python基础数据类型
一.python基础数据类型
1.int 整数。主要用于进行数学运算
2.str 字符串。可以保存少量数据并进行操作
3.bool 布尔。判断真或假 True/False
4.list 列表。存储大量数据用[]表示
5.tuple 元祖。不可以发生改变用()表示
6.dict 字典.。保存键值对,一样可以保存大量数据
7.set集合。 保存大量数据。不可以重复。其实就是不保存v的dict
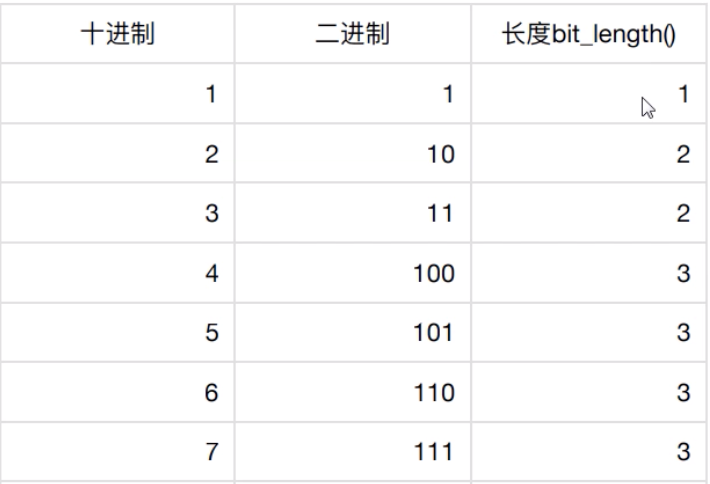
二 整数(int)
在python3中所有的整数都是int类型。但是在python2中如果大量数据比较大。会使用long类型。
在 python3中不 存在long类型
bit_length()计算整数在内存中占用的二进制码的长度
三 bool类型
bool在python中是没有相应的方法的
类型转换: !0 =True 0=False
字符串转换int int(内容)
int转换字符串 str(内容)
xx类型 ==bool类型 bool(内容)
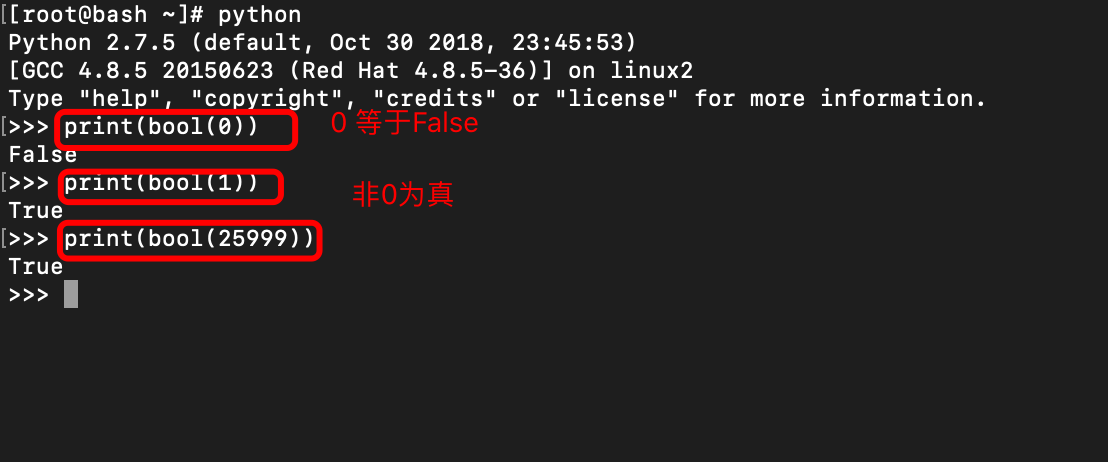

PS:空的东西False 非空的为True
no = None 表示也是空
print(bool(no))
PS:所有的数据类型,如果是空的,转换成bool就是false,如果是非空的True
死循环

四 字符串
索引和切片,索引就是编号,索引是从0开始的,索引可以获取到数据[索引即下标]
#索引
#正排 0123456
s = "jack和li"
#反排-6-5-4-3-2-1
print (s[1])
#倒数,在python中-1表示倒数第一个
print(s[-1])
print (s[-2])
#切片
li = "abcdefgh"
print (li[2:6]) #特点:顾头不顾尾
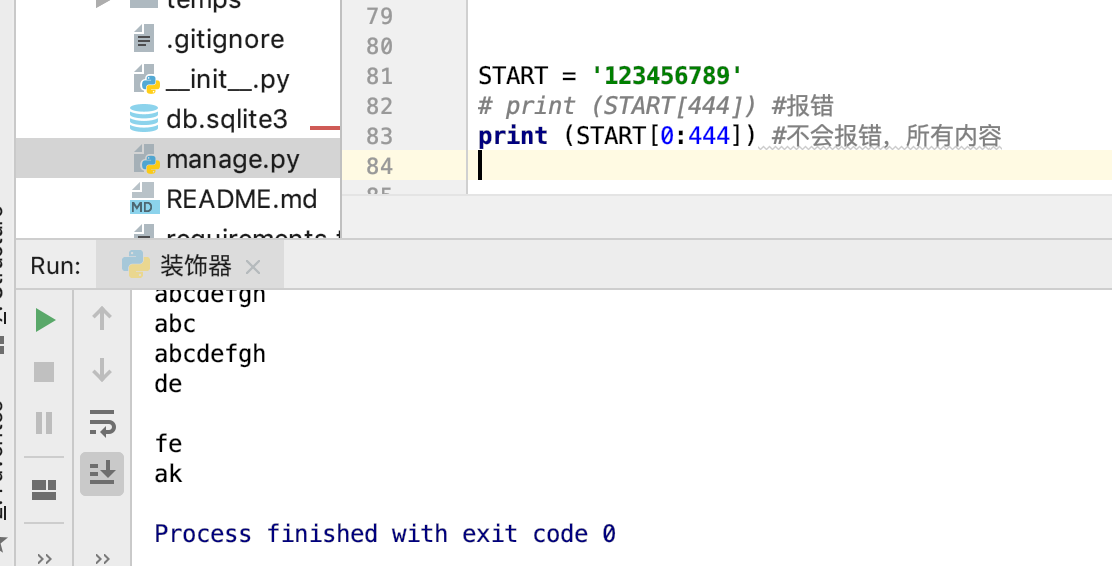
print (li[0:]) #如果不写表示 取到最后
print (li[:3]) #开头去可以写0或者不写
print(li[:]) #这里是把原来的字符串进行copy
print (li[-5:-3])
print (li[-3:-5]) # 只能从左往右取
#步长:如果步长为正,从左望右取,如果步长为负从右往左取
print (li[-3:-5:-1])
#数值表示:每n个取一个
fun = 'jackli'
print (fun[1:5:2]) #从a取到l因为顾头不顾尾取不到i,结果为ak
a = '''
切片:[开始位置:结束:步长]
特点:顾头不顾尾。步长;默认为1 如果步长为负数。从右往左取
'''
五 字符串操作
s = 'jack.Li'
s1 =s.capitalize() #首字母大写
print (s1)
s2 = s.lower() # 变成小些
print (s2)
s3 = s.upper() # 变成大写
print (s3)
s4 = s.startswith() #大小写互转
