调用其它系统,还要考虑有新系统接进来的兼容适配、同步调用超时怎么办?调用失败怎么办?是否要重发?是否需要保存消息等等问题。
示例:收付通系统中,如果用户支付成功,则需要通知分账系统进行分账、通知风控系统更新风控策略、通知智能路由系统更新通道数据、通知商户支付成功事件等。
总结:通过一个 MQ,Pub/Sub 发布订阅消息这么一个模型,A 系统就跟其它系统彻底解耦了。
- 异步:在主流程中,可能有一些操作是可以接受延迟的,不需要在主流程中同步进行操作,我们就可以将这些操作写入 MQ,后台异步从MQ中获取进行消费。这样可以降低主流程的耗时,给用户更好的体验。
示例: 用户支付成功后,需要发送短信通知客户,我们就可以在用户支付成功后,将支付成功的订单放入MQ,后端从MQ中获取支付成功的订单,然后异步发送短信,即使短信有延迟,用户也可以接受。这样就避免了由于短信网关的耗时导致支付主流程的耗时。
- 削峰:在业务高峰期的时候,由于请求量很大,后端的MySQL可能顶不住这么大的并发量导致系统挂掉,这时我们可以将这些请求写入 MQ,由后端慢慢拉取进行消费。这种情况可能导致 MQ 中有大量的消息积压,不过高峰期一过,系统就会快速将这些积压的消息消费掉。至于如何处理大量积压的消息,则是另外的一个问题了。
Q2: 消息队列有什么优点和缺点?
A2: 优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰。缺点有以下几个:
- 系统可用性降低:系统引入的外部依赖越多,越容易挂掉。
- 系统复杂度提高:引入 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?会引入一系列需要考虑的问题。
- 一致性问题:A 系统处理完了直接返回成功了,客户端都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,就会导致数据就不一致。
总结:消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉。
Q3: Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么区别,以及适合哪些场景?
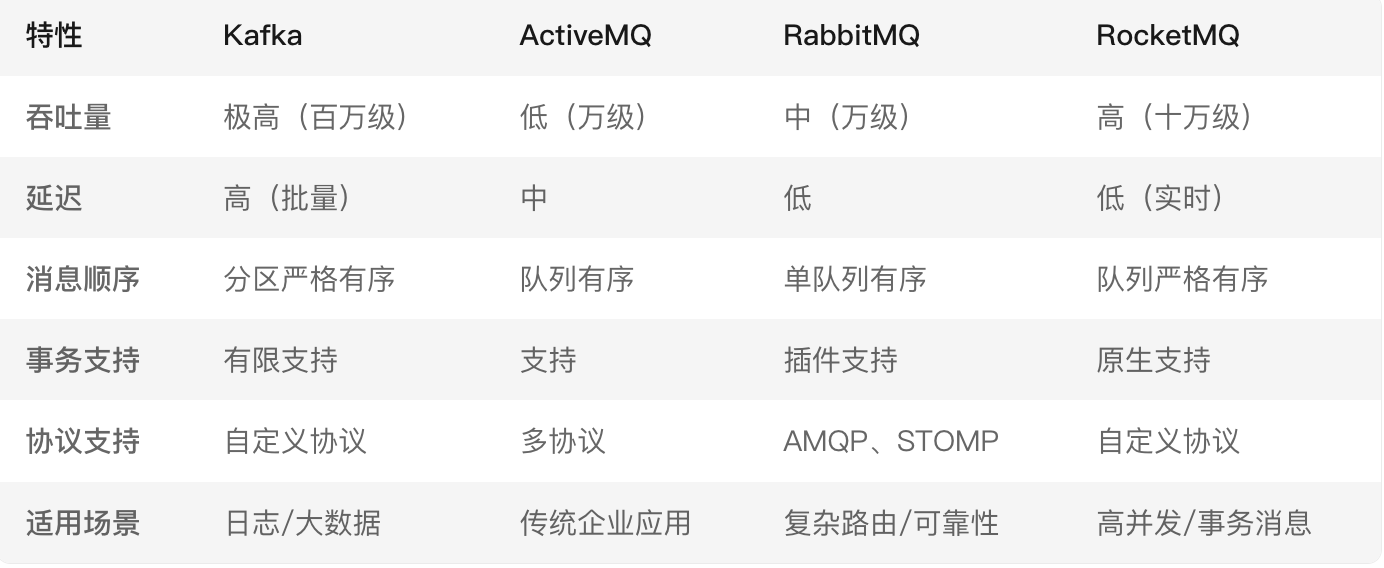
总结:
- ActiveMQ 没经过大规模吞吐量场景的验证,社区不活跃,不推荐
- RabbitMQ 使用erlang语言开发,一般的开发团队不是很熟悉这个语言,不推荐
- RocketMQ 阿里开源的,Java语言开发,已经贡献给了 Apache,推荐
- Kafka 主要用于大数据领域的实时计算、日志采集等场景,也可作为消息队列使用,但相比于专业的消息队列,功能有所欠缺,比如不支持延迟消息和死信队列,不支持消息优先级,不支持分布式事务(两阶段提交)。如果不使用这些特性,推荐
Q4: 如何保证消息队列的高可用?
