CSS selectors 选择器
CSS selectors 选择器
选择器的基本意义是:根据一些特征,选中元素树上的一批元素。
-
总览分类
- 简单选择器:针对某一特征判断是否选中元素。
- 复合选择器:连续写在一起的简单选择器,针对元素自身特征选择单个元素。
- 复杂选择器:由“(空格)”“ >”“ ~”“ +”“ ||”等符号连接的复合选择器,根据父元素或者前序元素检查单个元素。
- 选择器列表:由逗号分隔的复杂选择器,表示“或”的关系
-
详解
-
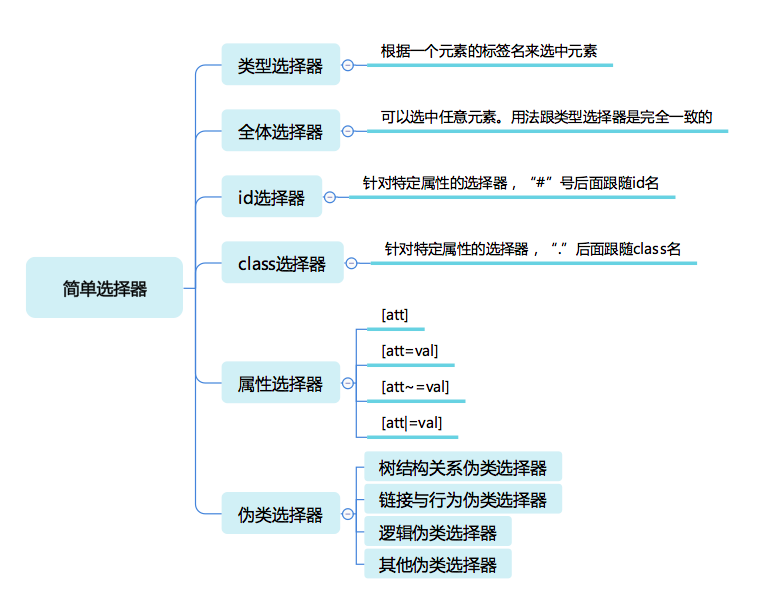
简单选择器
-
类型选择器和全体选择器
-
类型选择器有 div span p html body a 这些,选中的是全部的DOM 上的元素。
-
全体选择器就是 *,选中全部的元素。我们通常用来覆盖默认样式、写字体格式这些。
-
-
id 选择器与 class 选择器
- # 选中 id
- . 选中 class
这里有个值得一提的是,document.getElementBy...的性能要比 document.querySelector...的性能好的多,尽量用document.getElementBy
-
属性选择器
-
[att]
只要元素有这个属性,不论属性是什么值,都可以被选中。
-
[att=val]
精确匹配,检查一个元素属性的值是否是 val。
-
[att~=val]
多种匹配,检查一个元素的值是否是若干值之一,这里的 val 不是一个单一的值了,可以是用空格分隔的一个序列。
-
[att|=val]
开头匹配,检查一个元素的值是否是以 val 开头,它跟精确匹配的区别是属性只要以 val 开头即可,后面内容不管。
这个设计有点不符合直觉,感觉^=更靠谱点,毕竟正则是这么写的。。。
-
-
伪类选择器
-
树结构关系伪类选择器
- :empty 伪类表示没有子节点的元素,这里有个例外就是子节点为空白文本节点的情况。
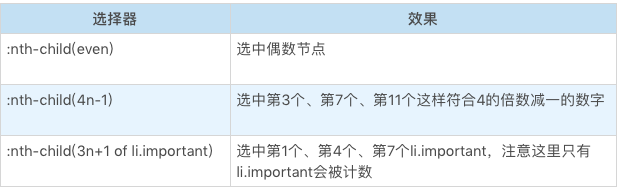
- :nth-child 和 :nth-last-child 这是两个函数型的伪类,CSS 的 An+B 语法设计的是比较复杂的,我们这里仅仅介绍基本用法。我们还是看几个例子:
-
:nth-last-child 的区别仅仅是从后往前数。
-
:first-child :last-child 分别表示第一个和最后一个元素。
-
:only-child 按字面意思理解即可,选中唯一一个子元素。
-
of-type 系列,是一个变形的语法糖,S:nth-of-type(An+B) 是:nth-child(|An+B| of S) 的另一种写法。以此类推,还有 nth-last-of-type、first-of-type、last-of-type、only-of-type。
-
链接与行为伪类选择器(常用的一批)
- :any-link 表示任意的链接,包括 a、area 和 link 标签都可能匹配到这个伪类
- :link 表示未访问过的链接, :visited 表示已经访问过的链接。
- :hover 表示鼠标悬停在上的元素。
- :active 表示用户正在激活这个元素,如用户按下按钮,鼠标还未抬起时,这个按钮就处于激活状态。
- :focus 表示焦点落在这个元素之上。
- :target 用于选中浏览器 URL 的 hash 部分所指示的元素。
- 在 Selector Level 4 草案中,还引入了 target-within、focus-within 等伪类,用于表示 target 或者 focus 的父容器。具体可以去看看 w3c selector 4
-
逻辑伪类选择器
-
:not 伪类。
*|*:not(:hover)
-
-
其他的伪类选择器(了解即可)
dir、lang、play、pause、current、past、future、nth-col、nth-last-col
-
-
复合选择器
连续写在一起 如:
html body div span .interesting #666selector { background-color: 'azure'; } -