print (s4)
s = 'jack'
print (s.center(10,"*")) #默认由空格来填充
s1 = ' li can not find li '
print (s1.strip()) #去掉左右两端的空格
print (s1.strip(" ")) #去掉两端字符串
print (s.lstrip()) # 去掉左边空格
#替换
s = "jack_li_jack_syf"
print (s.replace('jack','大王',1))
#字符串切割
li = "jack_songsir_egon"
ret = s.split("_") #切割之后的结果是列表
print (ret)
a = '''
水手
月亮之上
康定情缘
'''
lst = a.split("\n")
print (lst)
#查找
S = "can not find objket 百"
print (S.startswith("can")) #判断是否以can开头
print (S.endswith("百"))
li = "my can find name go mha"
print (li.count("a")) # 统计a出现的次数
s12 = "123455"
print (len(s12)) #计算字符串长度
s11 = "BeiJingJD"
for i in s12:
print (i)
六 格式化输出
vers = '我叫{}.来自{},爱好{}'.format("CREPJ","JD","shaodu")
print (vers)
vers = '我叫{name}.来自{address},爱好{hobby}'.format(name="hangzhou",address="BEIJIng",hobby="henan")
print (vers)
七 列表
1.列表
2.列表的增删改查
3.列表的嵌套
4.元祖和元祖嵌套
5.range
列表
7.1列表的介绍
列表是python的基础数据类型之一 ,其他编程语言也有类似的数据类型,如JS中的数组
Java中的数组等等,他是以[]括起来,每个元素用','隔开而且可以存放各种数据类型
lst [1,True,"字符串",[1,2,3,4],{"k":"jack"},{1,2,3}]
列表相对于字符串。不仅可以存放不同的数据类型。而且可以存放大量的数据。而且列表是有序的 ,有索引,可以切片方便取值
7.2列表的切片
#列表的索引/切片
lst = ["abc","def","efg"]
print (lst[1][0])
print (lst[-2][-1])
print (lst[0:2]) #切片切出来的还是列表
列表的增删改查#列表的lst1 = ["赌神","喜剧之王","西西里的传说","心灵朴树欧"]
'''
lst1.append("我不是药神")
print (lst1)
lst1.insert(1,"邪不压正") #效率较低
print (lst1)
lst1.extend(["举起瘦了"],[1],[2]) #迭代新增