A4: 不同的消息队列实现高可用的方式是不同的,可以回答一个你比较熟悉的一种,比如 Kafka 是如何保证高可用的。
- RabbitMQ 等传统的消息队列是基于集群,主从模式做 HA(Hight Available) 的,每个实例都是存放一个这个queue的完整数据,没有办法进行横向线性扩展。
- Kafka 这种分布式消息队列一个 topic 的数据,是存放到多个机器(broker)上的,每个机器只存储一部分数据(partition),这样就可以横向增加机器来进行扩展。每个 partition 又有多个副本(replica), 如果一个 broker 宕机了,其它 broker 上还有备份数据,并且如果这个 broker 包含某个 partition 的 leader,还会发生 failover, 进行重新选主,保证高可用。
Q5: 如何保证消息的可靠投递?
A5:消息丢失可能出现在生产者、消息队列本身、消费者中,我们以 Kafka 为例进行分析。
- 生产者:生产者往 broker 发送消息之前,先对消息进行一次落地,收到borker 的 ACK 后才将消息标记为已送达,后台启动一个定时任务,无限重试未送达的消息。
- 消息队列:
给 topic 设置参数 replication.factor 参数大于1,要求每个 partition 必须有至少 2 个副本。
在 Kafka 服务端设置 min.insync.replicas 参数,这个值必须大于 1,要求至少有一个 follower 与 leader 实时保持同步,避免选举新 leader 的时候丢失未同步的数据。
在 producer 端设置 acks = all 参数,这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。
在 producer 端设置 retries 参数和 delivery.timeout.ms 参数,要求进行重试(有限重试,无限重试可以在业务侧异步进行)。 - 消费者:Kafka有一种模式是自动提交 offset,考虑这么一个场景:业务系统拿到这个消息,还没来及进行处理,然后Kafka自动提交了offset,此时业务系统崩溃重启,重启后kafka认为消费者已经消费了这个消息,就会造成消息丢失。解决方式是自己手动提交 offset,执行步骤是:拉取消息-->完成消费者业务逻辑-->手动提交偏移量。这种情况可能造成重复消费,比如在处理完业务逻辑后系统崩溃,重启后会重新拉到这条处理过的消息。
Q6: 如何保证消息不被重复消费?
