2020软件工程个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 学习json文件的处理,学习GitHub的基础操作,学习高级语言处理文件 |
| 学号 | 031802321 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 40 |
| Estimate | 估计这个任务需要多少时间 | 300 | 335 |
| Development | 开发 | 20 | 30 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 25 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| Design | 具体设计 | 20 | 20 |
| Coding | 具体编码 | 20 | 30 |
| Code Review | 代码复审 | 15 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 10 | 10 |
| Test Report | 测试报告 | 20 | 15 |
| Size Measurement | 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 15 |
| 合计 |
目录
- 解题思路
- 实现过程
- 代码说明
json初始化- 实现命令行参数设置
- 求出最终结果
- 单元测试截图与描述
- 单元测试覆盖率优化和性能测试
- 代码规范链接
解题思路
- 思考过程
- 因为可能会有多个Json文件需要分析,所以我首先想到的就是将所有Json文件中的数据放入一个
data_file.json文件中 - 其次就是命令行参数的设置(一脸懵)
- 搞完这些,就可以根据给定的参数遍历
data_file.json来求出所需要的值
- 因为可能会有多个Json文件需要分析,所以我首先想到的就是将所有Json文件中的数据放入一个
- 使用
Python对文件的分析还是不太熟悉哈哈哈,所以就上百度察看了一些json.loads(),json.load(),open的知识 - 还有命令行参数的设置,这是我最懵的地方,在百度与某靓仔同学的教导下,算是了解了如何去操作
实现过程
def data_init(path_to_data):- 将
json文件夹中所有json文件放入一个json文件
- 将
def request_num(all_data,type_,actor_login,repo_name):- 对给定的参数进行分析,并遍历文件求出结果
opts,arvs= getopt.getopt(sys.argv[1:],'i:u:r:e:',['user=','repo=','event=','init='])- 命令行参数设置
代码说明
-
对给定的数据文件夹进行分析
-
files=os.listdir(path_to_data) # 数据文件夹中 json 文件的文件名列表 f=open('data_file.json','w',encoding='utf-8') #新建一个 json 文件进行存放 for file in files: file_adr=path_to_data+"\\"+file with open(file_adr,encoding='utf-8') as f1: for x in f1: f.write(x) # 将所有json文件放入data_file.json中 return
-
-
通过给定的参数遍历
data_file.json求出所求-
num=0 if repo_name=="-1": # 个人的 4 种事件的数量 for data_comp in all_data: if actor_login==data_comp['actor']['login']: if type_==data_comp['type']: num+=1 else: continue else: continue elif actor_login=="-1": # 每一个项目的 4 种事件的数量 for data_comp in all_data: if repo_name==data_comp['repo']['name']: if type_==data_comp['type']: num+=1 else: continue else: continue else: # 每一个人在每一个项目的 4 种事件的数量 for data_comp in all_data: if repo_name==data_comp['repo']['name'] and actor_login==data_comp['actor']['login']: if type_==data_comp['type']: num+=1 else: continue else: continue return num
-
-
根据命令行参数选择分支
-
if opt[0]=="-i" or opt[0]=="--init": path=opt[1] data_init(path) break elif opt[0]=="-u" or opt[0]=="--user": actor_login_=opt[1] elif opt[0]=="-r" or opt[0]=="--repo": repo_name_=opt[1] else: type__=opt[1]
-
-
最后运行函数 request_num()
number=request_num(all_data1,type__,actor_login_,repo_name_)
单元测试截图

单元测试覆盖率优化和性能测试
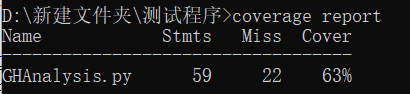
- 使用
coverage import进行覆盖率检测,代码将继续优化···(是有一点又臭又长)




代码规范链接
总结
- 自省
- 这次作业之前没什么经验,现在提交的代码可能并不完美,所实现的功能也不多,
- 我设想的是可以随意输入参数,每一次的输出都会输出参数们所对应的 repo_name 数量,4种 type 的数量以及 actor_login 的值
- 并且因为我的代码是单线程的,很不高大上,我会继续优化一下,尽力实现的更快,代码功能更强
- 所遇困难
- 之前有学过单文件的读写,但是这次涉及多文件的读写,就很懵,所以特意上百度学了一下os模块,了解了一下多文件的读写
- 其次是命令行参数设计,有在群里看到同学发的命令行参数设置的博客,就看了很久,其实还是不怎么明白,特意请教了那位同学,hhh 教了我一晚上,那位靓仔应该也很无语 hhh
- 还有就是多线程设计,在勉强参悟助教给的参考代码hhh,一句一句的面向百度与舍友编程ing
- 这次的作业,让我学到了许多知识,我的基础还差了很多,努力追赶,冲冲冲
参考
- cProfile——Python性能分析工具
https://www.cnblogs.com/kaituorensheng/p/4453953.html
- Python 命令行参数
https://www.runoob.com/python/python-command-line-arguments.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号