复杂选择器
-
选择器的组合
- “空格”:后代,表示选中所有符合条件的后代节点, 例如“ .a .b ”表示选中所有具有 class 为 a 的后代节点中 class 为 b 的节点。
- “>” :子代,表示选中符合条件的子节点,例如“ .a>.b ”表示:选中所有“具有 class 为 a 的子节点中,class 为 b 的节点”。
- “~” : 后继,表示选中所有符合条件的后继节点,后继节点即跟当前节点具有同一个父元素,并出现在它之后的节点,例如“ .a~.b ”表示选中所有具有 class 为 a 的后继中,class 为 b 的节点。
这么理解更简单,前面有.a 的 所有 .b元素
- “+”:直接后继,表示选中符合条件的直接后继节点,直接后继节点即 nextSlibling。例如 “.a+.b ”表示选中所有具有 class 为 a 的下一个 class 为 b 的节点。
- “||”:列选择器,表示选中对应列中符合条件的单元格。
我们在实际使用时,比较常用的连接方式是“空格”和“>”。
工程实践中一般会采用设置合理的 class 的方式,来避免过于复杂的选择器结构,这样更有利于维护和性能。空格和子代选择器通常用于组件化场景,当组件是独立开发时,很难完全避免 class 重名的情况,如果为组件的最外层容器元素设置一个特别的 class 名,生成 CSS 规则时,则全部使用后代或者子代选择器,这样可以有效避免 CSS 规则的命名污染问题。
-
选择器的优先级
-
优先级顺序
- 第一优先级
- 无连接符号
- 第二优先级
- “空格”
- “~”
- “+”
- “>”
- “||”
- 第三优先级
- “,”
- 第一优先级
-
优先级计算
CSS 标准用一个三元组 (a, b, c) 来构成一个复杂选择器的优先级。
-
id 选择器的数目记为 a;
-
伪类选择器和 class 选择器的数目记为 b;
-
伪元素选择器和标签选择器数目记为 c;
-
“*” 不影响优先级。
-
行内属性的优先级永远高于 CSS 规则,浏览器提供了一个“口子”,就是在选择器前加上“!import”。这个用法非常危险,因为它相当于一个新的优先级,而且此优先级会高于行内属性
CSS 标准建议用一个足够大的进制,获取“ a-b-c ”来表示选择器优先级。
specificity = base * base * a + base * b + cbase 是一个“足够大”的正整数。关于 base,历史中有些趣闻,早年 IE6 采用 256 进制,于是就产生“256 个 class 优先级等于一个 id”这样的奇葩问题,后来扩大到 65536,基本避免了类似的问题。
我们这么计算,specificity = a * 100 + b * 10 + c * 1
同一优先级的选择器遵循“后面覆盖前面的原则”。
实际写代码的时候还是少来点选择器,不然代码可读性会受到影响,不利于维护。(会被打死。。。)
-
-
-
-
选择器列表
就是一个 “,” 逗号,表示 或者 的关系。。。
-
-
-
伪元素
这个东西还没说呢
目前兼容性达到可用的伪元素有以下几种。
- ::first-line
- ::first-letter
- ::before
- ::after
- 说说 first-line 与 first-letter:
<p>This is a somewhat long HTML paragraph that will be broken into several lines. The first line will be identified by a fictional tag sequence. The other lines will be treated as ordinary lines in the paragraph.</p>p::first-line { text-transform: uppercase }这一段代码把段落的第一行字母变为大写。注意这里的第一行指的是排版后显示的第一行,跟 HTML 代码中的换行无关。