print (lst1)
#列表的删
lst2 = ["佟亚丽","王亚丽","王力宏","贺国强","国强民富欧"]
lst2.pop(2) #可以根据索引删除,也可以删除最后的元素,可以查看被删除的元素
print (lst2)
lst2.remove("佟丽娅") #制定元素进行删除
print (lst)
lst2.clear()#清空
print (lst2)
del lst2[0] #切片删除
print (lst2)
#修改:
lst = ["郭德纲","岳云鹏","孙悦","于谦"]
lst[2] = "曹云金"
print (lst)
lst[1:3] = ["郭麒麟"] #迭代修改
print (lst)
lst[1:3:2] = ["何云伟","李靖"] #带步长的一定注意元素的个数
print (lst)
'''
#查询
lst = ["空掉","冰箱","电视"]
for le in lst:
print (le)
#其他操作
c = lst.count("电视") #统计出现的次数
print (c)
lst2 = [1,3,2,5,3,5,7,86,8]
lst2.sort() #正序排
print (lst2)
lst2.sort(reverse=True) #反排
print (lst2)
lst2.reverse() #反转
print (lst2)
#列表的嵌套
lst3 = [1,"太白","wusir",["马化腾",["可口可乐"],"王健林"]]# print (lst3[3][1][0])
lst3[3][1].append("雪碧")
print (lst3)
八 元祖和元祖嵌套
元祖:不可变的列表。又称为只读列表,元祖也是python的基础数据类型之一,用小括号阔起来,里面可以放任何数据类型的数据,查询数据,切片,不能修改
#列表的嵌套
lst3 = [1,"太白","wusir",["马化腾",["可口可乐"],"王健林"]]
# print (lst3[3][1][0])
lst3[3][1].append("雪碧")
print (lst3)
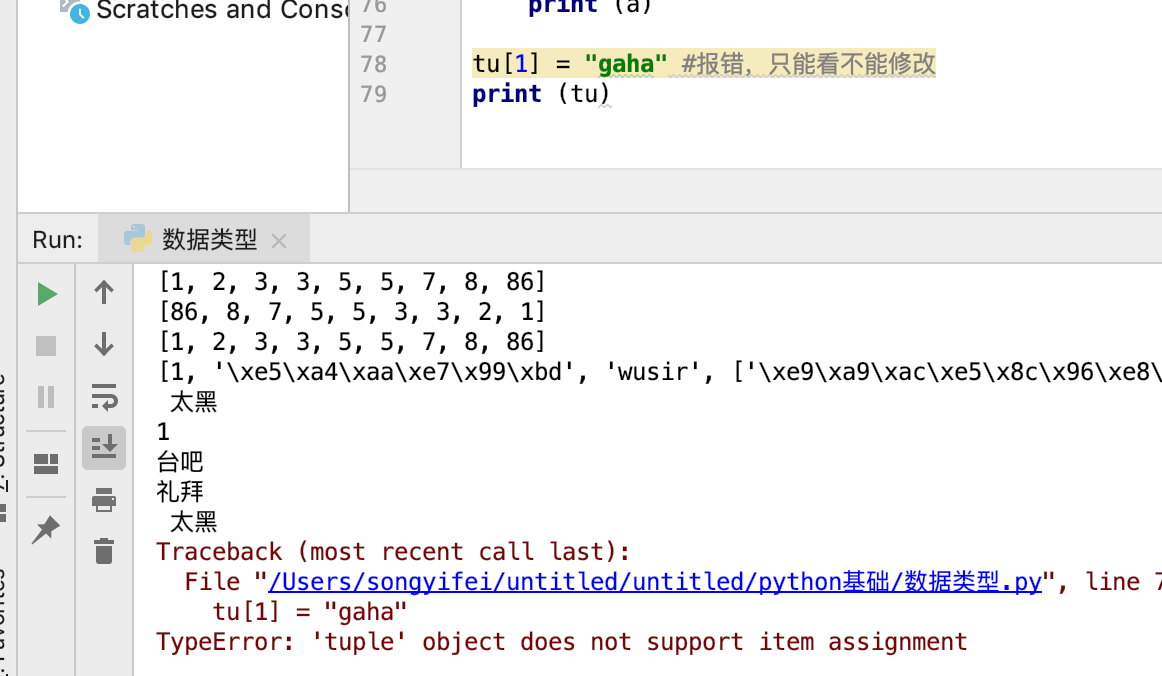
tu = (1,"台吧","礼拜"," 太黑")
print(tu[3]) #有索引,有切片
#可迭代
for a in tu:
print (a)
range
for i in range(1000000):
print (i)
for i in range(3,7): #[3,7], 顾头不顾尾
print (i)
for i in range(1,100,2): #步长
print (i)
九 字典
dic1 = {1:"马化腾",2:"胡辣汤",(1,2,3):"饺子"}
print (dic1)
# key必须是可哈希的,不可变的东西都是可哈希的
#字典以{}把key:value的数据保存起来。key必须可哈希value没有任何要求
#从字典中获取数据