A6: 由于 Kafka 在自动提交 offset 的情况下会造成重复消费,所以更多的是考虑业务处理时如何保证幂等性的问题。其实还是得结合业务来思考,这里有几个思路:
- 比如业务是拿个数据要写库,你先根据主键查一下,如果这数据已经有了,则不进行处理
- 比如业务是写 Redis,因为每次都是 set,天然保证幂等性
- 让生产者发送每条消息的时候,里面加一个全局唯一的 id,类似消息ID,消费者将消费过的消息ID存入Redis,进行判重
- 基于数据库的唯一键来保证重复数据不会重复插入多条
由于消息不能被永久存储,然后上游还是投递了下游已经清空了的历史消费消息等,即使由于种种原因,重复的消息还是到来了,业务侧一般有两种通用的解决方案: - 版本号:让每个消息携带一个版本号。参考TCP/IP协议,如果想让乱序的消息最后能够正确的被组织,那么就应该只接收比当前版本号大一的消息。最大的问题是需要业务方携带业务版本号
- 状态机:如果消息没有版本号, 业务方需要自己维护一个状态机,定义各种状态的流转关系, 比如上线状态只能转换为下线状态。遇到不符合状态转换的消息,给客户返回响应的错误码
总结:消息队列保证不丢失消息的情况下尽量少重复消息,消费顺序不保证。那么重复消息下和乱序消息下业务的正确,应该是由消费方保证的,我们要做的是减少消息发送的重复。
Q7: 如何解决消息队列的延迟以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,应该怎么解决?
A7: 当消费者消费比较慢,或者消费者出现故障后,就会造成消息的堆积,堆积中的消息进行消费就会有延迟。如果造成大量消息的堆积,还需要进行紧急扩容。一般流程是:
- 先分析是不是消费者故障,如果是则需要先进行修复,恢复正常的消费速度
- 如果是消费者正常,仅仅是因为消费者消费速度远小于生产者生产速度,则查看消费者和 partition 的数量关系,如果消费者数量少于 partition,则可以适当扩容消费者(快速扩展容器实例或者Kubernetes Pod的数量)。
- 如果已经积压了大量消息,需要紧急处理,则一般步骤是:
- 先停掉当前的 consumer
- 新建一个新的 topic, 比如 my_topic_v2, partition 数量是原来的 10 倍
- 然后写一个临时的分发数据的 consumer 程序(一般都有紧急预案会提前准备好),这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 partition 中。
- 将 consumer 服务修改为从新建的 my_topic_v2 读取消息,然后临时扩展容器实例或者Kubernetes Pod的数量为原来的 10 倍,相当于以 10 倍于原来的速度去消费。
- 消费完成后,将架构改为原来部署的架构,重新用原来的 consumer 来消费消息。
另外,对于 RabbitMQ 这样的消息队列,消息是可以设置有效期TTL的,如果消息在队列中过期了,就会被清理掉,这样消息就丢失了。一般情况下都会通过批量重导的方式去补回来。比如写个重导程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去。
其次,消息队列满了的话,可以通过设置消息的过期时间让老消息尽快过期,当然,如果使用的是一些云厂商提供的产品,应该会提供自动扩容的能力和消息堆积的告警能力,能提前发现和解决问题。
Q8: 如果让你写一个消息队列,该如何进行架构设计?说一下你的思路.
A8: 要大概知道消息队列技术的基本原理、核心组成部分、基本架构构成,然后参照一些开源的技术把一个系统设计出来的思路说一下就好。比如:
- RPC: 排除对效率的极端要求,都可以使用现成的RPC框架
- 可伸缩性:设计个分布式的系统,broker --> topic --> partition 每个 partition 存放一部分数据,每个 broker 存储多个 partition,这样的机制可以横向线性扩展。
- 存储子系统:理论上,从速度来看,文件系统>分布式KV(持久化)>分布式文件系统>数据库,而可靠性却截然相反。比如 Kafka 采用多副本保证消息的高可用
- 高可用:采用 leader 和 follower 的机制,故障自动 failover 的方式进行重新选主,来保证服务的高可用。协议为 KRaft(基于Raft实现)
- 消费关系:组间广播、组内单播是最常见的情形。
参考资料:
https://www.lanqiao.cn/library/advanced-java/docs/high-concurrency/mq-interview
美团:https://tech.meituan.com/2016/07/01/mq-design.html
长轮询:https://mp.weixin.qq.com/s?__biz=Mzg2NzYyNjQzNg==&mid=2247500202&idx=1&sn=069d57d65338a5c7a59b2362bca716e7&chksm=ceba3d01f9cdb417b8584ca7d3519ea3c9d019feaffb74f81bebe4bb476b7d9afcc60c0ba93c#rd


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