::first-letter 则指第一个字母。首字母变大并向左浮动是一个非常常见的排版方式。
<p>This is a somewhat long HTML paragraph that will be broken into several lines. The first line will be identified by a fictional tag sequence. The other lines will be treated as ordinary lines in the paragraph.</p>p::first-letter { text-transform: uppercase; font-size:2em; float:left; }虽然听上去很简单,但是实际上,我们遇到的 HTML 结构要更为复杂,一旦元素中不是纯文本,规则就变得复杂了。
CSS 标准规定了 first-line 必须出现在最内层的块级元素之内。因此,我们考虑以下代码。
<div> <p id=a>First paragraph</p> <p>Second paragraph</p> </div>div>p#a { color:green; } div::first-line { color:blue; }这段代码最终结果第一行是蓝色,因为 p 是块级元素,所以伪元素出现在块级元素之内,所以内层的 color 覆盖了外层的 color 属性。
如果我们把 p 换成 span,结果就是相反的。
<div> <span id=a>First paragraph</span><br/> <span>Second paragraph</span> </div>div>span#a { color:green; } div::first-line { color:blue; }这段代码的最终结果是绿色,这说明伪元素在 span 之外。
::first-letter 的行为又有所不同,它的位置在所有标签之内,我们把前面的代码换成::first-letter。
<div> <span id=a>First paragraph</span><br/> <span>Second paragraph</span> </div>div>span#a { color:green; } div::first-letter { color:blue; }执行这段代码,我们可以看到,首字母变成了蓝色,这说明伪元素出现在 span 之内。
CSS 标准只要求 ::first-line 和 ::first-letter 实现有限的几个 CSS 属性,都是文本相关,这些属性是下面这些。

-
说说 ::before 和 ::after 伪元素
这两个伪元素跟前面两个不同的是,它不是把已有的内容套上一个元素,而是真正的无中生有,造出一个元素。
::before 表示在元素内容之前插入一个虚拟的元素,::after 则表示在元素内容之后插入。
这两个伪元素所在的 CSS 规则必须指定 content 属性才会生效,我们看下例子:
<p class="special">I'm real element</p>p.special::before { display: block; content: "pseudo! "; }这里要注意一点,::before 和 ::after 还支持 content 为 counter,如:
<p class="special">I'm real element</p> p.special::before { display: block; content: counter(chapno, upper-roman) ". "; }这对于实现一些列表样式是非常有用的。
::before 和 ::after 中支持所有的 CSS 属性。实际开发中,这两个伪元素非常有用,有了这两个伪元素,一些修饰性元素,可以使用纯粹的 CSS 代码添加进去,这能够很好地保持 HTML 代码中的语义,既完成了显示效果,又不会让 DOM 中出现很多无语义的空元素。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号