在linux下安装并运行scrapyd
系统:centos7.4
安装scrapyd:pip isntall scrapyd
因为我腾讯云上是python2与python3并存的 所以我执行的命令是:pip3 isntall scrapyd
安装后新建一个配置文件:
sudo mkdir /etc/scrapyd
sudo vim /etc/scrapyd/scrapyd.conf
写入如下内容:(给内容在https://scrapyd.readthedocs.io/en/stable/config.html可找到)
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
主要更改bind_address=0.0.0.0
创建文件后执行命令启动scrapyd: (scrapyd > /dev/null &) 当想要记录输出日志时: (scrapyd > /root/scrapyd.log &)
坑1:当我执行完命令后报错,说是找不到命令:

那是因为我系统上python2与3并存,所以找不到,这时应该做软连接:
我的python3路径: /usr/local/python3
制作软连接: ln -s /usr/local/python3/bin/scrapy /usr/bin/scrapy
昨晚软连接后,执行上边命令,又报错:
坑2: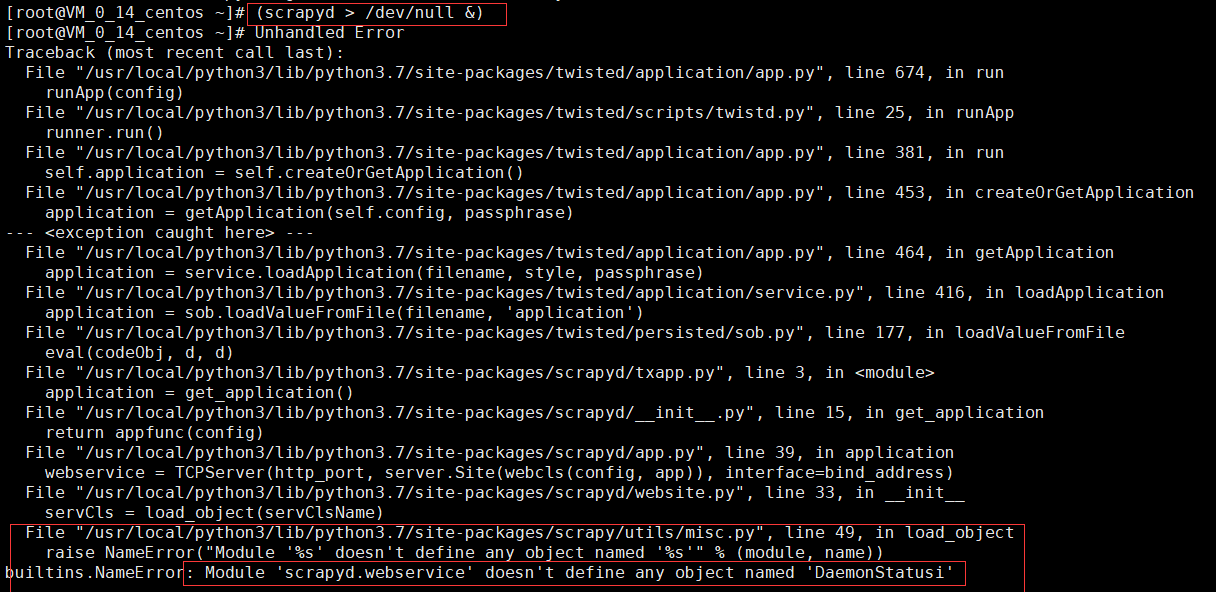
这个好像是那个配置文件的最后一行有问题,具体原因不大清楚,我将最后一行删除,再次重新执行,scrapyd就跑起来了
想了解更多Python关于爬虫、数据分析的内容,欢迎大家关注我的微信公众号:悟道Python


 浙公网安备 33010602011771号
浙公网安备 33010602011771号