# dic = {"id":1,"name":"jack",'age':12}
# print (dic["age"])
dic1 = {"周杰伦":"双节棍","王力宏":"大城小爱","郭得刚":"于谦他么美"}
dic1["刘强东"] = ["JD"] #新增 当key不存在的时候,直接赋值
print (dic1)
v = dic1.setdefault("刘强东","QQ") #当key不存在的时候,把k-v新增进字典,如果有这个key,就不会有这个key
#setdefault第二个工作,会把key对应的值或取到
print (dic1)
lsa = [11,22,33,44,55,66,77,88,99]
dic3 = {}
for i in lsa:
if i < 66:
dic3.setdefault("key1",[]).append(i)
else:
dic3.setdefault("key2",[]).append(i)
print (dic3)
#更新:
dic4 = {"id":"hafa","name":"sylar","age":18}
dic5 = {"id":456,"name":"马化腾","ok":"wtf"}
dic4.update(dic5) #把dic5更新到dic中.如果key重名,则修改替换,如果不存在key,则新增
print (dic4)
#查询
# print (dic4["pd"]) #会报错
print (dic4.get("PD","不存在")) #当key不存在的时候返回默认值,当key有的时候会返回v
#其他操作
print(dic4.keys()) #返回所有的key的集合(既不是列表也不是集合,是一个可迭代对象)
for i in dic4.keys(): #可迭代
print (i) #所有的key
print (dic4[i])
for a in dic4.values():#获取到所有的v
print (a)
for k,v in dic4.items(): #items ()拿到的是key,v组装出来的是元祖
print (k,v)
for k in dic4():
print (k)
print (dic4[k])
# 字典的嵌套
person = {
"name":"汪峰",
"艺名":"皮克",
"Wi-Fi":{
"name":"章子怡",
"艺名":"国际张",
"age":"30",
"前夫":[{'name':'撒贝宁'},{'name':'白眼怂'},{'name':'jack'}]
},
'children':[
{'name':'孩子',"age":128},
{'name':"孩子2","age":12}
]
}
print (person["Wi-Fi"]["前夫"][1]["name"])
person['children'].append({"name":"3","aeg":12})
print (person)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端